数据采集第五次大作业
作业①
- 要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架爬取京东商城某类商品信息及图片。
候选网站:http://www.jd.com/ - 关键词:学生自由选择
- 输出信息:MYSQL的输出信息如下
![]()

作业一代码链接:https://gitee.com/chenshuooooo/data-acquisition/blob/master/作业5/作业1使用selenium爬取京东.py
实现过程
- 1.设置浏览器
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')
- 2.爬取需要的信息
goodlist=driver.find_elements_by_xpath('//div[@id="J_goodsList"]/ul/li[@class="gl-item"]')
for i in goodlist:
price = i.find_elements_by_xpath(".//div/div[@class='p-price']/strong/i")
name = i.find_elements_by_xpath(".//div/div[@class='p-name p-name-type-2']/a/em")
img = i.find_elements_by_xpath(".//div/div[@class='p-img']/a/img")
note = i.find_elements_by_xpath(".//div/div[@class='p-name p-name-type-2']")
- 3.连接数据库并创建表
connect = pymssql.connect(host='localhost', user='chenshuo', password='cs031904104',
database='cs031904104', charset='UTF-8') # 连接到sql server数据库
cur = connect.cursor() # 创建操作游标
cur.execute("drop table scraf")
cur.execute(
"create table scraf"
" (mNo char(1000),mMark char(1000),mPrice char(1000),mNote char(1000),mFile char(1000) )")
cur = connect.cursor() # 创建操作游标
- 4.插入数据库
cur.execute(
"insert into scraf (mNo ,mMark ,mPrice ,mNote ,mFile ) values ('%s','%s','%s','%s','%s')" % (
str(num+1), name[0].text.replace("'"," ").replace("\n"," "), price[0].text.replace("'"," ").replace("\n"," "), note[0].text.replace("'"," ").replace("\n"," "), img[0].get_attribute('src')))
- 5.结果展示
![]()

心得体会
- 能够熟练使用selenum进行数据的爬取,复习了sql server数据库的相关操作。
作业②
-
要求:
熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+MySQL模拟登录慕课网,并获取学生自己账户中已学课程的信息保存到MySQL中(课程号、课程名称、授课单位、教学进度、课程状态,课程图片地址),同时存储图片到本地项目根目录下的imgs文件夹中,图片的名称用课程名来存储。 -
候选网站:中国mooc网:https://www.icourse163.org
-
输出信息:MYSQL数据库存储和输出格式
![]()

代码链接:https://gitee.com/chenshuooooo/data-acquisition/blob/master/作业5/作业2.py
实现过程
- 1.登入功能的实现
这部分通过模拟学习舍友的代码完成
(1)首先分析如何登入,点击登入按钮,然后点击其他登入方式
![]()

go=driver.find_elements_by_xpath("//div[@class='_3uWA6']")[0]
go.click()
##点击其他方式登录
go1=driver.find_elements_by_xpath("//div[@class='mooc-login-set-wrapper']/div[@class='mooc-login-set']/div[@class='ux-login-set-scan-code f-pr']/div[@class='ux-login-set-scan-code_ft']/span[@class='ux-login-set-scan-code_ft_back']")[0]
go1.click()
(2)点击手机号登入,输入手机号和密码
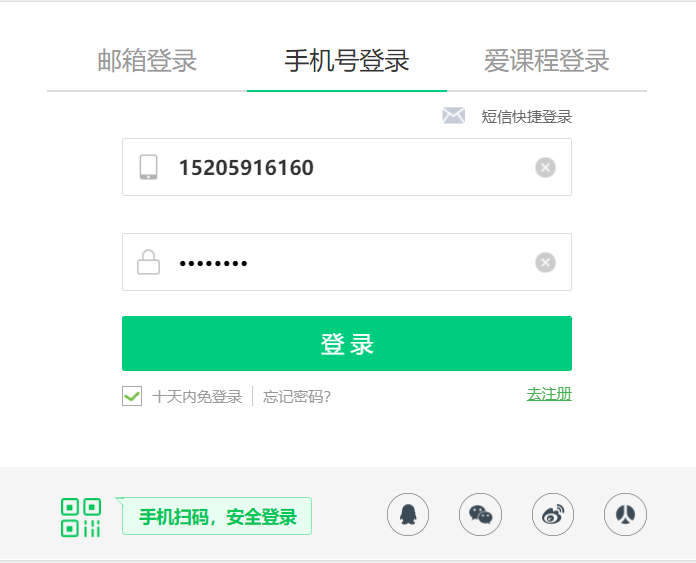
##点击手机号登录
go2=driver.find_elements_by_xpath("//div[@class='mooc-login-set-wrapper']/div[@class='mooc-login-set']/div[@class='ux-login-set-login-set-panel']/div[@class='login-set-panel']/div[@class='login-set-panel-login']/div[@class='ux-urs-login-urs-tab-login f-pr']/div[@class='ux-urs-login-urs-tabs']/div[@class='ux-tabs-underline']/ul[@class='ux-tabs-underline_hd']/li[2]")[0]
go2.click()
wait.until(
EC.frame_to_be_available_and_switch_to_it((By.XPATH, "//div[@class='ux-login-set-container']/iframe"))
)
##找到账号输入框,输入账号
loginname=driver.find_elements_by_xpath("//input[@type='tel']")[0]
loginname.send_keys('15205916160')
time.sleep(1)
##找到密码输入框,输入密码
password = driver.find_elements_by_xpath("//input[@type='password']")[1]
password.send_keys('cs031904104')
(3)登入成功后,这里可以忽略弹窗信息直接点击个人中心,进入要爬取的页面


go3 = driver.find_elements_by_xpath("//a[@target='_top']/span[@class='nav']")[2]
go3.click()
##等待页面内容加载
time.sleep(3)
- 2.爬取需要的信息
list=driver.find_elements_by_xpath("//div[@id='g-container']/div[@id='g-body']/div[@id='j-home-content']/div[@class='main-content f-cb']/div[@class='main-box f-fl']/div[@id='j-module-box']/div/div[@class='g-flow f-cb']/div[@class='g-mn2']/div[@class='g-mn2c']/div[@class='m-mcdoc']/div[@id='j-cnt1']/div[@id='j-coursewrap']/div[@class='course-panel-wrapper']/div[@class='course-panel-body-wrapper']/div[@class='course-card-wrapper']")
for i in list:
name= i.find_elements_by_xpath("./div[@class='box']/a[@class='ga-click']/div[@class='body']/div[@class='common-info-wrapper common-info-wrapper-fix-height']/div[@class='title']/div[@class='text']/span[@class='text']")[0]
school=i.find_elements_by_xpath("./div[@class='box']/a[@class='ga-click']/div[@class='body']/div[@class='common-info-wrapper common-info-wrapper-fix-height']/div[@class='school']/a")[0]
learn=i.find_elements_by_xpath("./div[@class='box']/a[@class='ga-click']/div[@class='body']/div[@class='personal-info']/div[@class='course-progress']/div[@class='status']/div[@class='text']/a/span[@class='course-progress-text-span']")[0]
status=i.find_elements_by_xpath("./div[@class='box']/a[@class='ga-click']/div[@class='body']/div[@class='personal-info']/div[@class='course-status']")[0]
url=i.find_elements_by_xpath("./div[@class='box']/a")[0]
- 3.数据库相关操作
connect = pymssql.connect(host='localhost', user='chenshuo', password='cs031904104',
database='cs031904104', charset='UTF-8') # 连接到sql server数据库
cur = connect.cursor() # 创建操作游标
cur.execute(
"create table mooc"
" (bCourse char(1000),bCollege char(1000),bSchedule char(1000),bCourseStatus char(1000),bImgUrl char(1000) )")
cur = connect.cursor() # 创建操作游标
connect.commit() # 提交命令
cur.execute(
"insert into mooc (bCourse,bCollege ,bSchedule ,bCourseStatus ,bImgUrl )values ('%s','%s','%s','%s','%s')" % (
name.text, school.text.replace("'", " ").replace("\n", " "),
learn.text.replace("'", " ").replace("\n", " "),
status.text.replace("'", " ").replace("\n", " "), status.text,url.get_attribute('href')))
- 4.结果展示
![]()
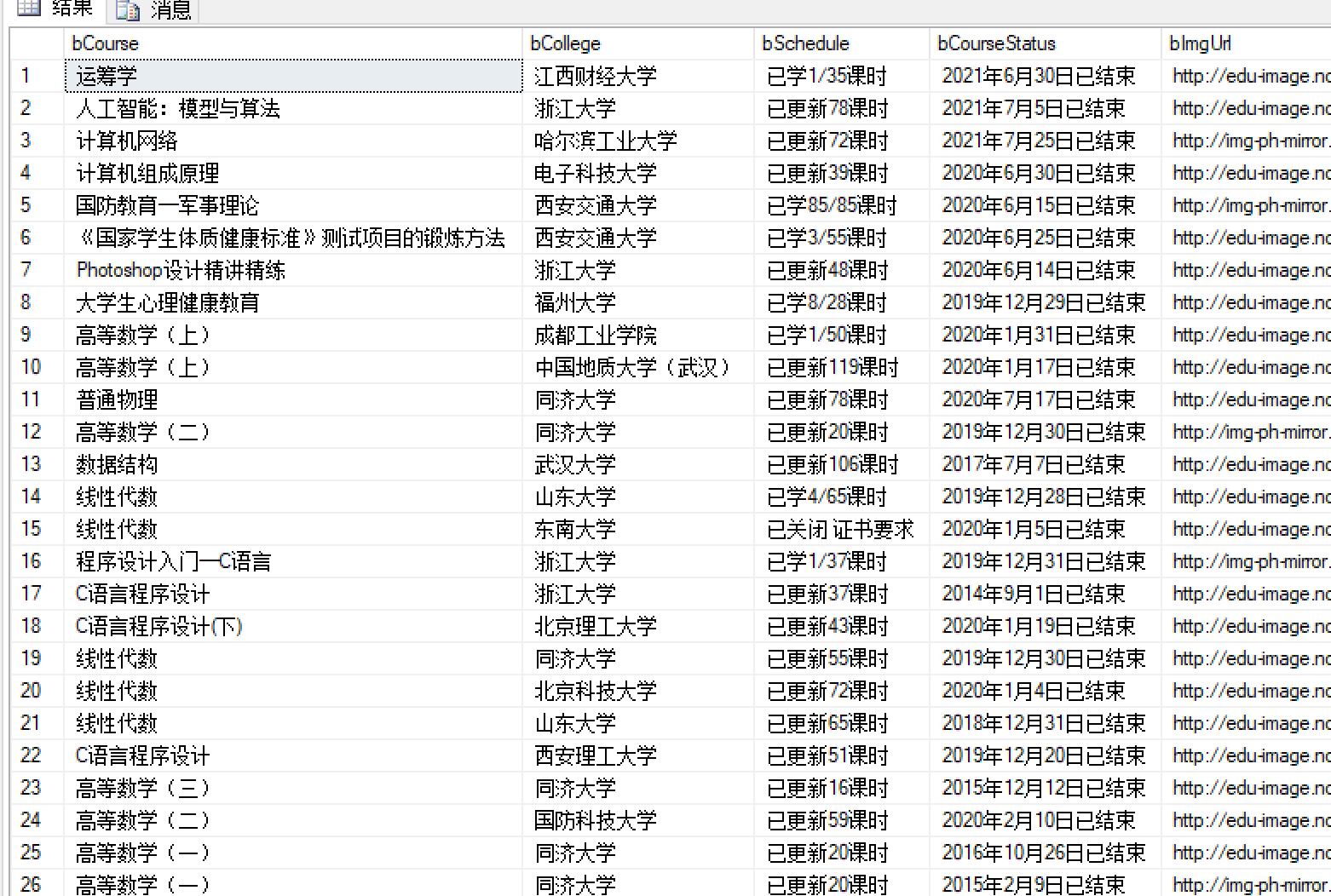
心得体会
- 通过学习并理解同学的代码,了解学习掌握了使用selenium的登入操作。
作业③
- 要求:掌握大数据相关服务,熟悉Xshell的使用
- 完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。-
- 环境搭建
任务一:开通MapReduce服务
实时分析开发实战:
任务二:Python脚本生成测试数据
任务三:配置Kafka
任务四:安装Flume客户端
任务五:配置Flume采集数据
实现过程
- (1)任务一:开通MapReduce服务
![]()
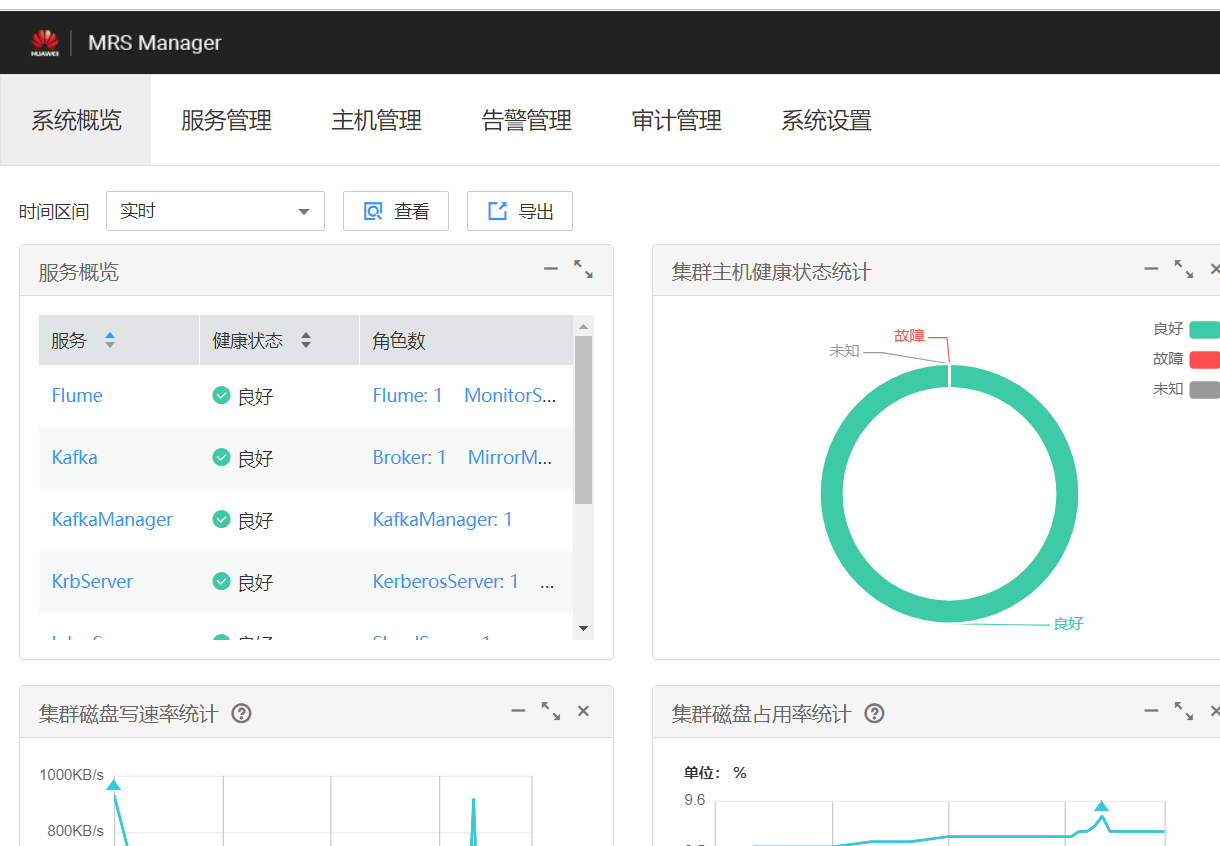
- (2)任务二:Python脚本生成测试数据

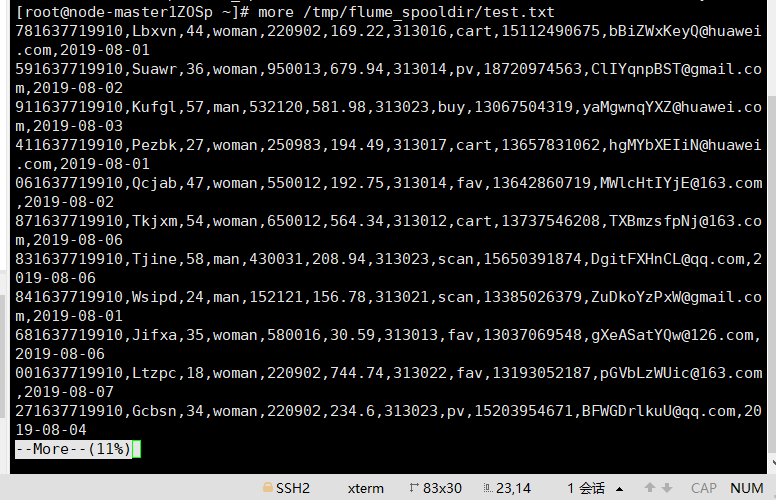
- (3)任务三:配置Kafka
![]()


-
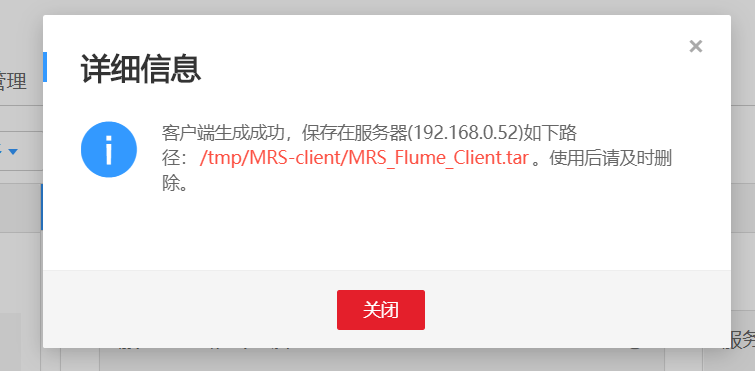
(4)任务四:安装Flume客户端
-
步骤一:下载Flume客户端
![]()
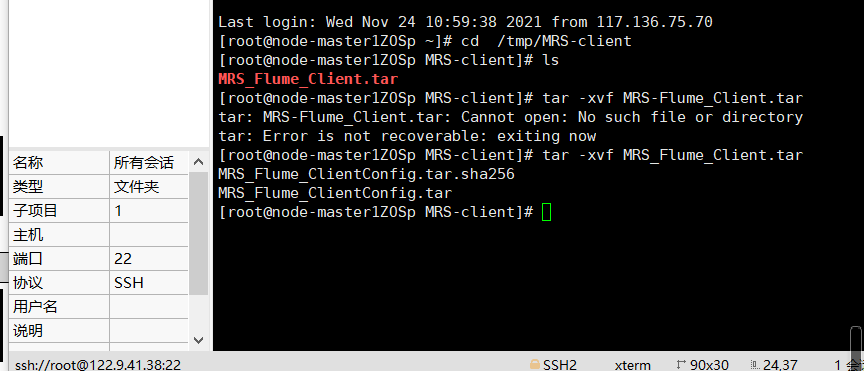
-
步骤二:解压下载的客户端文件
![]()
-
步骤三:校验文件包,校验成功
![]()
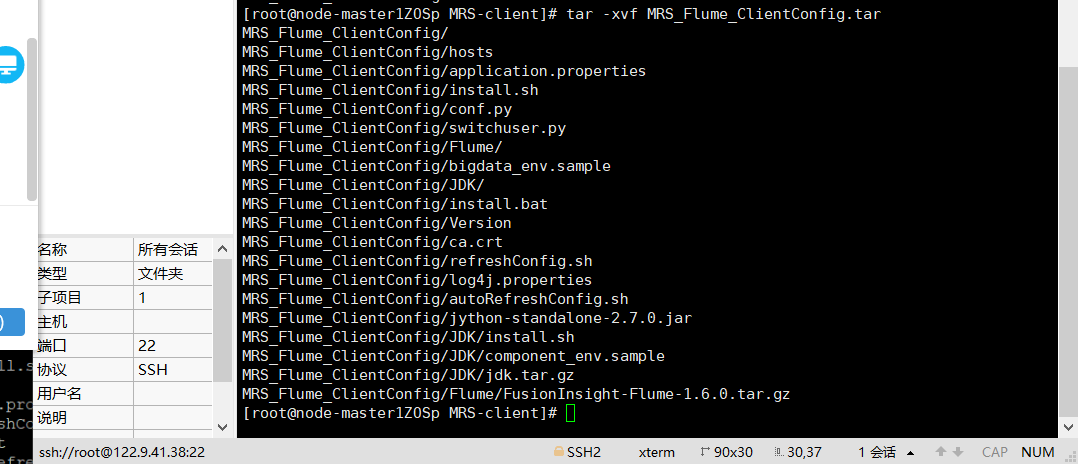
-
步骤四:解压“MRS_Flume_ClientConfig.tar”文件
![]()
-
步骤五:安装Flume环境变量
客户端运行环境安装成功
![]()
配置环境变量
![]()
-
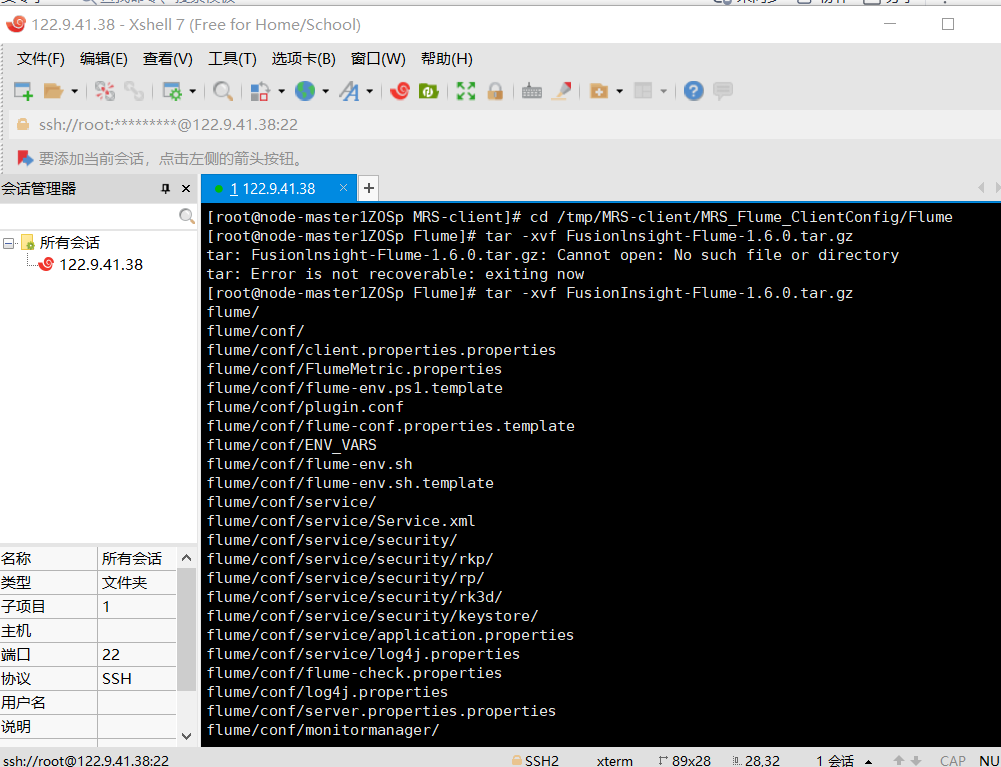
步骤六:解压Flume客户端
![]()
-
步骤七:安装Flume客户端
![]()
-
步骤八:重启Flume服务
![]()
-
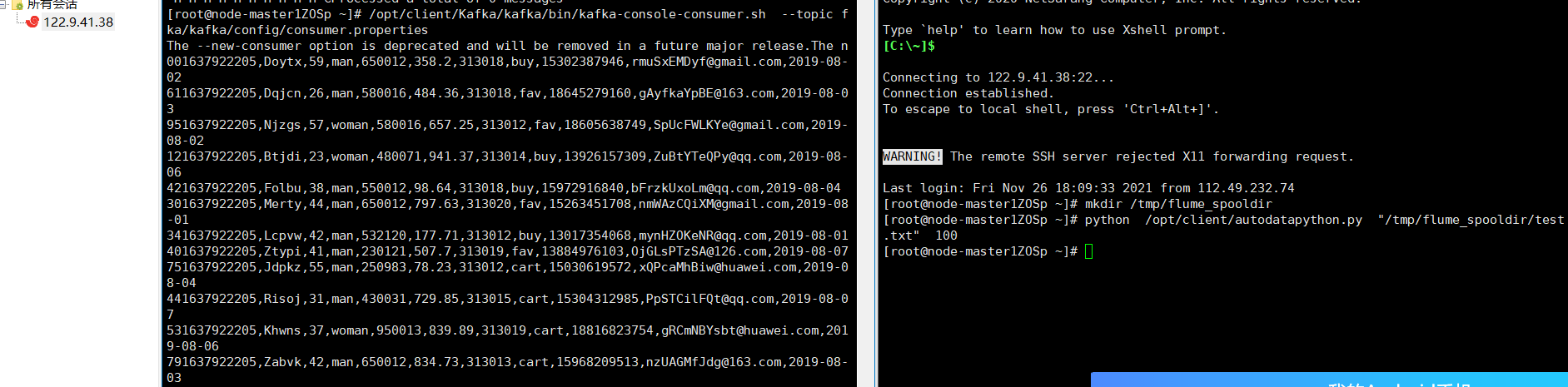
(5)任务五:配置Flume采集数据





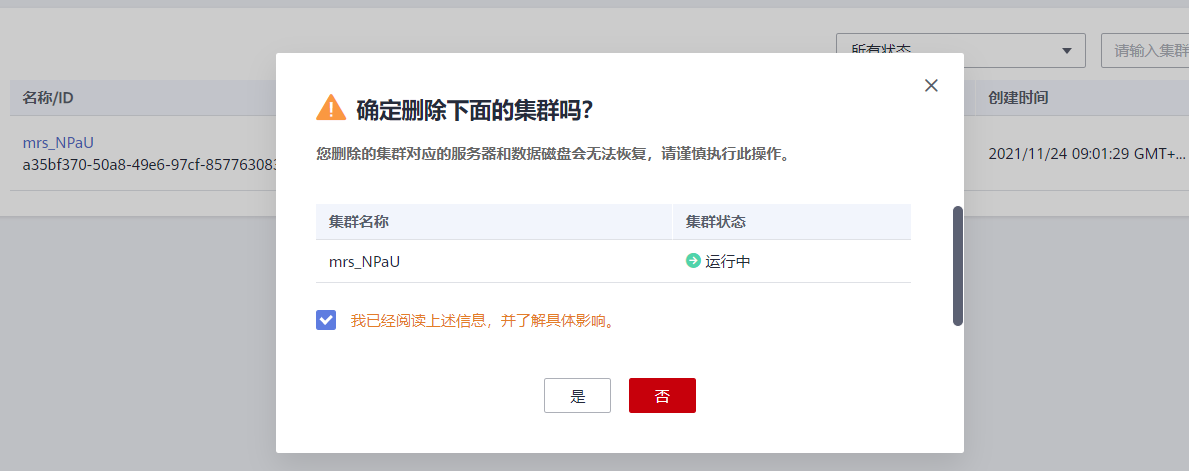
- (6)最后进行云资源的释放
![]()

心得体会
- 学习相关华为云平台的操作,了解了Flume日志采集服务,学习了xshell7以及xftp7的用法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号