数据采集第二次大作业
数据采集第二次大作业
作业①
- 要求:在中国气象网(http://www.weather.com.cn)爬取给定城市集的七日天气预报,并保存在数据库。
- 输出信息:作业①代码链接:https://gitee.com/chenshuooooo/data-acquisition/blob/master/%E4%BD%9C%E4%B8%9A2/1.py
| 序号 | 地区 | 日期 | 天气信息 | 温度 |
|---|---|---|---|---|
| 1 | 北京 | 七日(今天) | 晴间多云,北部山区有阵雨或雷阵雨转晴转多云 | 31℃/17℃ |
| 2 | 北京 | 八日(明天) | 多云转晴,北部地区有分散阵雨或雷阵雨转晴 | 34℃/20℃ |
| ... |
一.实现过程
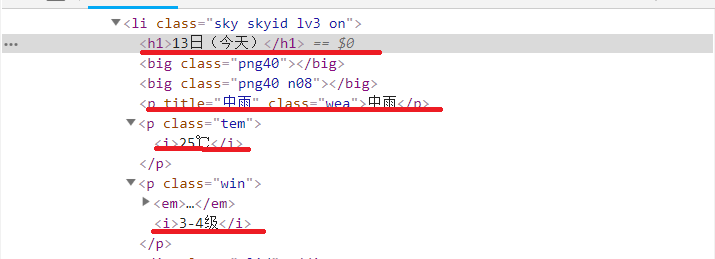
- 1.打开网址,分析要爬取的信息,可以找到要爬取信息对应的属性。
![]()
- 2.使用CSS进行页面解析,并获取和打印需要的信息
url = "http://www.weather.com.cn/weather/" + self.cityCode[city] + ".shtml"
try:
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
lis = soup.select("ul[class='t clearfix'] li")
for li in lis:
try:
date = li.select('h1')[0].text
weather = li.select('p[class="wea"]')[0].text
temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text
print('{:^20}{:^20}{:^20}{:^20}'.format(city, date, weather, temp))
self.db.insert(city, date, weather, temp)
except Exception as err:
pass
#print(err)
except Exception as err:
print(err)
- 3 导入sqlite3包,创建数据库以及实现插入爬取的数据
def openDB(self):
self.con = sqlite3.connect("weathers.db")
self.cursor = self.con.cursor()
try:
self.cursor.execute(
"create table weathers (wCity varchar(16),wDate varchar(16),wWeather varchar(64),wTemp varchar(32),constraint pk_weather primary key (wCity,wDate))")
except:
self.cursor.execute("delete from weathers")
def insert(self, city, date, weather, temp):
try:
self.cursor.execute("insert into weathers (wCity,wDate,wWeather,wTemp) values (?,?,?,?)",
(city, date, weather, temp))
except Exception as err:
print(err)
- 4.运行结果如下

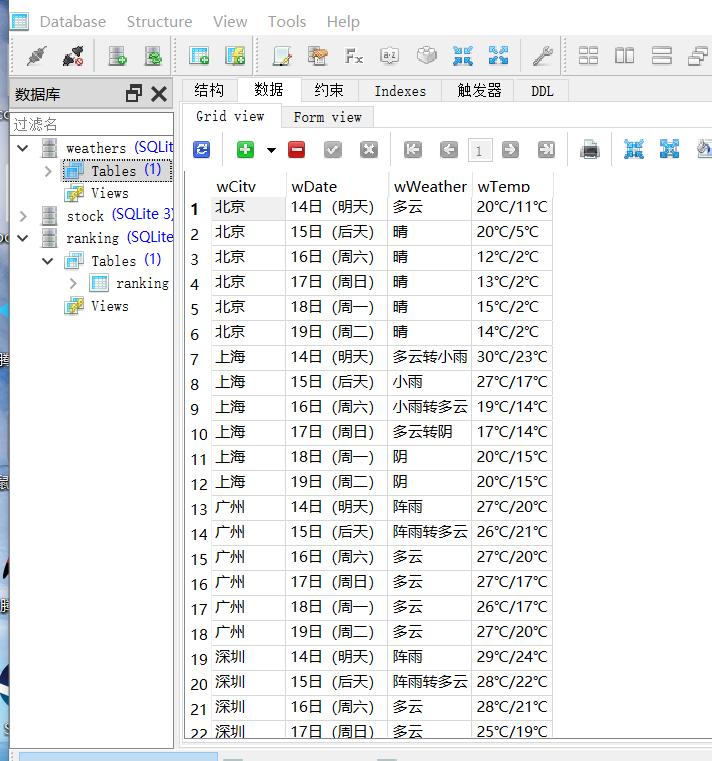
-5.下载SQLitStudio来打开创建的数据库weather.db,并查看表weather,截图如下
二.心得体会
- 初步学习了如何使用sqlite包进行数据库的相关操作。
- 加深了对bs4的掌握
作业②
- 要求:用requests和自选提取信息方法定向爬取股票相关信息,并存储在数据库中。
- 候选网站:东方财富网:https://www.eastmoney.com/
新浪股票:http://finance.sina.com.cn/stock/ - 技巧:在谷歌浏览器中进入F12调试模式进行抓包,查找股票列表加载使用的url,并分析api
返回的值,并根据所要求的参数可适当更改api的请求参数。根据URL可观察请求的参数f1、
f2可获取不同的数值,根据情况可删减请求的参数。
参考链接:https://zhuanlan.zhihu.com/p/50099084 - 输出信息:作业②代码链接:https://gitee.com/chenshuooooo/data-acquisition/blob/master/%E4%BD%9C%E4%B8%9A2/2.py
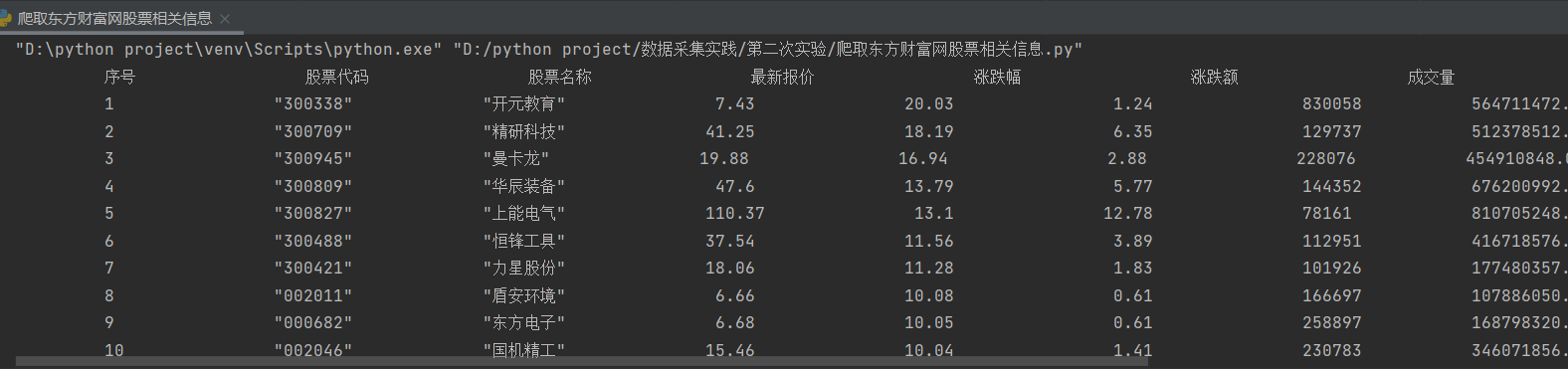
| 序号 | 股票代码 | 股票名称 | 最新报价 | 涨跌幅 | 涨跌额 | 成交量 | 成交额 | 振幅 | 最高 | 最低 | 今开 | 昨收 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 688093 | N世华 | 28.47 | 62.22% | 10.92 | 26.13万 | 7.6亿 | 22.3% | 32.0 | 28.08 | 30.2 | 17.55 |
| ... |
一.实现过程
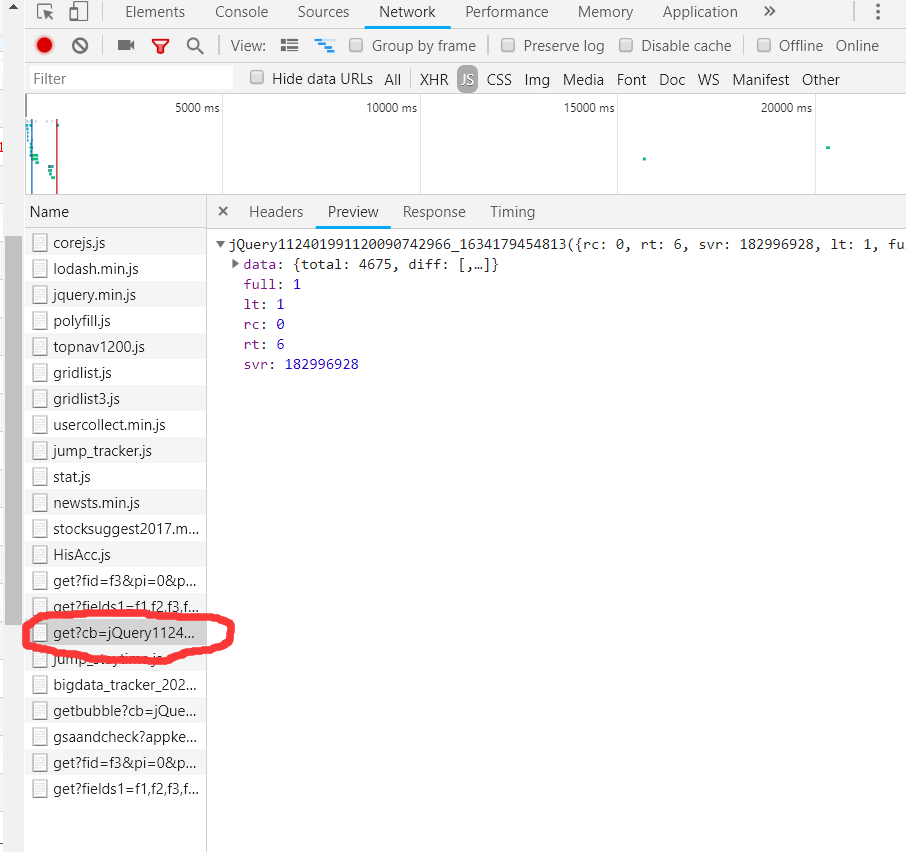
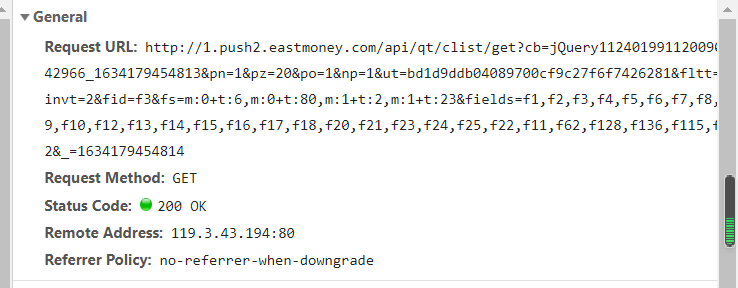
- 1.打开东方财富网,按下f12查看页面源代码,在network中寻找包含股票信息的js包,找到其头部url信息。

- 2.通过分析包信息构建正则表达式
f2 = '"f2":(.*?),'
f14 = '"f14":(.*?),'
f3 = '"f3":(.*?),'
f4 = '"f4":(.*?),'
f5 = '"f5":(.*?),'
f12 = '"f12":(.*?),'
f6 = '"f6":(.*?),'
f7 = '"f7":(.*?),'
f15 = '"f15":(.*?),'
f16 = '"f16":(.*?),'
f17 = '"f17":(.*?),'
f18 = '"f18":(.*?),'
- 3.结果print输出以及存储到数据库中
while i<20:
cursor.execute("insert into stock (sorder ,sno,sname ,snewprice,sincreaserate ,sincreasenum ,sdealcount ,sdealnum ,schangerate ,smax ,smin ,stodayprice ,syesterday) values (?,?,?,?,?,?,?,?,?,?,?,?,?)",(i,list2[i],list3[i],list4[i],list5[i],list6[i],list7[i],list8[i],list9[i],list10[i],list11[i],list12[i],list13[i]))
print('{:^20}{:^20}{:^20}{:^20}{:^20}{:^20}{:^20}{:^20}{:^20}{:^20}{:^20}{:^20}{:^20}'.format(i,list2[i],list3[i],list4[i],list5[i],list6[i],list7[i],list8[i],list9[i],list10[i],list11[i],list12[i],list13[i]))
i = i+1
- 4.结果截图
![]()
二.心得体会
- 加深了对sqlite3包的使用
- 了解并尝试了通过抓包爬取数据。
作业③
- 要求:爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021) 所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。
- 技巧:分析该网站的发包情况,分析获取数据的api
- 输出信息:作业③代码链接:https://gitee.com/chenshuooooo/data-acquisition/blob/master/%E4%BD%9C%E4%B8%9A2/3.py
| 排名 | 学校 | 总分 |
|---|---|---|
| 1 | 清华大学 | 969.2 |
一.实现过程
-
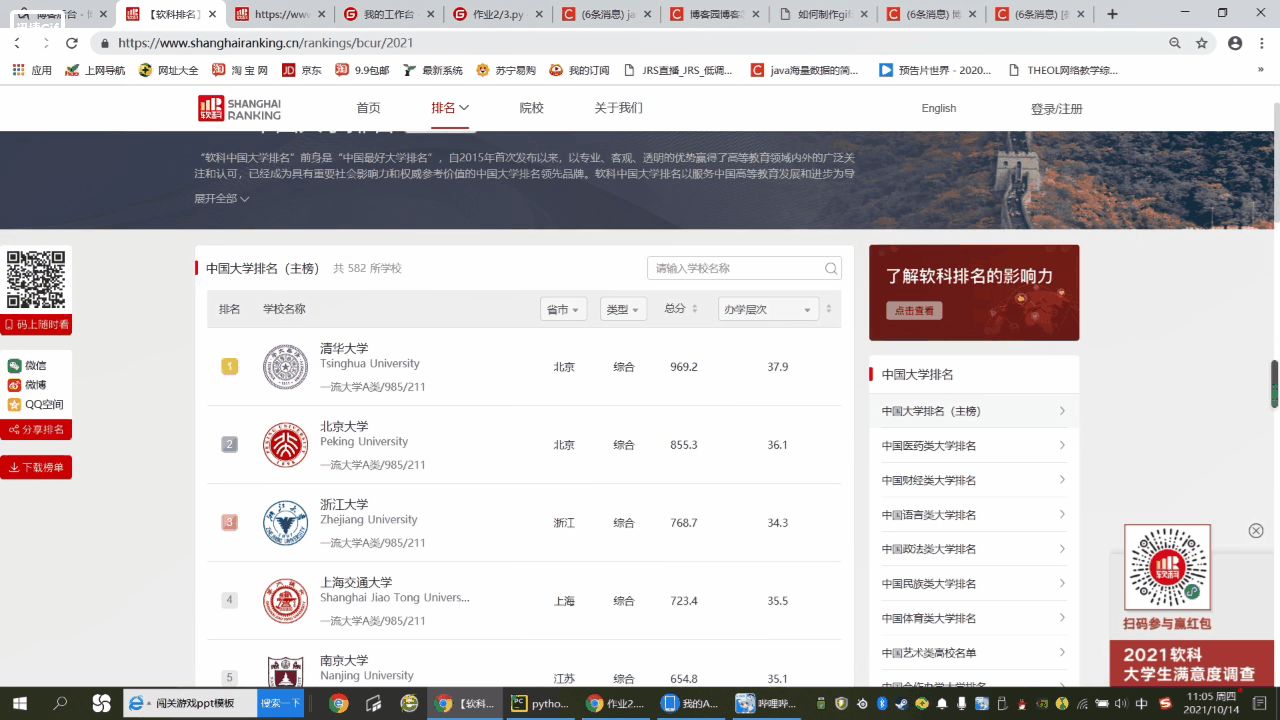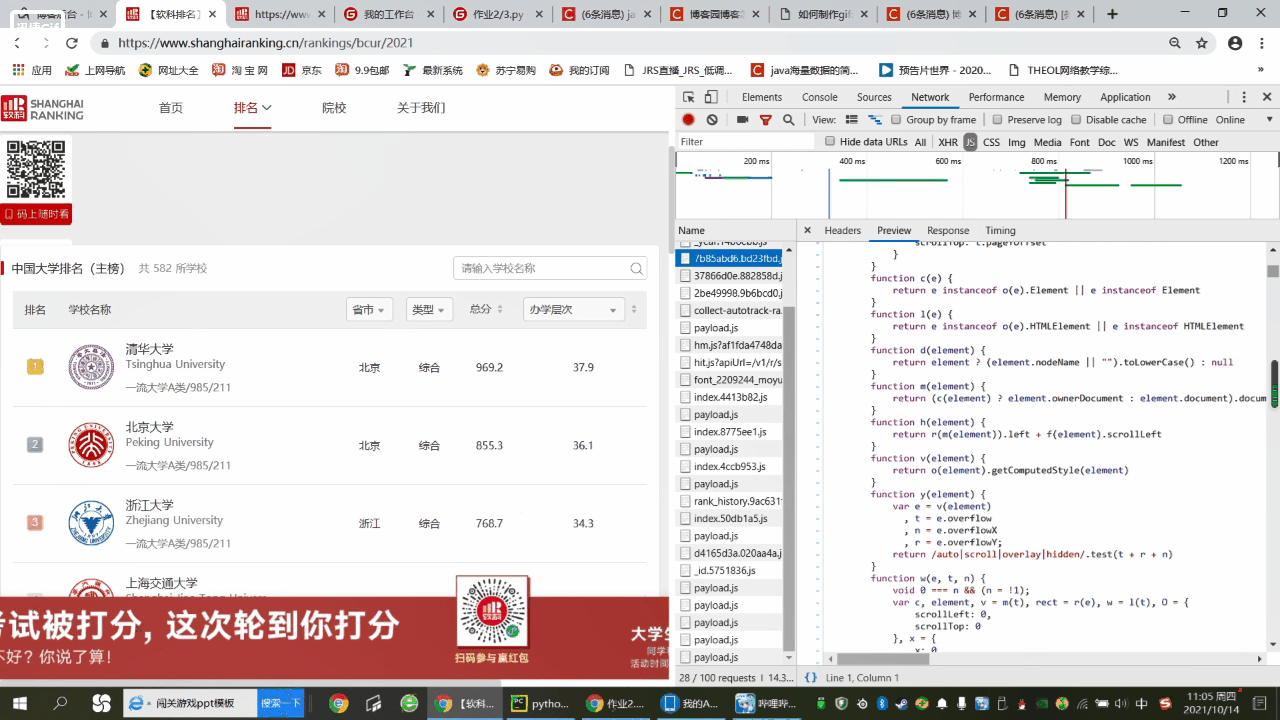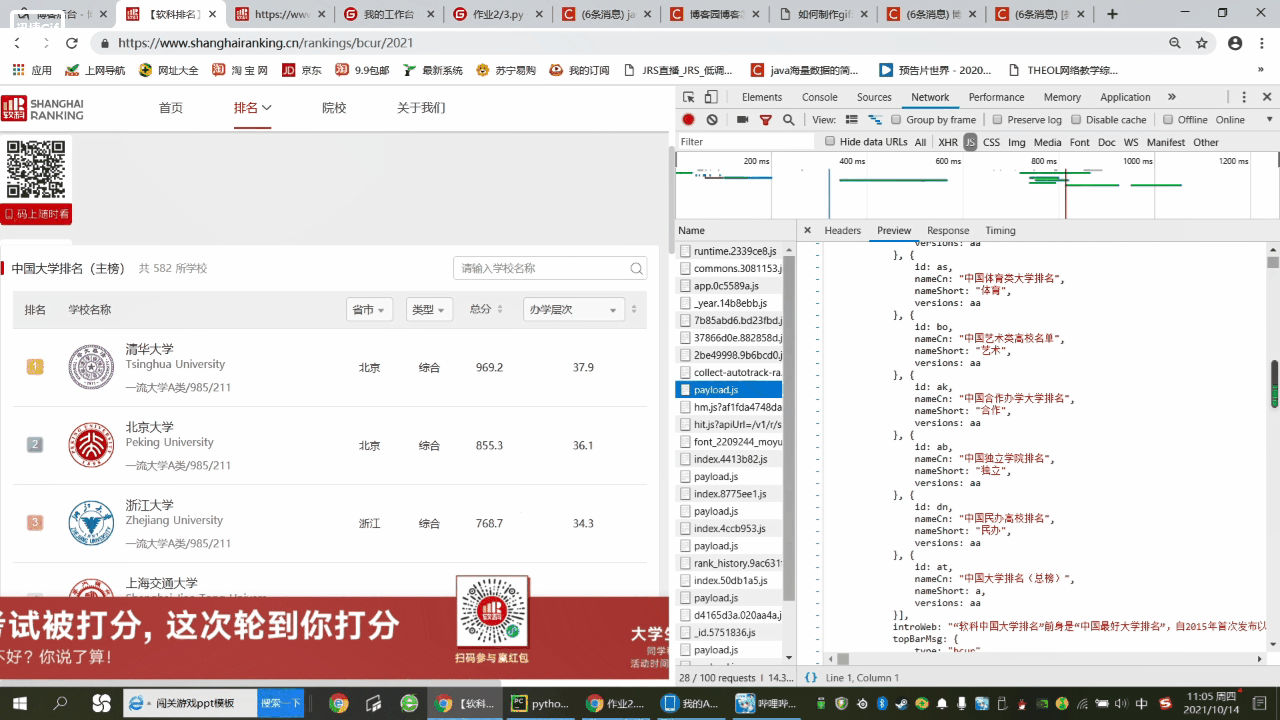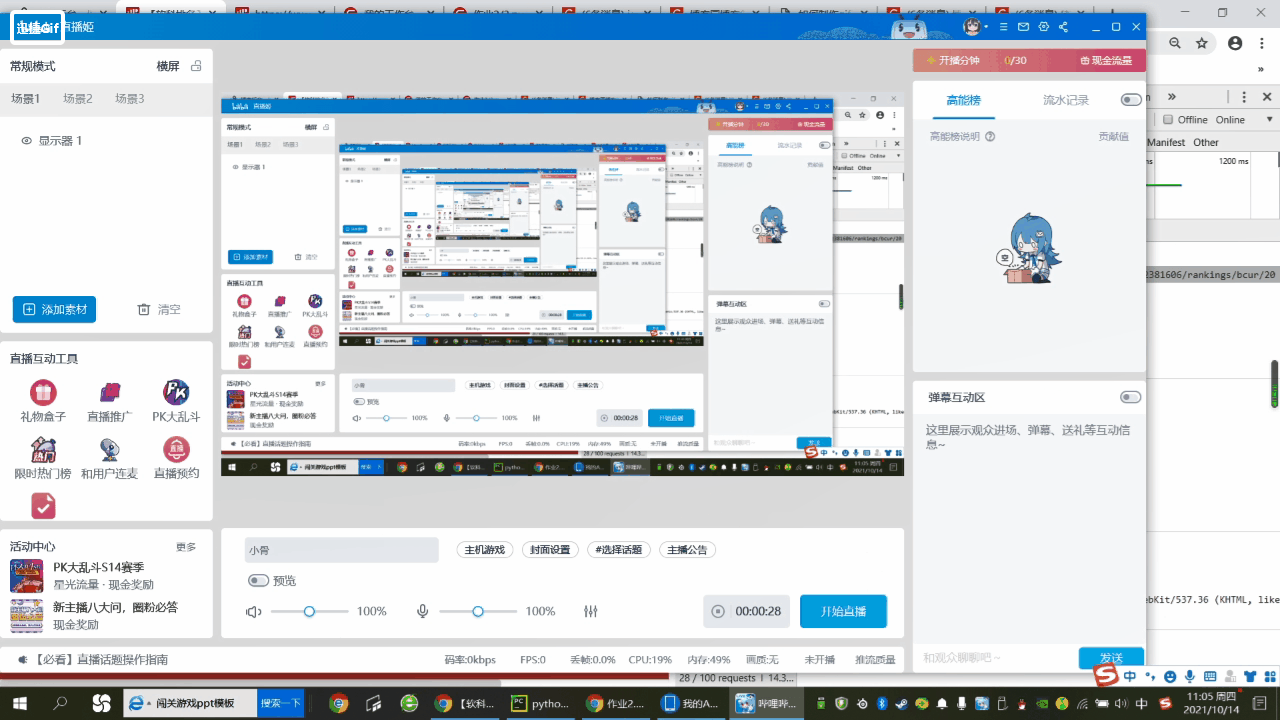
1.打开要爬取的网站,按下f12,寻找要爬取信息对应的js包,以下为f12调试过程gif动图。
![]()
-
2.得到js包的URL地址后,对其进行解析
url = 'https://www.shanghairanking.cn/_nuxt/static/1632381606/rankings/bcur/2021/payload.js'
req = urllib.request.Request(url)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data,["utf-8",'gbk'])
data=dammit.unicode_markup
- 3.构造正则表达式
s1='univNameCn:"(.*?)"'
#匹配大学名称
s2=',score:(.*?),'
#匹配总分
name = re.findall(s1,data)
score = re.findall(s2,data)
- 4.输出结果即将数据插入数据库
cursor.execute("insert into ranking.ranking (rno,rname,rscore) values (?,?,?)",(i+1,name[i],score[i]))
print('{:^20}{:^20}{:^20}'.format(i+1,name[i],score[i]))
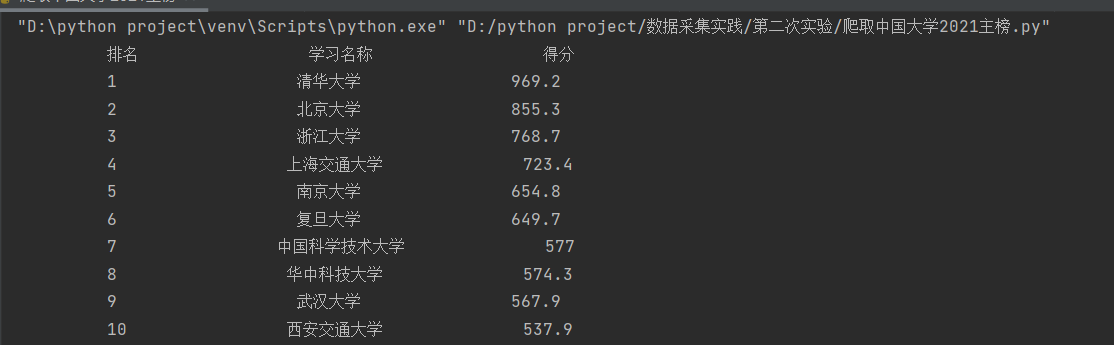
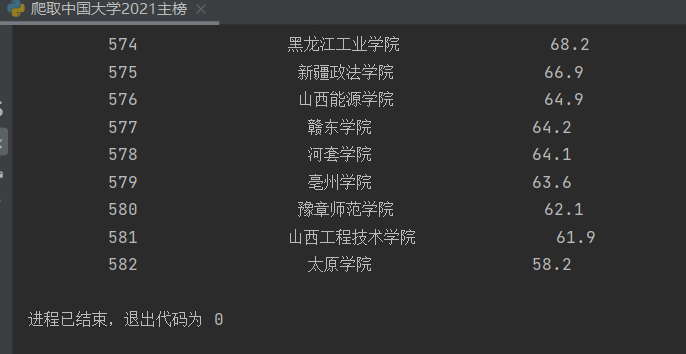
- 5.结果截图
![]()
![]()
二.心得体会
- 加深巩固了通过抓包进行爬取数据的方法,感觉简便很多
- 更加熟练正则表达式的构造

 浙公网安备 33010602011771号
浙公网安备 33010602011771号