数据采集第一次大作业
数据采集第一次大作业
作业①
- 要求:用urllib和re库方法定向爬取给定网址(https://www.shanghairanking.cn/rankings/bcsr/2020/0812 )的数据。
- 输出信息:
| 2020排名 | 全部层次 | 学校名称 | 总分 |
|---|---|---|---|
| 1 | 前%2 | 中国人民大学 | 1069.0 |
| 2....... |
一.实现过程
- 作业①代码链接
https://gitee.com/chenshuooooo/data-acquisition/blob/master/作业1/1.py - 1.首先打开要爬取的网址,选择查看页面源代码,分析要爬取的信息

- 2.根据元素写出合适的正则表达式来爬取对应的信息,部分实现代码如下
s1='<div class="ranking" data-v-68e330ae>(.*?)</div>'
ans1=re.findall(s1,data)
s2='</span></td><td data-v-68e330ae>(.*?)<!----></td><td class="align-left" data-v-68e330ae>'
ans2=re.findall(s2,data)
s3='class="name-cn" data-v-b80b4d60>(.*?) </a> <div class="collection"'
ans3=re.findall(s3,data)
s4='</div></div> <!----> <!----> <!----> <!----></div></div></td><td data-v-68e330ae>(.*?)</td></tr>'
ans4=re.findall(s4,data)
-
3.将爬取结果格式化输出,部分代码如下
print('{:<30}{:<30}{:<30}{:<30}'.format(a,b,c,d)) -
4.输出结果截图如下
![]()
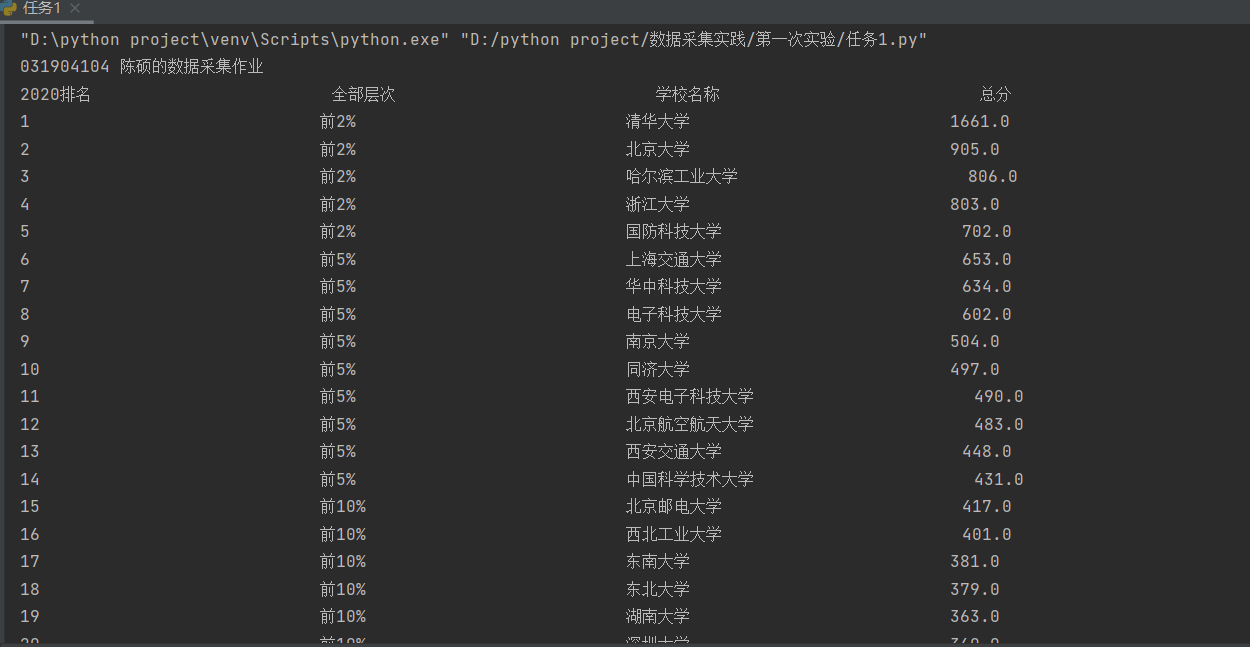
二.心得体会
- 在作业一中遇到的主要问题就是如何去写正则表达式,主要是没有考虑到换行符。
- 了解并学习了非贪婪匹配的写法
- 加深了对re库的使用
作业②
- 要求:用requests和Beautiful Soup库方法设计爬取https://datacenter.mee.gov.cn/aqiweb2/ AQI实时报。
- 输出信息:
| 序号 | 城市 | AQI | PM2.5 | SO2 | NO2 | CO | 首要污染物 |
|---|---|---|---|---|---|---|---|
| 1 | 北京 | 55 | 6 | 5 | 1.0 | 225 | - |
| 2...... |
一.实现过程
- 作业②代码链接
https://gitee.com/chenshuooooo/data-acquisition/blob/master/作业1/2.py - **1.打开要爬取的网页,打开检测页面源代码,分析要爬取的信息,找到对应的元素。
![]()
- 2.根据分析的信息构造正则表达式,分析得到要爬取的信息都在下(id='legend_02_table'为日报的标签,01是实时报),从而构造正则表达式,代码如下。

soup = BeautifulSoup(data, 'lxml')
#print(soup)
tags = soup.select("tbody[id='legend_01_table'] tr td")
- 3.将爬取结果格式化输出,代码截图如下
for tag in tags:
a[i]=tag.text.replace("\t","")
i+=1
count=0
print('{:<10}{:<10}{:<10}{:<10}{:<10}{:<10}{:<10}{:<10}{:<10}'.format('城市','AQI','PM2.5','PM10','SO2','NO2','CO','O3','首要污染物'))#对输出进行格式化处理
while count<len(a):
print('{:<10}{:<10}{:<10}{:<10}{:<10}{:<10}{:<10}{:<10}{:<10}'.format(a[count],a[count+1],a[count+2],a[count+3],a[count+4],a[count+5],a[count+6],a[count+7],a[count+8].replace(" ","")))
count=count+9
最后一项首要污染物有格式错误,我试了去掉换行符,空格,制表符等等,最后一项主要污染物格式还是有错误,后面就没弄了。。。
- 输出结果截图
![]()

二.心得体会
-之前几次作业都有涉及到bs4库的使用,所以这题相对而言比较容易做,没有遇到太大的问题
-没有弄清楚爬取的主要污染物信息的格式,导致主要污染物无法输出格式化
作业③
- 要求:使用urllib和requests爬取(http://news.fzu.edu.cn/),并爬取该网站下的所有图片
- 输出信息:将网页内的所有图片文件保存在一个文件夹中
一.实现过程
- 作业三代码链接
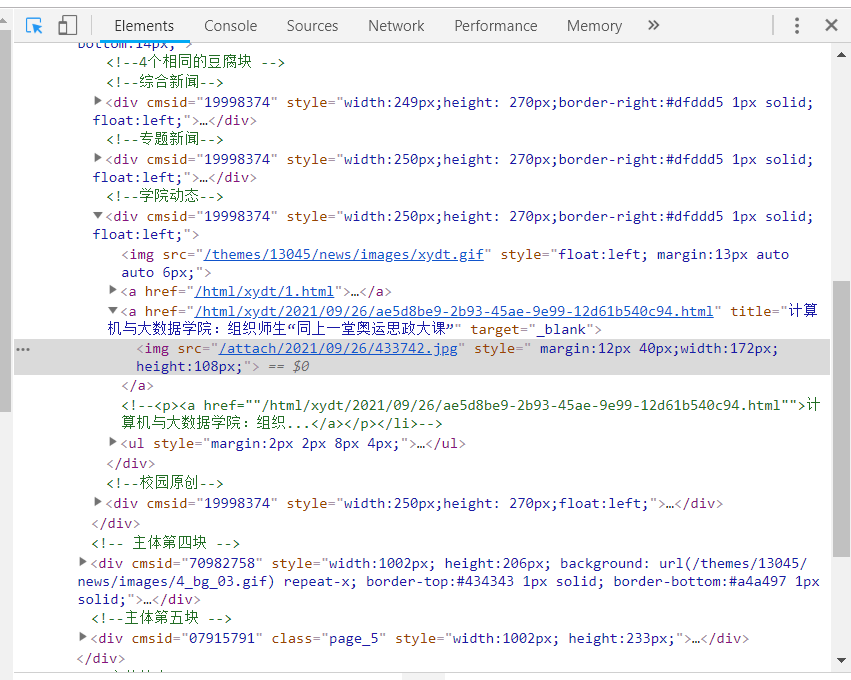
https://gitee.com/chenshuooooo/data-acquisition/blob/master/作业1/3.py - 1.打开要爬取的网页,打开f12,定位到图片查看对应的元素。
![]()
- 2.通过f12分析可得,图片元素都有img,于是通过这个构造正则表达式,代码如下。
s='<img src=\"(.*?)\".*?>'
src=re.findall(s,data)
- 3.爬取结果如下
![]()

二.心得体会
- 我是用re库爬取的信息,遇到的问题还是在正则表达式的构造,我在正则测试网站下可以匹配到要匹配的信息,但是用re.findall()方法就不行,后面在正则里加了两个引号就行(图片地址前后的引号)
![]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号