
理解爬虫原理
1. 简单说明爬虫原理
程序模拟浏览器送请求来获取网页代码,提取出有用的数据,储存起来。
2. 理解爬虫开发过程
1).简要说明浏览器工作原理;
浏览器提交请求--->下载网页代码--->解析成页面
2).使用 requests 库抓取网站数据;
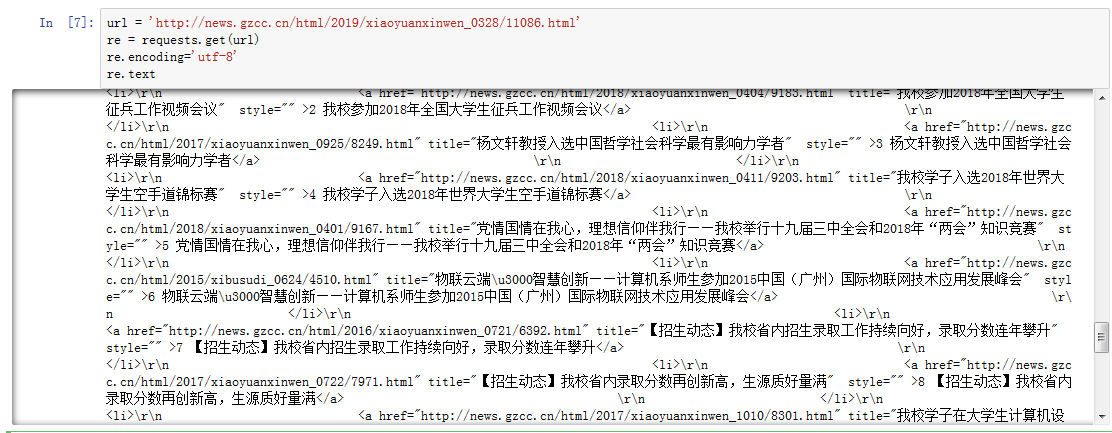
requests.get(url) 获取校园新闻首页html代码
import requests url = 'http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0328/11086.html' re = requests.get(url) re.encoding='utf-8'
3).了解网页
写一个简单的html文件,包含多个标签,类,id
<html>
<body>
<h1 id="title">hi</h1>
<a href="#" class="link"> This is link1</a>
<a href="# link2" class="link" qao=123> This is link2</a>
</body>
</html>
4).使用 Beautiful Soup 解析网页;
通过BeautifulSoup(html_sample,'html.parser')把上述html文件解析成DOM Tree
import bs4 from bs4 import BeautifulSoup soup = BeautifulSoup(re.text,"html.parser")
select(选择器)定位数据
找出含有特定标签的html元素
找出含有特定类名的html元素
找出含有特定id名的html元素
# 标题
soup.title.text.split()[0]
# 作者
soup.select('.show-info')[0].text.split()[2].split(':')[1]
# 出处
soup.select('.show-info')[0].text.split()[4].split(':')[1]
3.提取一篇校园新闻的标题、发布时间、发布单位、作者、点击次数、内容等信息
如url = 'http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0320/11029.html'
要求发布时间为datetime类型,点击次数为数值型,其它是字符串类型。
标题:
# 标题 soup.title.text.split()[0]

发布时间:
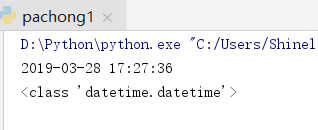
from datetime import datetime
year=soup.select('.show-info')[0].text.split()[0].split(':')[1]
time = soup.select('.show-info')[0].text.split()[1]
jx=year+' '+time
cday = datetime.strptime(jx, '%Y-%m-%d %H:%M:%S')
发布单位:
soup.select('.show-info')[0].text.split()[4].split(':')[1]

作者:
# 作者
soup.select('.show-info')[0].text.split()[2].split(':')[1]

点击次数:
num = requests.get('http://oa.gzcc.cn/api.php?op=count&id=11086&modelid=80')
print (int(num.text.split('.html')[-1].split('\'')[1]))

内容:
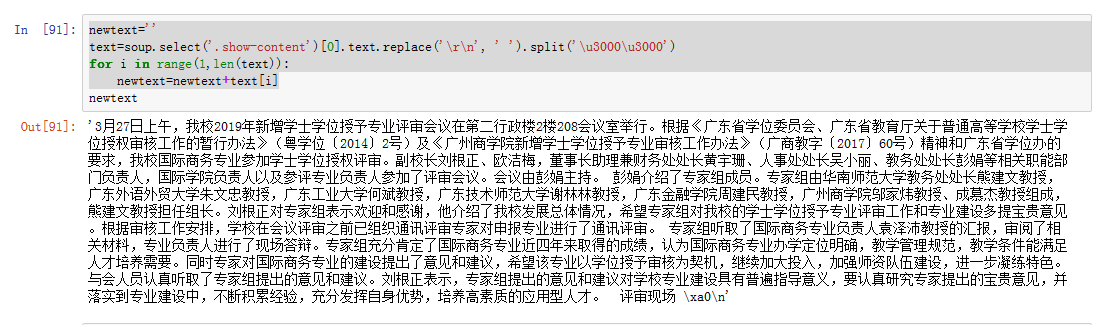
newtext=''
text=soup.select('.show-content')[0].text.replace('\r\n', ' ').split('\u3000\u3000')
for i in range(1,len(text)):
newtext=newtext+text[i]
代码:
from bs4 import BeautifulSoup
import requests
from datetime import datetime
url = 'http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0328/11086.html'
re = requests.get(url)
re.encoding='utf-8'
soup = BeautifulSoup(re.text,"html.parser")
soup.select('img')[1]['src']
year=soup.select('.show-info')[0].text.split()[0].split(':')[1]
time = soup.select('.show-info')[0].text.split()[1]
jx=year+' '+time
cday = datetime.strptime(jx, '%Y-%m-%d %H:%M:%S')
# 标题
title=soup.title.text.split()[0]
# 作者
zz=soup.select('.show-info')[0].text.split()[2].split(':')[1]
# 出处
cc=soup.select('.show-info')[0].text.split()[4].split(':')[1]
newtext=''
text=soup.select('.show-content')[0].text.replace('\r\n', ' ').split('\u3000\u3000')
for i in range(1,len(text)):
newtext=newtext+text[i]
num = requests.get('http://oa.gzcc.cn/api.php?op=count&id=11086&modelid=80')
print('标题:'+title+'\n作者:'+zz+'\n出处:'+cc+
'\n次数:'+num.text.split('.html')[-1].split('\'')[1]+
'\n时间:'+jx+'\n内容:'+newtext)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号