
Scrapy爬虫框架-如何快速了解与上手
一、Scrapy框架结构图:
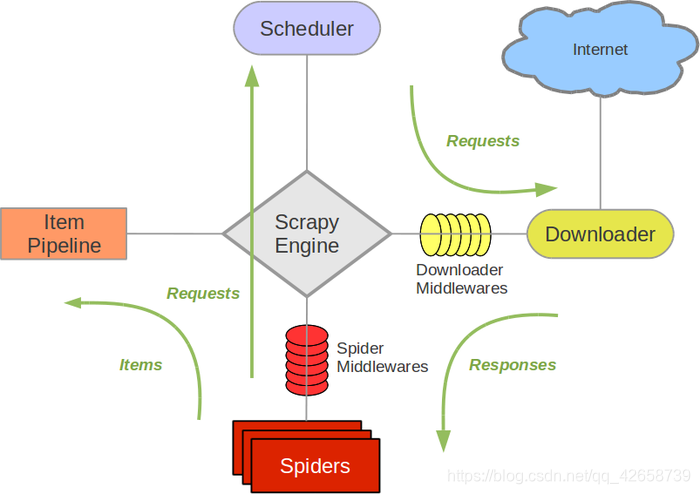
组件含义解释:
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器).
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
Downloader Middlewares(下载中间件):可以当作是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
二、Scrapy的运作流程:(写好代码之后,程序的运行步骤)
只有当调度器中不存在任何request了,整个程序才会停止,(也就是说,对于下载失败的URL,Scrapy也会重新下载。)
三、制作Scrapy爬虫的一般思路:
新建项目 (scrapy startproject xxx):新建一个新的爬虫项目
明确目标 (编写items.py):明确你想要抓取的目标
制作爬虫 (spiders/xxspider.py):制作爬虫开始爬取网页
存储内容 (pipelines.py):设计管道存储爬取内容
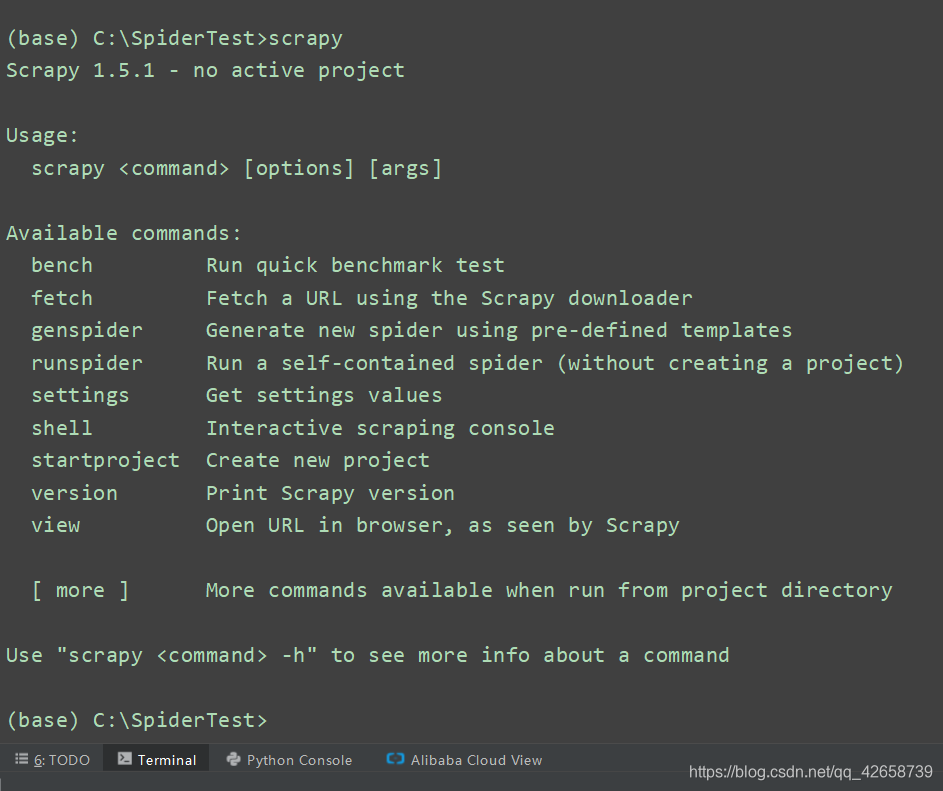
四、Scrapy爬虫框架的常用shell命令以及目录结构:
在命令行终端中输入scrapy即可弹出关于Scrapy爬虫 shell命令的命令列表:
-
scrapy startproject mySpider 其中mySpider是Scrapy爬虫项目名称,自己定义。
之后可以看到其目录结构为:
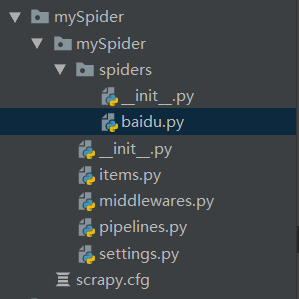
文件目录结构解释:
scrapy.cfg: 项目的配置文件。
mySpider/: 项目的Python模块,将会从这里引用代码。
mySpider/items.py: 项目的目标文件。
mySpider/pipelines.py: 项目的管道文件。
mySpider/settings.py: 项目的设置文件。
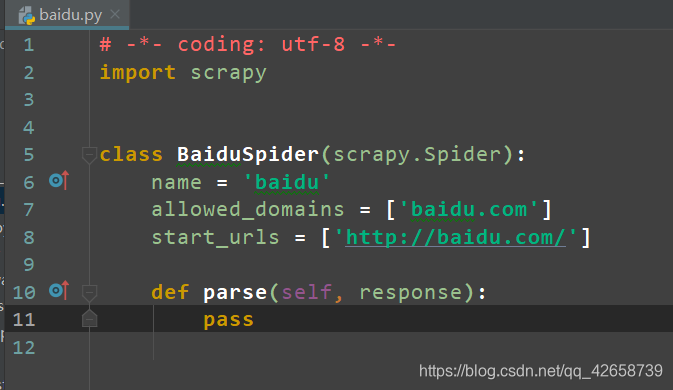
mySpider/spiders/: 存储爬虫代码的目录,具体的分析网站结构代码以及反爬会在这里编写,执行scrapy genspider baidu "baidu.com"命令之后该目录将出现baidu.py文件。 -
然后进入到mySpider目录执行 scrapy genspider baidu “baidu.com” ,可以看到将在mySpider/spider目录下创建一个名为baidu的爬虫,并指定爬取域的范围为baidu.com。
其中 , start_urls = () :爬取的URL元祖/列表。爬虫从这里开始抓取数据,所以,第一次下载的数据将会从这些urls开始(需要爬取的第一个url)。其他子URL将会从这些起始URL中继承性生成。
parse(self, response) :解析的方法,每个初始URL完成下载后将被调用,调用的时候传入从每一个URL传回的Response对象来作为唯一参数,主要作用如下:负责解析返回的网页数据(response.body),提取结构化数据(生成item);生成需要下一页的URL请求。
注:如果在parse方法中使用return 返回结构化数据那么返回的数据将不通过pipeline;使用yield 返回数据才会经过pipeline从而得到pipeline的处理。
3.scrapy crawl baidu
是启动scrapy爬虫,这里的baidu是使用 scrapy genspider命令的唯一爬虫名。运行之后,如果打印的日志出现 [scrapy] INFO: Spider closed (finished),代表执行完成。启动爬虫之前需要在item.py文件下定义结构化数据字段用来保存爬取到的数据(类似python中的字典),然后还需要在spiders文件目录下的baidu.py文件里写好相应的分析网页和反反爬措施,以及在settings.py文件里面开启一些反爬以及其它功能。
items.py里面已经有name = scrapy.Field()这个例子,仿照样式编写或者自己定制化编写即可。
4.如何使用命令行保存数据:(使用-o指定输出指定格式的文件)
(1)json格式数据(默认为Unicode编码): scrapy crawl baidu -o data.json
(2)csv 逗号表达式,可用Excel打开: scrapy crawl baidu -o data.csv
(3)xml格式:scrapy crawl itcast -o data.xml
(4)输出成以上三种数据格式需要返回数据的时候把数据的结构定义成相应的格式;当然也可以导出为其他的数据文件格式。
五、案例:用 Scrapy 抓取股票行情【这是之前刚刚开始学的时候的网上的案例】
爬取过程、思路:
第一步,创建Scrapy爬虫项目;
第二步,定义一个item容器;
第三步,定义settings文件进行基本爬虫设置;
第四步,编写爬虫逻辑;
第五步,代码调试。
1.创建爬虫:scrapy startproject stockspider
之后可以看到目录结构。
2. 在items.py文件中编写定义所爬取的字段(结构化数据)
# -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # https://doc.scrapy.org/en/latest/topics/items.html import scrapy from scrapy.loader import ItemLoader from scrapy.loader.processors import TakeFirst class StockspiderItemLoader (ItemLoader): #自定义新建一个类继承itemloader,用于存储爬虫所抓取的字段内容 default_output_processor = TakeFirst() class StockspiderItem(scrapy.Item): #建议相应的字段 # define the fields for your item here like: # name = scrapy.Field() code = scrapy.Field() # 股票代码 abbr = scrapy.Field() # 股票简称 last_trade = scrapy.Field() # 最新价 chg_ratio = scrapy.Field() # 涨跌幅 chg_amt = scrapy.Field() # 涨跌额 chg_ratio_5min = scrapy.Field() # 5分钟涨幅 volumn = scrapy.Field() # 成交量 turn_over = scrapy.Field() # 成交额
2.修改setting.py文件进行基本爬虫设置:
(1)robots.txt 是遵循 Robot 协议的一个文件,在 Scrapy 启动后,首先会访问网站的 robots.txt 文件,然后决定该网站的爬取范围。有时需要将此配置项设置为 False
ROBOTSTXT_OBEY=False
(2)请求头设置
3.编写爬虫逻辑:
首先需要在stockspider/stockspider/spiders目录下创建 stock.py文件,这个文件用于编写爬虫逻辑。
该文件会自动生成 start_url,即爬虫的起始地址,并且自动创建名为 parse 的自定义函数,之后的爬虫逻辑将在 parse 函数中书写。
cd stockspider scrapy genspider stock quote.stockstar.com
编写逻辑:
略
代码调试:
在C:\SpiderTest\stockspider下创建main.py文件写下
from scrapy.cmdline import execute execute(["scrapy","crawl","stock","-o","items.json"])
其等价于4在 C:\SpiderTest\stockspider 下执行命令“scrapy crawl stock-o items.json”,将爬取的数据导出到 items.json 文件。
在代码里可设置断点(如在 spiders/stock.py 内),然后单击“Run”选项按钮→在弹出的菜单中选择“Debug‘main’”命令,进行调试
终于有点时间总结东西了。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号