
【算法框架套路】最长公共子序列
需求
最长公共子序列,说起来比较抽象,换个接地气的说法:
寻找刘德化和梁朝伟的最长公共女粉丝
场景是这样的
给定两个字符串 text1 和 text2,返回这两个字符串的最长 公共子序列 的长度。如果不存在 公共子序列 ,返回 0 。
输入:text1 = "abcde", text2 = "ace"
输出:3
解释:最长公共子序列是 "ace",它的长度为 3。
子序列和子串有什么区别?
子串要连续,子序列可以不连续。比如
a=hellowolrd
b=loop
最长子串是lo,最长子序列是loo
思路
遇到这样的题,我一般都是这样的做法
- 先暴力破解:穷举
- 更高效地穷举
- 更高效地穷举+备忘录
- 动态规划
下面演示一下这种层层推进的过程,以chenqionghexsfz和cqhxsfz为例,两者的最长公共子序列是cqhxsfz,返回的结果是7.
1. dfs暴力收集所有解,再计算出最大解
用的是回溯套路,可以参考【算法框架套路】回溯算法(暴力穷举的艺术)
这里就是从头到尾穷举,遇到相同的字符串,就加入到公共子串的track数组,到头了将子串收集到res_list中。
import copy
def long_common_subsequence_all(str1, str2):
len1, len2 = len(str1), len(str2)
res_list = []
lcs = ""
def dp(i, j, track1, track2):
if i == len1 or j == len2:
nonlocal lcs
cs = "".join(track1)
res_list.append(cs) # 到头了,收集一下公共子序列
if len(cs) >= len(lcs):
lcs = cs # 更新最大子序列
return
c_track1 = copy.copy(track1)
c_track2 = copy.copy(track2)
if str1[i] == str2[j]:
# 找到一个lcs中的元素,str1和str2分别选中,继续往下找
c_track1.append(str1[i])
c_track2.append(str2[j])
dp(i + 1, j + 1, c_track1, c_track2)
return
else:
dp(i, j + 1, c_track1, c_track2)
dp(i + 1, j, c_track1, c_track2)
dp(0, 0, [], [])
return lcs, res_list
s1 = "chenqionghexsfz"
s2 = "cqhxsfz"
lcs, res_list = long_common_subsequence_all(s1, s2)
print(res_list)
print(lcs)
res_list是穷举所有的公共子串
结果如下

2. dfs暴力只收集最大解
这和上次不同,我们从末尾开始递归
s1[0:i]和s2[0:j]的最长公共子串
如果s1[i]和sj[j]相同,最长公共子串,肯定是等于s1[i-1]和s[j-1]的结果+1
这样的方式,肯定比穷举所有的要好一点,代码如下
# dp定义:返回text1[0:i]和text2[0:j]的lcs
def long_common_subsequence_all(text1, text2):
def dp(i, j):
if i == -1 or j == -1:
return 0
if text1[i] == text2[j]:
return dp(i - 1, j - 1) + 1
else:
return max(dp(i - 1, j), dp(i, j - 1)) # i和j不相同,分别再对比s1[i-1],s2[j]和s[i],s2[j-1]
return dp(len(text1) - 1, len(text2) - 1)
s1 = "chenqionghexsfz"
s2 = "cqhxsfz"
lcs_len = long_common_subsequence_all(s1, s2)
print(lcs_len)
运行输出如下
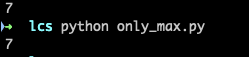
这里只给出了长度,代码较少。
如果想知道子串,也可以依照上面的track数组,这样写
def long_common_subsequence_all(str1, str2):
lcs = ""
# 定义dp:返回str1[0:i]和str2[0:j]的lcs
def dp(i, j, track1, track2):
nonlocal lcs
if i == -1 or j == -1:
# 到头了,更新最大的结果
cs = "".join(track1)
if len(cs) > len(lcs):
lcs = cs
return 0
c_track1 = copy.copy(track1)
c_track2 = copy.copy(track2)
if str1[i] == str2[j]:
# 找到一个lcs中的元素,str1和str2分别选中,继续往下找
c_track1.insert(0, str1[i])
c_track2.insert(0, str2[j])
return dp(i - 1, j - 1, c_track1, c_track2) + 1
else:
# i和j不相同,分别再对比s1[i-1],s2[j]和s[i],s2[j-1]
return max(dp(i - 1, j, c_track1, c_track2), dp(i, j - 1, c_track1, c_track2))
lcs_len = dp(len(str1) - 1, len(str2) - 1, [], [])
return lcs, lcs_len
s1 = "chenqionghexsfz"
s2 = "cqhxsfz"
lcs, lcs_len = long_common_subsequence_all(s1, s2)
print(lcs, lcs_len)
运行输出

3. dfs暴力只收集最大解+备忘录
上面会发生一些重复操作,
比如
dp(3,5) = dp(2,4)+1
dp(2,5) = dp(2,4)+1
那么dp(2,4)会被重复计算,我们需要将已经计算出来的结果缓存起来
代码如下
def long_common_subsequence(text1, text2):
memo = {}
def dp(i, j):
if (i, j) in memo:
return memo[(i, j)]
if i == -1 or j == -1:
return 0
if text1[i] == text2[j]:
return dp(i - 1, j - 1) + 1
else:
memo[(i, j)] = max(dp(i - 1, j), dp(i, j - 1)) # i和j不相同,分别再对比s1[i-1],s2[j]和s[i],s2[j-1]
return memo[(i, j)]
return dp(len(text1) - 1, len(text2) - 1)
s1 = "chenqionghexsfz"
s2 = "cqhxsfz"
lcs = long_common_subsequence(s1, s2)
print(lcs)
运行输出

4. dp动态规划
dp(i,j)是返回text1,text2的最大公共子串大小。
dp[i][j]也是返回text1,text2的最大公共子串大小,只是反着来
实现如下
# dp定义:返回text1[0:i]和text2[0:j]的lcs
def long_common_subsequence(text1, text2):
len1, len2 = len(text1), len(text2)
dp = [[0] * (len2 + 1) for _ in range(len1 + 1)]
for i in range(1, len1 + 1):
for j in range(1, len2 + 1):
# 找到一个公共字符串
if text1[i - 1] == text2[j - 1]:
dp[i][j] = dp[i - 1][j - 1] + 1
else:
dp[i][j] = max(dp[i - 1][j], dp[i][j - 1])
return dp[-1][-1]
s1 = "chenqionghexsfz"
s2 = "cqhxsfz"
lcs = long_common_subsequence(s1, s2)
print(lcs)
运行输出


 浙公网安备 33010602011771号
浙公网安备 33010602011771号