
Numpy科学计算从放弃到入门
什么是NumPy
NumPy是Python科学计算的基础包,不仅是python中使用最多的第三方库,还是SciPy、Pandas等数据科学的基础库。所提供的结构比Python自身的更高级、更高效。
可以说,NumPy所提供的数据结果是Python数据分析的基础。
标准的Python用列表list保存数组的值,list的元素在系统中内存是分散存储的,而Numpy的数组结构是存储在一个均匀连续的内存块中,遍历所有的元素更高效,节省了计算资源。
主要提供了以下功能:
- 快速高效的多维数组对象的ndarray
- 用于对数组执行元素级计算以及直接对数组执行数学运算的函数
- 用于读写硬盘上基于数组的数据集的工具
- 线性代数运算、傅立叶变换,以及随机数组生成
- 用于将C、C++、Fortran代码集成到Python的工具
- 作为算法之间传递数据的容器,对于数值型数据,Numpy数组在存储和处理数据时要比内置的Python数据结构高效得多
numpy提供了一个ndarray对象,多维数组的含义,维度称为rank(秩),每个线性的数组称为一个axes(轴)。数组是有属性的,可以通过函数shape获得数组的大小,通过dtype获得元素的属性
相关帮助文档
一、如何创建数组
-
array
将输入数据(列表、元组、数组或其他序列类型)转换为ndarray。要么推断出dtype,要么显示指定dtype
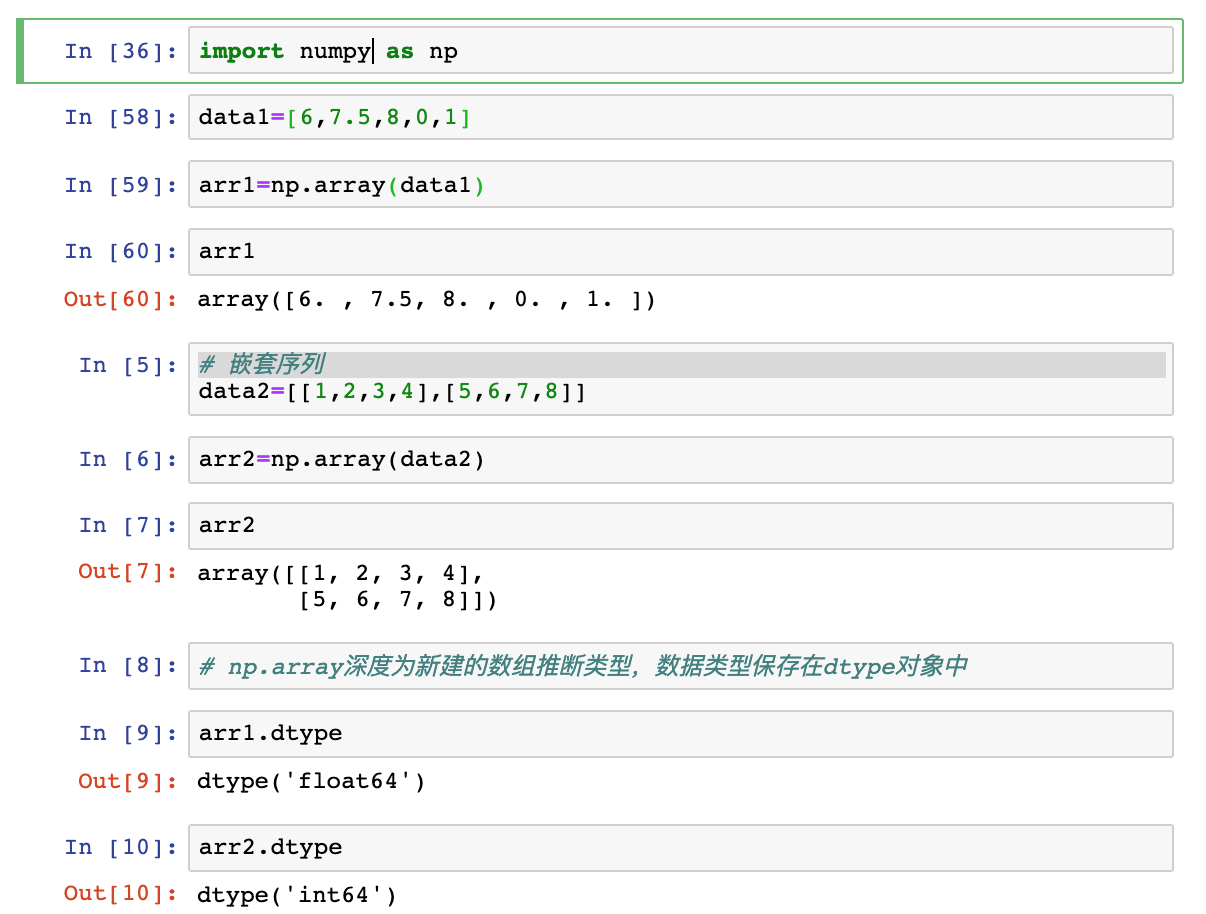
-
asarray
将输入转换为ndarray,如果输入本身就是一个ndarray就不再复制
array和asarray都可以将结构数据转化为ndarray,但是主要区别就是当数据源是ndarray时,array仍然会copy出一个副本,占用新的内存,但asarray不会 -
arange
类似内置的range,返回一个ndarray

-
linespace
生成等差数列,可以指定包含名都不包含终点值 -
zeros、zeros_like
根据指定的形状和dtype创建一个全是0的数组。
zeros_like以另一个数组为参数,并根据其形状和dtype创建一个全0数组
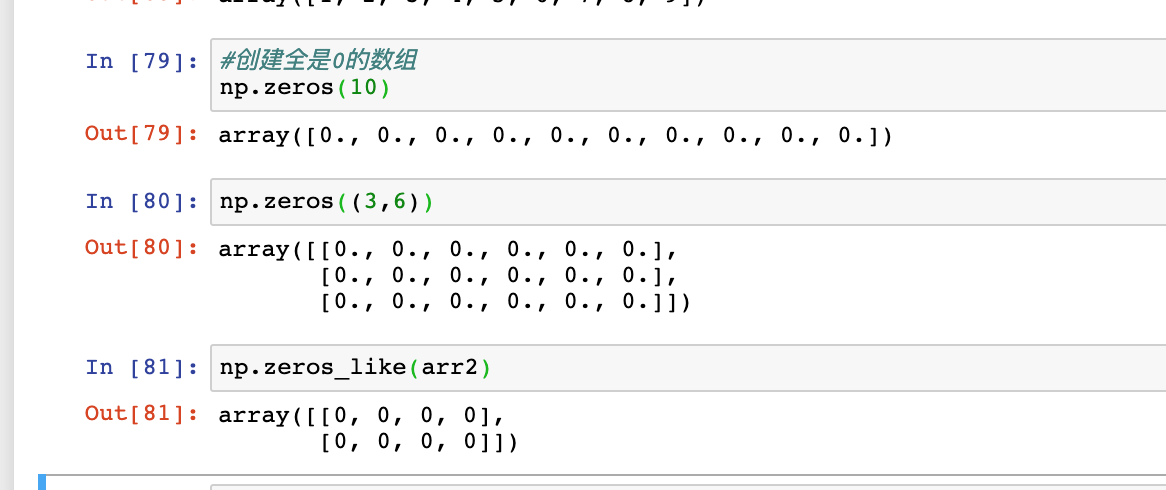
-
ones、ones_like
根据指定的形状和dtype创建一个全是1的数组。
ones_like以另一个数组为参数,并根据其形状和dtype创建一个全1数组
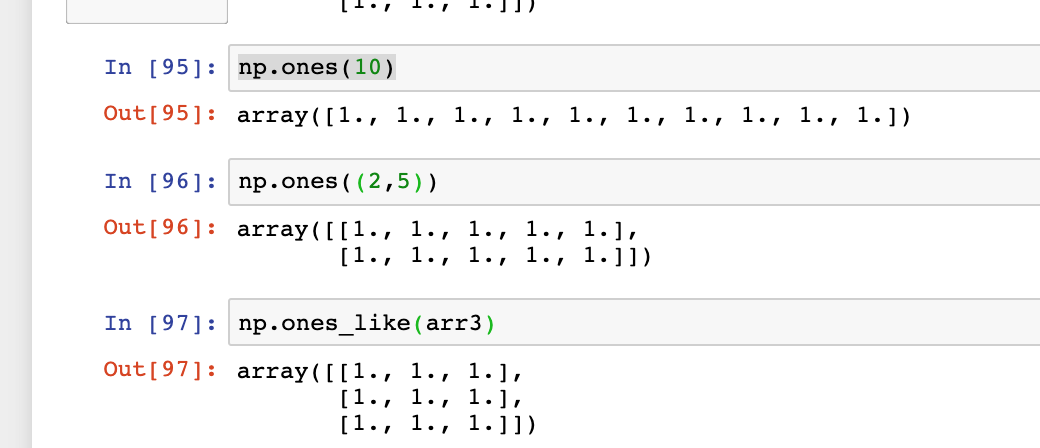
-
empty、empty_like
类似ones和ones_like,只是产生的是全0数组 -
eye、identity
创建一个正方的N*N单位矩阵,对角线为1,其余为0
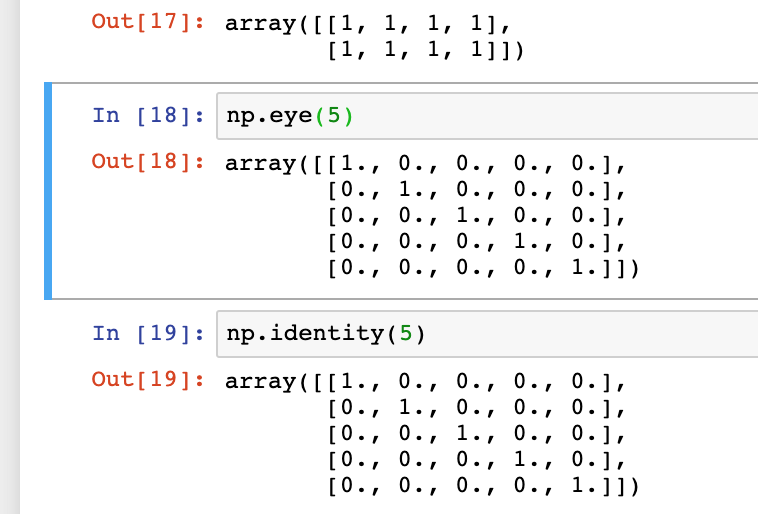
二、如何访问数组
-
下标索引
arr2d=np.array([[1,2,3],[4,5,6],[7,8,9]])
arr2d[0][2]和arr2d[0,2]是等价的 -
切片索引
可以一次传入多个切片,
arr2d[:2, 1:] -
布尔型索引
将data中所有负值都设置为0
data[data < 0] = 0
- 选出所有名字为“cqh”的所有行
data[names == 'cqh']
- 整数索引
利用整数数组进行索引
arr = np.empty((8,4))
for i in range(8):
arr[i] = i
传入指定顺序
arr[[4,3,0,6]]
* 负数索引
arr[[-3,-5,-7]]
- 方形索引
使用np.ix_方法,可以将两个一维整数数组转换为一个用于选取方形区域的索引
arr = np.arange(32).reshape((8,4))
获取行[1,5,7,2],列[0,3,1,2],为
arr[np.ix_([1,5,7,2],[0,3,1,2])]
相当于执行了
arr[[1,5,7,2]][:,[0,3,1,2]]
错误方法:
arr[[1,5,7,2],[0,3,1,2]]
三、如何做算数运算
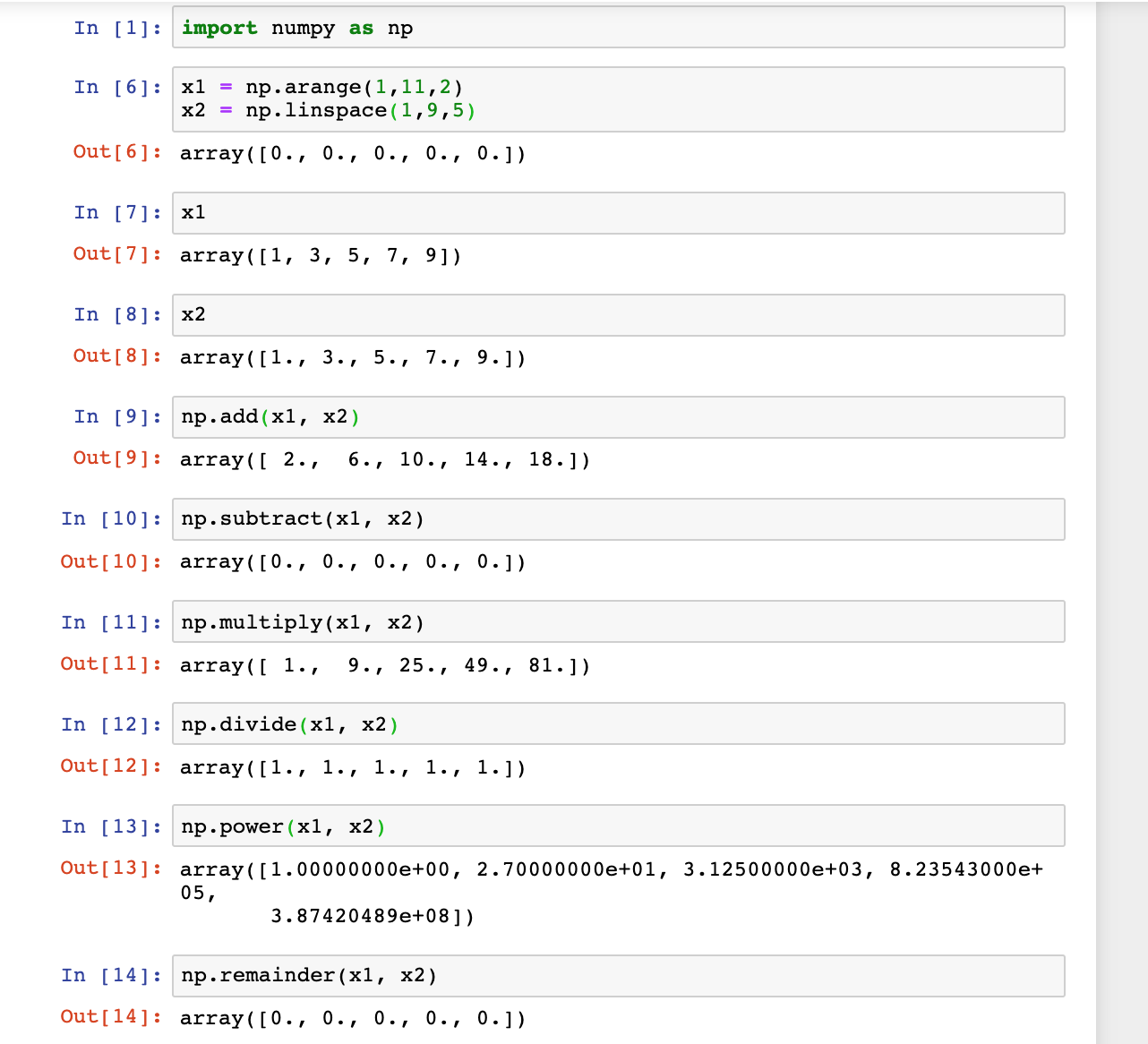
x1 = np.arange(1,11,2)
x2 = np.linspace(1,9,5)
np.add(x1, x2)
np.subtract(x1, x2)
np.multiply(x1, x2)
np.divide(x1, x2)
np.power(x1, x2)
np.remainder(x1, x2)
四、如何使用统计函数
默认axis=0代表沿着列统计,axis=1代表沿着行统计
- amax:矩阵中的最大值
- amin:矩阵中的最小值
- ptp:统计最大值与最小值的差
- percentile:统计数组的百分位数
- median:统计中位数
- mean:平均数
- average:加权平均值(需要传入各个元素的权重)
- std:标准差
- var:方差
五、如何转置数组和反转
- reshape
arr = np.arange(15).reshape((3,5))

- T
arr.T

六、如何去重、计算差集并集等集合操作
- unique(x):计算x中的唯一元素,并返回有序结果
- intersect1d(x,y):计算x和y中的公共元素,并返回有序结果
- union(x,y):计算x和y的并集,并返回有序结果
- in1d(x,y):得到一个表示“x的元素是否包含在y”的布尔型数组
- setdiff1d(x,y) 集合的差,元素在x中且不在y中
- setxor1d(x,y) 集合的对称差,存在于一个数组中但不同时存在两个数组中的元素
七、如何生成随机数
-
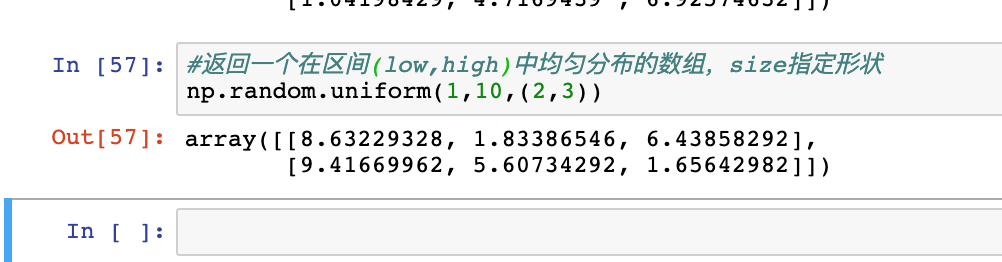
rand:产生[0,1]均匀分布的样本值

-
uniform:产生在[0,1]中均匀分页的样本值
-
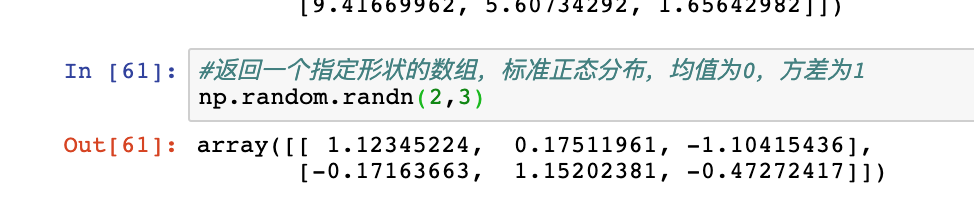
randn:产生正态分布(平均值0,标准差1)的样本值,类似MATLAB接口
-
normal:生成标准正态分布的样本数组

-
randint:在给定的上下限范围内随机选取整数

-
seed:确定随机数生成器的种子
-
permutation:返回一个序列的随机排列
-
shuffle:对一个序列就地随机排列
-
bionmial:产生二项分布的样本值
-
beta:生产Beta分布的样本值
-
chisquare:产生卡方分布的样本值
-
gamma:产生Gamma分布的样本值
八、如何输入输出文件
以二进制格式保存到磁盘
- np.save:保存到磁盘
- np.savez:将多个数组保存到一个压缩文件中,加载时得到一个字典对象
- np.load:从磁盘加载
存取文本文件
- loadtxt:指定各种分隔符
- savetxt:将数组写到以某种分隔符隔开的文本文件

 浙公网安备 33010602011771号
浙公网安备 33010602011771号