第四次作业
作业①:
要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
输出信息:MYSQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,由同学们自行定义设计表头:
Gitee文件夹链接
序号 股票代码 股票名称 最新报价 涨跌幅 涨跌额 成交量 成交额 振幅 最高 最低 今开 昨收
| 序号 | 股票代码 | 股票名称 | 最新报价 | 涨跌幅 | 涨跌额 | 成交量 | 成交额 | 振幅 | 最高 | 最低 | 今开 | 昨收 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 688093 | N世华 | 28.47 | 62.22% | 10.92 | 26.13万 | 7.6亿 | 22.34 | 32.0 | 28.08 | 30.2 | 17.55 |
| 2...... |
作业代码
from selenium import webdriver
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import By
from urllib.parse import urljoin
import sqlite3
import time
# 全局变量
browser = None
page_count = 0
def setup_browser():
#配置浏览器
browser_options = Options()
browser_options.add_argument('--headless')
browser_options.add_argument('--disable-gpu')
return webdriver.Edge(options=browser_options)
def clear_database():
# 清空数据库中的所有数据
db_connection = sqlite3.connect("stock_data.db")
db_cursor = db_connection.cursor()
db_cursor.execute("DELETE FROM stock_data")
db_connection.commit()
db_connection.close()
print("数据库已清空")
def create_database():
#创建数据库表
db_connection = sqlite3.connect("stock_data.db")
db_cursor = db_connection.cursor()
db_cursor.execute("""
CREATE TABLE IF NOT EXISTS stock_data (
sequence_num TEXT,
stock_code TEXT,
stock_name TEXT,
current_price TEXT,
change_rate TEXT,
change_value TEXT,
trade_volume TEXT,
trade_amount TEXT,
swing_range TEXT,
highest_price TEXT,
lowest_price TEXT,
open_price TEXT,
close_price TEXT
)
""")
db_connection.commit()
db_connection.close()
def store_stock_data(data_list):
#存储股票数据到数据库
db_connection = sqlite3.connect("stock_data.db")
db_cursor = db_connection.cursor()
db_cursor.execute("""
INSERT INTO stock_data VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
""", data_list)
db_connection.commit()
db_connection.close()
def fetch_stock_info(page_url):
#获取股票信息
global page_count
page_count += 1
browser.get(page_url)
time.sleep(2)
# 定位股票数据行
stock_rows = browser.find_elements(By.XPATH, "//div[@class='quotetable']//tbody/tr")
for row in stock_rows:
stock_info = [
row.find_element(By.XPATH, './td[1]').text,
row.find_element(By.XPATH, './td[2]').text,
row.find_element(By.XPATH, './td[3]').text,
row.find_element(By.XPATH, './td[5]').text,
row.find_element(By.XPATH, './td[6]').text,
row.find_element(By.XPATH, './td[7]').text,
row.find_element(By.XPATH, './td[8]').text,
row.find_element(By.XPATH, './td[9]').text,
row.find_element(By.XPATH, './td[10]').text,
row.find_element(By.XPATH, './td[11]').text,
row.find_element(By.XPATH, './td[12]').text,
row.find_element(By.XPATH, './td[13]').text,
row.find_element(By.XPATH, './td[14]').text
]
store_stock_data(stock_info)
# 处理分页
handle_pagination(page_url)
def display_results():
#显示数据
db_connection = sqlite3.connect("stock_data.db")
db_cursor = db_connection.cursor()
db_cursor.execute("SELECT * FROM stock_data")
data_rows = db_cursor.fetchall()
# 表头
headers = ["序号", "代码", "名称", "最新价", "涨跌幅", "涨跌额", "成交量", "成交额", "振幅", "最高", "最低", "今开", "昨收"]
header_format = "%-6s%-10s%-8s%-8s%-9s%-9s%-8s%-8s%-8s%-8s%-8s%-8s%-8s"
print(header_format % tuple(headers))
# 数据行
for row in data_rows:
print("%-6s%-10s%-8s%-8s%-10s%-10s%-12s%-12s%-10s%-10s%-10s%-10s%-10s" % row)
print(f"\n总共爬取 {len(data_rows)} 条股票记录")
db_connection.close()
def main():
"""主函数"""
global browser
browser = setup_browser()
try:
# 创建数据库表
create_database()
# 清空现有数据
clear_database()
# 开始爬取
start_url = "http://quote.eastmoney.com/center/gridlist.html#hs_a_board"
fetch_stock_info(start_url)
display_results()
except Exception as error:
print(f"执行过程中出现错误: {error}")
finally:
if browser:
browser.quit()
if __name__ == "__main__":
main()
码云链接
https://gitee.com/chenming333/chenmingproject/blob/master/作业4/1.py
运行结果
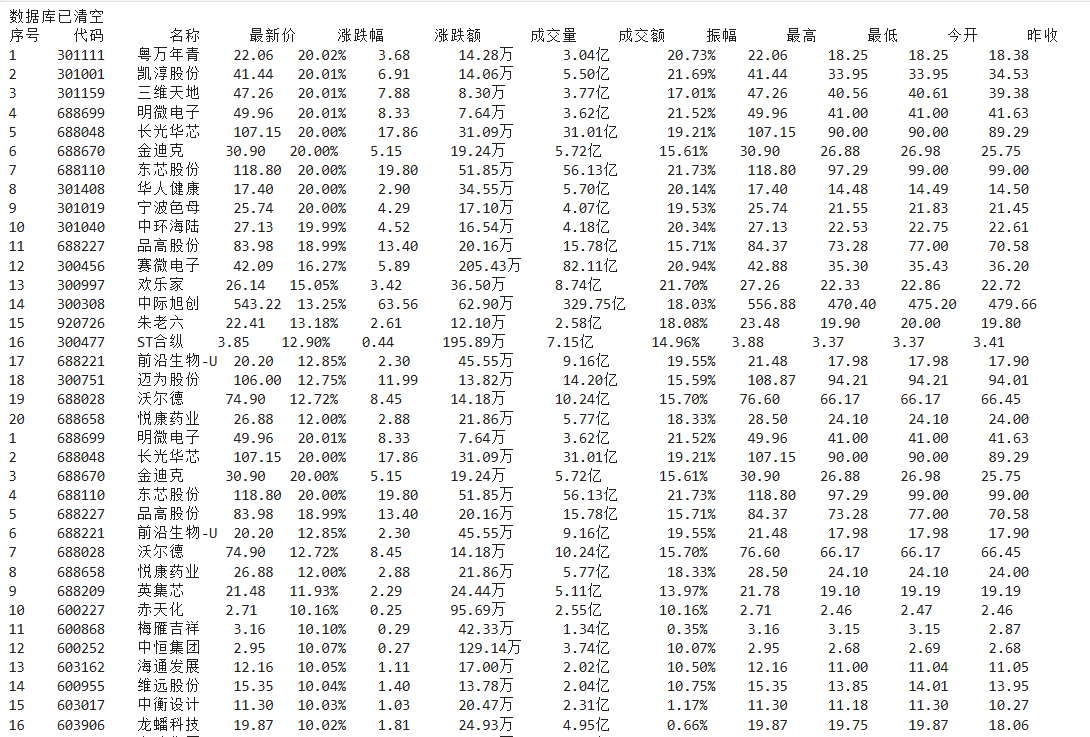
作业心得
通过本次股票数据爬取实验,我深入掌握了动态网页的自动化抓取技术。面对JavaScript渲染的复杂页面,运用Selenium模拟浏览器操作,精准定位并提取表格数据;同时,结合SQLite数据库实现了数据的结构化存储与管理。整个过程强化了我对网络爬虫工作流程、异常处理及数据持久化的理解,提升了解决实际工程问题的能力。
作业②:
要求:
熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
候选网站:中国mooc网:https://www.icourse163.org
输出信息:MYSQL数据库存储和输出格式
Gitee文件夹链接
| Id | cCourse | cCollege | cTeacher | cTeam | cCount | cProcess | cBrief |
|---|---|---|---|---|---|---|---|
| 1 | Python数据分析与展示 | 北京理工大学 | 嵩天 | 嵩天 | 470 | 2020年11月17日 ~ 2020年12月29日 | “我们正步入一个数据或许比软件更重要的新时代。——Tim O'Reilly” …… |
| 2...... |
作业代码
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import sqlite3
import time
import traceback
# 打开浏览器
driver = webdriver.Edge()
driver.get('https://www.icourse163.org/')
time.sleep(1)
button = driver.find_element(By.CLASS_NAME, '_3uWA6')
button.click()
time.sleep(1)
frame = driver.find_element(By.XPATH, "//div[@class='ux-login-set-container']//iframe")
driver.switch_to.frame(frame)
# 账号密码输入
account = driver.find_element(By.ID, 'phoneipt').send_keys('15306991229')
password = driver.find_element(By.XPATH, "//input[@placeholder='请输入密码']").send_keys("cm123456")
button1 = driver.find_element(By.ID, 'submitBtn')
button1.click()
time.sleep(2) # 等待登录完成
# 访问搜索页面
url = 'https://www.icourse163.org/search.htm?search=%E8%AE%A1%E7%AE%97%E6%9C%BA#/'
driver.get(url)
time.sleep(3) # 等待页面加载
# 滚动加载更多内容
print("开始滚动加载内容...")
last_height = driver.execute_script("return document.body.scrollHeight")
for i in range(5): # 滚动5次
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2) # 等待加载
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
print(f"第{i + 1}次滚动后高度未变化,停止滚动")
break
last_height = new_height
print(f"第{i + 1}次滚动完成")
# 等待课程元素
wait = WebDriverWait(driver, 10)
try:
courses = wait.until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "div._3NYsM"))
)
print(f"成功找到 {len(courses)} 个课程")
except Exception as e:
print(f"查找课程元素失败: {e}")
courses = []
# 数据库操作
if courses:
conn = sqlite3.connect('课程信息.db')
cursor = conn.cursor()
# 删除已存在的表(如果需要重新创建)
cursor.execute('DROP TABLE IF EXISTS course')
cursor.execute('''
CREATE TABLE course
(
id INTEGER PRIMARY KEY AUTOINCREMENT,
课程名称 TEXT NOT NULL,
学校名称 TEXT,
老师 TEXT,
教师团队 TEXT,
参加人数 TEXT,
课程进度 TEXT,
课程简介 TEXT
)
''')
count = 0
for course in courses:
count += 1
print(f"\n处理第 {count} 个课程:")
try:
# 1. 课程名称
try:
course_name = course.find_element(By.CSS_SELECTOR, "div._1vfZ-").text
except:
course_name = "未知课程"
# 2. 学校名称
try:
# 注意:有些课程没有学校,只有机构或个人
school_name = course.find_element(By.CSS_SELECTOR, "a._3vJDG").text
except:
try:
# 尝试其他可能的选择器
school_name = course.find_element(By.CSS_SELECTOR, "a._3t_C8").text
except:
school_name = ""
# 3. 主讲老师
try:
teacher = course.find_element(By.CSS_SELECTOR, "a._3t_C8").text
except:
teacher = ""
# 4. 教师团队
try:
# 查找所有教师
teachers = course.find_elements(By.CSS_SELECTOR, "a._3t_C8")
teacher_names = [t.text for t in teachers if t.text]
if teacher_names:
team_member = "、".join(teacher_names)
else:
team_member = teacher
except:
team_member = teacher
# 5. 参加人数
try:
attendees = course.find_element(By.CSS_SELECTOR, "div._CWjg").text
attendees = attendees.replace('参加', '').strip()
except:
attendees = "0"
# 6. 课程进度
try:
process = course.find_element(By.CSS_SELECTOR, "div._1r-No").text
except:
process = ""
# 7. 课程简介
try:
introduction = course.find_element(By.CSS_SELECTOR, "div._3JEMz").text
except:
introduction = ""
# 打印提取的数据
print(f"课程名称: {course_name}")
print(f"学校名称: {school_name}")
print(f"主讲老师: {teacher}")
print(f"教师团队: {team_member}")
print(f"参加人数: {attendees}")
print(f"课程进度: {process}")
print(f"简介摘要: {introduction[:50]}..." if introduction else "无简介")
# 插入数据库
cursor.execute('''
INSERT INTO course(课程名称, 学校名称, 老师, 教师团队, 参加人数, 课程进度, 课程简介)
VALUES (?, ?, ?, ?, ?, ?, ?)
''', (course_name, school_name, teacher, team_member, attendees, process, introduction))
except Exception as e:
print(f"处理第{count}条记录时出错: {e}")
traceback.print_exc()
continue
conn.commit()
print(f"\n{'=' * 50}")
print(f"成功保存 {count} 条记录到数据库")
print("数据库文件: 课程信息.db")
# 查询并显示保存的数据
cursor.execute("SELECT COUNT(*) FROM course")
total = cursor.fetchone()[0]
print(f"数据库中总记录数: {total}")
cursor.execute("SELECT 课程名称, 学校名称, 参加人数 FROM course LIMIT 5")
print("\n前5条记录:")
for row in cursor.fetchall():
print(f"课程: {row[0]}, 学校: {row[1]}, 人数: {row[2]}")
cursor.close()
conn.close()
else:
print("没有找到任何课程")
# 自动关闭浏览器
print("\n程序执行完成,5秒后自动关闭浏览器...")
time.sleep(5)
driver.quit()
码云链接
https://gitee.com/chenming333/chenmingproject/blob/master/作业4/2.py
运行结果



作业心得
这次实验让我深刻体会到了网络爬虫的魅力。面对动态加载的页面,我学会了如何让程序模拟人类操作滚动网页,并耐心等待内容加载。虽然途中常因元素定位失败而调试许久,但每当成功抓取到一行课程信息时都特别有成就感。从浏览器自动化到数据入库的完整流程走下来,我感觉自己真正把课堂知识用到了实处。
作业③:
要求:
掌握大数据相关服务,熟悉Xshell的使用
完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
环境搭建:
任务一:开通MapReduce服务
1、购买集群

2、给集群的master节点绑定弹性IP
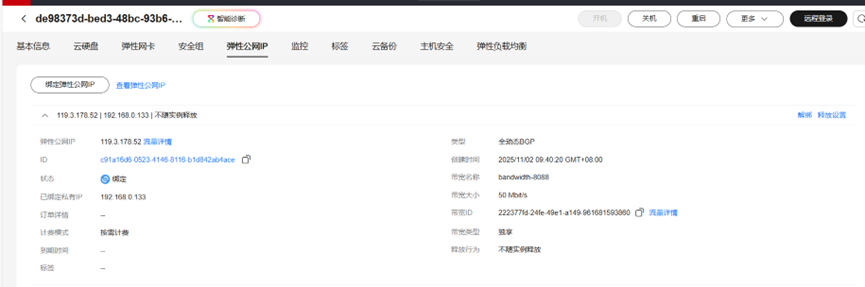
3、修改安全组规则

实时分析开发实战:
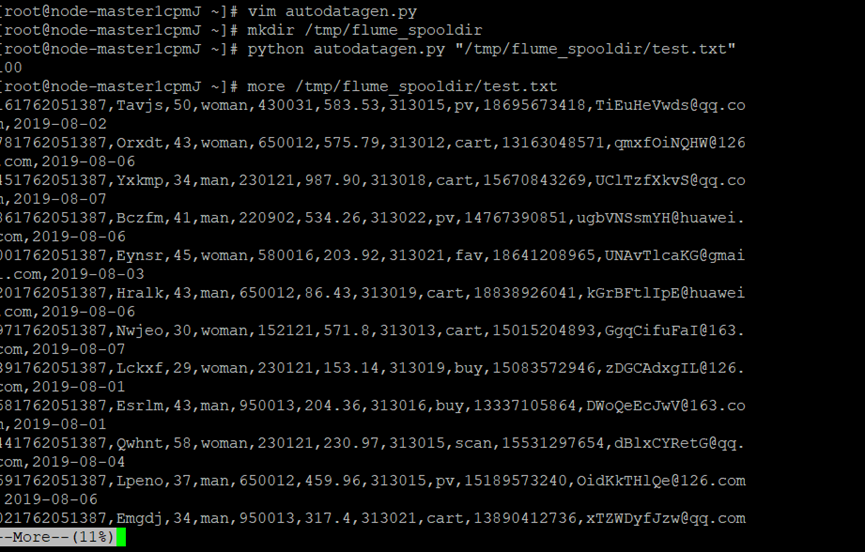
任务一:Python脚本生成测试数据
1、登录
2、编写Python脚本,查看结果
任务二:配置Kafka
1、查看kafka的ip

2、配置环境变量

3、查看topic信息

任务三: 安装Flume客户端
1、下载客户端

2、解压校验文件包

3、解压“MRS_Flume_ClientConfig.tar”文件

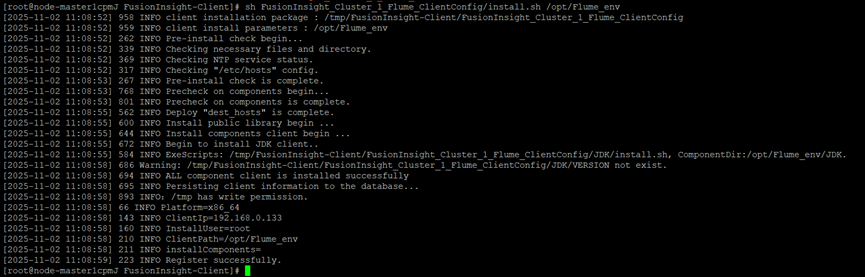
4、运行环境安装成功

5、重启Flume服务

任务四:配置Flume采集数据
1、创建消费者消费kafka中的数据

2、新建一个会话
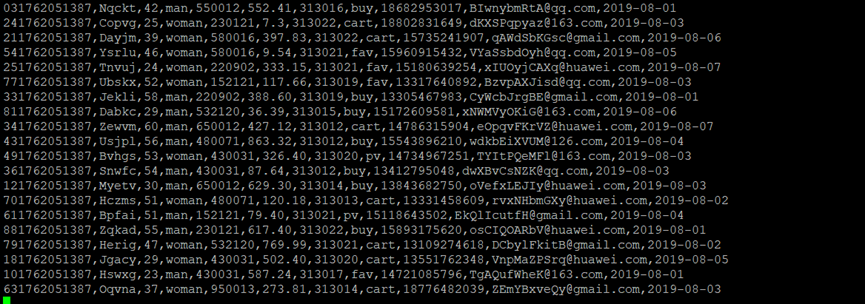
3、在源端口看到数据,表明Flume到Kafka目前是打通的。
作业心得
通过这次Flume日志采集实验,我深刻体会到大数据平台中数据采集与传输的实际流程。从搭建MRS集群、配置Kafka主题到部署Flume客户端,每一步都需要细心操作和严谨验证。尤其在打通Flume与Kafka时,看到数据成功流动的瞬间,让我对实时数据处理有了更直观的认识。实验中遇到的问题也锻炼了我的排查能力,今后会更注重细节和系统间的协同配置。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号