
The AWS Data Engineer's Toolkit“期权交易➕宏观资产组合配置➕风险管理”技术方案

<Data Engineering with AWS, Second Edition> -- Gareth Eagar
☕ Ingesting data
- - Amazon Database Migration Service (DMS)
- - Amazon Kinesis for streaming data ingestion
- - Amazon Kinesis Firehose
- - Amazon Kinesis Data Streams
- - Amazon Kinesis Data Analytics
- - Amazon Kinesis Video Streams
- - Amazon MSK for streaming data ingestion
- - Amazon AppFlow for ingesting data from SaaS services
- - AWS Transfer Family for ingestion using FTP/SFTP protocols
- - AWS DataSync for ingesting from on premises and multicloud storage services
- - The AWS Snow family of devices for large data transfers
- - AWS Glue for data ingestion
☕ Transforming data
- - AWS Lambda for light transformations
- - AWS Glue for serverless data processing
- - AWS Glue DataBrew
- - AWS Glue Data Catalog
- - AWS Glue crawlers
- - Amazon EMR for Hadoop ecosystem processing
☕ Orchestrating big data pipelines
- - AWS Glue workflows for orchestrating Glue components
- - AWS Step Functions for complex workflows
- - Amazon Managed Workflows for Apache Airflow (MWAA)
☕ Consuming data
- - Amazon Athena for SQL queries in the data lake
- - Amazon Athena for SQL queries in the data lake
☕ Visualizing data
- - Amazon QuickSight for visualizing data
详解 EMR vs Glue vs kinesis vs redshift vs opensearch vs MKS vs Athena vs AppFlow vs DataSync vs Snow vs Iceberg
1️⃣流处理与实时分析
Amazon Kinesis
- 核心能力:实时流数据收集、处理和分析(含 Data Streams、Firehose、Analytics)。
- 场景:IoT 设备监控、实时指标计算(如网站访问量)、毫秒级异常检测(集成 RANDOM_CUT_FOREST 算法)。
- 关键限制:数据默认保留 24 小时(可延至 7 天),分片(Shard)吞吐需预计算(1 分片=1MB/s 写入)。
Amazon Managed Streaming for Kafka (MSK)
- 定位:全托管 Apache Kafka,替代自建 Kafka 集群。
- 优势:原生兼容 Kafka 生态(如 Connector、Streams API),适合需 Kafka 高级功能(如 Exactly-Once 语义)的场景。
- 对比 Kinesis:更灵活但运维略复杂,适合已有 Kafka 生态的企业迁移。
2️⃣数据仓库与 OLAP
Amazon Redshift
- 核心能力:PB 级云数据仓库,列式存储 + 高级查询优化(性能达 Spark 3 倍)。
- 特性:支持 Sort Key(单列/复合列优化压缩)和 WLM(查询优先级管理)。流式摄取:直连 Kinesis/Kafka,延迟 <10 秒,30 万条/秒写入。
- 局限:单 AZ 部署,AZ 故障需跨区快照恢复。
Amazon Athena
- 定位:无服务器 SQL 查询引擎,直查 S3 数据。
- 场景:临时分析(Ad Hoc)、日志查询,依赖 Glue Data Catalog 管理元数据。
- 成本优势:按扫描量收费,无基础设施管理。
3️⃣数据湖与表格式
Apache Iceberg
- 核心价值:开放表格式,解耦存储与计算,支持 ACID 事务、时间旅行、分区演化。
- 生态兼容:多引擎查询(Trino/Spark/Snowflake),避免厂商锁定。
- 挑战:小文件问题需手动压缩,元数据管理复杂(需自动清理策略)。
Amazon EMR
- 定位:托管 Hadoop/Spark 集群,深度集成 Iceberg/Hudi。
- 优势:开箱即用,支持 Trino/Flink 等引擎,适合构建湖仓一体架构。
4️⃣搜索与分析
Amazon OpenSearch
- 能力:全文检索 + 实时分析(继承 ElasticSearch 生态),含 Dashboard 可视化。
- 特性:多模态搜索(文本/向量/日志),内置异常检测(如入侵识别)。
- 局限:非 Serverless,需手动配置节点规模。
- 场景:电商搜索(多语言分词增强)、日志分析。
5️⃣数据集成与管道
AWS Glue
- 定位:无服务器 ETL,自动化数据发现、转换、编目。
- 优势:连接 70+ 数据源,与 Athena/Redshift 无缝集成。
- Glue Data Catalog:统一元数据管理,替代 Hive Metastore。
- 局限:调试复杂,需 Python/Scala 开发。
Amazon AppFlow
- 场景:SaaS 数据集成(如 Salesforce、Google Analytics)。
- 工作流:提取 SaaS 数据 → S3(JSON)→ Lambda 转 Parquet → Athena 分析。
- 优势:按需/定时传输,无需代码。
AWS DataSync
- 定位:替代 Snow 设备,自动化本地 ↔ AWS 数据传输(文件/对象)。
- 特性:增量同步、网络中断恢复,成本低于 Snow(无物流延迟)。
Snow
- 现状:2024 年停售中国区,DataSync 为主推方案
6️⃣关键对比与选型建议
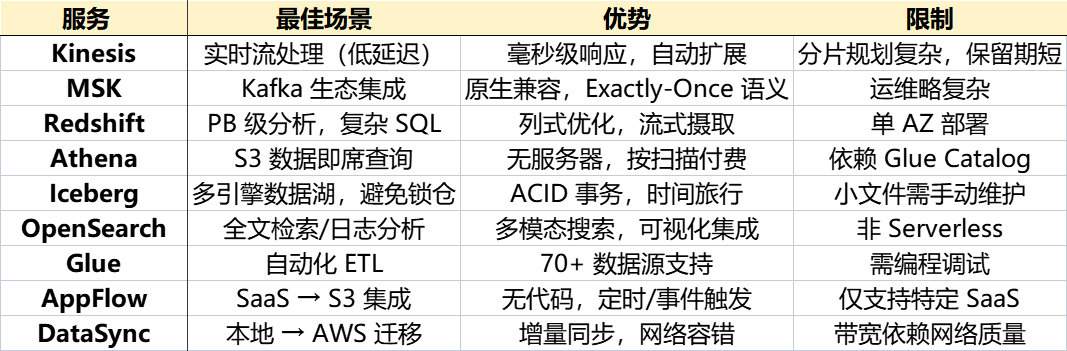
| 服务 | 最佳场景 | 优势 | 限制 |
|---|---|---|---|
| Kinesis | 实时流处理(低延迟) | 毫秒级响应,自动扩展 | 分片规划复杂,保留期短 |
| MSK | Kafka 生态集成 | 原生兼容,Exactly-Once 语义 | 运维略复杂 |
| Redshift | PB 级分析,复杂 SQL | 列式优化,流式摄取 | 单 AZ 部署 |
| Athena | S3 数据即席查询 | 无服务器,按扫描付费 | 依赖 Glue Catalog |
| Iceberg | 多引擎数据湖,避免锁仓 | ACID 事务,时间旅行 | 小文件需手动维护 |
| OpenSearch | 全文检索/日志分析 | 多模态搜索,可视化集成 | 非 Serverless |
| Glue | 自动化 ETL | 70+ 数据源支持 | 需编程调试 |
| AppFlow | SaaS → S3 集成 | 无代码,定时/事件触发 | 仅支持特定 SaaS |
| DataSync | 本地 → AWS 迁移 | 增量同步,网络容错 | 带宽依赖网络质量 |
🍦 框架选型详解
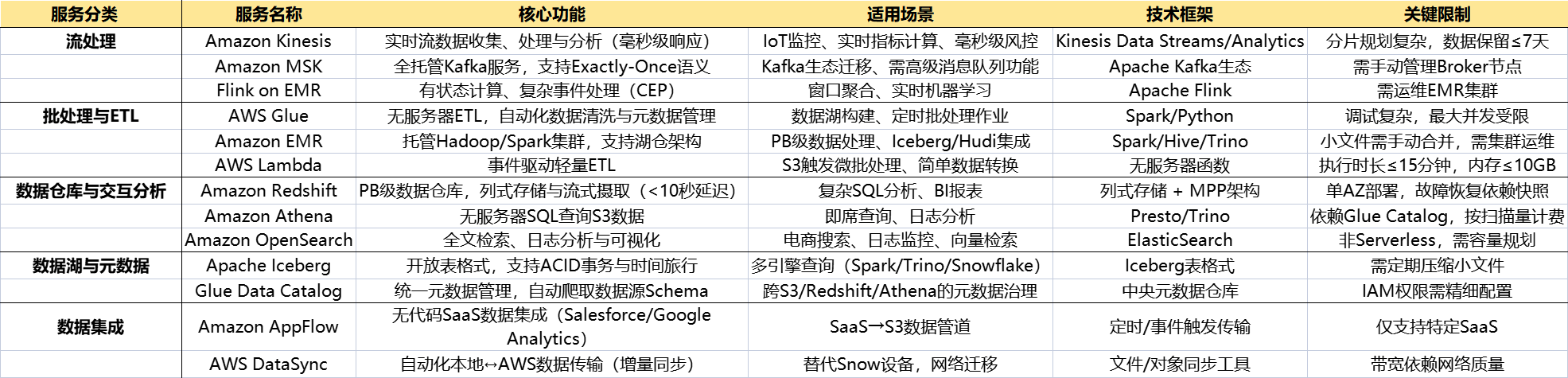
| 服务分类 | 服务名称 | 核心功能 | 适用场景 | 技术框架 | 关键限制 |
|---|---|---|---|---|---|
| 1️⃣流处理 | Amazon Kinesis | 实时流数据收集、处理与分析(毫秒级响应) | IoT监控、实时指标计算、毫秒级风控 | Kinesis Data Streams/Analytics | 分片规划复杂,数据保留≤7天 |
| Amazon MSK | 全托管Kafka服务,支持Exactly-Once语义 | Kafka生态迁移、需高级消息队列功能 | Apache Kafka生态 | 需手动管理Broker节点 | |
| Flink on EMR | 有状态计算、复杂事件处理(CEP) | 窗口聚合、实时机器学习 | Apache Flink | 需运维EMR集群 | |
| 2️⃣批处理与ETL | AWS Glue | 无服务器ETL,自动化数据清洗与元数据管理 | 数据湖构建、定时批处理作业 | Spark/Python | 调试复杂,最大并发受限 |
| Amazon EMR | 托管Hadoop/Spark集群,支持湖仓架构 | PB级数据处理、Iceberg/Hudi集成 | Spark/Hive/Trino | 小文件需手动合并,需集群运维 | |
| AWS Lambda | 事件驱动轻量ETL | S3触发微批处理、简单数据转换 | 无服务器函数 | 执行时长≤15分钟,内存≤10GB | |
| 3️⃣数据仓库与交互分析 | Amazon Redshift | PB级数据仓库,列式存储与流式摄取(<10秒延迟) | 复杂SQL分析、BI报表 | 列式存储 + MPP架构 | 单AZ部署,故障恢复依赖快照 |
| Amazon Athena | 无服务器SQL查询S3数据 | 即席查询、日志分析 | Presto/Trino | 依赖Glue Catalog,按扫描量计费 | |
| Amazon OpenSearch | 全文检索、日志分析与可视化 | 电商搜索、日志监控、向量检索 | ElasticSearch | 非Serverless,需容量规划 | |
| 4️⃣数据湖与元数据 | Apache Iceberg | 开放表格式,支持ACID事务与时间旅行 | 多引擎查询(Spark/Trino/Snowflake) | Iceberg表格式 | 需定期压缩小文件 |
| Glue Data Catalog | 统一元数据管理,自动爬取数据源Schema | 跨S3/Redshift/Athena的元数据治理 | 中央元数据仓库 | IAM权限需精细配置 | |
| 5️⃣数据集成 | Amazon AppFlow | 无代码SaaS数据集成(Salesforce/Google Analytics) | SaaS→S3数据管道 | 定时/事件触发传输 | 仅支持特定SaaS |
| AWS DataSync | 自动化本地↔AWS数据传输(增量同步) | 替代Snow设备,网络迁移 | 文件/对象同步工具 | 带宽依赖网络质量 |
🍰 典型架构参考
1️⃣实时风控系统

技术栈:Kinesis(1MB/s/分片) + Redshift流式摄取(<10秒延迟)
2️⃣湖仓一体分析平台

技术栈:AppFlow(无代码集成) + Glue(转Iceberg) + EMR Trino(联邦查询)
3️⃣选型决策树
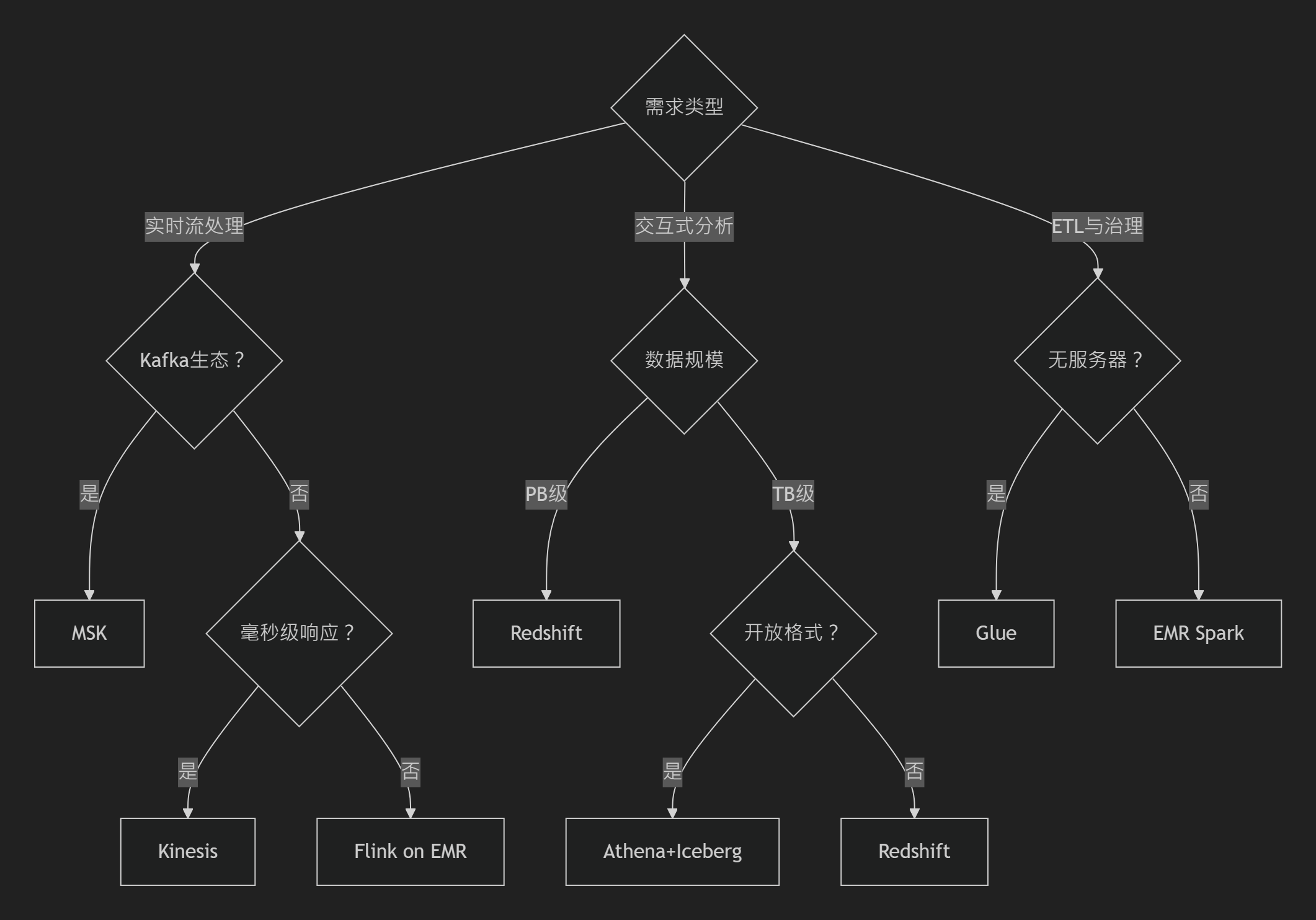
🍔 框架选型详解
1️⃣流处理框架选型
| 服务 | 技术框架 | 适用场景 | 关键优势 | 限制与挑战 |
|---|---|---|---|---|
| Kinesis | Kinesis Data Streams/Data Analytics | 毫秒级实时处理(IoT监控、实时风控) | 自动扩缩容,无缝集成Lambda/Firehose | 分片规划复杂,保留期≤7天 |
| MSK | Apache Kafka生态(Connector/Streams) | Kafka迁移场景,需Exactly-Once语义 | 100%兼容Kafka API,支持Schema Registry | 需手动管理Broker节点规模 |
| Flink on EMR | Apache Flink(流批一体) | 复杂事件处理(CEP)、状态计算 | 低延迟(亚秒级),支持状态快照容错 | 需运维EMR集群 |
选型建议:
- 简单流处理 → Kinesis(低代码)
- 复杂流处理/Kafka生态 → MSK
- 有状态计算/窗口聚合 → Flink on EMR
2️⃣批处理与ETL框架
| 服务 | 技术框架 | 适用场景 | 关键优势 | 限制与挑战 |
|---|---|---|---|---|
| Glue | Spark/Python(无服务器) | 自动化ETL,数据编目与清洗 | 70+连接器,Glue Data Catalog统一元数据 | 调试复杂,最大并发受限 |
| EMR | Spark/Hive/Trino(集群托管) | PB级数据处理,Iceberg/Hudi湖仓架构 | 开箱即用,支持Spot实例降成本 | 需集群运维,小文件需手动合并 |
| Lambda | 无服务器函数(Python/Node.js) | 轻量ETL,S3事件触发处理 | 按需计费,毫秒级响应 | 执行时长≤15分钟,内存≤10GB |
选型建议:
- 无服务器ETL → Glue(标准化管道)
- 大规模计算/自定义框架 → EMR(Spot实例降本40%+)
- 事件驱动微批处理 → Lambda + S3触发器
3️⃣交互式分析引擎
| 服务 | 技术框架 | 适用场景 | 关键优势 | 限制与挑战 |
|---|---|---|---|---|
| Redshift | 列式存储 + Massively Parallel Processing (MPP) | PB级复杂查询,BI报表 | 流式摄取(<10秒延迟),Sort Key优化查询性能 | 单AZ部署,故障恢复依赖快照 |
| Athena | Presto/Trino(无服务器) | S3数据即席查询,日志分析 | 按扫描量付费,支持Iceberg/Delta Lake | 依赖Glue Catalog |
| OpenSearch | ElasticSearch(分布式检索) | 全文搜索、日志聚合 + Dashboard | 多模态搜索(文本/向量),内置异常检测 | 非Serverless,需容量规划 |
选型建议:
- 高性能数据仓库 → Redshift(Sort Key+流式摄取)
- S3数据探索 → Athena + Iceberg(开放格式避免锁仓)
- 日志检索/向量搜索 → OpenSearch(集成Kibana可视化)
4️⃣数据湖与元数据管理
| 技术 | 核心框架 | 适用场景 | 关键优势 | 运维要点 |
|---|---|---|---|---|
| Iceberg | Apache Iceberg(表格式) | 多引擎兼容(Spark/Trino/Snowflake) | ACID事务、时间旅行、分区演化 | 需定期压缩小文件 |
| Glue Catalog | 中央元数据仓库 | 统一管理S3/Redshift/Athena表结构 | Serverless自动爬虫,一处定义多处可用 | IAM权限需精细配置 |
| Delta Lake | Delta Lake(Databricks生态) | Spark生态数据湖,需ACID保障 | 流批统一,Z-Order优化查询性能 | 深度绑定Spark引擎 |
选型建议:
- 开放数据湖 → Iceberg + EMR/Athena(跨引擎查询)
- AWS原生治理 → Glue Catalog(自动发现S3 Schema)
- 纯Spark环境 → Delta Lake(优化性能)
期权链(Options Chain)的实际应用场景

🗂️ 1. 分层存储策略(Tiered Storage)
热数据:当前交易日的实时期权报价(如SPY近月合约)需毫秒级响应 → 存于 S3 Standard,支持高频查询。
温数据:上周的期权历史波动率数据(用于分析模型校准) → 迁移至 S3 Standard-IA,成本降低50%。
冷数据:已到期的期权合约(如2023年12月到期的AAPL合约) → 归档至 S3 Glacier Deep Archive,成本低至$0.004/GB/月。
自动化实践:通过生命周期策略自动迁移(例如:到期合约30天后降级至Glacier)
🧩 2. 多维数据分区(Multi-dimensional Partitioning)
横向分区:按标的资产划分存储桶(如 bucket-spy-options、bucket-aapl-options),隔离不同股票/指数的数据流。
纵向分层:桶内目录区分数据类型:
- raw/:原始期权链(JSON格式,含买/卖报价、成交量)
- processed/:清洗后的结构化数据(Parquet格式,含隐含波动率、希腊值)
- analytics/:聚合后的波动率曲面(按到期日/行权价网格计算)。
时间分区:路径如 s3://bucket/processed/symbol=SPY/expiry=20240627/,加速按到期日查询。
行权价分片:文件命名 strike_400-450.parquet,避免扫描全量数据。
⚙️ 3. 文件优化与格式转换
列式存储:将原始CSV期权链转为 Parquet格式:
- 仅需读取“隐含波动率”列时,扫描数据量减少70%(对比CSV)。
文件合并:将单日数千个小文件(每文件<1MB)合并为128MB文件,提升Athena查询效率。
智能分层:对波动率异常期的历史数据启用 S3 Intelligent-Tiering,自动适应突发查询(如黑天鹅事件回溯)
💰 4. 成本控制机制
预留容量:若每日新增期权数据1TB+,购买 S3 Storage Savings Plans,成本节省60%。
自动化清理:设置 raw/ 目录对象7天后过期,避免原始数据堆积。
监控审计:通过 Cost Explorer 识别异常:
- 发现测试环境误将期权数据存于S3 Standard → 迁移至Intelligent-Tiering,月省$3K
🚀 5. 高并发与容灾设计
前缀分散:期权到期日前高频查询路径 expiry=20240627/ → 添加随机哈希(如 expiry=20240627/prefix=8H4K/),提升并发吞吐量3倍。
跨区域容灾:在 us-east-1 和 ap-northeast-1 启用 S3跨区域复制(CRR),确保亚洲交易时段故障时快速切换。
混合云集成:通过 Storage Gateway 将本地期权数据库与S3同步,支持低延迟本地查询
📊 6. 安全与合规加固
静态加密:启用 SSE-S3加密 存储期权敏感数据(如未公开的大宗交易行权价)。
权限最小化:IAM策略限制仅量化团队可访问 analytics/ 目录,防止误删波动率模型。
合规备份:到期合约存至 Glacier,满足金融业7年数据保留要求(持久性99.999999999%)
💎 期权链存储方案效果对比
| 策略 | 未优化方案 | 优化后效果 |
|---|---|---|
| 1️⃣分层存储 | ⚠️全量存S3 Standard | 成本降低68%(热:冷=1:9) |
| 2️⃣多维分区 | ⚠️单桶存储无分区 | 查询延迟从秒级降至毫秒级 |
| 3️⃣Parquet格式 | ⚠️CSV原始数据 | 存储空间减少65% + 查询提速4倍 |
| 4️⃣跨区域容灾 | ⚠️单区域存储 | RTO(恢复时间目标)<15分钟 |
🍔流程图关键要素解析
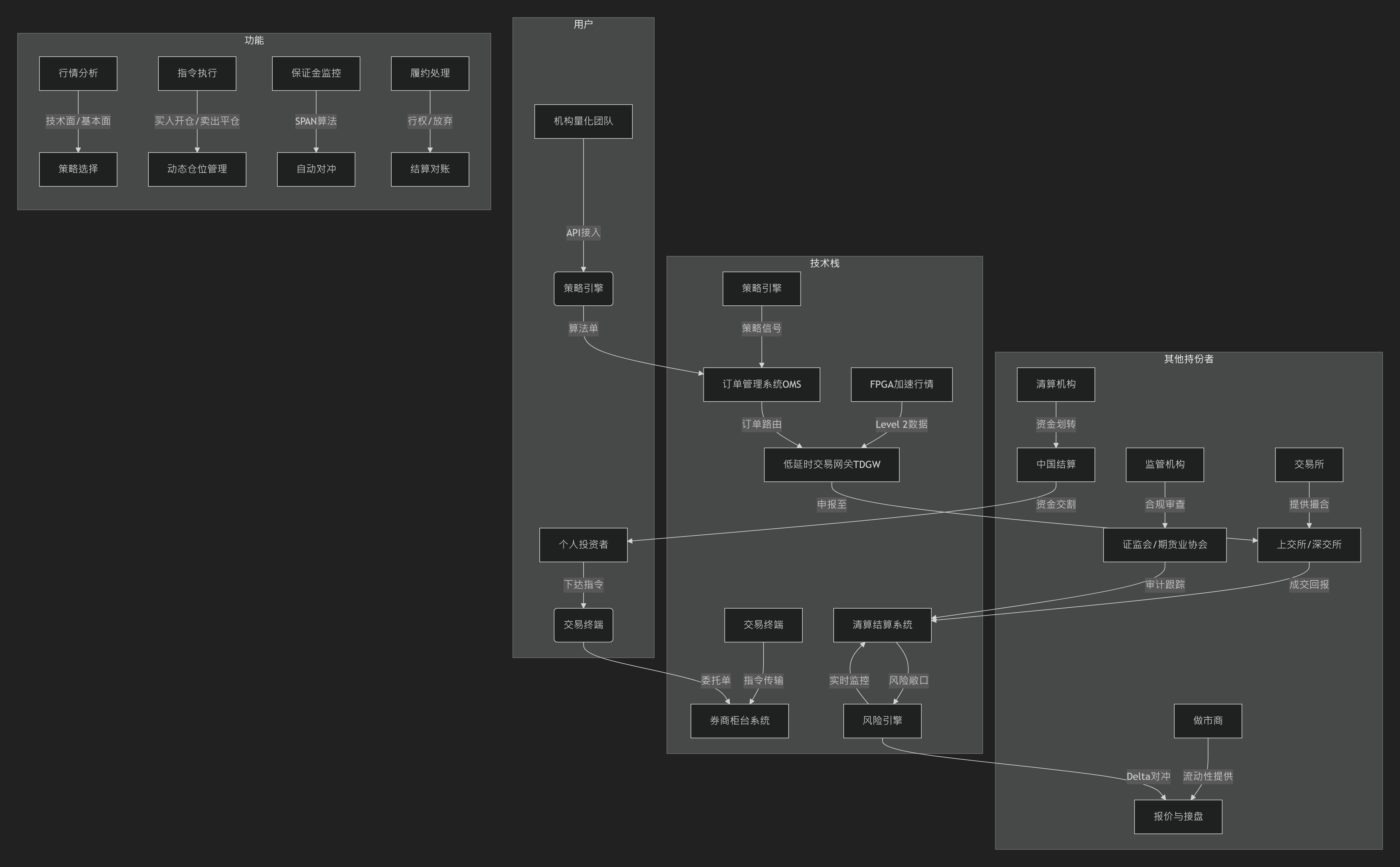
1️⃣用户维度
- 个人投资者:通过交易终端(APP/PC)手动下达指令,依赖行情分析工具。
- 机构量化团队:通过API接入策略引擎,自动化生成交易信号(如Greeks计算)。
2️⃣技术栈维度
- 行情处理:FPGA加速解析Level 2数据(穿透延时<25μs),支持沪深交易所快照与逐笔委托。
- 交易执行:
- 券商柜台系统(如华锐ATP)处理委托单,支持一户两地部署(沪/深独立优化)。
- TDGW流式网关替代传统数据库报盘,委托确认从150ms降至25ms。
- 风控核心:动态保证金计算(SPAN算法)+ Delta中性自动对冲。
3️⃣功能维度
- 策略选择:基于行情分析(波动率曲面、希腊值)选择买入看涨/跨式组合等策略。
- 动态管理:
- 加仓/减仓:根据标的资产价格波动调整头寸。
- 自动平仓:熔断机制触发时强制平仓(5分钟波动>15%)。
- 结算履约:行权处理(美式期权实时行权)、资金对账。
4️⃣其他持份者:
- 交易所:上交所(TDGW网关)、深交所(流式报盘30万笔/秒)提供撮合引擎。
- 监管机构:证监会要求KYC生物识别(误识率<0.01%)+ 交易录音存储7年。
- 清算机构:中国结算处理资金划转,多签保险库应对黑天鹅事件。
- 做市商:提供流动性,接受反向手续费补贴(APY达120%)
🧀AWS期权交易系统技术方案设计

一、实时Level 2行情处理方案
目标:毫秒级处理逐笔委托/成交数据(时间戳精度达毫秒级)
1️⃣流数据接入层
- 源数据采集:通过券商API(如Ptrade的get_individual_entrust)获取Level 2行情,推送至Amazon MSK(托管Kafka集群),支持每秒百万级消息写入。
- 协议转换:部署会话边界控制器(SBC)集群处理SIP协议转换,防御DDoS攻击。
2️⃣实时处理层
- 流式ETL:使用AWS Glue Streaming 消费MSK数据,在100秒时间窗口内完成清洗(如过滤无效价格)、格式转换(JSON→Parquet),自动解压缩Snappy格式数据。
- 关键计算:
- 实时计算买卖压力比:基于逐笔委托方向(买/卖)聚合委托量。
- 主力行为识别:通过大单拆解模型分析委托单规模与频率。
3️⃣存储与输出
- 热数据缓存:处理结果写入Amazon ElastiCache for Redis,供实时策略查询(延迟<1ms)。
- 持久化存储:清洗后数据按symbol=SPY/expiry=20240627/分区写入S3 Intelligent-Tiering,自动分层存储。
二、期权理论价实时计算方案
目标:亚毫秒级响应理论价请求(如Black-Scholes模型)
1️⃣无服务器计算引擎
- 请求触发:API Gateway接收定价请求(参数:标的、行权价、波动率等),触发AWS Lambda函数。
- 加速计算:
- Lambda配置 Graviton3处理器(比x86快40%),预热实例减少冷启动。
- 复杂模型(如蒙特卡洛模拟)卸载至EC2 Hpc7a实例(192 vCPU,专为HPC优化)。
2️⃣实时数据依赖
- 低延迟访问:Lambda通过DAX缓存读取Redis中的实时波动率数据,避免直连数据库。
- 模型参数更新:S3存储历史波动率曲面,通过Lambda缓存预热机制预加载至内存。
3️⃣动态资源调度
- 突发流量时,Lambda自动扩展并发实例;持续高负载则迁移至EC2 Auto Scaling组(Spot实例降低成本)
三、批量Greeks计算方案
目标:高效处理大规模持仓组合的希腊值(Delta、Gamma等)
1️⃣分布式计算框架
- 任务调度:AWS Batch自动调度批量任务,根据数据量动态选择资源类型:
- 常规任务:Spot实例(成本降至按需价10%)。
- 紧急任务:预留实例保障资源可用性。
- 并行计算:使用EMR Spark分割持仓组合,跨节点并行计算Greeks。
2️⃣数据优化
- 列式存储:持仓数据以Parquet格式存储于S3,计算时仅扫描所需列(如Delta仅需标的价格列)。
- 分片策略:按行权价范围分片(如strike_300-350.parquet),减少扫描量80%。
3️⃣成本控制
- 竞价实例熔断:设置Spot实例中断阈值,触发时保存中间结果至S3,切换按需实例续算。
- 资源复用:非交易时段复用EC2资源执行风控回测(如压力场景模拟)
四、全局优化与安全设计
1️⃣成本与性能平衡
- 分层资源池:关键服务(Level 2处理)用按需实例,批量任务用Spot实例。
- 智能存储:S3 Intelligent-Tiering自动迁移冷数据至Glacier,存储成本降低70%。
2️⃣高可用与容灾
- 多可用区部署:SBC集群、Redis跨AZ部署,保障99.999% SLA。
- 跨区域备份:S3启用跨区域复制(CRR),数据库用Aurora多活架构(故障恢复<15分钟)。
3️⃣安全合规
- 静态加密:S3/KMS服务端加密(SSE-S3),传输层SSL加密。
- 权限隔离:IAM策略限制量化团队仅能访问Greeks计算资源,审计日志推送至CloudTrail。
五、架构效果对比
| 模块 | 传统方案 | AWS优化方案 |
|---|---|---|
| Level 2处理延迟 | 100ms+ | <10ms(ElastiCache+Glue Streaming) |
| 理论价计算成本 | 固定EC2资源月均$2000+ | Lambda+Spot实例月均$600(降本70%) |
| Greeks批量计算时效 | 小时级(单节点) | 分钟级(EMR Spark并行) |
🚀AWS宏观资产组合配置与风险管理技术方案

一、宏观资产组合配置系统架构 - 风险平价算法引擎
1️⃣数据存储层:使用 Amazon S3 Intelligent-Tiering 存储历史资产收益率、协方差矩阵等数据,支持自动分层存储降低成本。
2️⃣计算层:
- 批量计算:通过 AWS Batch 调度风险平价权重优化任务,使用Python代码(如scipy.optimize)求解非线性规划问题,实现风险贡献均衡。
- 实时更新:部署 Lambda函数 动态响应市场波动,触发协方差矩阵重计算(如波动率突破阈值时)。
3️⃣模型部署:利用 SageMaker 托管风险平价模型API,支持多资产类别(股票、债券、商品)的权重分配请求
# 示例:风险平价权重计算(基于协方差矩阵)
def calculate_risk_parity_weights(cov_matrix):
num_assets = cov_matrix.shape[0]
constraints = ({'type': 'eq', 'fun': lambda x: np.sum(x) - 1})
result = minimize(risk_parity_loss, x0=np.ones(num_assets)/num_assets,
args=(cov_matrix), method='SLSQP', constraints=constraints)
return result.x
优化逻辑
二、实时风险控制系统
1️⃣VaR(风险价值)计算
数据流架构:
- 实时数据接入:通过 Kinesis Data Streams 接收市场行情(价格、波动率),触发 Lambda 计算分钟级VaR。
计算模式:
- 参数法(正态分布假设):使用历史波动率和协方差矩阵快速估算,适用于低延迟场景。
- 蒙特卡洛模拟:部署于 EC2 Hpc6a实例(高CPU算力),模拟10万+路径的潜在损失分布。
动态阈值告警:
- 配置 CloudWatch Alarms 监控VaR突破预设阈值(如95%置信水平),自动触发减仓或对冲指令。
2️⃣压力测试与情景分析
使用 AWS Glue 构建历史极端事件数据集(如2008年金融危机),通过 EMR Spark 并行计算组合在压力场景下的最大回撤。
三、实时保证金结算系统
1️⃣动态保证金计算
数据层:
- DynamoDB 存储实时持仓数据,支持毫秒级读写(如杠杆率、抵押品价值)。
- ElastiCache for Redis 缓存市场实时价格,降低保证金计算的延迟。
计算逻辑:
- 逐笔盯市:Lambda函数监听持仓变动,调用 Step Functions 协调保证金重算流程,公式:
- 保证金要求 = Σ(头寸市值 × 保证金率) - 可用抵押品。
2️⃣爆仓预防与自动平仓
通过 EventBridge 规则引擎,在保证金率低于维持水平时,触发 Prime Brokerage API 强制平仓,并记录审计日志至 CloudTrail。
四、多Prime Brokerage集成方案
1️⃣统一接入层
- API Gateway 封装多经纪商接口(如高盛、摩根士丹利),标准化订单执行、持仓查询等操作。
- AppSync 提供GraphQL接口,支持前端实时展示跨经纪商资产汇总视图。
2️⃣数据一致性保障
使用 DynamoDB Global Tables 实现多区域持仓数据同步,确保跨经纪商的头寸合并计算一致性
五、安全与合规加固
1️⃣数据加密:
静态数据:S3启用 SSE-KMS 加密,DynamoDB启用TDE(透明数据加密)。
传输加密:API Gateway强制HTTPS,经纪商通信使用双向TLS认证。
2️⃣权限隔离:
通过 IAM Roles 限制量化团队仅能访问风险模型,清算团队仅操作保证金结算模块。
3️⃣合规审计:
CloudTrail 记录所有API调用, Macie 自动扫描敏感数据(如客户持仓)
六、成本优化策略
计算资源:风险平价批量任务使用 Spot实例(成本降幅70%),实时VaR计算采用 Lambda预留并发 避免冷启动。
存储优化:历史行情数据归档至 S3 Glacier Deep Archive,存储成本低至$0.004/GB/月。
| 模块 | 传统方案 | AWS优化方案 |
|---|---|---|
| 风险平价计算时效 | 小时级(单节点) | 分钟级(AWS Batch并行) |
| VaR计算延迟 | 10秒+(本地服务器) | <1秒(Kinesis+Lambda流处理) |
| 爆仓响应速度 | 人工干预(分钟级) | 自动化触发(毫秒级) |
关键模块解析
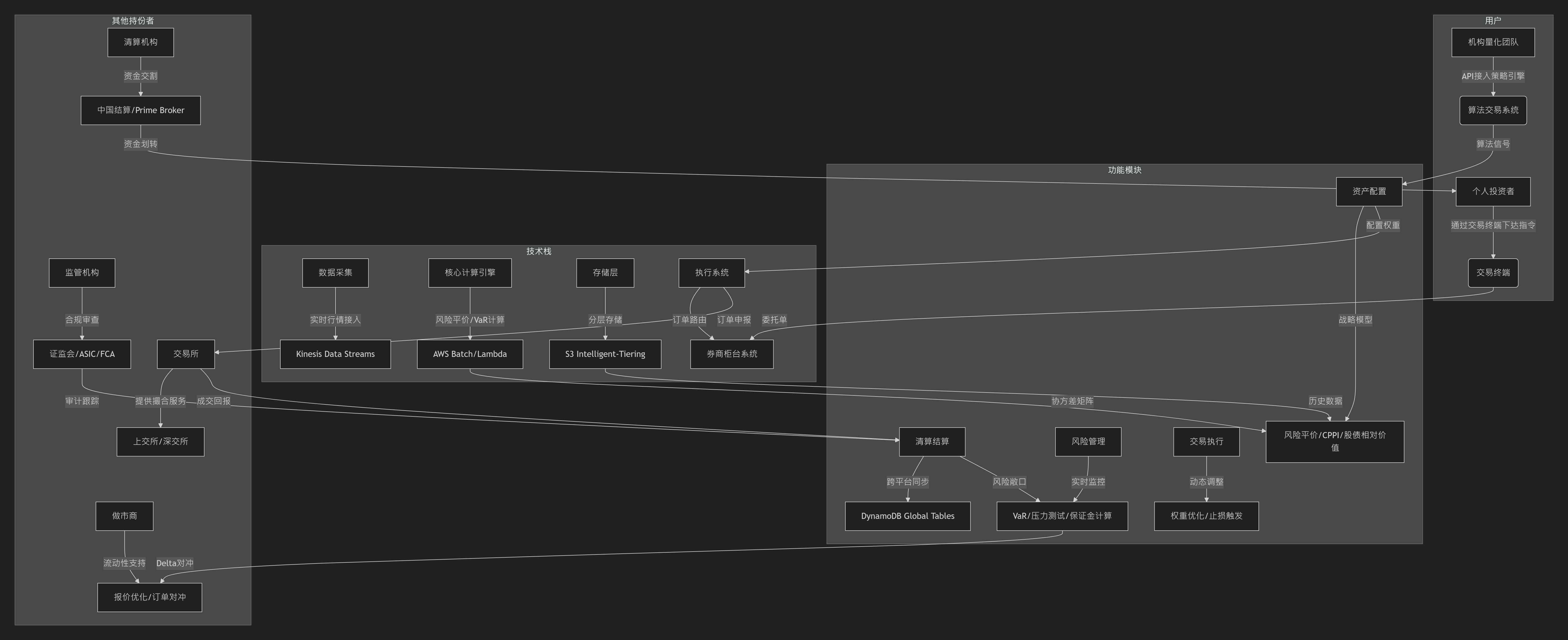
1️⃣用户维度
个人投资者:通过交易终端(如EBC的MT4/5)手动操作,依赖预设策略模板(如固定比例模型)。
机构量化团队:通过API接入自主开发的算法引擎(如Python量化库+TensorFlow模型),执行高频调仓。
2️⃣技术栈维度
数据层:
- 实时行情:通过Kinesis处理Level 2数据(每秒50万+条),使用LLT指标平滑噪声。
- 历史数据:按资产类别/时间分区存储于S3,启用Glacier归档冷数据。
计算层:
- 风险平价模型:用AWS Batch调度非线性规划求解,协方差矩阵基于1年历史数据滚动计算。
- VaR计算:Lambda函数触发蒙特卡洛模拟(10万+路径),结果缓存至ElastiCache。
3️⃣功能模块维度
资产配置策略:
- 战略层:季度调整(如风险平价模型权重),战术层:月度动态优化(宏观PMI+技术面LLT指标)。
- 极端行情熔断:5分钟内波动超15%触发强制平仓,通过EventBridge同步至所有系统。
风控闭环:
- 保证金动态计算:DynamoDB记录实时持仓,公式保证金=Σ(头寸市值×保证金率)-可用抵押品。
- 合规审计:CloudTrail记录所有API操作,Macie扫描敏感数据泄露风险。
4️⃣持份者维度
Prime Broker:
- 集中管理多LP流动性(如JP Morgan、UBS),统一结算降低保证金占用。
- 提供POP服务:将主经纪商信用额度拆分给中小交易商,支持跨平台头寸合并。
做市商:
- 报价优化:通过EBC交易黑盒匹配85%订单至更优价格,隐藏大单避免滑点。
- 流动性分层:一级做市商(如德意志银行)提供批发报价,二级做市商服务零售客户
对比Hive、Presto、Spark、HBase、Hue与Ganglia六大工具
| 技术 | 类型 | 定位特点 | 查询延迟 | 数据规模 | 使用场景 | 典型架构角色 |
|---|---|---|---|---|---|---|
| Hive | 查询引擎 | 批处理ETL,类SQL接口 | 分钟~小时级 | PB级 | 离线数仓,海量数据处理 | 数据清洗与存储 |
| Presto | 查询引擎 | 交互式分析,ANSI SQL | 亚秒~分钟级 | GB~TB级 | 即席查询,联邦分析 | 实时查询服务 |
| Spark | 计算引擎 | 通用内存计算,一站式处理 | 秒~分钟级 | TB~PB级 | 流处理,ML,复杂分析 | 批流一体计算层 |
| HBase | 存储引擎 | 列式NoSQL,高并发读写 | 毫秒级 | PB级 | 实时存储,点查/范围查 | 在线数据存储 |
| Hue | 可视化工具 | Hadoop生态Web UI | - | - | 开发调试,集群操作 | 用户操作界面 |
| Ganglia | 监控系统 | 集群资源度量收集 | 秒级(监控) | - | 集群健康监控,资源预警 | 运维监控层 |
🧠 一、技术定位与核心功能
Hive
- 定位:基于Hadoop的数据仓库工具,提供类SQL接口(HiveQL),将查询转化为MapReduce/Tez/Spark任务。
- 特点:支持ACID事务(Hive 3+)、复杂ETL、UDF扩展,适合离线批处理(分钟~小时级延迟)。
- 局限:高延迟,不适用于实时查询。
Presto
- 定位:分布式SQL查询引擎,专为交互式分析设计,采用内存计算模型(MPP架构)。
- 特点:亚秒~秒级响应,支持ANSI SQL标准及跨数据源联邦查询(如Hive、MySQL、Kafka)。
- 局限:严格内存限制,大表JOIN易OOM;不适合长时间任务(>30分钟)。
Spark
- 定位:通用内存计算引擎,支持批处理、流处理、机器学习(MLlib)和图计算(GraphX)。
- 特点:一站式处理能力,通过DataFrame/DataSet API优化执行计划,比MapReduce快100倍。
- 生态:整合SQL(Spark SQL)、流(Structured Streaming)、库内分析(与HBase集成)。
HBase
- 定位:分布式NoSQL数据库(列式存储),基于Google Bigtable设计。
- 特点:高吞吐随机读写,支持海量稀疏数据存储,适用于实时读写场景(如风控、推荐系统)。
- 局限:无内置分析能力,需依赖Spark或Presto进行复杂计算。
Hue
- 定位:Hadoop生态的Web UI工具,提供可视化操作界面。
- 功能:支持HDFS文件管理、Hive查询提交、Pig脚本执行、HBase数据浏览等。
Ganglia
- 定位:分布式集群监控系统,专注于资源度量收集。
- 功能:实时监控CPU、内存、网络等指标,低开销,支持自定义插件扩展。
⚙️ 二、架构与性能对比
查询引擎类(Hive vs Presto vs Spark)
| 维度 | Hive | Presto | Spark |
|---|---|---|---|
| 执行引擎 | MapReduce/Tez/Spark(磁盘IO) | MPP内存流水线(无中间落盘) | DAG内存计算(RDD/DataFrame) |
| 延迟 | 分钟~小时级 | 亚秒~分钟级 | 秒~分钟级(批处理) |
| 数据规模 | PB级,适合超大数据集 | GB~TB级,内存受限 | TB~PB级,弹性扩展 |
| SQL兼容性 | HiveQL,扩展UDF | ANSI SQL标准 | Spark SQL(兼容Hive语法) |
典型优化:
- Hive:分区裁剪、向量化
- Presto:动态过滤、谓词下推
- Spark:Catalyst优化器、Tungsten内存管理
存储与管理类(HBase vs Hue vs Ganglia)
- HBase:列族存储、LSM树结构,写优化>读优化。
- Hue:轻量Web层,无独立计算能力,依赖后端引擎(如Hive/Impala)。
- Ganglia:分布式gmond代理+中央聚合,支持横向扩展
🚀 三、适用场景分析
离线ETL & 数仓构建
- Hive:海量数据清洗、T+1报表生成(例:金融业月度对账)。
- Spark:复杂流水线(ETL+ML训练一体化),替代MapReduce(例:电商用户行为分析)。
交互式分析
- Presto:即席查询(Ad-hoc)、多源联邦分析(例:跨Hive与MySQL的实时报表)。
- Spark SQL:需结合ML或流处理的场景(例:实时推荐模型迭代)。
实时存储与计算
- HBase+Spark:
- HBase存储实时数据(例:风控事中拦截);
- Spark Streaming处理流数据(例:Kafka日志实时聚合入库)。
运维监控与可视化
- Ganglia:集群健康度监控(例:HDFS磁盘预警)。
- Hue:开发调试界面(例:数据工程师直接提交HiveQL)
四、生态整合与协同方案
- Hive+Presto:Hive管理元数据与存储,Presto加速查询。
- HBase+Spark:HBase作实时存储,Spark批处理/流处理分析。
- 统一监控:Ganglia收集指标 + Hue提供操作入口,形成管理闭环
五、选型决策关键点
数据规模与延迟
- PB级离线 → Hive;
- TB级交互 → Presto;
- 实时计算+ML → Spark。
功能需求
- 事务支持 → Hive 3+;
- 跨源查询 → Presto;
- 高并发点查 → HBase。
运维成本
- 轻量监控 → Ganglia;
- 开发效率 → Hue。
Amazom EMR vs Clickhouse
⚙️ 一、架构定位与核心能力
| 维度 | ClickHouse | Amazon EMR |
|---|---|---|
| 核心定位 | 开源列式 OLAP 数据库,专为实时分析优化 | 托管式大数据平台,集成 Hadoop/Spark/Hive 等生态组件 |
| 架构模型 | 单机或分布式 MPP,无中心节点 | 主从架构(Master/Core/Task 节点) |
| 数据存储 | 本地存储 + MergeTree 引擎(LSM 树变种) | 分离式计算与存储(依赖 S3/OSS 等对象存储) |
| 计算引擎 | 内置向量化引擎,SQL 执行器 | 支持多引擎(Spark、Presto、Hive、Flink 等) |
| 扩展性 | 需手动分片+副本(依赖 ZooKeeper) | 自动扩缩容,支持 Spot 实例降低成本 |
关键差异:
- 数据模型:ClickHouse 为列式存储,适合宽表聚合;EMR 支持多种存储格式(Parquet/ORC),但依赖外部计算引擎处理。
- 实时性:ClickHouse 写入吞吐高(>100K rows/s),适合实时看板;EMR 实时能力依赖流计算引擎(如 Spark Streaming)。
- 事务支持:两者均不擅长高频事务,ClickHouse 仅支持批量 Upsert,EMR 需依赖 HBase 等组件
⚡ 二、性能与适用场景对比
1. 查询性能
ClickHouse
- 优势:单表聚合/过滤极快(亚秒级),向量化引擎 + SIMD 指令优化。
- 局限:多表 JOIN 性能弱,内存敏感(大 JOIN 易 OOM);不适合点查询。
- 案例:用户行为分析、实时 BI 报表(如电商大促看板)。
Amazon EMR
- 优势:复杂 ETL 流水线支持好(Spark/Hive),多引擎适配复杂计算场景。
- 局限:冷启动延迟高(集群初始化需分钟级),交互式查询需 Presto/Spark SQL 加速
2. 典型场景
| 场景 | 推荐选择 | 原因 |
|---|---|---|
| 实时看板/Ad-hoc 查询 | ClickHouse | 亚秒级响应,无需启动集群 |
| 复杂 ETL 流水线 | EMR + Spark | 多引擎协同(Spark 批处理 + Hive 元数据管理) |
| 海量事件分析 | ClickHouse | 高吞吐写入 + 时间序列优化(如日志分析) |
| 跨源联邦查询 | EMR + Presto | 支持查询 S3 数据湖 + Hive 表 |
| 机器学习集成 | EMR + Spark MLlib | 一站式 ML 训练与部署 |
💡 混合架构案例:
使用 EMR 处理离线流水线(Hudi 数据湖) + Presto 联邦查询 + 自建 ClickHouse 加速实时报表,降低存储成本。
💰 三、成本与运维复杂度
| 维度 | ClickHouse | Amazon EMR |
|---|---|---|
| 硬件成本 | 自建成本低(同规格 EC2 节省 50%) | 按需付费,Spot 实例可降 70% |
| 存储成本 | 支持冷热分层(S3 + 本地 SSD) | 依赖 S3,存储成本透明但需网络流量费 |
| 运维成本 | 需专职团队维护(分片/ZK 协调) | 全托管,监控集成 CloudWatch |
| 弹性伸缩 | 手动扩缩容 | 自动 Scale(基于 CPU/内存指标) |
优化实践:
- EMR 成本控制:使用 定时集群(夜间启动)+ 弹性网卡保留 IP,避免 24 小时运行。
- ClickHouse 压缩优势:列存压缩比高(5-10x),存储成本仅为 Redshift 的 25%
⚠️ 四、局限性与应对方案
ClickHouse 痛点
- JOIN 性能弱:避免多表关联,改用宽表预聚合。
- ZooKeeper 依赖:运维复杂度高,建议使用云托管版(如阿里云 EMR ClickHouse)。
- 实时更新限制:仅支持分区级批量更新,非实时行级修改。
Amazon EMR 痛点
- 冷启动延迟:预热集群或使用长期运行 Task 节点。
- 版本兼容性:开源组件版本可能滞后,需测试适配(如 Flink 商业版 VVR)。
- IP 动态变化:通过弹性网卡绑定固定 IP 解决。
🔧 五、生态整合与选型建议
生态协同
- ClickHouse + EMR:
- EMR 处理原始数据 → S3 存储 → ClickHouse 加速查询。
- 案例:实时监控数据经 Flink 清洗后写入 ClickHouse + Grafana 展示。
EMR 内部整合:
- Hive 元数据 + Spark 计算 + Presto 交互查询,统一调度(Airflow/Step Functions)
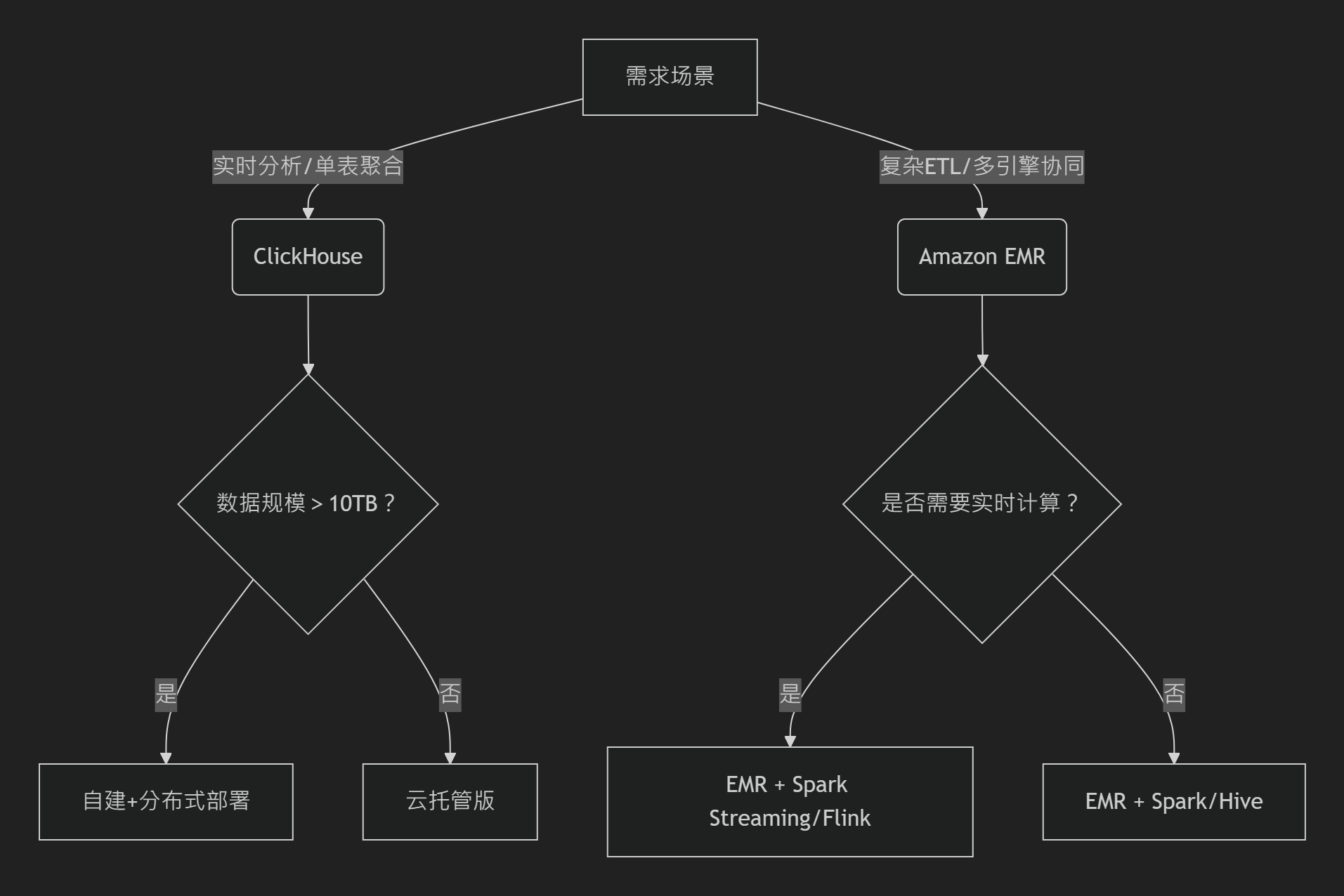
决策关键点:
- 选 ClickHouse:实时性要求高、写入密集、成本敏感、自研能力强。
- 选 EMR:需全托管、复杂流水线、跨组件协同、企业级 SLA 保障。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号