5、request的使用
""" 输入一个网址,浏览器会等待服务器返回 服务器返回东西之后,浏览器会将服务器给的东西进行展示 请求:你向服务器发送一条消息,要东西 响应:服务器返回一些消息,返回东西 渲染:浏览器会把服务器返回的消息,展示给用户 数据是在服务器里变成页面源代码的 第一种请求方式: 如果页面源代码里有 数据 ,服务器渲染数据成页面源代码的 resp.read() => 页面源代码 => 提纯 => 保存 第二种请求方式: 不是所有的网站都是把数据直接加载到页面源代码上的 输入网址后,服务器返回一个页面源代码,可能会缺少一些数据 在一个特殊的情况下,会触发一个新的请求, 这个新的请求专门用来请求数据 服务器返回数据后,浏览器执行一些脚本,把数据渲染到浏览器上给用户使用 Elements(当前页面状况代码) 并不等于页面源代码 """
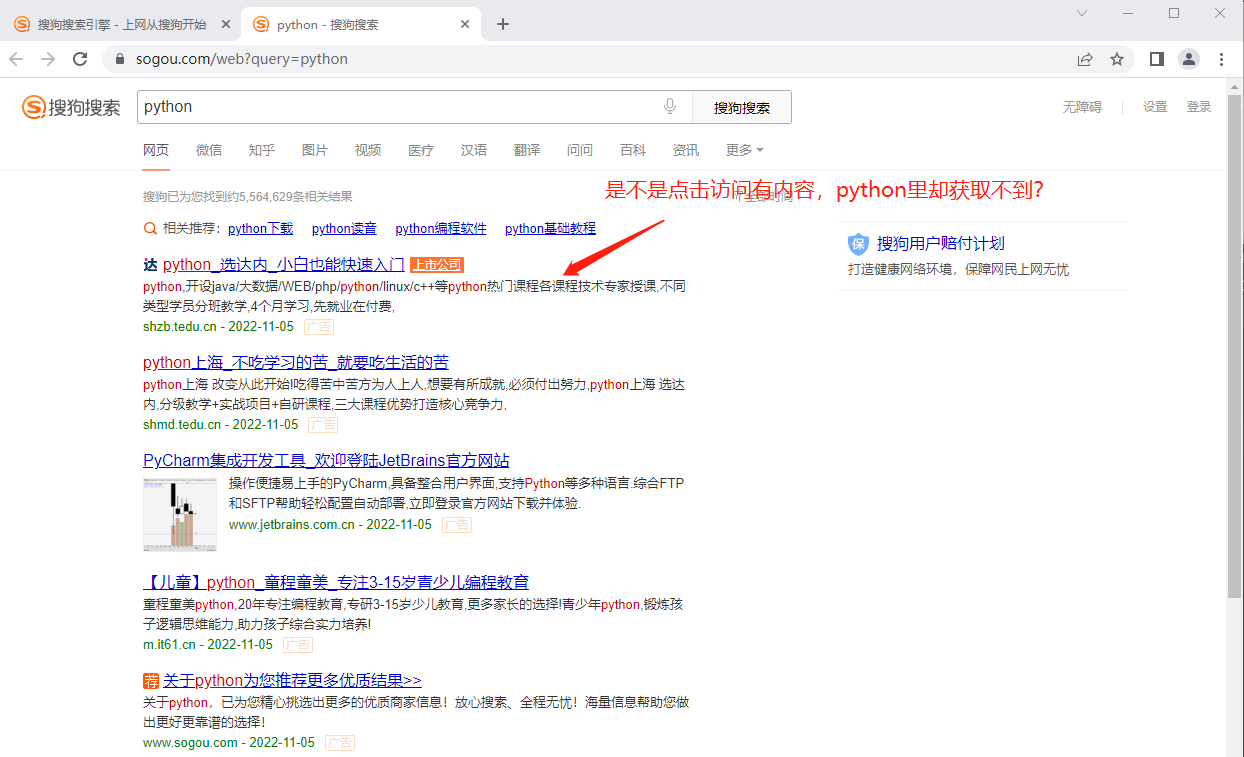
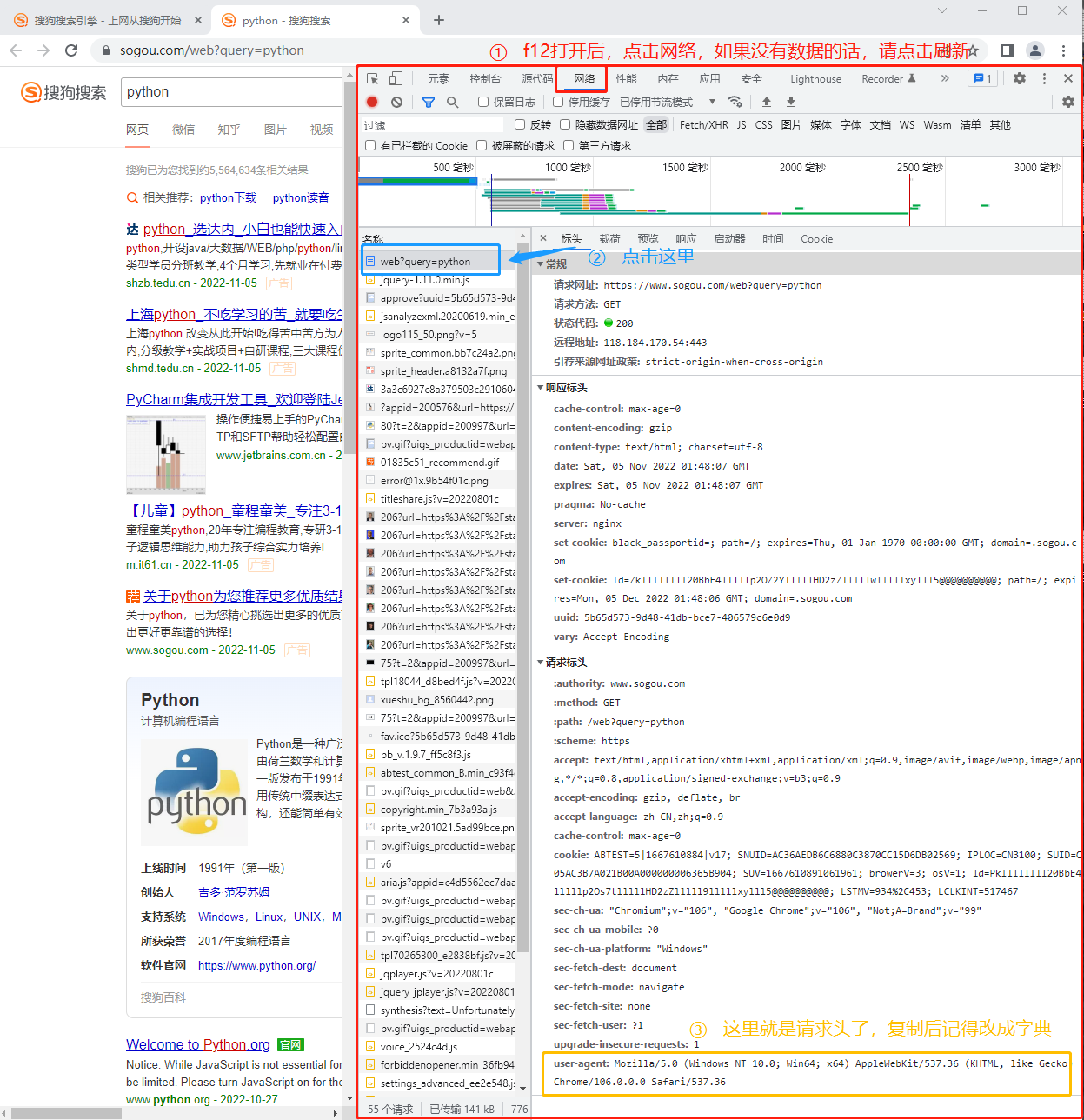
# 导入request模块 import requests # requests 的核心功能就是发送请求 url = "https://www.sogou.com/web?query=python" # 发送请求 resp = requests.get(url) # get请求 # requests.post() # post请求 # 获得状态码 print(resp) # 获得网面源代码 page_resp = resp.text print(page_resp) # 仔细看看是不是获得的数据与期望得到的不一样? # 是因为被网页识别出我们的访问方式有问题 print(resp.request.headers) # 查看自己的请求头,很容易就发现自己是通过python访问,所以被浏览器拒绝了。 # 开始修改请求头,首先要获得请求头(具体下面有图片) headers = { # 下面的内容不要手写, 复制粘贴最安全 "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.82 Safari/537.36" } resp = requests.get(url, headers=headers) # 拿到页面源代码 page_resp = resp.text print(page_resp) # 终于可以获得自己想要的数据了把

 浙公网安备 33010602011771号
浙公网安备 33010602011771号