Python分析新型冠状病毒趋势
前瞻
据世卫组织称,新型冠状病毒是一个病毒大家族,它们引起的疾病很多,包括普通感冒和更严重的疾病,武汉乃至全中国都拟被按下暂停键,整个世界从来没有像现在这样安静。新型冠状病毒是一种新的病毒株,此前尚未被人类发现。此前,据《纽约时报》的一篇报道,确诊感染人数上升至 37198 人,中国死亡人数上升至811人,超过了非典疫情造成的死亡人数。更糟糕的是,中国股市暴跌,全球股市受到了影响。一些分析人士预测,疫情对全球经济构成的威胁,有可能引发深远的政治后果。对于我来说,正好是学习的机会。我就带领大家分析一下新型冠状病毒的爆发趋势,也借此作为一次数据分析课程的案例,从数据获取、数据清洗、数据可视化再到产出数据结论,完整的走一遍数据分析流程。
数据来源
GitHub中文社区
大数据(数据集)设计方案
大数据源
世界疫情数据名为COVID-19.cvs,筛选出国家为中国的所有数据集。
方案分析
①查看数据维度,描述统计,重复值,缺失值等了解数据组成。
②数据清洗主要为删除重复值和省份以及城市的有缺失的。
③主要筛选中国和武汉疫情测进行分析。
数据预览及简单处理
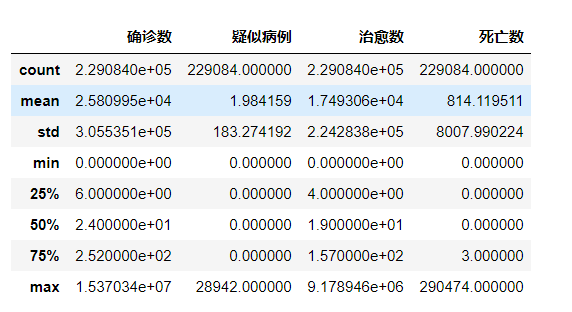
import pandas as pd import warnings warnings.filterwarnings('ignore') df=pd.read_csv('COVID-19.csv',encoding='gbk') #查看前10行数据 df.head(10) #数据维度 df.shape #数据描述 df.info() #数据描述性统计 df.describe()
运行截图:
数据清理
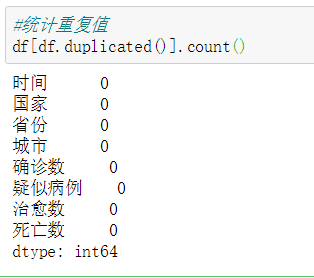
第一:删除重复值
从数据中我们可以看出,统计重复值,是对我们的分析看下有没有重复的数据,如果有重复的数据进行删除。
#统计重复值
df[df.duplicated()].count()
运行截图:
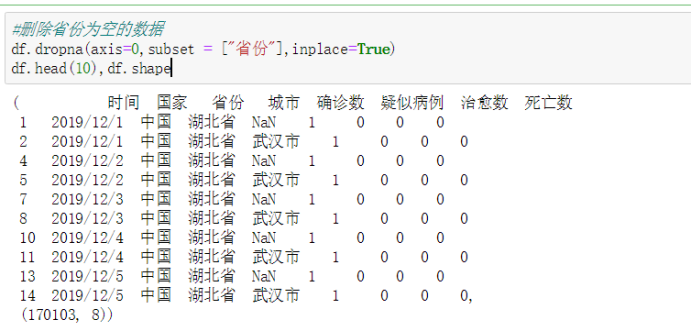
第二:删除省份为空的数据
从数据中我们可以看出,进行对省份为空的数据进行删除,这对我们的分析来说没有实际意义,所以进行删除的操作。
#删除省份为空的数据 df.dropna(axis=0,subset = ["省份"],inplace=True) df.head(10),df.shape
运行结果:
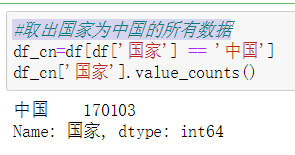
第三:取出国家为中国的所有新型冠状病毒数据
从数据中我们可以看出,有上万新型冠状病毒数据是中国的。
#取出国家为中国的所有数据 df_cn=df[df['国家'] == '中国'] df_cn['国家'].value_counts()
运行截图:
中国数据集进行省份分组
从每个省份的疫情确诊最终数据,绘制出疫情地图。
from pyecharts.charts import Map,Page,Timeline,Bar from pyecharts import options as opts import re #对数据进行分组,取得每个省份最后累计的最大确诊数 df_cn_groupby=df[['省份','确诊数']].groupby(by='省份',as_index=False).max() df_cn_groupby ls1=[] for i in df_cn_groupby.index: ls2=[] ls2.append(re.sub(r'[省市]','',df_cn_groupby.loc[i]["省份"])) ls2.append(df_cn_groupby.loc[i]["确诊数"]) ls1.append(ls2) ls1
运行截图:

构建全国疫情地图
ls1=[['上海', 1370],['云南', 221],['内蒙古', 336],['北京', 952],['台湾', 718],['吉林', 157],['四川', 820],['天津', 301], ['宁夏', 75],['安徽', 992],['山东', 857],['山西', 222],['广东', 2007], ['广西', 263], ['新疆', 980], ['江苏', 680], ['江西', 937], ['河北', 373], ['河南', 1295], ['浙江', 1295], ['海南', 171], ['湖北', 68149], ['湖南', 1020], ['澳门', 46], ['甘肃', 182], ['福建', 500], ['西藏', 1], ['贵州', 147], ['辽宁', 289], ['重庆', 590], ['陕西', 502], ['青海', 18], ['香港', 7075], ['黑龙江', 949]] m=(Map() .add("全国疫情累计确诊人数",ls1,"china",is_map_symbol_show=False) .set_global_opts( title_opts=opts.TitleOpts(title="疫情总览图"), visualmap_opts=opts.VisualMapOpts(max_=100000,min_=0,is_piecewise=True, pieces=[ {"min":20000,"label":"大于20000"}, {"min":2000,"max":19999,"label":"大于19999"}, {"min":1000,"max":1999,"label":"大于999"}, {"min":400,"max":999,"label":"大于399"}, {"min":200,"max":399,"label":"大于199"}, {"min":100,"max":199,"label":"大于100"}, {"min":0,"max":99,"label":"大于0"}, ]) )) m.render_notebook()
运行截图:
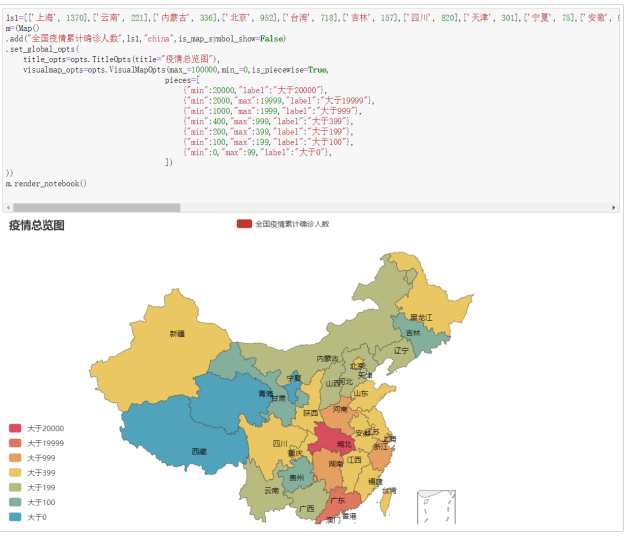
数据可视化
全国疫情走势折线图(确诊-治愈-死亡)
import numpy as np import matplotlib as mpl import matplotlib.pyplot as plt df_cn_time=df[['时间','确诊数','治愈数','死亡数']].groupby(by='时间',as_index=False).sum() df_cn_time
运行截图:

num1=[] #确诊数 num2=[] #治愈数 num3=[] #死亡数 times=[] for i in df_cn_time.index: times.append(df_cn_time.loc[i]['时间']) num1.append(df_cn_time.loc[i]['确诊数']) num2.append(df_cn_time.loc[i]['治愈数']) num3.append(df_cn_time.loc[i]['死亡数']) total=[] for i in range(len(num1)): total.append(int(num1[i]-num2[i]-num3[i])) plt.figure(figsize=(20,15)) plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 plt.rcParams['axes.unicode_minus']=False #用来正常显示负号 plt.xticks([]) plt.ylabel('number', fontdict={'weight': 'normal', 'size': 15}) plt.title(u'The epidemic chart',fontdict={'weight':'normal','size': 20}) plt.plot(times, total,color='red') plt.show()
运行截图:

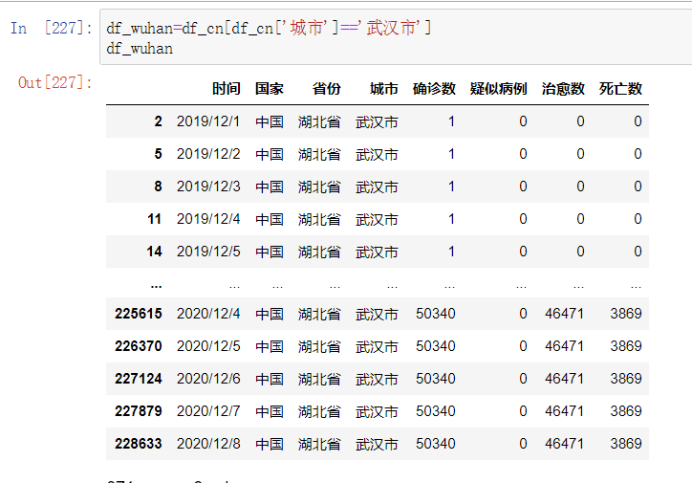
武汉疫情分析
武汉是中国四大科教中心城市之一,武汉成为继北京、上海之后,全国第三个拥有“双国家制造业创新中心”的城市。因为武汉是中国地区发生最严重的地区,也作为中国最重要的城市之一,也具有标志性的,所以最后用武汉来拟合预测。
df_wuhan=df_cn[df_cn['城市']=='武汉市'] df_wuhan #选取武汉每15天的数据进行可视化,由于最后会平缓,所以去掉最后两百天 df_wuhan.reset_index(drop=True, inplace=True) #重0开始排列索引 df_wuhan ls_1=[] #确诊数 ls_2=[]#治愈数 ls_3=[]#死亡数 ls_4=[]#日期 for i in range(0,len(df_wuhan)-200,15): ls_1.append(df_wuhan.loc[i]['确诊数']) ls_2.append(df_wuhan.loc[i]['治愈数']) ls_3.append(df_wuhan.loc[i]['死亡数']) ls_4.append(df_wuhan.loc[i]['时间']) plt.figure(figsize=(15,15)) plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签 plt.rcParams['axes.unicode_minus']=False #用来正常显示负号 plt.ylabel('number', fontdict={'weight': 'normal', 'size': 15}) plt.title(u'The epidemic chart',fontdict={'weight':'normal','size': 20}) plt.plot(ls_4, ls_1,color='red',label='Confirmed the number') plt.plot(ls_4, ls_2,color='blue',label='Number of cure') plt.plot(ls_4, ls_3,color='black',label='Number of deaths') plt.legend() plt.show()
运行截图:
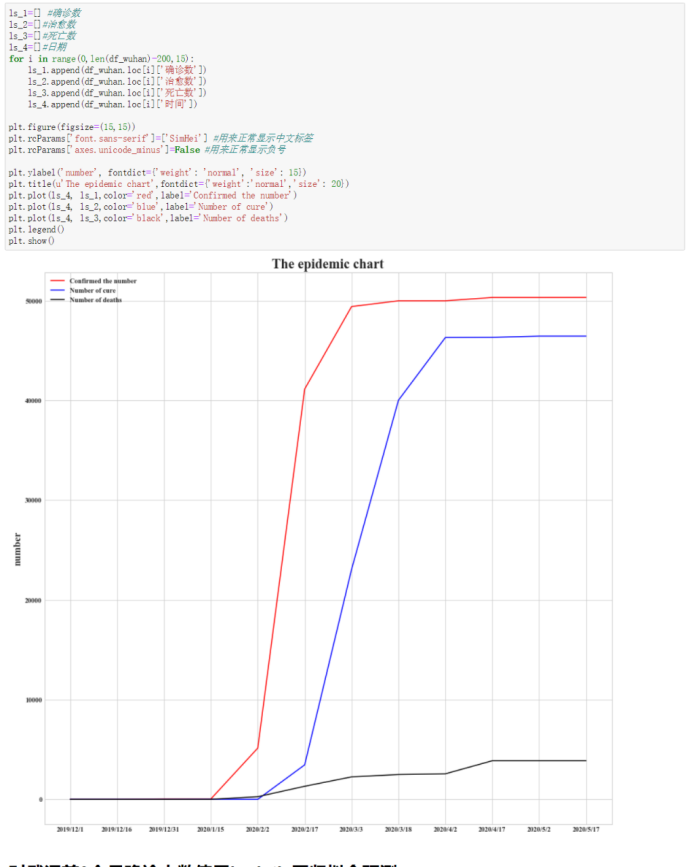
对武汉前3个月确诊人数使用logistic回归拟合预测
import numpy as np #导入数值计算模块 import pandas as pd #导入数据处理模块 import matplotlib.pyplot as plt #导入绘图模块 from scipy.optimize import curve_fit #导入拟合模块 plt.rcParams["font.sans-serif"]="SimHei" #黑体中文 plt.rcParams["axes.unicode_minus"]=False #显示负号 #取前3个月数据 df_wuhan_data=df_wuhan[df_wuhan.index<90] date=df_wuhan_data['时间'] #日期 confirm=df_wuhan_data['确诊数'] #确诊数 t=range(len(confirm)) #构造横轴 fig=plt.figure(figsize=(20,20)) #建立画布 ax=fig.add_subplot(1, 1, 1) ax.scatter(t,confirm, color="k", label="Confirmed the number") #真实数据散点图 #ax.set_xlabel("天数") #横坐标 ax.set_ylabel("number",fontdict={'weight':'normal','size': 20}) #纵坐标 ax.set_title("Wu Han",fontdict={'weight':'normal','size': 20}) #标题 def logistic(t,K,P0,r): #定义logistic函数 exp_value=np.exp(r*(t)) return (K*exp_value*41)/(K+(exp_value-1)*41) coef, pcov = curve_fit(logistic, t, confirm) #拟合 print(coef) #logistic函数参数 y_values = logistic(t,coef[0], coef[1], coef[2]) #拟合y值 ax.plot(t,y_values,color="blue", label="fitting") #画出拟合曲线 x=np.linspace(50,56,60) #构造日期 y_predict=logistic(x,coef[0], coef[1], coef[2]) #未来预测值 ax.scatter(x,y_predict, color="green",label="predict") #未来预测散点 ax.legend() #加标签

全部代码:
1 #导入pandas库,用于处理数据 2 import pandas as pd 3 4 import warnings 5 6 warnings.filterwarnings('ignore') 7 8 #读取数据 9 df=pd.read_csv('COVID-19.csv',encoding='gbk') 10 11 #查看前10行数据 12 df.head(10) 13 14 #数据维度 15 df.shape 16 17 #数据描述 18 df.info() 19 20 #数据描述性统计 21 df.describe() 22 23 #统计重复值 24 df[df.duplicated()].count() 25 26 #删除省份为空的数据 27 df.dropna(axis=0,subset = ["省份"],inplace=True) 28 df.head(10),df.shape 29 30 #取出国家为中国的所有数据 31 df_cn=df[df['国家'] == '中国'] 32 df_cn['国家'].value_counts() 33 34 #导入绘图相关库 35 from pyecharts.charts import Map,Page,Timeline,Bar 36 from pyecharts import options as opts 37 38 #导入正则表达式库 39 import re 40 41 #对数据进行分组,取得每个省份最后累计的最大确诊数 42 df_cn_groupby=df[['省份','确诊数']].groupby(by='省份',as_index=False).max() 43 df_cn_groupby 44 45 #用于保存各省份 46 ls1=[] 47 for i in df_cn_groupby.index: 48 ls2=[] 49 50 #正则表达式过滤不需要字符 51 ls2.append(re.sub(r'[省市]','',df_cn_groupby.loc[i]["省份"])) 52 ls2.append(df_cn_groupby.loc[i]["确诊数"]) 53 ls1.append(ls2) 54 ls1 55 ls1=[['上海', 1370],['云南', 221],['内蒙古', 336],['北京', 952],['台湾', 718],['吉林', 157],['四川', 820],['天津', 301],['宁夏', 75],['安徽', 992],['山东', 857],['山西', 222],['广东', 2007], ['广西', 263], ['新疆', 980], ['江苏', 680], ['江西', 937], ['河北', 373], ['河南', 1295], ['浙江', 1295], ['海南', 171], ['湖北', 68149], ['湖南', 1020], ['澳门', 46], ['甘肃', 182], ['福建', 500], ['西藏', 1], ['贵州', 147], ['辽宁', 289], ['重庆', 590], ['陕西', 502], ['青海', 18], ['香港', 7075], ['黑龙江', 949]] 56 57 #绘制地图 58 m=(Map() 59 .add("全国疫情累计确诊人数",ls1,"china",is_map_symbol_show=False) 60 .set_global_opts( 61 title_opts=opts.TitleOpts(title="疫情总览图"), 62 visualmap_opts=opts.VisualMapOpts(max_=100000,min_=0,is_piecewise=True, 63 pieces=[ 64 {"min":20000,"label":"大于20000"}, 65 {"min":2000,"max":19999,"label":"大于19999"}, 66 {"min":1000,"max":1999,"label":"大于999"}, 67 {"min":400,"max":999,"label":"大于399"}, 68 {"min":200,"max":399,"label":"大于199"}, 69 {"min":100,"max":199,"label":"大于100"}, 70 {"min":0,"max":99,"label":"大于0"}, 71 ]) 72 )) 73 74 #展示地图 75 m.render_notebook() 76 import numpy as np 77 import matplotlib as mpl 78 import matplotlib.pyplot as plt 79 #将数据按照指标分组并求和 80 df_cn_time=df[['时间','确诊数','治愈数','死亡数']].groupby(by='时间',as_index=False).sum() 81 df_cn_time 82 83 #确诊数 84 num1=[] 85 86 #治愈数 87 num2=[] 88 89 #死亡数 90 num3=[] 91 92 #时间 93 times=[] 94 for i in df_cn_time.index: 95 times.append(df_cn_time.loc[i]['时间']) 96 num1.append(df_cn_time.loc[i]['确诊数']) 97 num2.append(df_cn_time.loc[i]['治愈数']) 98 num3.append(df_cn_time.loc[i]['死亡数']) 99 total=[] 100 #循环遍历求出确诊数-治愈数-死亡数 101 for i in range(len(num1)): 102 total.append(int(num1[i]-num2[i]-num3[i])) 103 104 plt.figure(figsize=(20,15)) 105 #用来正常显示中文标签 106 107 plt.rcParams['font.sans-serif']=['SimHei'] 108 #用来正常显示负号 109 110 plt.rcParams['axes.unicode_minus']=False 111 #将x轴标签去掉 112 113 plt.xticks([]) 114 #设置y轴标签并设置字号字体 115 116 plt.ylabel('number', fontdict={'weight': 'normal', 'size': 15}) 117 #设置标题 118 119 plt.title(u'The epidemic chart',fontdict={'weight':'normal','size': 20}) 120 #画曲线 121 122 plt.plot(times, total,color='red') 123 #展示图片 124 plt.show() 125 126 #取出武汉市数据 127 df_wuhan=df_cn[df_cn['城市']=='武汉市'] 128 df_wuhan 129 130 #选取武汉每15天的数据进行可视化,由于最后会平缓,所以去掉最后两百天 131 df_wuhan.reset_index(drop=True, inplace=True) 132 133 #重0开始排列索引 134 df_wuhan 135 #确诊数 136 ls_1=[] 137 138 #治愈数 139 ls_2=[] 140 141 #死亡数 142 ls_3=[] 143 144 #日期 145 ls_4=[] 146 for i in range(0,len(df_wuhan)-200,15): 147 ls_1.append(df_wuhan.loc[i]['确诊数']) 148 ls_2.append(df_wuhan.loc[i]['治愈数']) 149 ls_3.append(df_wuhan.loc[i]['死亡数']) 150 ls_4.append(df_wuhan.loc[i]['时间']) 151 152 #设置画布大小 153 plt.figure(figsize=(15,15)) 154 155 #用来正常显示中文标签 156 157 plt.rcParams['font.sans-serif']=['SimHei'] 158 #用来正常显示负号 159 160 plt.rcParams['axes.unicode_minus']=False 161 162 #设置y轴标签 163 plt.ylabel('number', fontdict={'weight': 'normal', 'size': 15}) 164 165 #设置标题 166 plt.title(u'The epidemic chart',fontdict={'weight':'normal','size': 20}) 167 #绘制多个曲线 168 plt.plot(ls_4, ls_1,color='red',label='Confirmed the number') 169 170 plt.plot(ls_4, ls_2,color='blue',label='Number of cure') 171 172 plt.plot(ls_4, ls_3,color='black',label='Number of deaths') 173 174 plt.legend() 175 176 plt.show() 177 178 import numpy as np 179 #导入数值计算模块 180 181 import pandas as pd 182 #导入数据处理模块 183 184 import matplotlib.pyplot as plt 185 #导入绘图模块 186 187 from scipy.optimize import curve_fit 188 #导入拟合模块 189 190 plt.rcParams["font.sans-serif"]="SimHei" 191 #黑体中文 192 193 plt.rcParams["axes.unicode_minus"]=False 194 #显示负号 195 196 #取前3个月数据 197 df_wuhan_data=df_wuhan[df_wuhan.index<90] 198 199 #日期 200 date=df_wuhan_data['时间'] 201 202 #确诊数 203 confirm=df_wuhan_data['确诊数'] 204 205 #构造横轴 206 t=range(len(confirm)) 207 #建立画布 208 fig=plt.figure(figsize=(20,20)) 209 ax=fig.add_subplot(1, 1, 1) 210 #真实数据散点图 211 ax.scatter(t,confirm, color="k", label="Confirmed the number") 212 #横坐标 213 #ax.set_xlabel("天数") 214 #纵坐标 215 ax.set_ylabel("number",fontdict={'weight':'normal','size': 20}) 216 #标题 217 ax.set_title("Wu Han",fontdict={'weight':'normal','size': 20}) 218 219 #定义logistic函数 220 def logistic(t,K,P0,r): 221 exp_value=np.exp(r*(t)) 222 return (K*exp_value*41)/(K+(exp_value-1)*41) 223 #拟合 224 225 coef, pcov = curve_fit(logistic, t, confirm) 226 #logistic函数参数 227 228 print(coef) 229 #拟合y值 230 y_values = logistic(t,coef[0], coef[1], coef[2]) 231 232 #画出拟合曲线 233 ax.plot(t,y_values,color="blue", label="fitting") 234 #构造日期 235 236 x=np.linspace(50,56,60) 237 #未来预测值 238 239 y_predict=logistic(x,coef[0], coef[1], coef[2]) 240 #未来预测散点 241 242 ax.scatter(x,y_predict, color="green",label="predict") 243 #加标签 244 ax.legend()
总结
本次分析采用了github中文社区的开源数据集,分析了中国从2019年12月到2020年12月的疫情相关情况,通过疫情期间确诊人数、治愈人数以及死亡人数的变化情况及趋势,可以发现中国疫情情况随着时间的推移形势越来越好,到最后已基本控制住了,最后本文选取疫情重灾区武汉市进行有关分析,并通过Logistic函数对疫情发展时间和确诊人数进行了拟合,并用图表展示,拟合效果良好,并可从拟合得到模型预测后几天疫情发展趋势,所以该方法具有一定意义。在本次分析中,我学会了数据分析的一些基本流程和方法,并能通过所学知识运用到分析中,但本次分析也有几个不足之处:数据集不够详细,导致分析指标不多。拟合预测函数没有进行效果验证,仅通过图表看出效果良好。未来希望在对数据进行分析预测方面,能会使用不同的机器学习模型来进行,比较不同模型的优劣,选择最适合的那个模型。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号