SQL 强化练习 (五)
果然日常练练这些 sql 是非常有必要的, 这几日的报表开发, 用一款过程软件 fineReport, 相对于我之前用 Tableau 来做报表, 这个帆软, 确实更加适合中国人哦, 而Tableau只是专门用来展示而已. 我感觉 FR, 还是有一定门槛的, 首先就是 SQL, 大量的操作都是需要写 sql 来完成的, 我还蛮喜欢的其实, 很灵活的嘛. 其实是要理解 WEB, 比如做填报, 就是要先弄个页面, 然后设计数据库, 单元格值回写数据库, 数据库查询报表展示... 这个就是 WEB 呀, 反正我觉得还是有些复杂的, 但核心技能 SQL 是必须的, 虽然这里用的更多是 查询方面. 还是得不断练习...
表关系
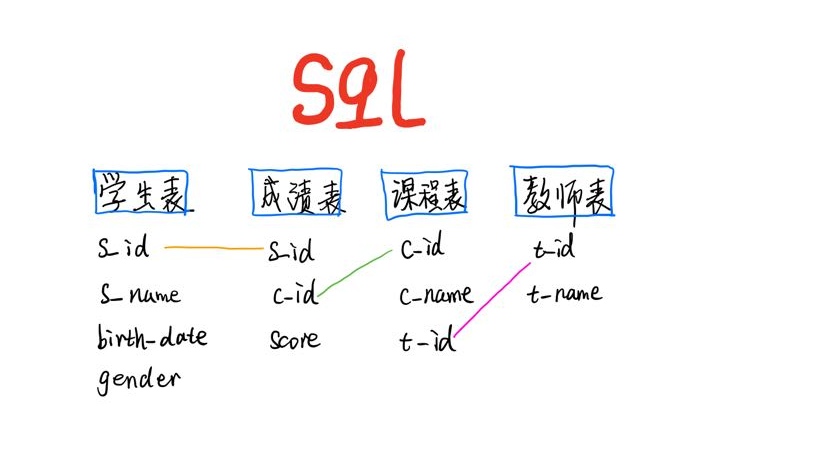
深深可在脑海中, 我感觉, 其实业务中也只不过是, 字段变多了, 表结构复杂一些而已, 本质是还是表呀.
需求 01
查询课程编号为 "0002" 的总成绩, 平均成绩, 人数等.
分析
这就是用来练习下聚合函数(sum, count, avg..)
select
sum(score) as "总成绩",
avg(score) as "平均成绩",
count(score) as "成绩总份数",
count(distinct s_id) as "学生人数"
from score
where c_id = "0002";
+-----------+--------------+-----------------+--------------+
| 总成绩 | 平均成绩 | 成绩总份数 | 学生人数 |
+-----------+--------------+-----------------+--------------+
| 230 | 76.6667 | 3 | 3 |
+-----------+--------------+-----------------+--------------+
感觉其实这个查询是没啥意义的, 就选一个一门课, 有啥号看的呢, 倒不如, 查看所有的课程的信息多好.
select
c_id as "课程编号",
sum(score) as "总成绩",
avg(score) as "平均成绩",
count(score) as "成绩总份数",
count(distinct s_id) as "学生人数"
from score
group by c_id;
+--------------+-----------+--------------+-----------------+--------------+
| 课程编号 | 总成绩 | 平均成绩 | 成绩总份数 | 学生人数 |
+--------------+-----------+--------------+-----------------+--------------+
| 0001 | 160 | 80.0000 | 2 | 2 |
| 0002 | 230 | 76.6667 | 3 | 3 |
| 0003 | 259 | 86.3333 | 3 | 3 |
+--------------+-----------+--------------+-----------------+--------------+
这样, 看全部的数据, 我感觉这更加贴和业务一点. 值得主要的是 group by 的用法, select 一般都先是这个 聚合字段的值, 然后再是一些聚合函数字段. 不要再select 放跟 分组字段 没有关系的字段. 这样经常会引发歧义和直接报错, group by -> aggregation... 这是必须要掌握的哦. 其次, 就是 group by 后面不要跟 where, 根本没有意义, where 必然是要放在 group by 之前呀, 而对于 分组后的过滤 用 having.
正好来练习一下: 用分组过滤 having 的方式来查看 "0002" 的信息
select
c_id as "课程编号",
sum(score) as "总成绩",
avg(score) as "平均成绩",
count(score) as "成绩总份数",
count(distinct s_id) as "学生人数"
from score
group by c_id having c_id = "0002";
一样的结果
+--------------+-----------+--------------+-----------------+--------------+
| 课程编号 | 总成绩 | 平均成绩 | 成绩总份数 | 学生人数 |
+--------------+-----------+--------------+-----------------+--------------+
| 0002 | 230 | 76.6667 | 3 | 3 |
+--------------+-----------+--------------+-----------------+--------------+
1 row in set (0.00 sec)
我感觉我每天都是在干这类似的 筛选字段, 分组聚合的活. 原本我以为会了 Pandas 就无所畏惧, 为所欲为, 结果, 工作中更多是要去从数据库中查询数据 用sql 的方式来查询返回, 而非用 Python 来搞, 我感觉 Python 我搞得更多的是一些线下的表格数据, 什么 Excel, csv, json... 无敌强, 但更多还是用 sql 来查询数据会更通用和专业些.
需求 02
查询 所有课程成绩小于 90 分 的学生学号, 姓名
分析
先用学号进行 group by (结合 where 成绩 < 90) 的课程数量;
然后再统计, 该学号总共选了几门课, 这样一比较就好啦.
我还是先自己肉眼给看一眼:
select
s_id as "学号",
c_id as "课程号",
score as "成绩"
from score
group by s_id, c_id;
+--------+-----------+--------+
| 学号 | 课程号 | 成绩 |
+--------+-----------+--------+
| 0001 | 0001 | 80 |
| 0001 | 0002 | 90 |
| 0001 | 0003 | 99 |
| 0002 | 0002 | 60 |
| 0002 | 0003 | 80 |
| 0003 | 0001 | 80 |
| 0003 | 0002 | 80 |
| 0003 | 0003 | 80 |
+--------+-----------+--------+
8 rows in set (0.00 sec)
这样一看, 都是满足的呀.
-- 首先呢, 先看看每个人成绩小于 90 分的 课有几门
select
s_id as "学号",
count(c_id) as "小于90的课数"
from score
where score < 90
group by s_id;
+--------+-------------------+
| 学号 | 小于90的课数 |
+--------+-------------------+
| 0001 | 1 |
| 0002 | 2 |
| 0003 | 3 |
+--------+-------------------+
3 rows in set (0.00 sec)
-- 然后呢, 再看看每个人一个选课几门课
select
s_id as "学号",
count(c_id) as "选课数"
from score
group by s_id;
+--------+-----------+
| 学号 | 选课数 |
+--------+-----------+
| 0001 | 3 |
| 0002 | 2 |
| 0003 | 3 |
+--------+-----------+
3 rows in set (0.00 sec)
再将这两个表一拼 inner join 不就美滋滋.. 即 inner 上的学号就是不满足条件的呀
select
a.*,
b.*
from
(
select
s_id as "学号",
count(c_id) as "小于90的课数"
from score
where score < 90
group by s_id) as a
inner join
(
select
s_id as "学号",
count(c_id) as "选课数"
from score
group by s_id) as b
on a.学号= b.学号;
+--------+-------------------+--------+-----------+
| 学号 | 小于90的课数 | 学号 | 选课数 |
+--------+-------------------+--------+-----------+
| 0001 | 1 | 0001 | 3 |
| 0002 | 2 | 0002 | 2 |
| 0003 | 3 | 0003 | 3 |
+--------+-------------------+--------+-----------+
3 rows in set (0.00 sec)
最后来个完整的. 我一般是从里到外的. 不断 select , 面向过程多一些.
select
s_id as "学号",
s_name as "姓名"
from student
where s_id in (
select
a.学号
from
(
select
s_id as "学号",
count(c_id) as "小于90的课数"
from score
where score < 90
group by s_id) as a
inner join
(
select
s_id as "学号",
count(c_id) as "选课数"
from score
group by s_id) as b
on a.学号= b.学号
);
+--------+-----------+
| 学号 | 姓名 |
+--------+-----------+
| 0001 | 王二 |
| 0002 | 星落 |
| 0003 | 胡小适 |
+--------+-----------+
3 rows in set (0.00 sec)
小结
- 聚合函数练习 sum, avg, count + distinct ....这些常见聚合函数的熟练使用呀.
- group by 前的 select 不要放跟 其无关的非聚合字段, 没有意义, where 要置前, 组内过滤用 having
- 复杂查询先理清楚逻辑, 一点点给查出来, 再拼接 Join 再过滤, 子查询等操作, 跟写代码一样的其实

 浙公网安备 33010602011771号
浙公网安备 33010602011771号