
第一次编程作业
这个作业属于哪个课程 https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience
这个作业的要求在哪里 https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience/homework/13477
这个作业的目标 实现一个3000字以上论文查重程序
Github链接:https://github.com/CJ-fighting/3123004476
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 320 | 300 |
| · Estimate | · 估计这个任务需要多少时间 | 20 | 20 |
| Development | 开发 | 60 | 50 |
| · Analysis | · 需求分析 (包括学习新技术) | 30 | 30 |
| · Design Spec | · 生成设计文档 | 30 | 20 |
| · Design Review | · 设计复审 | 30 | 30 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| · Design | · 具体设计 | 30 | 30 |
| · Coding | · 具体编码 | 30 | 30 |
| · Code Review | · 代码复审 | 30 | 30 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 30 | 30 |
| Reporting | 报告 | 120 | 90 |
| · Test Repor | · 测试报告 | 40 | 30 |
| · Size Measurement | · 计算工作量 | 40 | 30 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 40 | 30 |
| · 合计 | 440 | 390 |
接口的设计和实现过程
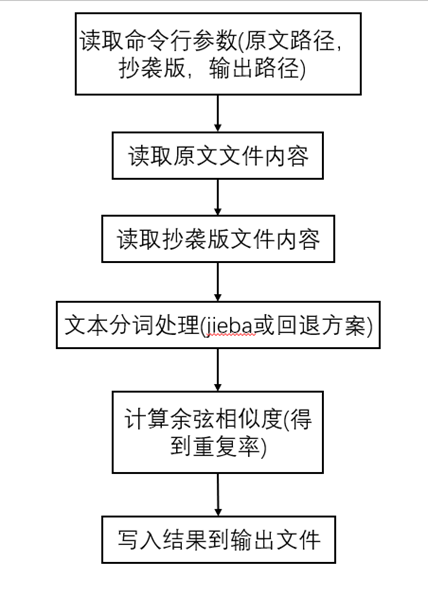
程序主要分为三个类:FileHandler文件读写类,Tokenizer文本处理类,SimilarityCalculator相似度计算类。
算法主要运用了余弦相似度
分词方法:jieba.cut(text)把中文句子拆成词,解决“中文没有空格”的问题。
词频统计:collections.Counter高效统计词出现的次数。
向量化表示:把文本转化为“词频向量”,方便计算相似度。
余弦相似度:一种常见的文本相似度算法,适合高维稀疏向量。广泛用于信息检索、推荐系统、文档查重。
计算模块单元测试展示
测试代码如下def run_tests():
print("==== 测试开始 ====")
# 1. 完全相同的文本
t1 = "今天是星期天,天气晴"
t2 = "今天是星期天,天气晴"
sim = cosine_similarity(t1, t2)
print("测试1:完全相同")
print(f"相似度 = {sim:.4f}") # 预期接近 1.0
# 2. 完全不同的文本
t1 = "今天是星期天,天气晴"
t2 = "我喜欢吃苹果"
sim = cosine_similarity(t1, t2)
print("\n测试2:完全不同")
print(f"相似度 = {sim:.4f}") # 预期接近 0.0
# 3. 部分相似(有共同词)
t1 = "今天是星期天,天气晴"
t2 = "今天周天,天气很好"
sim = cosine_similarity(t1, t2)
print("\n测试3:部分相似")
print(f"相似度 = {sim:.4f}") # 预期在 0.3~0.7 之间
# 4. 空文本
t1 = ""
t2 = "今天是星期天"
sim = cosine_similarity(t1, t2)
print("\n测试4:空文本")
print(f"相似度 = {sim:.4f}") # 预期 = 0.0
print("==== 测试结束 ====")
调用测试函数
if name == "main":
run_tests()
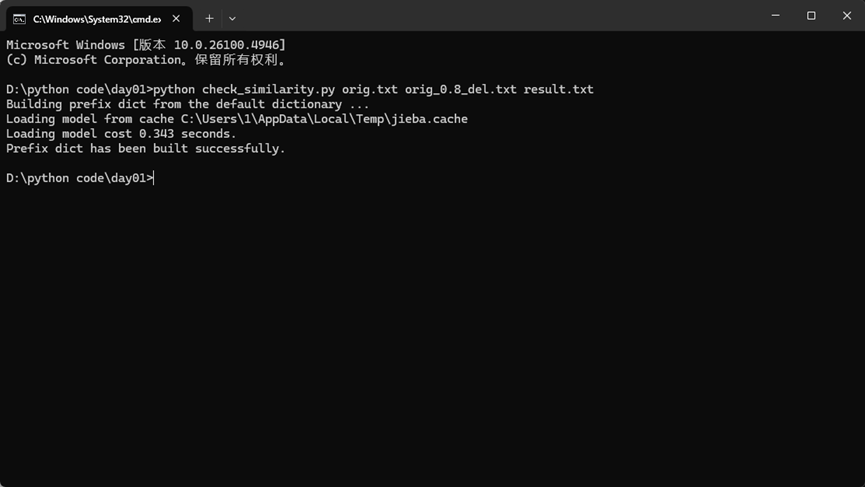
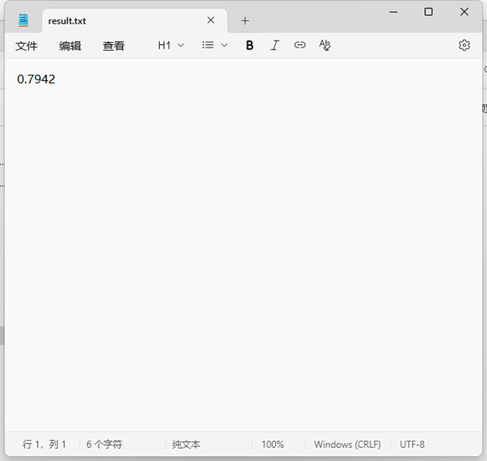
测试给定数据集文件
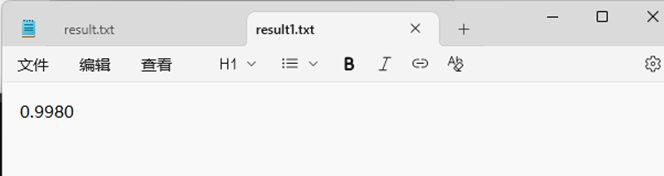
Orig_0.8_del的文本查重数据
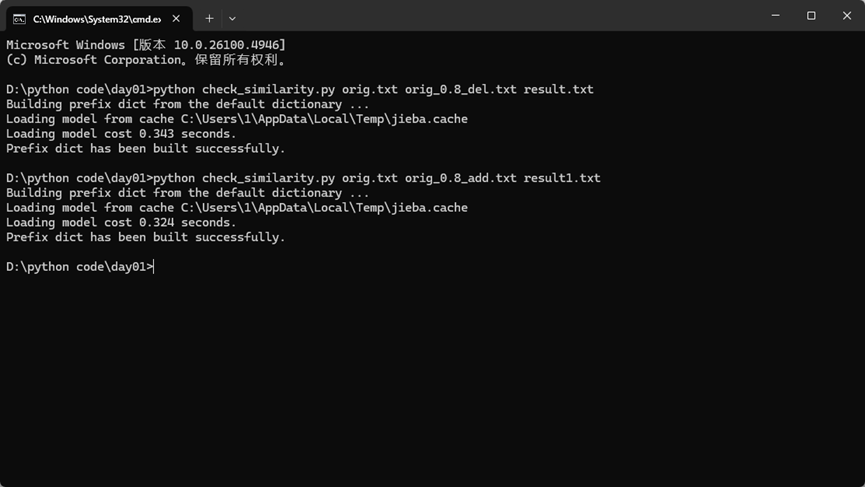
Orig_0.8_add的查重数据
有可能出现的异常情况
文本为空
位置:cosine_similarity()
if norm1 == 0 or norm2 == 0:
return 0.0
异常类型:除零错误 (ZeroDivisionError)
触发条件:如果某个文本完全为空,向量长度为 0。
避免方法:代码里显式判断 norm1 == 0 or norm2 == 0,返回 0.0,成功避免了除零异常。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号