

计算机中多字节存储顺序,小端、大端、网络字节序
1. 2在计算机中的存储为10
2. (x<<1) 等价于乘2
如果要有左右顺序来看计算机内存的排列的话,那么排序顺序如下:

也就是内存从右到左升序。
例子: 观察int在计算机是如何存储的
int a = 197121;//0-3-2-1 int* p = &a; char* cp = (char*)p; std::cout << "adrs:" << (int)cp << ", " << (int)*cp << std::endl; std::cout << "adrs:" << int(cp + 1) << ", " << (int)*(cp + 1) << std::endl; std::cout << "adrs:" << int(cp + 2) << ", " << (int)*(cp + 2) << std::endl; std::cout << "adrs:" << int(cp + 3) << ", " << (int)*(cp + 3) << std::endl;
结果:
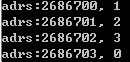
可以发现,int类型中数据的低位与内存的低位相对应(小端模式)。
配合平时一直用的左移、右移操作即可发现存储顺序。
197121在内存中的表示为:


这篇文字很有灵性:https://zhuanlan.zhihu.com/p/21388517
大小端问题主要涉及的是非单字节非字符串外的其余数据的表示和传递。
小端:数字的低位 对应于 地址低位
大端:数字的高位 对应于 地址低位
网络字节序
前面的大端和小端都是在说计算机自己,也被称作主机字节序。其实,只要自己能够自圆其说是没啥问题的。问题是,网络的出现使得计算机可以通信了。通信,就意味着相处,相处必须得有共同语言啊,得说普通话,要不然就容易会错意,下了一个小时的小电影发现打不开,理解错误了!
但是每个计算机都有自己的主机字节序啊,还都不依不饶,坚持做自己,怎么办?
TCP/IP协议隆重出场,RFC1700规定使用“大端”字节序为网络字节序,其他不使用大端的计算机要注意了,发送数据的时候必须要将自己的主机字节序转换为网络字节序(即“大端”字节序),接收到的数据再转换为自己的主机字节序。这样就与CPU、操作系统无关了,实现了网络通信的标准化。突然觉得,TCP/IP协议好任性啊有木有!
为了程序的兼容,你会看到,程序员们每次发送和接受数据都要进行转换,这样做的目的是保证代码在任何计算机上执行时都能达到预期的效果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号