数据采集与融合实验二
码云链接
https://gitee.com/chenhhhs/homework_project/tree/master/homework2
作业①
(1)、在中国气象网( http://www.weather.com.cn )给定城市集的 7日天气预报,并保存在数据库。
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import sqlite3
class WeatherDB:
def openDB(self):
self.con=sqlite3.connect("weathers.db")
self.cursor=self.con.cursor()
try:
self.cursor.execute("create table weathers (wCity varchar(16),wDate varchar(16),wWeather varchar(64),wTemp varchar(32),constraint pk_weather primary key (wCity,wDate))")
except:
self.cursor.execute("delete from weathers")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, city, date, weather, temp):
try:
self.cursor.execute("insert into weathers (wCity,wDate,wWeather,wTemp) values (?,?,?,?)",
(city, date, weather, temp))
except Exception as err:
print(err)
def show(self):
self.cursor.execute("select * from weathers")
rows = self.cursor.fetchall()
print("%-16s%-16s%-32s%-16s" % ("city", "date", "weather", "temp"))
for row in rows:
print("%-16s%-16s%-32s%-16s" % (row[0], row[1], row[2], row[3]))
class WeatherForecast:
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
self.cityCode = {"北京": "101010100", "上海": "101020100", "广州": "101280101", "深圳": "101280601"}
def forecastCity(self, city):
if city not in self.cityCode.keys():
print(city + " code cannot be found")
return
url = "http://www.weather.com.cn/weather/" + self.cityCode[city] + ".shtml"
try:
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
lis = soup.select("ul[class='t clearfix'] li")
# for li in lis:
# print(li)
for li in lis:
try:
date = li.select('h1')[0].text
weather = li.select('p[class="wea"]')[0].text
temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text
print(city, date, weather, temp)
self.db.insert(city, date, weather, temp)
except Exception as err:
print(err)
except Exception as err:
print(err)
def process(self, cities):
self.db = WeatherDB()
self.db.openDB()
for city in cities:
self.forecastCity(city)
# self.db.show()
self.db.closeDB()
ws = WeatherForecast()
ws.process(["北京", "上海", "广州", "深圳"])
print("completed")
通过navicat可视化数据库查看数据
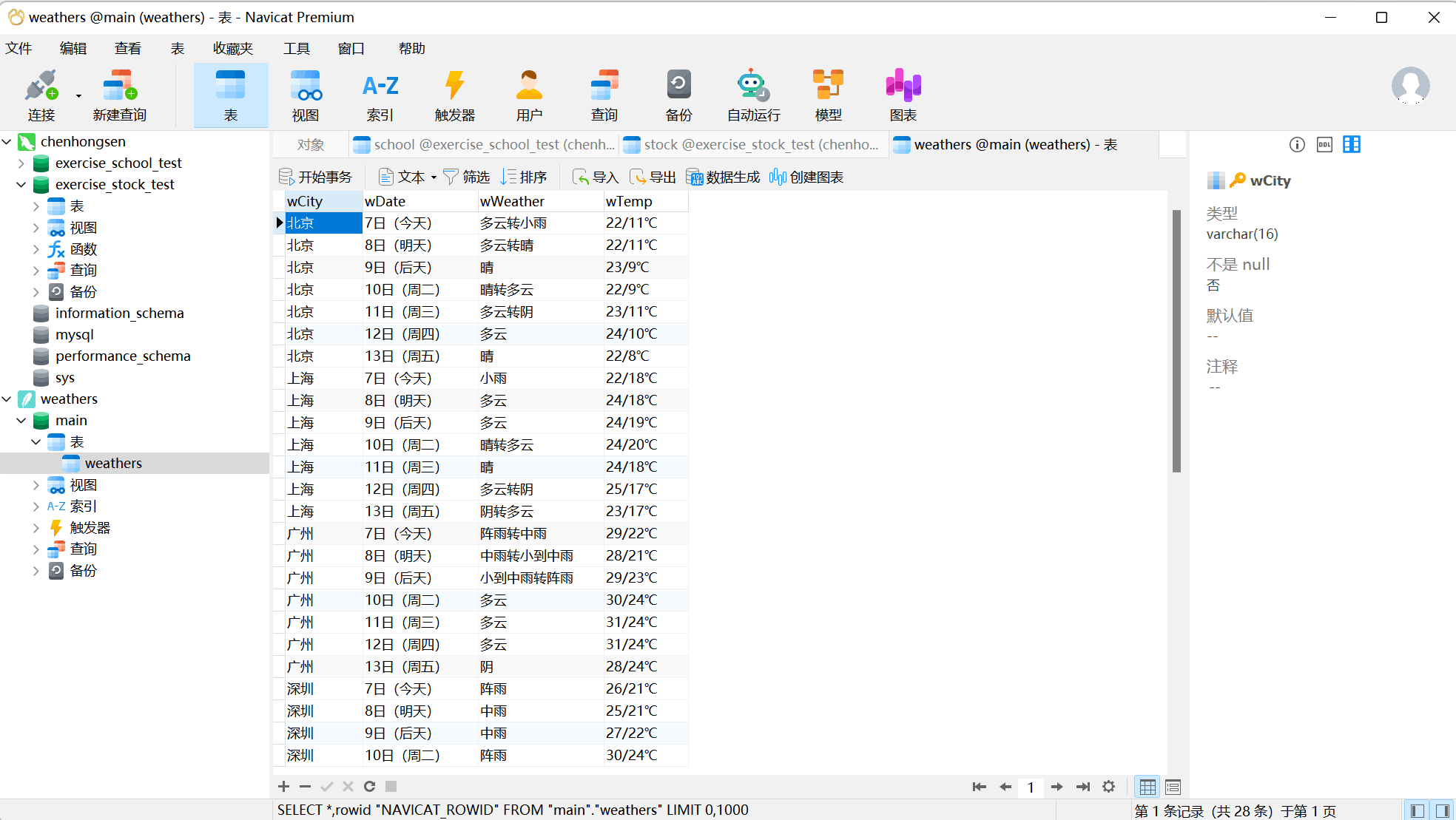
(2)、心得体会
第一题为复现,通过本题学会了如何手动生成数据库,初始化数据库,插入数据。
作业②
(1)、用 requests 和 BeautifulSoup 库方法定向爬取股票相关信息,并存储在数据库中。
import json
import requests
import pandas as pd
import sqlite3
from sqlalchemy import create_engine
import mysql.connector
def gethtml(fs,page): #fs为地区股票,page为爬取的页码
url = "http://44.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112406854618710877052_1696660618066&pn=" + str(page) + "&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=" + fs + "&fields=f2,f3,f4,f5,f6,f7,f12,f14&_=1696660618067"
resquest = requests.get(url)
# print(resquest.text)
start = resquest.text.find('(')
end = resquest.text.rfind(')')
data = resquest.text[start+1:end] #切片寻找所需要的数据
# print(data)
data = json.loads(data) #将数据转变为json格式
data = data['data']['diff'] #返回需要的数据 data为二维数组
# print(type(data))
return data
'''
沪深京A股:fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048
北证A股: fs=m:0+t:81+s:2048
上证A股票: fs=m:1+t:2,m:1+t:23&
'''
def getdata(fs,page):
name = ['f12','f14','f2','f3','f4','f5','f6','f7']
#f12:股票代码 f14:股票名称 f2:最新报价 f3:涨跌幅 f4:涨跌幅 f5:成交量 f6:成交额 f7:涨幅
global count
list_data = []
data = gethtml(fs,page) #data为fs地区股票第page页的二维数组
for i in range(len(data)):
list = []
list.append(count)
for j in name:
list.append(data[i][j]) #依次取出数据放入list_data中
count = count + 1
list_data.append(list)
return list_data
# print(gethtml(1))
# print(getdata(1))
count = 1 #记录爬取的股票序号
shares = [] #存放爬取下来的股票数据
fs = {
"沪深京A股":"m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048",
"北证A股":"m:0+t:81+s:2048",
"上证A股票":"m:1+t:2,m:1+t:23"
} #不同地区股票对应的编码
n = int(input("请输入想要爬取的页面:"))
for page in range(1,n+1):
for value in fs.values():
share = getdata(value,page)
name = list(fs.keys())[list(fs.values()).index(value)] #name获取地区股票名字
print(f"正在爬取{name}中第{page}页")
# print(k)
for s in share:
shares.append(s)
# print(data,len(data))
df = pd.DataFrame(data=shares,columns=['序号','代码','名称','最新价','涨跌幅','跌涨额','成交量','成交额','涨幅'])
print(df)
df.to_excel('test2_股票.xlsx')
engine = create_engine("mysql+mysqlconnector://root:123456@127.0.0.1:3306/exercise_stock_test") #传入数据库
df.to_sql('stock',engine,if_exists="replace")
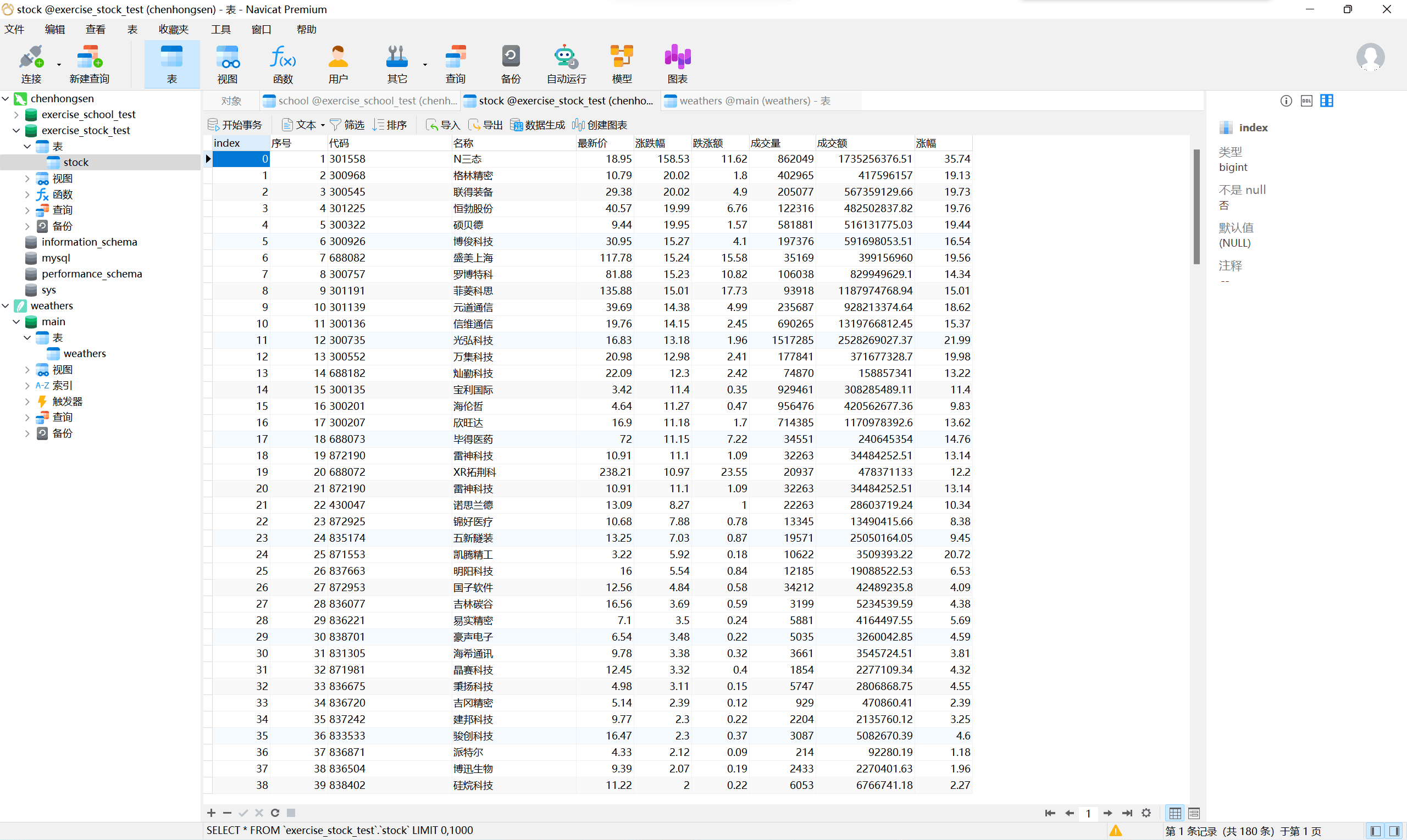
从沪深京A股、北证A股、上证A股中各爬取三页数据
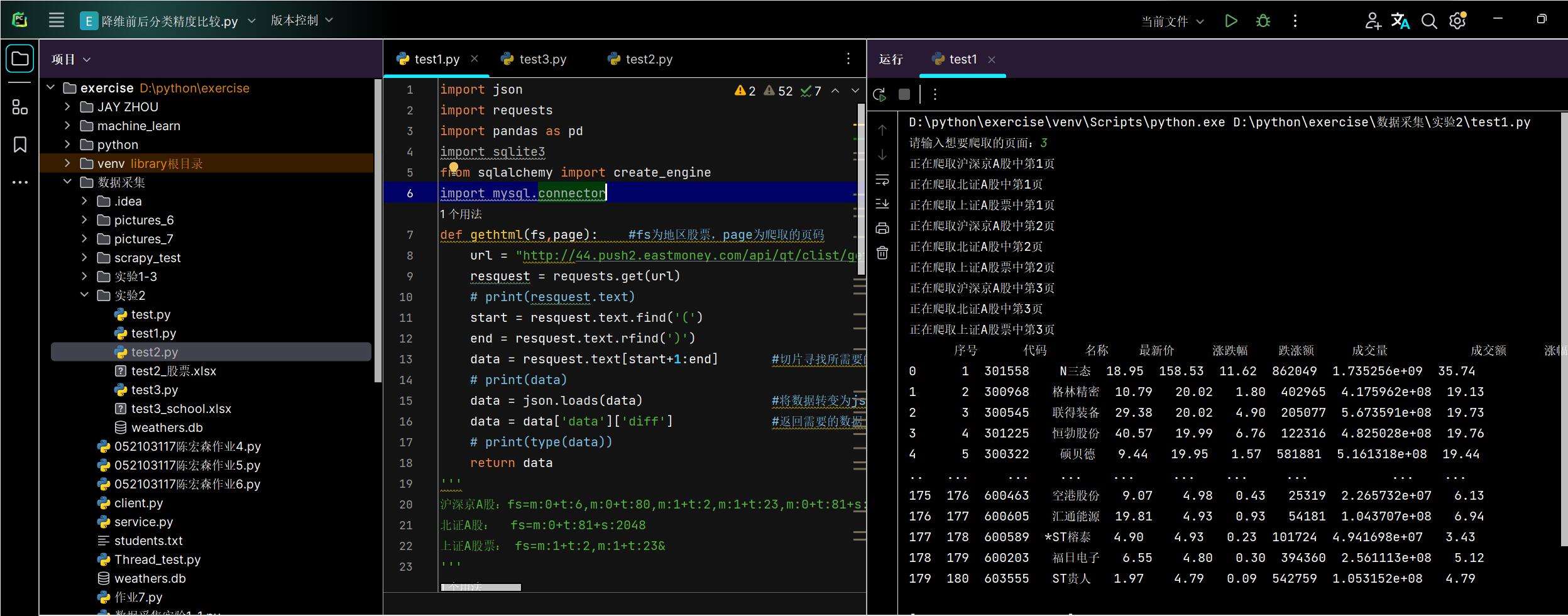
通过navicat可视化数据库查看数据
(2)、心得体会
为了实现爬取在不同地区的股票以及不同页面的股票信息,对比了一系列url,发现通过修改pn可以实现翻页,通过修改fs可以实现爬取不同地区的股票。缺点是没有发现地区股票的规律,因此在本题中只爬取了三个地区的股票信息。
通过本次实践,学会了如何将字典转为了json格式,以及如何直接生成数据库。
作业③
(1)、爬取中国大学 2021 主榜( https://www.shanghairanking.cn/rankings/bcur/2021 )所有院校信息,并存储在数据库中,同时将浏览器 F12 调试分析的过程录制 Gif 加入至博客中。
F12抓包过程:

代码如下:
import requests
import pandas as pd
import re
from sqlalchemy import create_engine
import mysql.connector
url = "https://www.shanghairanking.cn/_nuxt/static/1695811954/rankings/bcur/2021/payload.js"
resquest = requests.get(url=url)
# print(resquest.text)
name = re.findall(',univNameCn:"(.*?)",',resquest.text) #获取学校名称
score = re.findall(',score:(.*?),',resquest.text) #获取学校总分
category = re.findall(',univCategory:(.*?),',resquest.text) #获取学校类型
province = re.findall(',province:(.*?),',resquest.text) #获取学校所在省份
# print(name,type(name))
# print(score,type(score))
# print(category)
# print(province)
code_name = re.findall('function(.*?){',resquest.text)
start_code = code_name[0].find('a')
end_code = code_name[0].find('pE')
code_name = code_name[0][start_code:end_code].split(',') #将function中的参数取出并存在code_name列表中
# print(code_name,len(code_name),type(code_name))
value_name = re.findall('mutations:(.*?);',resquest.text)
start_value = value_name[0].find('(')
end_value = value_name[0].find(')')
value_name = value_name[0][start_value+1:end_value].split(",") #将参数所对应的含义取出存在value_name列表中
# print(value_name)
df = pd.DataFrame(columns=["排名","学校","省份","类型","总分"])
for i in range(len(name)):
province_name = value_name[code_name.index(province[i])][1:-1]
# print(province_footnode)
category_name = value_name[code_name.index(category[i])][1:-1]
df.loc[i] = [i+1,name[i],province_name,category_name,score[i]]
print(df)
df.to_excel("test3_school.xlsx")
engine = create_engine("mysql+mysqlconnector://root:123456@127.0.0.1:3306/exercise_school_test") #传入数据库
df.to_sql('school',engine,if_exists="replace")
通过navicat可视化数据库查看如下:
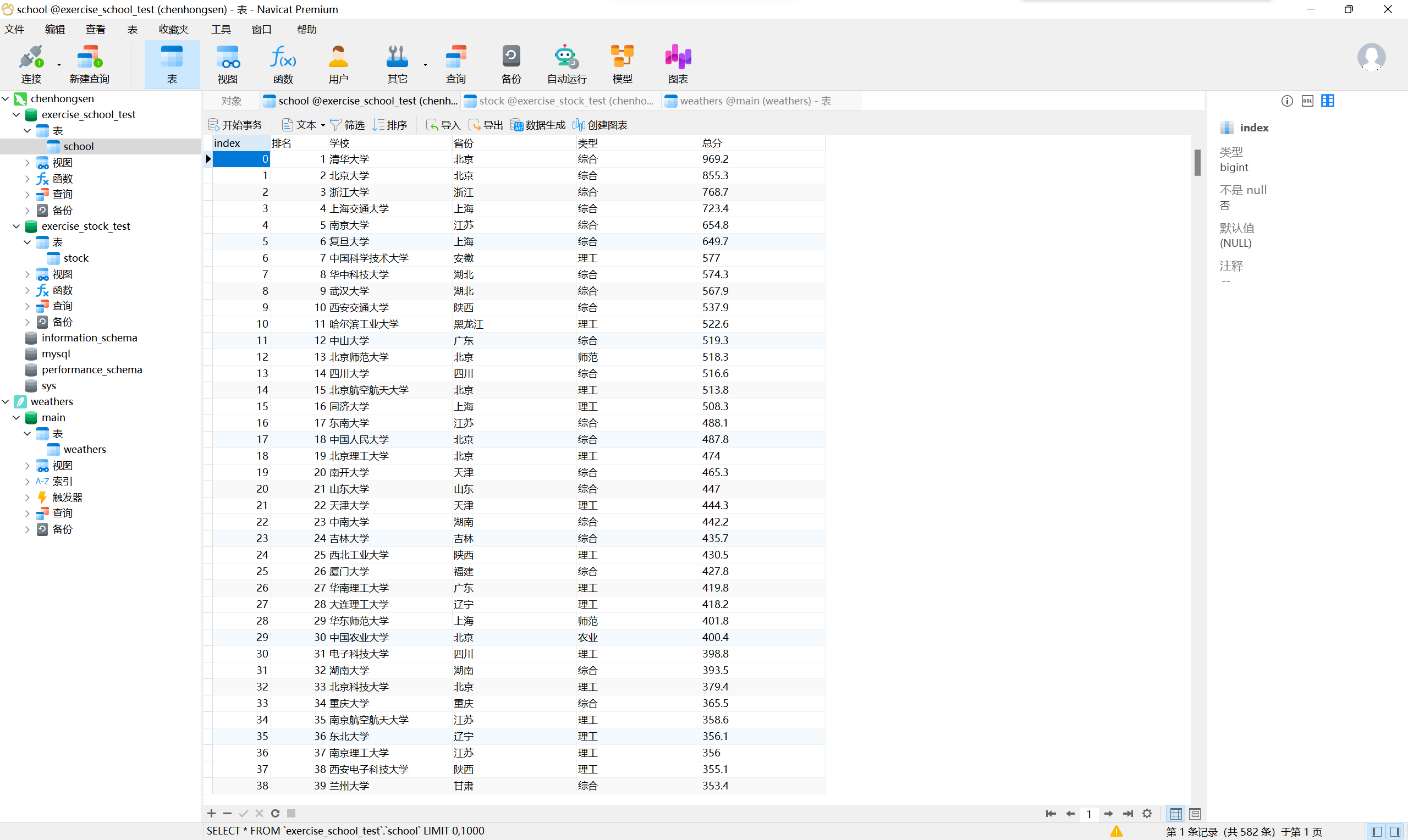
(2)、心得体会
在此题中抓包后通过re对所需要的数据进行提取,对re有进一步的了解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号