JavaScript高级篇
JavaScript高级篇
一、javaScript基础总结
数据类型分类
基本(值)类型
- Number:任意数值
- String:任意文本
- Boolean:true / false
- undefined:undefined
- null:null
对象(引用)类型
- Object:任意对象([]、函数...)
- Array:特别的对象类型(数值下标 / 内部数据有序)
- Function:特别的对象类型(可执行)
注:除了基本数据类型,其余类型都是对象类型
数据类型 判断
typeof
- 返回数据类型的字符串表达;
- 可以区别:数值、字符串、布尔值、undefined、function;
- 不能区别:null与object、一般object与array。
instanceof
- 专门用来判断对象数据的类型:Object、Array与Function。
===
- 可以判断:undefined和null。
<script type="text/javascript">
// typeof: 返回的是数据类型的字符串表达形式
//1. 基本类型
var a
console.log(a, typeof a, a === undefined) // undefined 'undefined' true
console.log(a === typeof a) // false, (typeof a) 返回的是字符串类型的'undefined'
a = 3
console.log(typeof a === 'number') //true
a = 'atguigu'
console.log(typeof a === 'string') //true
a = true
console.log(typeof a === 'boolean') //true
a = null
console.log(a === null) // true
console.log(typeof a) // 'object'
var b = undefined;
console.log(b === undefined); //true
console.log(typeof b); //undefined
console.log('--------------------------------')
// //2. 对象类型
var b1 = {
b2: [2, 'abc', console.log],
b3: function () {
console.log('b3()')
}
}
console.log(b1 instanceof Object, typeof b1) // true 'object'
console.log(b1.b2 instanceof Array, typeof b1.b2) // true 'object'
console.log(b1.b3 instanceof Function, typeof b1.b3) // true 'function'
console.log(typeof b1.b2[2]) // 'function'
console.log(b1.b2[2]('abc')) // 'abc' undefined
</script>

实例
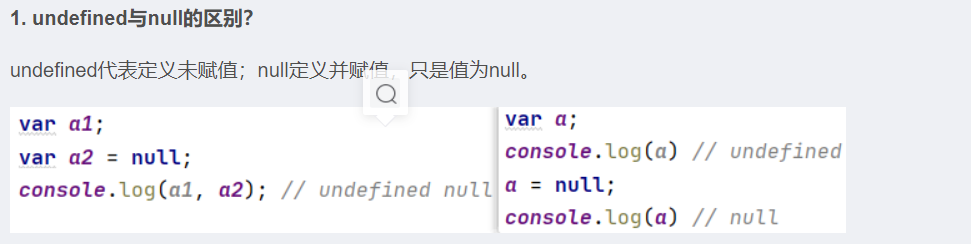
1. undefined与null的区别?
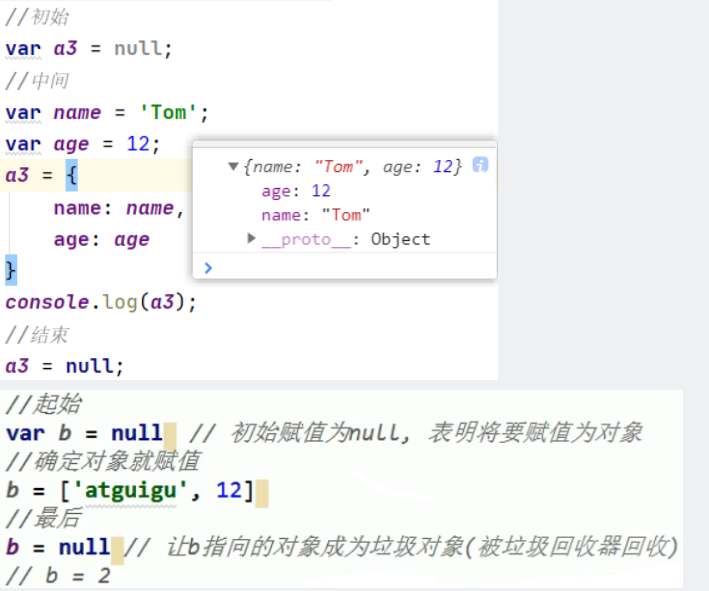
2. 什么时候给变量赋值为null呢?
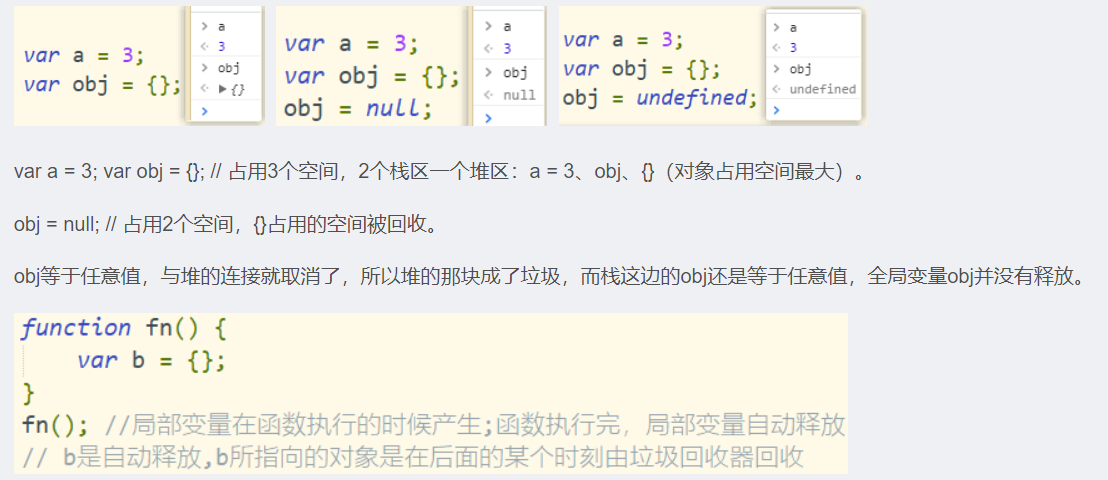
初始赋值,表明将要赋值为对象;结束前,让对象成为垃圾对象(被垃圾回收器回收)。初始化赋值:将要作为引用变量使用, 但对象还没有确定。结束时:将变量指向的对象成为垃圾对象。
var a = null // a将指向一个对象,但对象此时还没有确定
....
a = null // 让a指向的对象成为垃圾对象
3. 严格区别变量类型与数据类型?
js的变量本身是没有类型的,变量的类型实际上是变量内存中数据的类型(js是弱类型的语言)。var a; 判断变量类型,实际上 是判断值的类型。
数据的类型(数据对象):
- 基本类型
- 对象类型
变量的类型(变量内存值的类型):
- 基本类型:保存基本类型的数据(保存基本类型数据的变量)。
- 引用类型:保存对象地址值(保存对象地址值的变量)。
练习
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>01_相关问题</title>
</head>
<body>
<!--
1. undefined与null的区别?
* undefined代表定义未赋值
* nulll定义并赋值了, 只是值为null
2. 什么时候给变量赋值为null呢?
* 初始赋值, 表明将要赋值为对象
* 结束前, 让对象成为垃圾对象(被垃圾回收器回收)
3. 严格区别变量类型与数据类型?
* 数据的类型
* 基本类型
* 对象类型
* 变量的类型(变量内存值的类型)
* 基本类型: 保存就是基本类型的数据
* 引用类型: 保存的是地址值
-->
<script type="text/javascript">
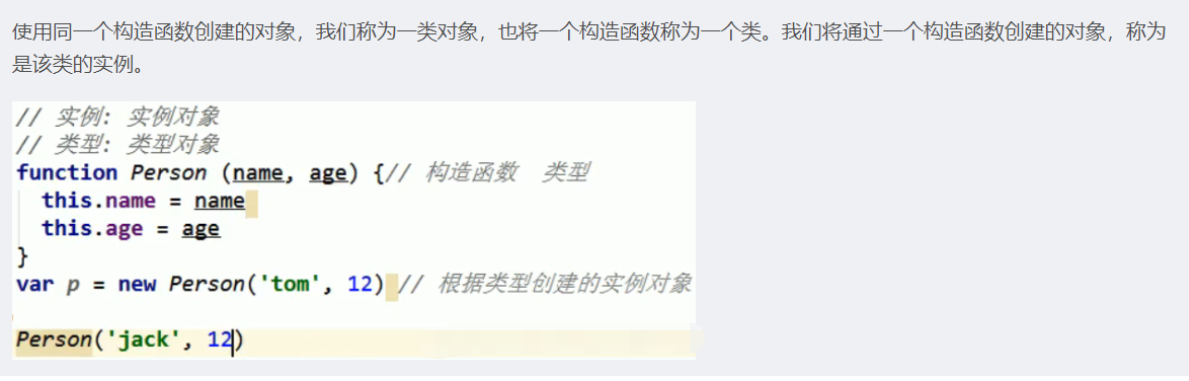
// 实例: 实例对象
// 类型: 类型对象
function Person(name, age) {// 构造函数 类型
this.name = name
this.age = age
}
var p = new Person('tom', 12) // 根据类型创建的实例对象
// Person('jack', 12)
// 1. undefined与null的区别?
var a
console.log(a) // undefined
a = null
console.log(a) // null
//起始
var b = null // 初始赋值为null, 表明将要赋值为对象
//确定对象就赋值
b = ['atguigu', 12]
//最后
b = null // 让b指向的对象成为垃圾对象(被垃圾回收器回收)
// b = 2
var c = function () {
}
console.log(typeof c) // 'function'
</script>
</body>
</html>
数据、变量、内存管理
概述
1. 什么是数据?
* 存储于内存中代表特定信息的'东东', 本质就是0101二进制
* 具有可读和可传递的基本特性
* 万物(一切)皆数据, 函数也是数据
* 程序中所有操作的目标: 数据
* 算术运算
* 逻辑运算
* 赋值
* 调用函数传参
...
2. 什么是内存?
* 内存条通电后产生的存储空间(临时的)
* 产生和死亡: 内存条(集成电路板)==>通电==>产生一定容量的存储空间==>存储各种数据==>断电==>内存全部消失
* 内存的空间是临时的, 而硬盘的空间是持久的
* 一块内存包含2个数据
* 内部存储的数据(一般数据/地址数据)
* 内存地址值数据
* 内存分类
* 栈: 全局变量, 局部变量 (空间较小)
* 堆: 对象 (空间较大)
3. 什么是变量?
* 值可以变化的量, 由变量名与变量值组成
* 一个变量对应一块小内存, 变量名用来查找到内存, 变量值就是内存中保存的内容
4. 内存,数据, 变量三者之间的关系
* 内存是一个容器, 用来存储程序运行需要操作的数据
* 变量是内存的标识, 我们通过变量找到对应的内存, 进而操作(读/写)内存中的数据

问题1:变量在内存中保存的值
var a = xxx(赋值操作),a内存中到底保存的是什么?
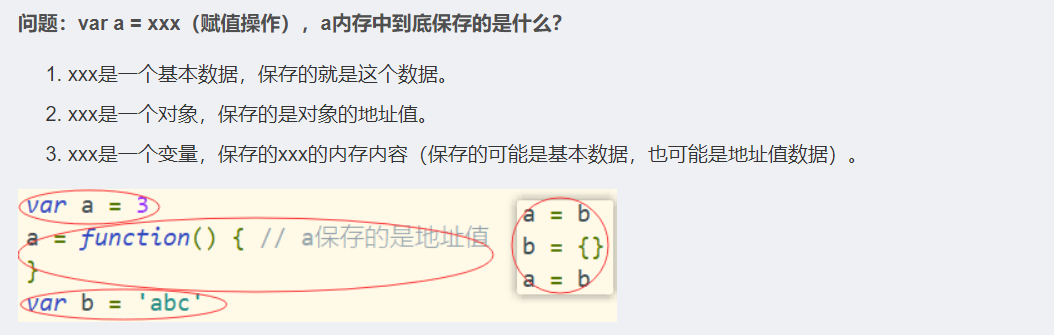
问题2:关于引用变量赋值
关于引用变量赋值问题
- 2个引用变量指向同一个对象(保存的内容是同一个对象的地址值),通过一个引用变量修改对象内部数据,另一个引用变量也看得见(看见的是修改之后的数据)。
- 2个引用变量指向同一个对象,让一个引用变量指向另一个对象,另一个引用变量还是指向原来的对象。

<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>02_关于引用变量赋值问题</title>
</head>
<body>
<script type="text/javascript">
//1. 2个引用变量指向同一个对象, 通过一个引用变量修改对象内部数据, 另一个引用变量也看得见
var obj1 = {}
var obj2 = obj1
obj2.name = 'Tom'
console.log(obj1.name) // Tom
function f1(obj) {
obj.age = 12
}
f1(obj2)
console.log(obj1.age) // 12
//2. 2个引用变量指向同一个对象,让一个引用变量指向另一个对象, 另一个引用变量还是指向原来的对象
var obj3 = {
name: 'Tom'
}
var obj4 = obj3
obj3 = {
name: 'JACK'
}
console.log(obj4.name) // Tom
function f2(obj) {
obj = {
name: 'Bob'
}
}
f2(obj4)
console.log(obj4.name) // Tom
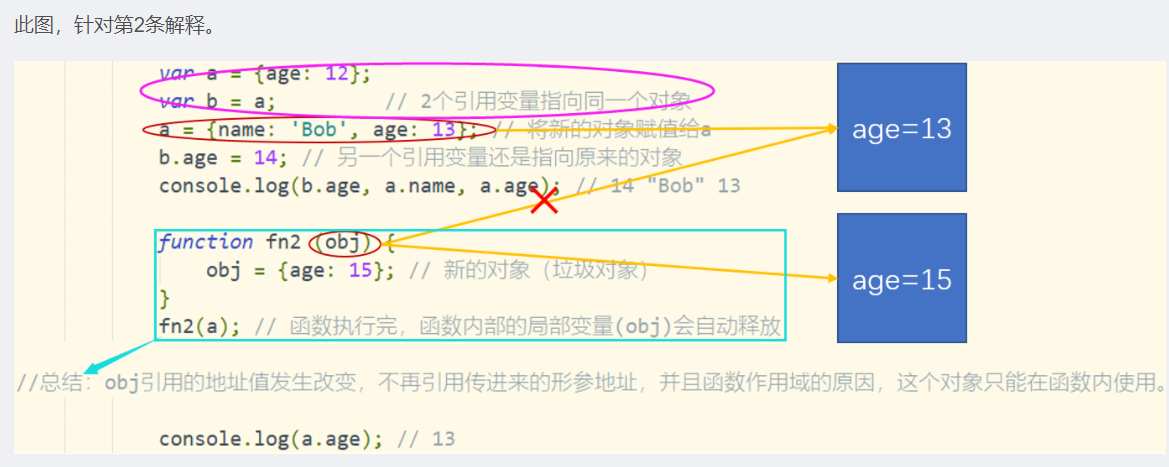
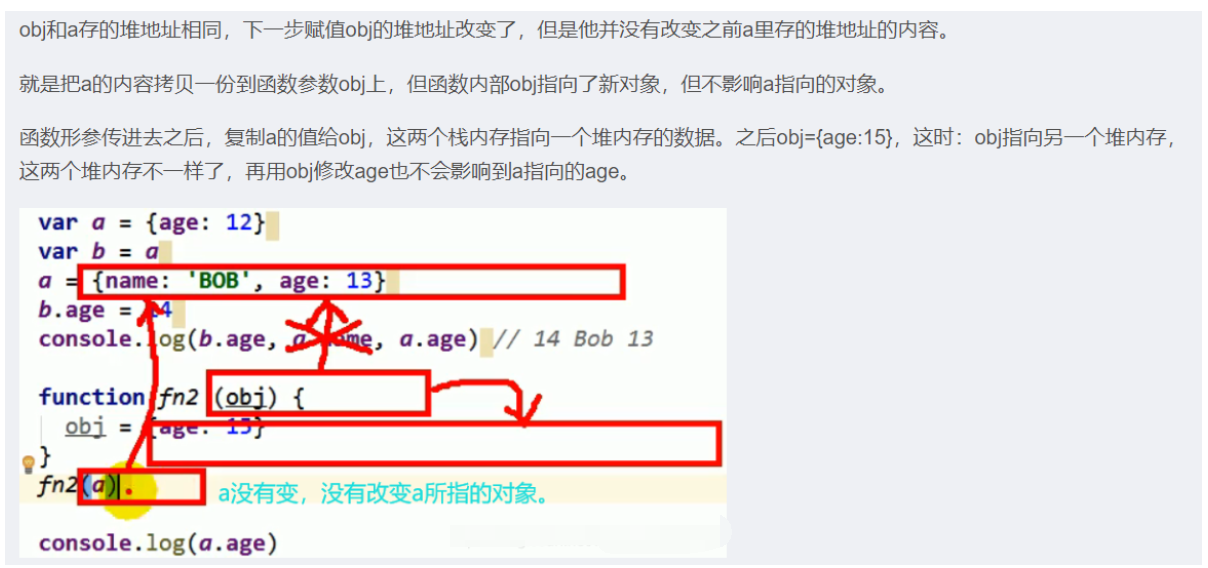
var a = {age: 12}; // 2个引用变量指向同一个对象
var b = a; // 2个引用变量指向同一个对象
a = {name: 'Bob', age: 13}; // 将新的对象赋值给a
b.age = 14; // 另一个引用变量还是指向原来的对象
console.log(b.age, a.name, a.age); // 14 "Bob" 13
function fn2 (obj) {
obj = {age: 15}; // 新的对象(垃圾对象)
}
fn2(a); // 函数执行完,函数内部的局部变量(obj)会自动释放
//总结:obj引用的地址值发生改变,不再引用传进来的形参地址,并且函数作用域的原因,这个对象只能在函数内使用。
console.log(a.age); // 13
</script>
</body>
</html>
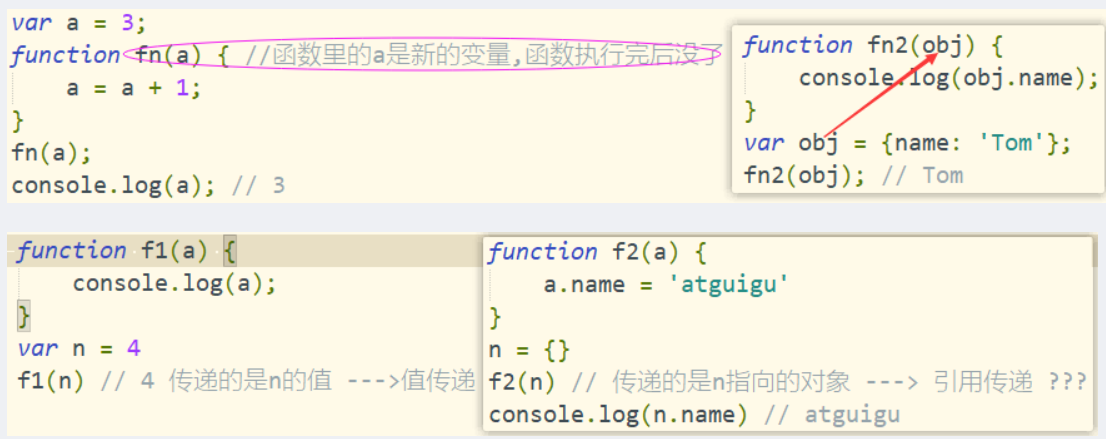
问题3:数据传递问题
在js调用函数时传递变量参数时,是值传递还是引用传递?
理解1:都是值(基本/地址值)传递。
理解2:可能是值传递,也可能是引用传递(地址值)。
只有值传递,没有引用传递,传递的都是变量的值,只是这个值可能是基本数据,也可能是地址(引用)数据。
如果后一种看成是引用传递,那就值传递和引用传递都可以有。
因为函数里的a是函数内的局部变量,换成this.a = a + 1,这时候this.a就是你最开始定义的a。
假设形参是x,调用函数传参时,发生了两件事:1、读取全局变量a的值;2、将值赋值给x ,然后执行函数内代码。
括号里的a是全局里的a的值copy给他的。
问题4:JS引擎如何管理内存?
1. 内存生命周期
分配小内存空间,得到它的使用权(分配需要的内存)。
存储数据,可以反复进行操作(使用分配到的内存)。
释放小内存空间(不需要时将其释放/归还)。
2. 释放内存
局部变量:函数执行完 自动释放(为执行函数分配的栈空间内存)。
对象:成为垃圾对象==>垃圾回收器回收(存储对象的堆空间内存:当内存没有引用指向时,对象成为垃圾对象,垃圾回收器后面就会回收释放此内存。)
问题5:什么是对象
-
多个数据的封装体(集合体)。
-
用于保存多个数据的容器。
-
一个对象代表现实中的一个事物(代表现实中的某个事物,是该事物在编程中的抽象)。
问题6:为什么要用对象?
- 便于对多个数据进行统一管理。
问题7:对象的组成
对象中的函数叫方法;对象中的字符串、数字等等叫属性。
- 属性:属性名(字符串)和属性值(任意)组成。(代表现实事物的状态数据;属性名都是字符串类型,属性值是任意类型)
- 方法:一种特别的属性(属性值是函数)。(代表现实事物的行为数据)
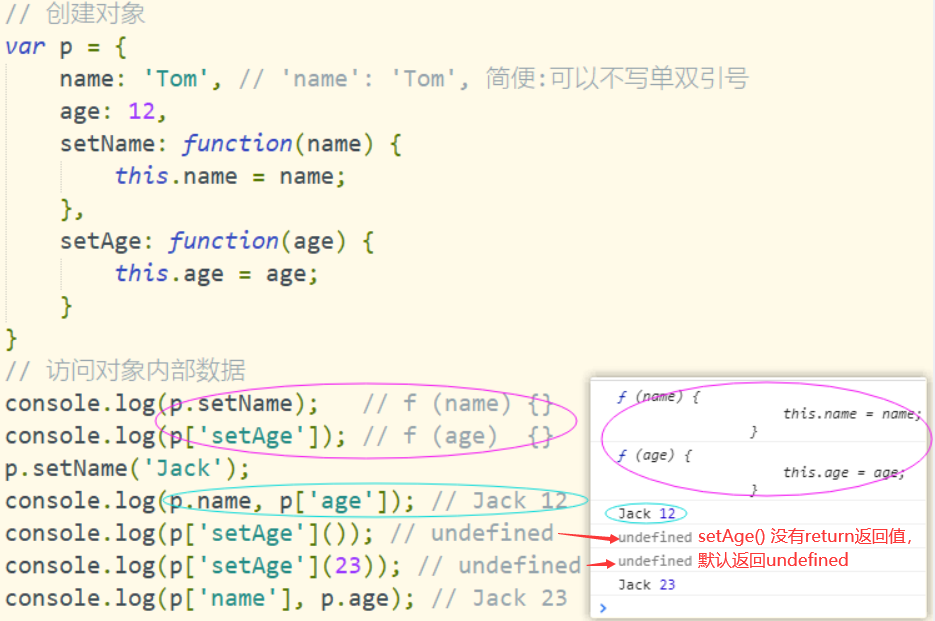
问题8:如何访问对象内部数据?
-
对象.属性名: 编码简单, 有时不能用
-
对象['属性名']: 编码麻烦, 能通用
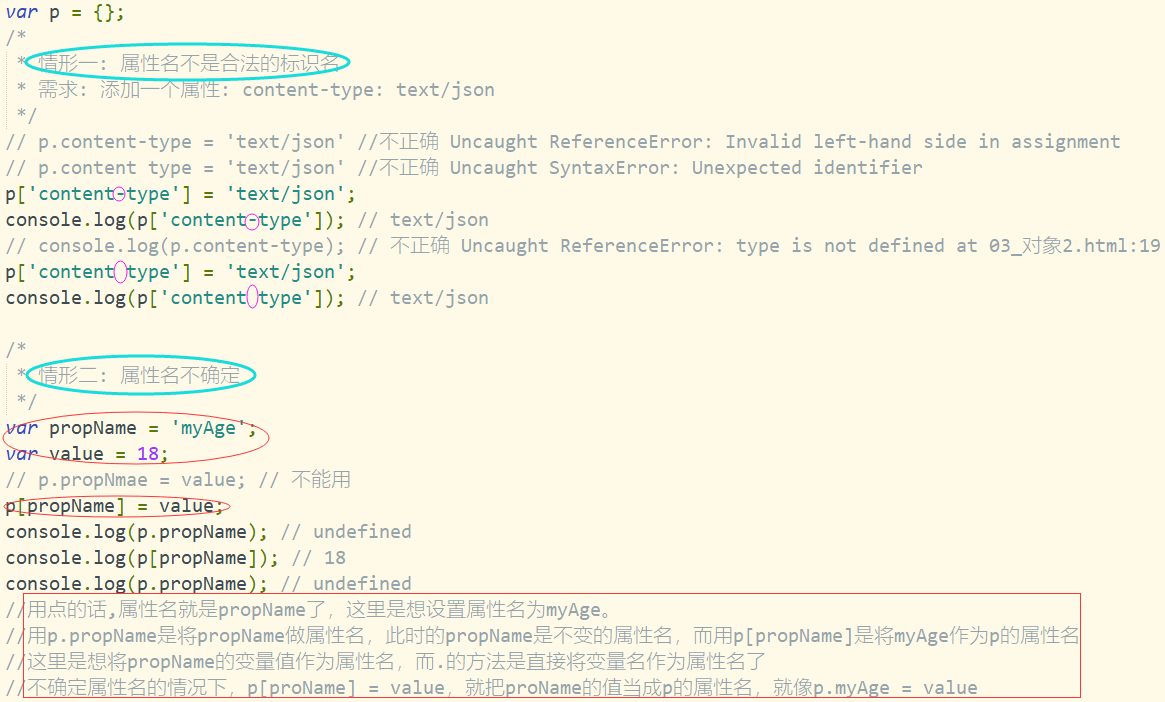
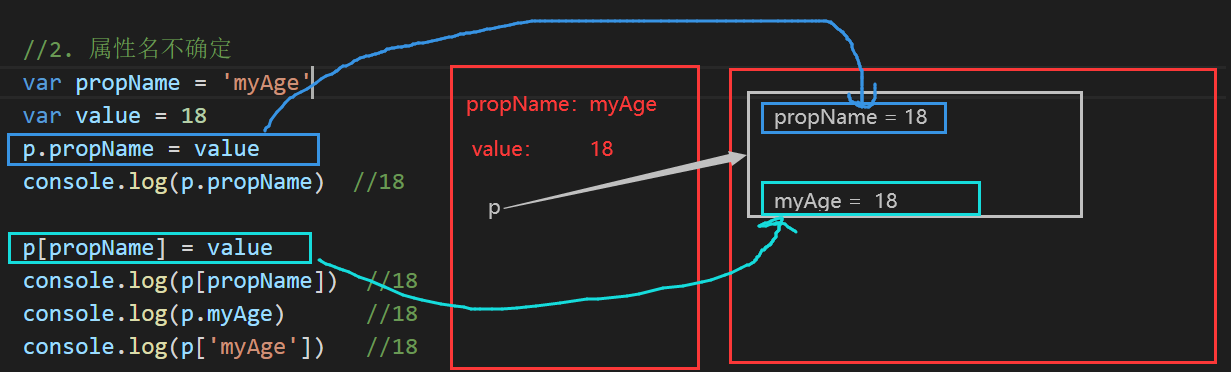
问题9:什么时候必须使用['属性名']的方式?
-
属性名包含特殊字符: - 空格
-
属性名不确定
函数
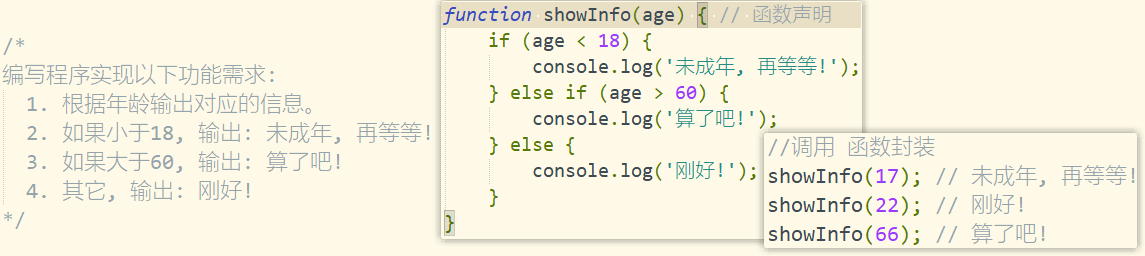
1.什么是函数?
- 实现特定功能的n条语句的封装体;
- 只有函数是可执行的,其它类型的数据是不能执行(不用管);
- 函数也是对象。

2. 为什么要用函数?
-
提高代码复用
-
便于阅读交流
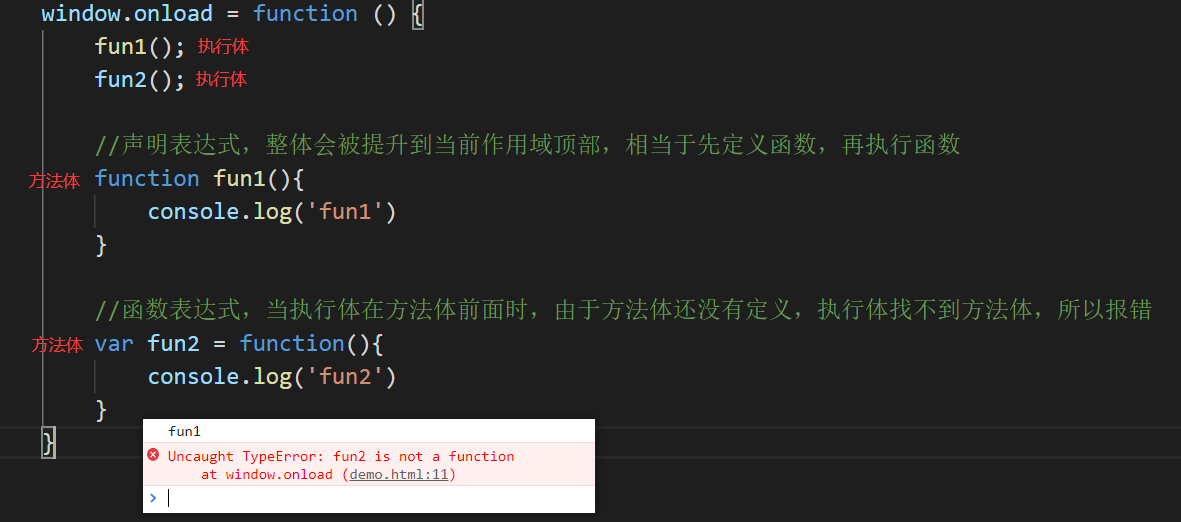
3.如何定义函数?
- 函数声明:整体会被提升到当前作用域顶部。
- 表达式:也会提升到顶部,但是只有变量名提升。
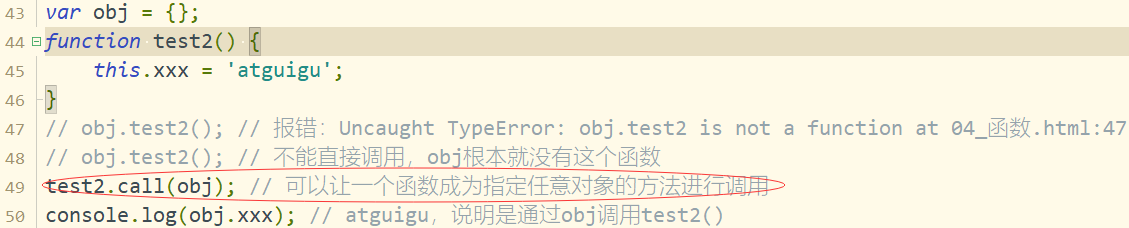
4. 如何调用(执行)函数?
- test():直接调用
- obj.test():通过对象调用
- new test():new 调用
- test.call/apply(obj):临时让test成为obj的方法进行调用
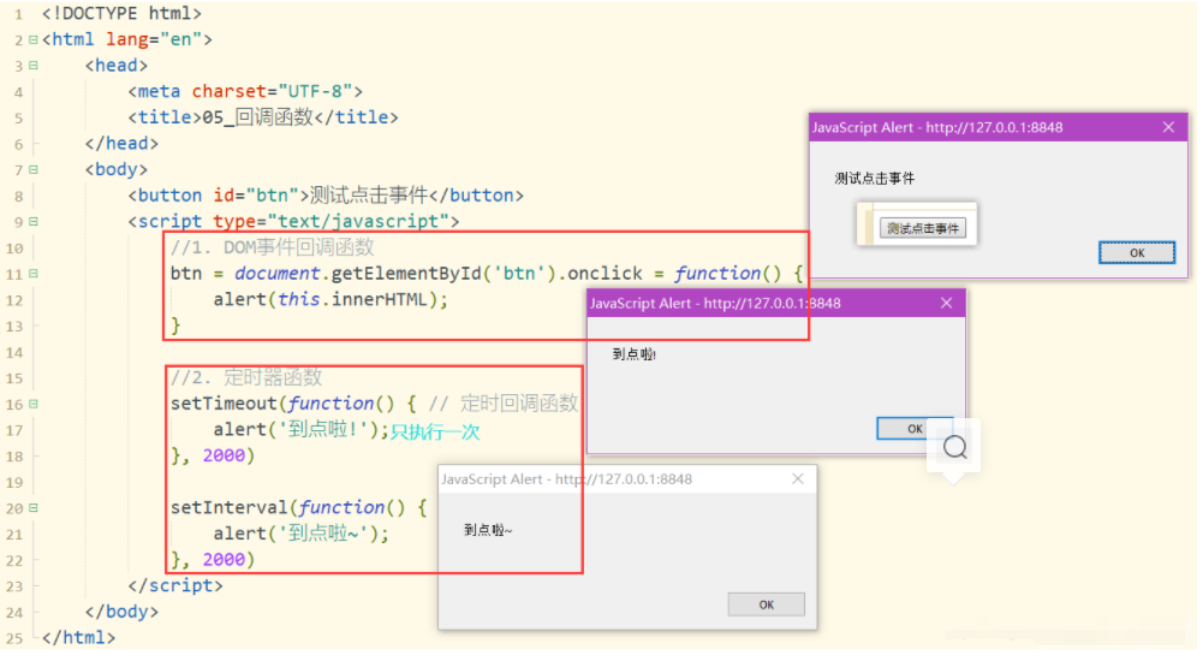
5.什么函数才是回调函数?
- 用户定义的
- 用户没有直接调用
- 但最终它执行了(在某个时刻或某个条件下 在特定条件或时刻)
6.常见的回调函数?
- dom事件回调函数 ==> 发生事件的dom元素
- 定时器回调函数 ==> window
- 超时定时器
setTimeOut(function(){},延迟时间) - 循环定时器
setInterval(function(){},定时)
- 超时定时器
- 后面学:ajax请求回调函数、生命周期回调函数
7.匿名函数(IIFE)
1. 理解
- 全称:Immediately-Invoked Function Expression,立即调用函数表达式
- 别名:匿名函数自调用
2. 作用
- 隐藏内部实现
- 不会污染外部(全局)命名空间
- 用它来编码js模块
匿名函数自调用,并且只能执行一次。匿名函数得是一个表达式,不能是函数声明。
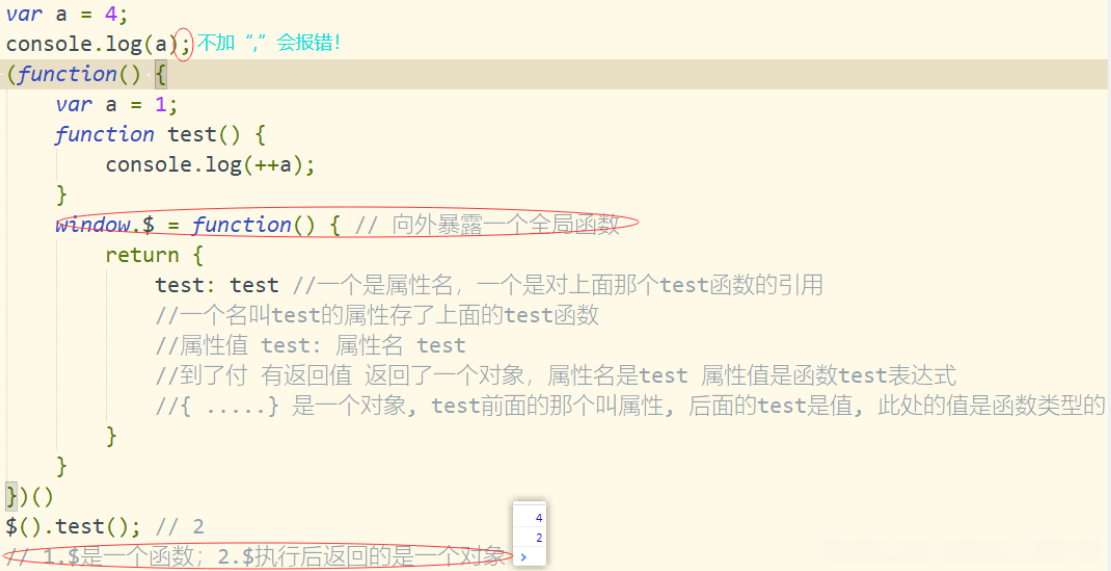
(function () { //匿名函数自调用
var a = 3
console.log(a + 3)
})()
console.log(a) // a is not defined
//此处前方为何要一个`;`-->因为自调用函数外部有一个()包裹,可能与前方以()结尾的代码被一起认为是函数调用
//不加分号可能会被认为这样 console.log(a)(IIFE)
;(function () {//不会污染外部(全局)命名空间-->举例
let a = 1;
function test () { console.log(++a) } //声明一个局部函数test
window.$ = function () { return {test: test} }// 向外暴露一个全局函数
})()
test () //test is not defined
$().test() // 1. $是一个函数 2. $执行后返回的是一个对象
函数中的this
① this是什么?
- 任何函数本质上都是通过某个对象来调用的,如果没有直接指定就是window
- 所有函数内部都有一个变量this
- 它的值是
调用函数的当前对象
② 如何确定this的值?
- test(): window
- p.test(): p
- new test(): 新创建的对象
- p.call(obj): obj
③ 代码举例详解
function Person(color) { console.log(this) this.color = color; this.getColor = function () { console.log(this) return this.color; }; this.setColor = function (color) { console.log(this) this.color = color; }; } Person("red"); //this是谁? window const p = new Person("yello"); //this是谁? p p.getColor(); //this是谁? p const obj = {}; //调用call会改变this指向-->让我的p函数成为`obj`的临时方法进行调用 p.setColor.call(obj, "black"); //this是谁? obj const test = p.setColor; test(); //this是谁? window -->因为直接调用了 function fun1() { function fun2() { console.log(this); } fun2(); //this是谁? window } fun1();//调用fun1
关于语句分号
- js一条语句的后面可以不加分号
- 是否加分号是编码风格问题, 没有应该不应该,只有你自己喜欢不喜欢
- 在下面2种情况下不加分号会有问题
小括号开头的前一条语句中方括号开头的前一条语句
- 解决办法: 在行首加分号
- 强有力的例子: vue.js库
- 知乎热议: https://www.zhihu.com/question/20298345
二、函数高级
1、原型与原型链
Ⅰ-原型 [prototype]
- 函数的
prototype属性
- 每个函数都有一个prototype属性, 它默认指向一个Object空对象(即称为: 原型对象)
- 原型对象中有一个属性constructor, 它指向函数对象
- 给原型对象添加属性(
一般都是方法)
- 作用: 函数的所有实例对象自动拥有原型中的属性(方法)
- 代码示例
// 每个函数都有一个prototype属性, 它默认指向一个Object空对象(即称为: 原型对象) console.log(Date.prototype, typeof Date.prototype) function Fun () { } console.log(Fun.prototype) // 默认指向一个Object空对象(没有我们的属性) // 原型对象中有一个属性constructor, 它指向函数对象 console.log(Date.prototype.constructor===Date) console.log(Fun.prototype.constructor===Fun) //给原型对象添加属性(一般是方法) ===>实例对象可以访问 Fun.prototype.test = function () { console.log('test()') } var fun = new Fun() fun.test()
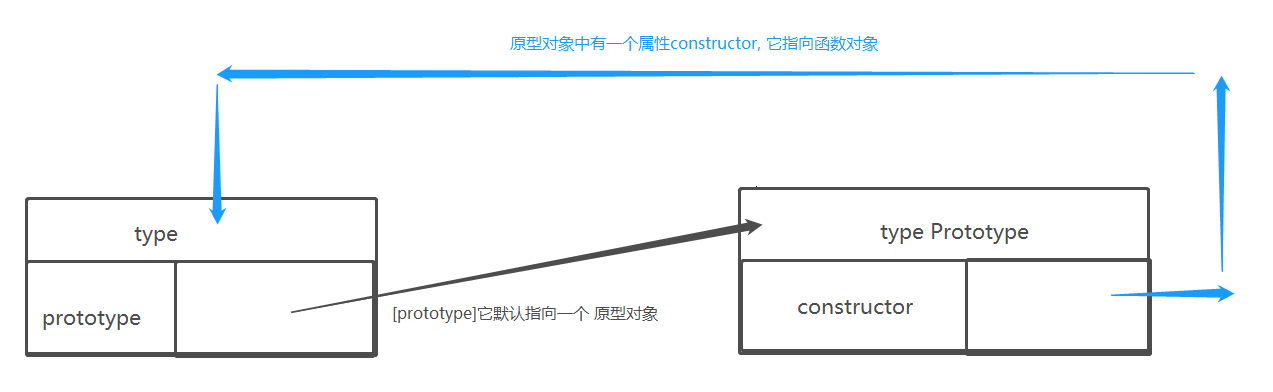
Ⅱ-显式原型与隐式原型
每个函数function都有一个
prototype,即显式原型(属性)每个实例对象都有一个[
__ proto __],可称为隐式原型(属性)对象的隐式原型的值为其对应构造函数的显式原型的值
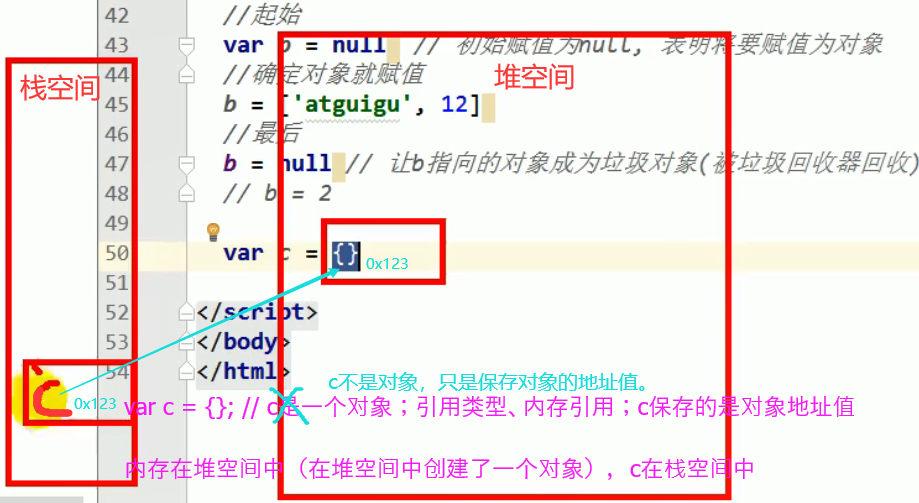
内存结构
总结:
- 函数的[
prototype]属性: 在定义函数时自动添加的, 默认值是一个空Object对象- 对象的[
__ proto __]属性: 创建对象时自动添加的,默认值为构造函数的prototype属性值- 程序员能直接操作显式原型, 但不能直接操作隐式原型(ES6之前)
- 代码示例:
//定义构造函数 function Fn() { // 内部默认执行语句: Fn.prototype = {} } // 1. 每个函数function都有一个prototype,即显式原型属性, 默认指向一个空的Object对象 console.log(Fn.prototype) // 2. 每个实例对象都有一个__proto__,可称为隐式原型 //创建实例对象 var fn = new Fn() // 内部默认执行语句: this.__proto__ = Fn.prototype console.log(fn.__proto__) // 3. 对象的隐式原型的值为其对应构造函数的显式原型的值 console.log(Fn.prototype===fn.__proto__) // true //给原型添加方法 Fn.prototype.test = function () { console.log('test()') } //通过实例调用原型的方法 fn.test()
Ⅲ-原型链
① 原型链
- 原型链
- 访问一个对象的属性时,
- 先在自身属性中查找,找到返回
- 如果没有, 再沿着[
__ proto __]这条链向上查找, 找到返回- 如果最终没找到, 返回undefined
- 别名: 隐式原型链
- 作用: 查找对象的属性(方法)
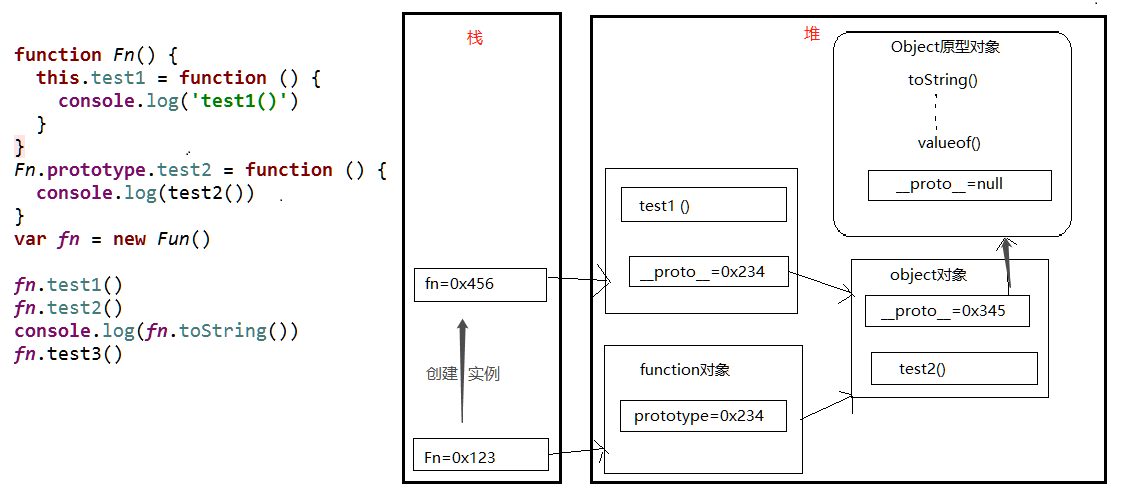
②构造函数/原型/实例对象的关系(图解)
var o1 = new Object();
var o2 = {};
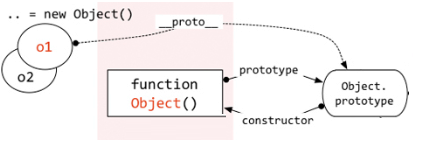
function Foo(){ } //相当于 var Foo = new Function(),说明Foo函数是Function的实例对象
function f1(){} //相当于var f1 = new Function(),
console.log(Foo.__proto__ === f1.__proto__) //true,说明任何函数的隐式原型属性 __proto__ 都指向相同的地址(该地址指向Function.prototype的值)
ps:所有函数的__proto__都是一样的
var Function = new Function(); //Function函数自己创建自己,Function既是示例对象也是构造函数 Function.__proto__ = Function.prototypeps:所有函数的[
__ proto __]都是一样的
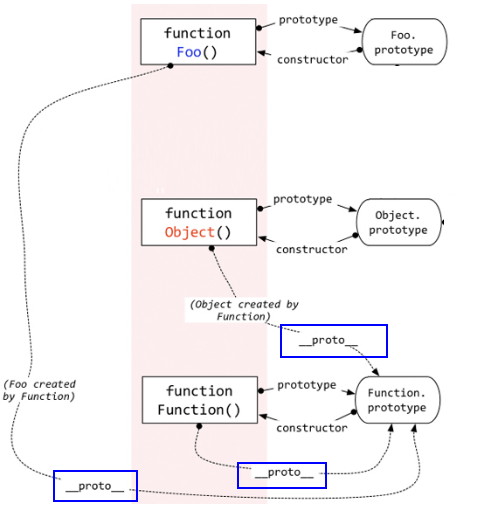
③ 属性问题
读取对象的属性值时: 会自动到原型链中查找
设置对象的属性值时: 不会查找原型链, 如果当前对象中没有此属性, 直接添加此属性并设置其值
方法一般定义在原型中, 属性一般通过构造函数定义在对象本身上
代码示例
function Fn() { } Fn.prototype.a = 'xxx' var fn1 = new Fn() console.log(fn1.a, fn1) //xxx Fn{} var fn2 = new Fn() fn2.a = 'yyy' console.log(fn1.a, fn2.a, fn2) //xxx yyy Fn{a: "yyy"} function Person(name, age) { this.name = name this.age = age } Person.prototype.setName = function (name) { this.name = name } var p1 = new Person('Tom', 12) p1.setName('Bob') console.log(p1) //Person {name: "Bob", age: 12} var p2 = new Person('Jack', 12) p2.setName('Cat') console.log(p2) //Person {name: "Cat", age: 12} console.log(p1.__proto__===p2.__proto__) // true -->所以方法一般定义在原型中
Ⅳ-instanceof

- instanceof是如何判断的?
- 表达式: A instanceof B
- 如果B函数的显式原型对象在A对象的原型链上, 返回true, 否则返回false
- Function是通过new自己产生的实例
/* 案例1 */ function Foo() { } var f1 = new Foo() console.log(f1 instanceof Foo) // true console.log(f1 instanceof Object) // true /* 案例2 */ console.log(Object instanceof Function) // true console.log(Object instanceof Object) // true console.log(Function instanceof Function) // true console.log(Function instanceof Object) // true function Foo() {} console.log(Object instanceof Foo) // false
总结:
xxx instanceof Object //永远为true,因为Object.prototype为原型链终点
xxx(函数名) instanceof Function //永远为true,var xxx = new Function(),xxx.__proto__ 等于 Function.prototyoe,一句话:实例对象的隐式原型属性等于构造函数的显式原型属性
Ⅴ-相关面试题
测试题1:
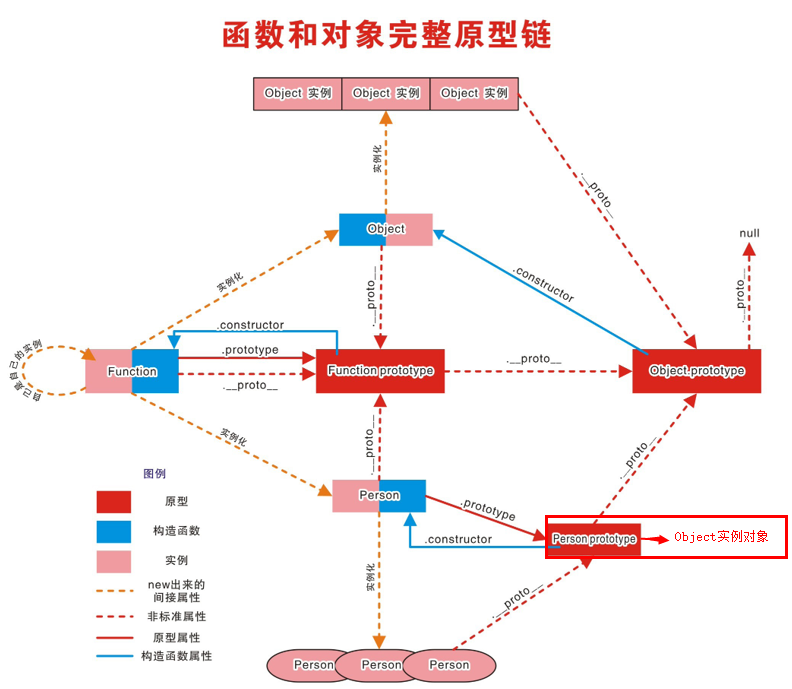
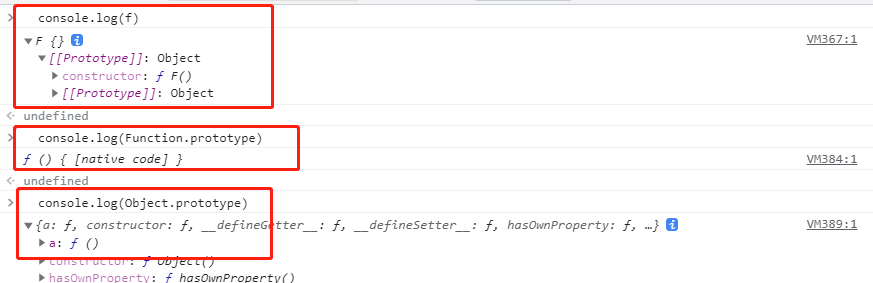
/* 测试题1 */ function A () {} A.prototype.n = 1 let b = new A() A.prototype = { n: 2, m: 3} let c = new A() console.log(b.n, b.m, c.n, c.m) // 1 undefined 2 3测试题2:原理看②构造函数/原型/实例对象的关系(图解)
/* 测试题2 */ function F (){} Object.prototype.a = function(){ console.log('a()') } Function.prototype.b = function(){ console.log('b()') } let f = new F() f.a() //a() f.b() //f.b is not a function -->找不到 F.a() //a() F.b() //b() console.log(f) console.log(Object.prototype) console.log(Function.prototype)结果图例
2、执行上下文与执行上下文栈
当代码在 JavaScript 中运行时,执行代码的环境非常重要,并将概括为以下几点:
全局代码——第一次执行代码的默认环境。
函数代码——当执行流进入函数体时。
(…) —— 我们当作 执行上下文 是当前代码执行的一个环境与范围。
换句话说,当我们启动程序时,我们从全局执行上下文中开始。一些变量是在全局执行上下文中声明的。我们称之为全局变量。当程序调用一个函数时,会发生什么?
以下几个步骤:
- JavaScript 创建一个新的执行上下文,我们叫作本地执行上下文。
- 这个本地执行上下文将有它自己的一组变量,这些变量将是这个执行上下文的本地变量。
- 新的执行上下文被推到到执行堆栈中。可以将执行堆栈看作是一种保存程序在其执行中的位置的容器。
函数什么时候结束?当它遇到一个 return 语句或一个结束括号}。
当一个函数结束时,会发生以下情况:
- 这个本地执行上下文从执行堆栈中弹出。
- 函数将返回值返回调用上下文。调用上下文是调用这个本地的执行上下文,它可以是全局执行上下文,也可以是另外一个本地的执行上下文。这取决于调用执行上下文来处理此时的返回值,返回的值可以是一个对象、一个数组、一个函数、一个布尔值等等,如果函数没有 return 语句,则返回 undefined。
- 这个本地执行上下文被销毁,销毁是很重要,这个本地执行上下文中声明的所有变量都将被删除,不在有变量,这个就是为什么 称为本地执行上下文中自有的变量。
此图出于CSDN的Free Joe
Ⅰ-变量提升与函数提升
- 变量声明提升
- 通过var定义(声明)的变量, 在定义语句之前就可以访问到
- 值: undefined
- 函数声明提升
- 通过function声明的函数, 在之前就可以直接调用
- 值: 函数定义(对象)
- 引出一个问题: 变量提升和函数提升是如何产生的?
/* 面试题 : 输出 undefined */ var a = 3 function fn () { console.log(a) var a = 4 //变量提升 } fn() //undefined '--------------------------------------------' console.log(b) //undefined 变量提升 fn2() //可调用 函数提升 // fn3() //报错 dmeo.html:22 Uncaught TypeError: fn3 is not a function 变量提升 var b = 3 function fn2() { console.log('fn2()') } var fn3 = function () { console.log('fn3()') }
Ⅱ-执行上下文
- 代码分类(位置)
- 全局代码
- 函数(局部)代码
- 全局执行上下文
- 在执行全局代码前将window确定为全局执行上下文
- 对全局数据进行预处理
- var定义的全局变量==>undefined, 添加为window的属性
- function声明的全局函数==>赋值(fun), 添加为window的方法
- this==>赋值(window)
- 开始执行全局代码
- 函数执行上下文
- 在调用函数, 准备执行函数体之前, 创建对应的函数执行上下文对象(虚拟的, 存在于栈中)
- 对局部数据进行预处理
- 形参变量>赋值(实参)>添加为执行上下文的属性
arguments==>赋值(实参列表), 添加为执行上下文的属性 -->不懂的同学看这里- var定义的局部变量==>undefined, 添加为执行上下文的属性
- function声明的函数 ==>赋值(fun), 添加为执行上下文的方法
- this==>赋值(调用函数的对象)
- 开始执行函数体代码
Ⅲ-执行上下文栈
- 在全局代码执行前, JS引擎就会创建一个栈空间来存储管理所有的执行上下文对象
- 在全局执行上下文(window)确定后, 将其添加到栈中(压栈)-->
所以栈底百分百是[window]- 在函数执行上下文创建后, 将其添加到栈中(压栈)
- 在当前函数执行完后,将栈顶的对象移除(出栈)
- 当所有的代码执行完后, 栈中只剩下window
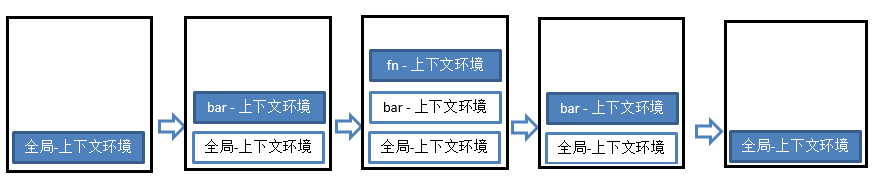
上下文栈数==函数调用数+1//1. 进入全局执行上下文 var a = 10 var bar = function (x) { var b = 5 foo(x + b) //3. 进入foo执行上下文 } var foo = function (y) { var c = 5 console.log(a + c + y) } bar(10) //2. 进入bar函数执行上下文
此处用一个动态图来展示:
举个栗子:
//栗子 <!-- 1. 依次输出什么? gb: undefined fb: 1 fb: 2 fb: 3 fe: 3 fe: 2 fe: 1 ge: 1 2. 整个过程中产生了几个执行上下文? 5 --> <script type="text/javascript"> console.log('gb: '+ i) var i = 1 foo(1) function foo(i) { if (i == 4) { return } console.log('fb:' + i) foo(i + 1) //递归调用: 在函数内部调用自己 console.log('fe:' + i) //出栈 所以会 3 2 1这样的结果 } console.log('ge: ' + i) </script>
Ⅳ-相关面试题
函数提升优先级高于变量提升,且不会被变量声明覆盖,但是会被变量赋值覆盖/* 测试题1: 先执行变量提升, 再执行函数提升 */ function a() {} var a console.log(typeof a) // 'function' /* 测试题2: */ if (!(b in window)) { var b = 1 } console.log(b) // undefined /* 测试题3: */ var c = 1 function c(c) { console.log(c) var c = 3 //与此行无关 } //相当于 /* function c(c) { console.log(c) var c = 3 //与此行无关 } var c c = 1 //此处的c函数变覆盖变成了c变量 */ c(2) // 报错 c is not a function
3、作用域与作用域链
Ⅰ-作用域
- 理解
- 就是一块"地盘", 一个代码段所在的区域
- 它是静态的(相对于上下文对象,上下文对象是动态的), 在编写代码时就确定了
- 分类
- 全局作用域
- 函数作用域
- 没有块作用域(ES6有了) -->(java语言也有)
- 作用
- 隔离变量,不同作用域下同名变量不会有冲突
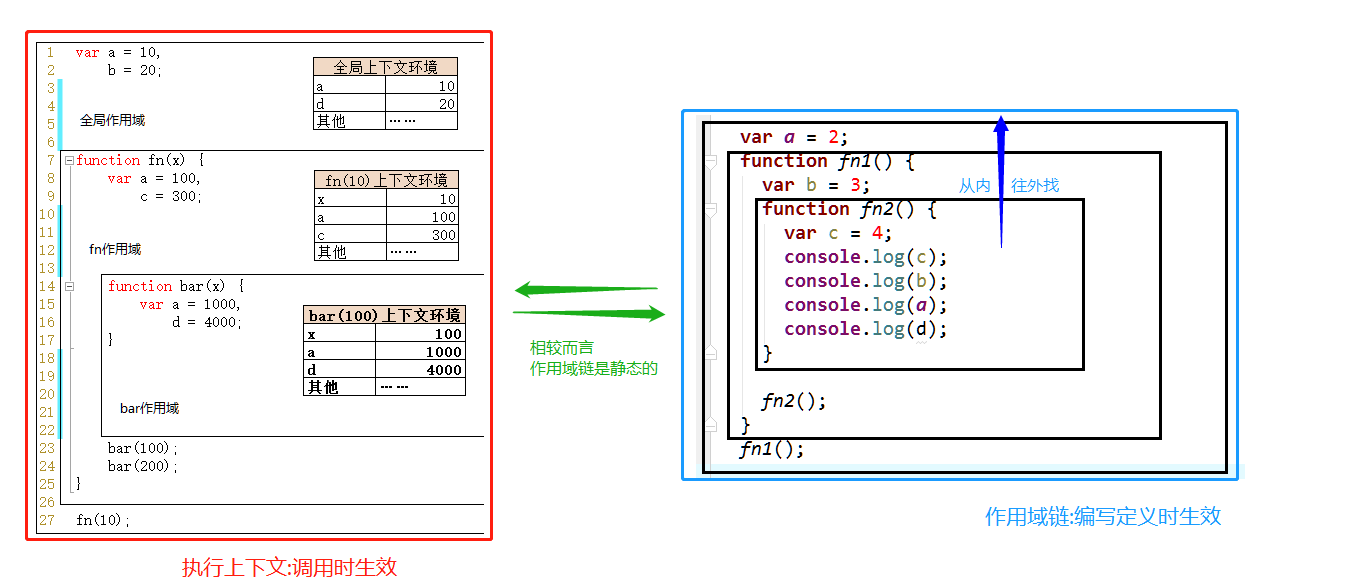
/* //没块作用域 if(true) { var c = 3 } console.log(c) */ var a = 10, b = 20 function fn(x) { var a = 100, c = 300; console.log('fn()', a, b, c, x) //100 20 300 10 function bar(x) { var a = 1000, d = 400 console.log('bar()', a, b, c, d, x) } bar(100)//1000 20 300 400 100 bar(200)//1000 20 300 400 200 } fn(10)
Ⅱ-作用域与执行上下文的区别与联系
- 区别1:
- 全局作用域之外,每个函数都会创建自己的作用域,
作用域在函数定义时就已经确定了。而不是在函数调用时- 全局执行上下文环境是在全局作用域确定之后 并且在js代码马上执行之前 创建
- 函数执行上下文是在调用函数时 并且在函数体代码执行之前 创建
- 区别2:
- 作用域是静态的, 只要函数定义好了就一直存在, 且不会再变化
- 执行上下文是动态的, 调用函数时创建, 函数调用结束时就会自动释放
- 联系:
- 执行上下文(对象)是从属于所在的作用域
- 全局上下文环境==>全局作用域
- 函数上下文环境==>对应的函数使用域
Ⅲ-作用域链
- 理解
- 多个上下级关系的作用域形成的链, 它的方向是从下向上的(从内到外)
- 查找变量时就是沿着作用域链来查找的
- 查找一个变量的查找规则
- 1.在当前作用域下的执行上下文中查找对应的属性, 如果有直接返回, 否则进入2
- 2.在上一级作用域的执行上下文中查找对应的属性, 如果有直接返回, 否则进入3
- 3.再次执行2的相同操作, 直到全局作用域, 如果还找不到就抛出找不到的异常
var a = 1 function fn1() { var b = 2 function fn2() { var c = 3 console.log(c) console.log(b) console.log(a) console.log(d) } fn2() } fn1()
Ⅳ-相关面试题
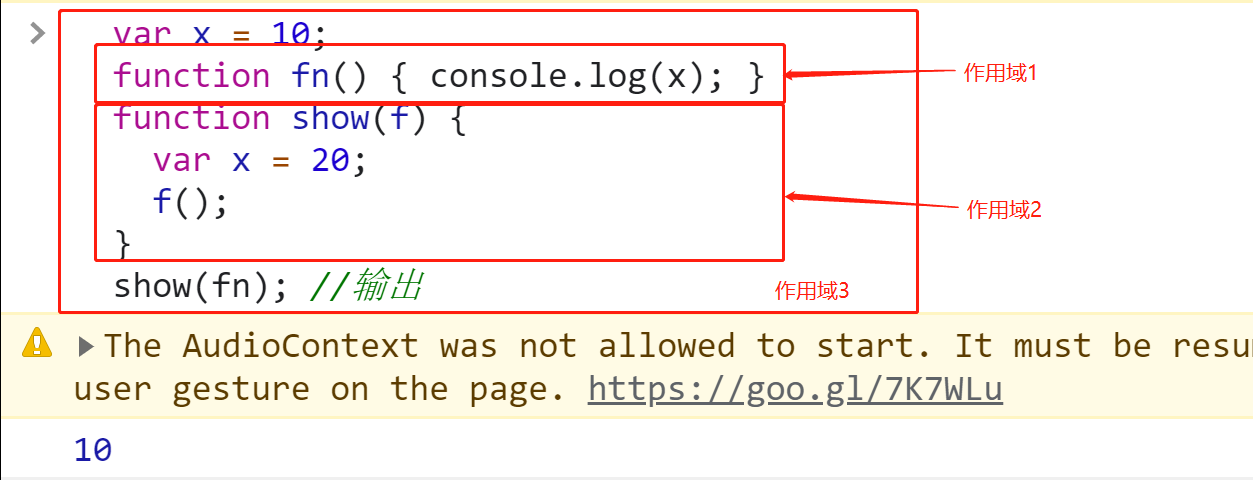
① 作用域在函数定义时就已经确定了。而不是在函数调用时
作用域1:
作用域在函数定义时就已经确定了。而不是在函数调用时var x = 10; function fn() { console.log(x); } function show(f) { var x = 20; f(); //相当于执行fn(),变量x不在fn函数的作用域内,所以往外找全局作用域x,全局作用域中有x = 10 } show(fn); //输出10
② 对象变量不能产生局部作用域
ES5里只有全局作用域和函数作用域,只有函数具有切割作用域的功能
var fn = function () { console.log(fn) } fn() var obj = { //对象变量不能产生局部作用域,所以会找到全局去,导致报错 fn2: function () { console.log(fn2) //console.log(this.fn2) } } obj.fn2()
4、闭包预备知识点梳理
在进入闭包之前,你要确保上面知识点你能掌握.你不确定 ? 噢好吧,那你就跟着我看下这部分梳理(如果懂得直接跳过即可)
Ⅰ- 举个栗子分析执行上下文
在讨论闭包之前,让我们看下下方的代码(建议先只看代码自己头脑风暴再看笔记中的描述),也算是对上面知识点的梳理回顾:
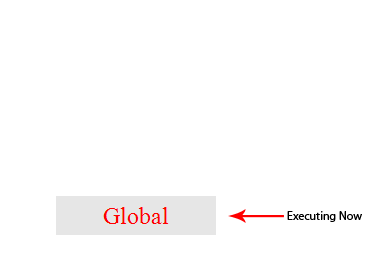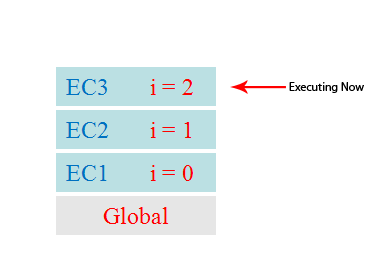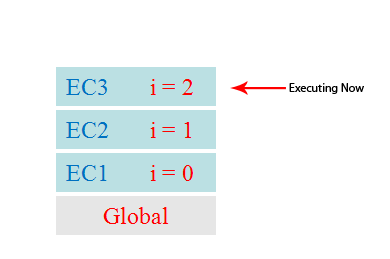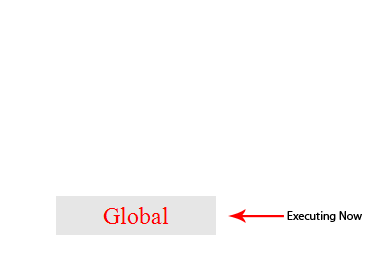
1: let a = 3 2: function addTwo(x) { 3: let ret = x + 2 4: return ret 5: } 6: let b = addTwo(a) 7: console.log(b)为了理解 JavaScript 引擎是如何工作的,让我们详细分析一下:
- 在第 1 行,我们在全局执行上下文中声明了一个新变量 a,并将赋值为 3。
- 接下来就变得棘手了,第 2 行到第 5 行实际上是在一起的。这里发生了什么?
- 我们在全局执行上下文中声明了一个名为
addTwo的新变量,我们给它分配了什么? -->一个函数定义。- 两个括号{}之间的任何内容都被分配给
addTwo,函数内部的代码没有被求值,没有被执行,只是存储在一个变量中以备将来使用。
- 现在我们在第 6 行。
- 它看起来很简单,但是这里有很多东西需要拆开分析。首先,我们在全局执行上下文中声明一个新变量,并将其标记为[
b],变量一经声明,其值即为 undefined。- 接下来,仍然在第 6 行,我们看到一个赋值操作符。我们准备给变量
b赋一个新值,接下来我们看到一个函数被调用。当您看到一个变量后面跟着一个圆括号(…)时,这就是调用函数的信号,接着,每个函数都返回一些东西(值、对象或 undefined),无论从函数返回什么,都将赋值给变量b。
- 但是首先我们需要调用标记为
addTwo的函数。JavaScript 将在其全局执行上下文内存中查找名为addTwo的变量。噢,它找到了一个,它是在[步骤 2(或第 2 - 5 行)中定义]的。变量[addTwo]包含一个函数定义。
- 注意:
变量[a]作为参数传递给函数。- JavaScript 在全局执行上下文内存中搜索变量
a,找到它,发现它的值是 3,并将数字 3 作为参数传递给函数,准备好执行函数。
- 现在执行上下文将切换,创建了一个新的本地执行上下文,我们将其命名为[“
addTwo 执行上下文”,执行上下文被推送到调用堆栈上。在 addTwo 执行上下文中,我们要做的第一件事是什么?
- 你可能会说,“在 addTwo 执行上下文中声明了一个新的变量 ret”,
这是不对的。正确的答案是:我们需要先看函数的参数。在 addTwo 执行上下文中声明一个新的变量[x],因为值 3 是作为参数传递的,所以变量 x 被赋值为 3。- 下一步才是在 addTwo 执行上下文中声明一个新的变量
ret。它的值被设置为 undefined(第三行)。
- 仍然是第 3 行,需要执行一个相加操作。
- 首先我们需要
x的值,JavaScript 会寻找一个变量x,它会首先在addTwo执行上下文中寻找,找到了一个值为 3。第二个操作数是数字 2。两个相加结果为 5 就被分配给变量ret。
- 第 4 行,我们返回变量
ret的内容,在 addTwo 执行上下文中查找,找到值为 5,返回,函数结束。- 第 4 - 5 行,函数结束。
addTwo 执行上下文被销毁,变量x和ret被消去了,它们已经不存在了。addTwo 执行上下文从调用堆栈中弹出,返回值返回给调用上下文,在这种情况下,调用上下文是全局执行上下文,因为函数addTwo是从全局执行上下文调用的。
- 现在我们继续第 4 步的内容,返回值 5 被分配给变量
b,此时实际上程序仍然在第 6 行(盗梦空间既视感🐶)- 在第 7 行,
b的值 5 被打印到控制台了。对于一个非常简单的程序,这是一个非常冗长的解释,我们甚至还没有涉及闭包。但肯定会涉及的,不过首先我们得绕一两个弯。
Ⅱ-举个栗子分析词法作用域
这里想说明,我们在函数执行上下文中有变量,在全局执行上下文中有变量。JavaScript 的一个复杂之处在于它如何查找变量,如果在函数执行上下文中找不到变量,它将在调用上下文中寻找它,如果在它的调用上下文中没有找到,就一直往上一级,直到它在全局执行上下文中查找为止。(如果最后找不到,它就是 undefined)。
1: let val1 = 2 2: function multiplyThis(n) { 3: let ret = n * val1 4: return ret 5: } 6: let multiplied = multiplyThis(6) 7: console.log('example of scope:', multiplied)下面列出几个步骤来解释一下(如果你已经熟悉了,请跳过):
- 在全局执行上下文中声明一个新的变量
val1,并将其赋值为 2。- 行 2 - 5,声明一个新的变量
multiplyThis,并给它分配一个函数定义。- 第六行,声明一个在全局执行上下文
multiplied新变量。- 从全局执行上下文内存中查找变量
multiplyThis,并将其作为函数执行,传递数字 6 作为参数。
- 新函数调用(创建新执行上下文),创建一个新的
multiplyThis函数执行上下文。- 在
multiplyThis执行上下文中,声明一个变量 n 并将其赋值为 6-->声明后才会进入函数体内部执行
- 执行函数回到第 3 行。
- 在
multiplyThis执行上下文中,声明一个变量ret。- 继续第 3 行。对两个操作数 n 和 val1 进行乘法运算.在
multiplyThis执行上下文中查找变量n。
- 我们在步骤 6 中声明了它,它的内容是数字 6。在
multiplyThis执行上下文中查找变量val1。multiplyThis执行上下文没有一个标记为 val1 的变量。我们向调用上下文查找,调用上下文是全局执行上下文,在全局执行上下文中寻找 [val1]。哦,是的、在那儿,它在步骤 1 中定义,数值是 2。- 继续第 3 行。将两个操作数相乘并将其赋值给
ret变量,6 * 2 = 12,ret 现在值为 12。
- 返回
ret变量,销毁multiplyThis执行上下文及其变量ret和n。变量val1没有被销毁,因为它是全局执行上下文的一部分。- 回到第 6 行。在调用上下文中,数字 12 赋值给
multiplied的变量。- 最后在第 7 行,我们在控制台中打印
multiplied变量的值在这个例子中,我们需要记住一个函数可以访问在它的调用上下文中定义的变量,这个就是词法作用域(Lexical scope)。
Ⅲ- 返回函数的函数[高阶函数]
在第一个例子中,函数
addTwo返回一个数字。请记住,函数可以返回任何东西。让我们看一个返回函数的函数示例,因为这对于下方理解闭包非常重要。看栗子:1: let val = 7 2: function createAdder() { 3: function addNumbers(a, b) { 4: let ret = a + b 5: return ret 6: } 7: return addNumbers 8: } 9: let adder = createAdder() 10: let sum = adder(val, 8) 11: console.log('example of function returning a function: ', sum)让我们回到分步分解:
- 第一行。我们在全局执行上下文中声明一个变量
val并赋值为 7。- 行 2 - 8。我们在全局执行上下文中声明了一个名为
createAdder的变量,并为其分配了一个函数定义。
- 内部的第 3 至 7 行描述了上述函数定义,和以前一样,在这一点上,我们没有直接讨论这个函数。我们只是将函数定义存储到[
createAdder]变量中。
- 第 9 行。
- 我们在全局执行上下文中声明了一个名为
adder的新变量,暂时,值为 undefined- 我们看到括号(),我们需要执行或调用一个函数,查找全局执行上下文的内存并查找名为
createAdder的变量,它是在步骤 2 中创建的。好吧,我们调用它。
- 调用函数时,执行到第 2 行。
- 创建一个新的
createAdder执行上下文。我们可以在createAdder的执行上下文中创建自有变量。js 引擎将createAdder的上下文添加到调用堆栈。这个函数没有参数,让我们直接跳到它的主体部分.
- 第 3 - 6 行(执行到主体函数中)。
- 我们有一个新的函数声明,我们在
createAdder执行上下文中创建一个变量 addNumbers。这很重要,addnumber只存在于createAdder执行上下文中。我们将函数定义存储在名为addNumbers的自有变量中。- 在第 7 行,我们返回变量
addNumbers的内容。js 引擎查找一个名为addNumbers的变量并找到它,这是一个函数定义。好的,函数可以返回任何东西,包括函数定义。我们返addNumbers的定义。第 4 行和第 5 行括号之间的内容构成该函数定义。
- [return addNumbers]时,
createAdder执行上下文将被销毁。addNumbers变量不再存在。但addNumbers函数定义仍然存在,因为它返回并赋值给了 adder 变量。
此处很重要!!!此时的[adder=createAdder()]实际上它的值是[addNumbers]的函数定义而不是[createAdder]了,adder现在是一个匿名函数--这里有点绕,要确定理解
- 第 10 行。我们在全局执行上下文中定义了一个新的变量
sum,先赋值为 undefined;
- 接下来我们需要执行一个函数。哪个函数?
- 是名为
adder变量中定义的函数。我们在全局执行上下文中查找它,果然找到了它,这个函数有两个参数。- 让我们查找这两个参数,第一个是我们在步骤 1 中定义的变量
val,它表示数字 7,第二个是数字 8。- 现在我们要执行这个函数,函数定义概述在第 3-5 行,
因为这个函数是匿名,为了方便理解,我们暂且叫它adder吧。这时创建一个adder函数执行上下文,在adder执行上下文中创建了两个新变量a和b。它们分别被赋值为 7 和 8,因为这些是我们在上一步传递给函数的参数。
- 执行回到第 4 行。
- 在
adder执行上下文中声明了一个名为ret的新变量,- 将变量
a的内容和变量b的内容相加得 15 并赋给 ret 变量。
ret变量从该函数返回。这个匿名函数执行上下文被销毁,从调用堆栈中删除,变量a、b和ret不再存在。- 返回值被分配给我们在步骤 10中定义的
sum变量。- 我们将
sum的值打印到控制台。如预期,控制台将打印 15。我们在这里确实经历了很多困难,我想在这里说明几点。首先,函数定义可以存储在变量中,函数定义在程序调用之前是不可见的。其次,每次调用函数时,都会(临时)创建一个本地执行上下文。当函数完成时,执行上下文将消失。函数在遇到 return 或右括号}时执行完成。
高阶函数是什么?
所谓高阶函数,就是一个函数就可以接收另一个函数作为参数,或者是返回一个函数-->常见的高阶函数有map、reduce、filter、sort等
var ADD =function add(a) { return function(b) { return a+b } } //调用:ADD(2)(3)即可获得结果
- map
//map接受一个函数作为参数,不改变原来的数组,只是返回一个全新的数组 var arr = [1,2,3,4,5] var arr1 = arr.map(item => item = 2) //arr 输出[1,2,3,4,5] //arr1 输出[2,2,2,2,2]
- reduce
//reduce也是返回一个全新的数组。reduce接受一个函数作为参数,这个函数要有两个形参,代表数组中的前两项,reduce会将这个函数的结果与数组中的第三项再次组成这个函数的两个形参以此类推进行累积操作 var arr = [1,2,3,4,5] var arr2 = arr.reduce((a,b)=> a+b) console.log(arr2) // 15
- filter
//filter返回过滤后的数组。filter也接收一个函数作为参数,这个函数将作用于数组中的每个元素,根据该函数每次执行后返回的布尔值来保留结果,如果是true就保留,如果是false就过滤掉(这点与map要区分) var arr = [1,2,3,4,5] var arr3 = arr.filter(item => item % 2 == 0) console.log(arr3)// [2,4]
5、闭包
如何产生闭包
<!--
1. 如何产生闭包?
* 当一个嵌套的内部(子)函数引用了嵌套的外部(父)函数的变量(函数)时, 就产生了闭包
2. 闭包到底是什么?
* 使用chrome调试查看
* 理解一: 闭包是嵌套的内部函数(绝大部分人)
* 理解二: 包含被引用变量(函数)的对象(极少数人)
* 注意: 闭包存在于嵌套的内部函数中
3. 产生闭包的条件?
* 函数嵌套
* 内部函数引用了外部函数的数据(变量/函数)
-->
一个函数和对其周围状态(lexical environment,词法环境)的引用捆绑在一起(或者说函数被引用包围),这样的组合就是闭包(closure)。也就是说,闭包让你可以在一个内层函数中访问到其外层函数的作用域。在 JavaScript 中,每当创建一个函数,闭包就会在函数创建的同时被创建出来。
Ⅰ-引出闭包概念
① 错误场景
需求:
点击某个按钮, 提示"点击的是第n个按钮"<button>测试1</button> <button>测试2</button> <button>测试3</button> <!-- 需求: 点击某个按钮, 提示"点击的是第n个按钮" --> <script type="text/javascript"> var btns = document.getElementsByTagName('button') //注意[btns]不是一个数组,它是一个伪数组 //每次获取[btns.length]其实都是需要进行计算的(因为它是伪数组) //所以为了性能更好,在此处赋值,就只需要计算一次 for (var i = 0,length=btns.length; i < length; i++) { var btn = btns[i] btn.onclick = function () { //遍历加监听 alert('第'+(i+1)+'个') //结果 全是[4] } } </script>此处错误是,直接修改并使用全局变量[
i],导致for循环结束后,所有点击按钮绑定的弹窗值都是[i+1]随后调用时,都会找到[
i]这个变量,但是此时i==3,所以所有结果都是4

② 将变量挂载到自身来解决
解决方式:将btn所对应的下标保存在btn上
<button>测试1</button> <button>测试2</button> <button>测试3</button> <!-- 需求: 点击某个按钮, 提示"点击的是第n个按钮" --> <script type="text/javascript"> var btns = document.getElementsByTagName('button') for (var i = 0,length=btns.length; i < length; i++) { var btn = btns[i] //将btn所对应的下标保存在btn上 btn.index = i btn.onclick = function () { //遍历加监听 alert('第'+(this.index+1)+'个') //结果 全是[4] } } </script>将其放在自己的身上,需要时自己找自己拿,这样就能解决
伪数组
特征:
-
具有length属性
-
按索引方式存储数据
-
不具有数组的方法, 比如push(),pop()等
生成伪数组的方法
在js中生成伪数组的方法比较多
-
function的arguments对象
-
document.getElementsByTagName和document.childNodes,返回NodeList对象的都是伪数组
-
上传文件时选择的file对象也是伪数组
-
自定义的某些对象
将伪数组转为真正的数组
- 使用Array.prototype.slice.call();
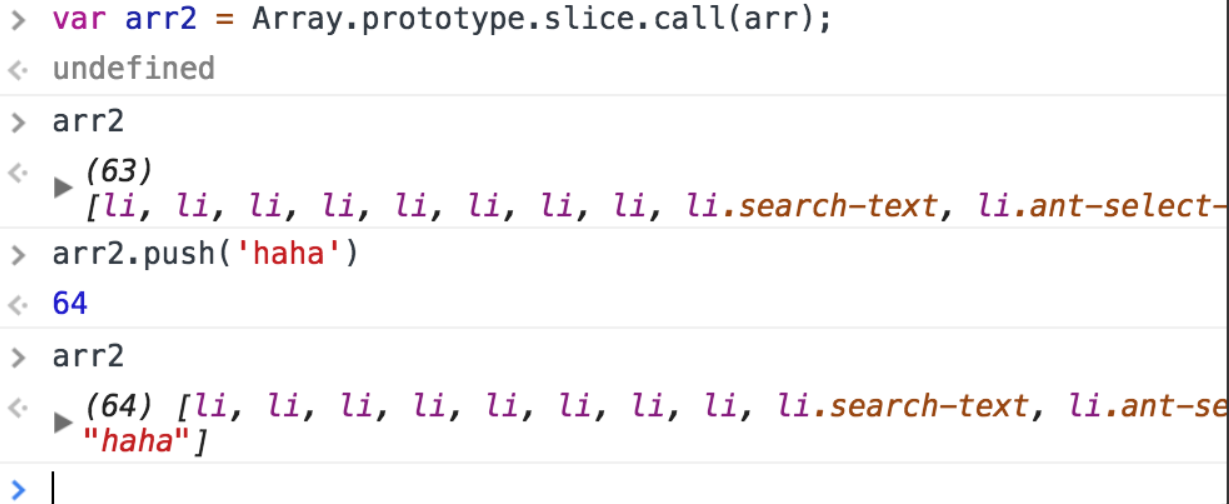
- 使用[].slice.call();了解js原型链的都知道,其实这种方法和上面的方法是一样的,但是上面的方式效率相对较高
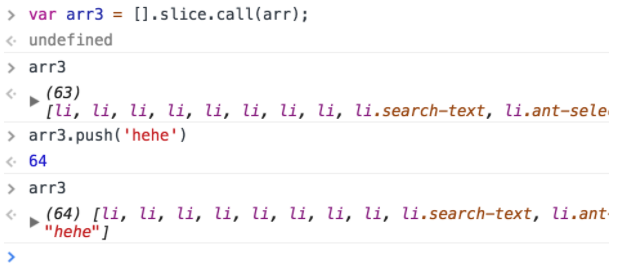
- 使用ES6的Array.from();
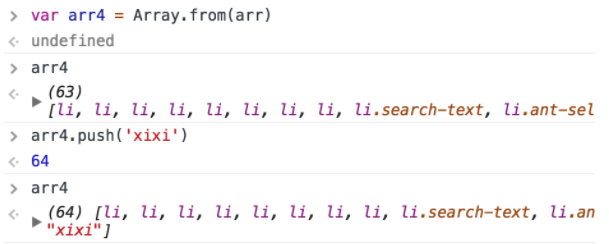
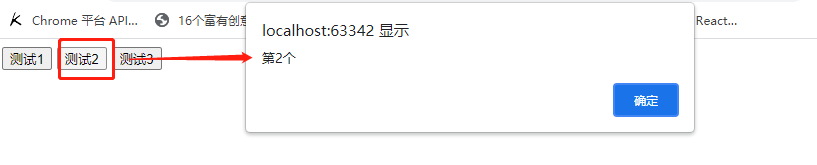
③ 利用闭包
利用闭包知识点解决,引出下方知识点,不懂的可以带着疑问继续往下看
<body> <button>测试1</button> <button>测试2</button> <button>测试3</button> <script type="text/javascript"> //利用闭包 for (var i = 0,length=btns.length; i < length; i++) { //此处的j是局部的,它将传入的[i]存入局部的[j]中,这样就能实现效果 (function (j) { var btn = btns[j] btn.onclick = function () { alert('第'+(j+1)+'个') } })(i) } </script> </body>
Ⅱ-举个闭包栗子分析理解
按照上方 [
4]代码举例分析流程的方式 来尝试理解闭包概念提前给出一个闭包栗子进行分析,先看看发生什么,再去看它的概念进行印证,相信我,你会有种拨开迷雾的感受
① 按照正常逻辑理解
先说,此部分不是按照闭包机制进行理解,所以中途发觉不对(
肯定有地方不对劲)请勿钻牛角尖,主要用作后方对照1: function createCounter() { 2: let counter = 0 3: const myFunction = function() { 4: counter = counter + 1 5: return counter 6: } 7: return myFunction 8: } 9: const increment = createCounter() 10: const c1 = increment() 11: const c2 = increment() 12: const c3 = increment() 13: console.log('example increment', c1, c2, c3)现在,我们已经从前几个示例中掌握了它的诀窍,让我们按照预期的方式快速执行它: (
错误的流程理解,故意按照正常的逻辑流程走,做印证)
- 行 1 - 8。我们在全局执行上下文中创建了一个新的变量
createCounter,并赋值了一个的函数定义。- 第 9 行。
- 我们在全局执行上下文中声明了一个名为
increment的新变量。- 我们需要调用
createCounter函数并将其返回值赋给increment变量。
- 返回执行 行 1 - 8。调用函数,创建新的本地执行上下文。
- 第 2 行。在本地执行上下文中,声明一个名为
counter的新变量并赋值为 0;- 行 3 - 6。声明一个名为
myFunction的新变量,变量在本地执行上下文中声明,变量的内容是为第 4 行和第 5 行所定义。- 第 7 行。返回
myFunction变量的内容,删除本地执行上下文。变量myFunction和counter不再存在。此时控制权回到了调用上下文。
- 再次回到 第 9 行
- 在调用上下文(全局执行上下文)中,
createCounter返回的值赋给了increment,变量increment现在包含一个函数定义内容为createCounter返回的函数。- 它不再标记为
myFunction,但它的定义是相同的。在全局上下文中,它的标记为increment。
- 第 10 行。声明一个新变量(c1)。
- 继续第 10 行。查找
increment变量,它是一个函数并调用它。它包含前面返回的函数定义,如第 4-5 行所定义的。- 创建一个新的执行上下文。没有参数。开始执行函数。
- 回到 第 4 行。
- counter=counter + 1。在本地执行上下文中查找
counter变量。- 我们只是创建了那个上下文,从来没有声明任何局部变量。让我们看看全局执行上下文。这里也没有
counter变量。- Javascript 会将其计算为 counter = undefined + 1,声明一个标记为
counter的新局部变量,并将其赋值为 number 1,因为 undefined 被当作值为 0。-->此处是错误的哦,别钻牛角尖,正确的理解在下方,此处是做错误对比
- 第 5 行。我们变量
counter的值(1),我们销毁本地执行上下文和counter变量。- 回到第 10 行。返回值(1)被赋给 c1。
- 第 11 行。重复步骤 10-14,c2 也被赋值为 1。
- 第 12 行。重复步骤 10-14,c3 也被赋值为 1。
- 第 13 行。我们打印变量 c1 c2 和 c3 的内容。
你自己试试,看看会发生什么。你会将注意到,
它并不像从我上面的解释中所期望的那样记录 1,1,1。而是记录 1,2,3。这个是为什么?
②正确的理解
不知怎么滴,
increment函数记住了那个counter的值。这是怎么回事?
- counter是全局执行上下文的一部分吗?
- 尝试 console.log(counter),得到undefined的结果,显然不是这样的。
- 也许,当你调用increment时,它会以某种方式返回它创建的函数(createCounter)?
- 这怎么可能呢?变量increment包含函数定义,而不是函数的来源,显然也不是这样的。
- 所以一定有另一种机制。闭包,我们终于找到了,丢失的那块。
- **-
它是这样工作的,无论何时声明新函数并将其赋值给变量,都要存储函数定义和闭包。闭包包含了函数创建时作用域中的所有变量,它类似于背包。函数定义附带一个小背包,它的包中存储了函数定义创建时作用域中的所有变量**所以我们上面的解释都是错的,让我们再试一次,但是这次是正确的
1: function createCounter() { 2: let counter = 0 3: const myFunction = function() { 4: counter = counter + 1 5: return counter 6: } 7: return myFunction 8: } 9: const increment = createCounter() 10: const c1 = increment() 11: const c2 = increment() 12: const c3 = increment() 13: console.log('example increment', c1, c2, c3)
- 同上,第
1-8行。我们在全局执行上下文中创建了一个新的变量createCounter,它得到了指定的函数定义。- 同上,第
9行。
- 我们在全局执行上下文中声明了一个名为
increment的新变量。- 我们需要调用
createCounter函数并将其返回值赋给increment变量。
- 同上,第
1-8行。调用函数,创建新的本地执行上下文。
- 第
2行。在本地执行上下文中,声明一个名为counter的新变量并赋值为0。- 第
3-6行。声明一个名为myFunction的新变量,变量在本地执行上下文中声明,变量的内容是另一个函数定义。如第4行和第5行所定义,现在我们还创建了一个闭包,并将其作为函数定义的一部分。闭包包含作用域中的变量,在本例中是变量counter(值为0)。- 第
7行。返回myFunction变量的内容,删除本地执行上下文。myFunction和counter不再存在。控制权交给了调用上下文,我们返回函数定义和它的闭包,闭包中包含了创建它时在作用域内的变量。
- 回到第
9行。
- 在调用上下文(全局执行上下文)中,
createCounter返回的值被指定为increment- 变量
increment现在包含一个函数定义(和闭包),由createCounter返回的函数定义,它不再标记为myFunction,但它的定义是相同的,在全局上下文中,称为increment。
- 第
10行。声明一个新变量c1。
- 继续第
10行。查找变量increment,它是一个函数,调用它。它包含前面返回的函数定义,如第4-5行所定义的。(它还有一个带有变量的闭包)。- 创建一个新的执行上下文,没有参数,开始执行函数。
- 第
4行。[counter = counter + 1],寻找变量 [counter],在查找本地或全局执行上下文之前,让我们检查一下闭包,瞧,闭包包含一个名为[counter]的变量,其值为0。在第4行表达式之后,它的值被设置为1。它再次被储存在闭包里,闭包现在包含值为1的变量 [counter]。- 第
5行。我们返回counter的值,销毁本地执行上下文。- 回到第
10行。返回值1被赋给变量c1。- 第
11行。我们重复步骤5-7。这一次,在闭包中此时变量counter的值是1。它在第12行设置的,它的值被递增并以2的形式存储在递增函数的闭包中,c2被赋值为2。- 第
12行。重复步骤5-7行,c3被赋值为3。- 第13行。我们打印变量
c1 c2和c3的值。**
你此时可能会问,是否任何函数都具有闭包,甚至是在全局范围内创建的函数?**答案是肯定的。在全局作用域中创建的函数创建闭包,但是由于这些函数是在全局作用域中创建的,所以它们可以访问全局作用域中的所有变量,闭包的概念并不重要。
但当函数返回函数时,闭包的概念就变得更加重要了。返回的函数可以访问不属于全局作用域的变量,但它们仅存在于其闭包中。
Ⅲ-常见的闭包
① 将函数作为另一个函数的返回值,并且内部函数引用外面函数的变量
注意:闭包创建时期:执行函数定义就会产生闭包(不用调用内部函数)
<script type="text/javascript"> // 1. 将函数作为另一个函数的返回值 function fn1() { var a = 2 function fn2() { a++ console.log(a) } return fn2 } var f = fn1() f() // 3 f() // 4 </script>
② 将函数(带有父函数的属性)作为实参传递给另一个函数调用
// 2. 将函数作为实参传递给另一个函数调用 function showDelay(msg, time) { setTimeout(function () { alert(msg) }, time) } showDelay('atguigu', 2000)
③ 高阶函数与柯里化
有时候闭包在你甚至没有注意到它的时候就会出现,你可能已经看到了我们称为部分应用程序的实例
当然如果你还不理解的话,可以完整的多看几次本笔记闭包知识点部分,或者结合上方
Ⅱ-举个闭包栗子分析理解进行理解
1、从 ES6 高阶箭头函数理解函数柯里化(运用到闭包)
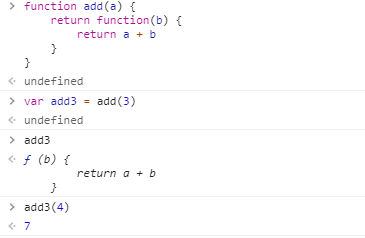
- 首先看到了这样的一个例子:
let add = a => b => a + b
- 以上是一个很简单的相加函数,把它转化成 ES5 的写法如下
function add(a) { return function(b) { return a + b } } var add3 = add(3) //add3表示一个指向函数的变量 可以当成函数调用名来用 add3(4) === 3 + 4 //true
- 再简化一下,可以写成如下形式:
let add = function(a) { var param = a; var innerFun = function(b) { return param + b; } return innerFun; }
- 虽然好像没什么意义,但是很显然上述使用了[
闭包],而且该函数的返回值是一个函数。其实,这就是高阶函数的定义:以函数为参数或者返回值是函数的函数。
2、柯里化
- 图例:
- 关键就是
理解柯里化,其实可以把它理解成,柯里化后,将第一个参数变量存在函数里面了(闭包),然后本来需要n个参数的函数可以变成只需要剩下的(n - 1个)参数就可以调用,比如let add = x => y => x + y let add2 = add(2) -*---------------------------------- 本来完成 add 这个操作,应该是这样调用 let add = (x, y) => x + y add(2,3) ---------------------------------- 1. 而现在 add2 函数完成同样操作只需要一个参数,这在函数式编程中广泛应用。 let add = x => y => x + y let add2 = add(2) 2.详细解释一下,就是 add2 函数 等价于 有了 x 这个闭包变量的 y => x + y 函数,并且此时 x = 2,所以此时调用 add2(3) === 2 + 3

4、总结
- 如果是
a => b => c => {xxx}这种多次柯里化的,如何理解?理解:前
n - 1次调用,其实是提前将参数传递进去,并没有调用最内层函数体,最后一次调用才会调用最内层函数体,并返回最内层函数体的返回值
结合上文可知,这里的多个连续箭头(无论俩个箭头函数三个及以上)函数连在一起 就是在柯里化。所以连续箭头函数就是多次柯里化函数的 es6 写法。
调用特点:let test = a => b => c =>比如对于上面的
test函数,它有 3 个箭头, 这个函数要被调用 3 次test(a)(b)(c),前两次调用只是在传递参数,只有最后一次调用才会返回{xxx}代码段的返回值,并且在{xxx}代码段中可以调用 a,b,c
Ⅳ-闭包的作用
- 使用函数内部的变量在函数执行完后, 仍然存活在内存中(延长了局部变量的生命周期)
让函数外部可以操作(读写)到函数内部的数据(变量/函数)- 闭包说白了就是把变量变成对象的属性,从而不受函数作用的限制
问题:
1. 函数执行完后, 函数内部声明的局部变量是否还存在? - 一般是不存在, 存在于闭包中的变量才可能存在 2. ~~在函数外部能直接访问函数内部的局部变量吗?~~ - ~~不能, 但我们可以通过闭包让外部操作它~~
Ⅴ-闭包的生命周期
- 产生: 在嵌套内部函数定义执行完时就产生了(不是在调用)
- 死亡: 在嵌套的内部函数成为垃圾对象时
- 即没有人指向它时死亡,通常置为[
null],当然指向其他也行,但不安全(容易污染变量)//闭包的生命周期 function fn1() { //此时闭包就已经产生了(函数提升,实际上[fn2]提升到了第一行, 内部函数对象已经创建了) var a = 2 function fn2 () { //如果时[let fn2=function(){}],那么在这行才会产生闭包 a++ console.log(a) } return fn2 } var f = fn1() f() // 3 f() // 4 f = null //闭包死亡(包含闭包的函数对象成为垃圾对象)
Ⅵ-闭包的应用
闭包的应用 : 定义JS模块
- 具有特定功能的js文件
- 将所有的数据和功能都封装在一个函数内部(私有的)
- 只向外暴露一个包含n个方法的对象或函数
- 模块的使用者, 只需要通过模块暴露的对象调用方法来实现对应的功能
- 模块定义:
//myModule.js function myModule() { //私有数据 var msg = 'My atguigu' //操作数据的函数 function doSomething() { console.log('doSomething() '+msg.toUpperCase()) } function doOtherthing () { console.log('doOtherthing() '+msg.toLowerCase()) } //向外暴露对象(给外部使用的方法) return { doSomething: doSomething, doOtherthing: doOtherthing } } ----------------------------------------------------------------- // myModule2.js (function () { //私有数据 var msg = 'My atguigu' //操作数据的函数 function doSomething() { console.log('doSomething() '+msg.toUpperCase()) } function doOtherthing () { console.log('doOtherthing() '+msg.toLowerCase()) } //向外暴露对象(给外部使用的方法) window.myModule2 = { doSomething: doSomething, doOtherthing: doOtherthing } })()
- 模块调用
//调用示例 ------------ 模块调用1 -------------------------------------------- <script type="text/javascript" src="myModule.js"></script> <script type="text/javascript"> var module = myModule() module.doSomething() module.doOtherthing() </script> ------------ 模块调用2 -------------------------------------------- <script type="text/javascript" src="myModule2.js"></script> <script type="text/javascript"> myModule2.doSomething() myModule2.doOtherthing() </script>
Ⅶ-闭包的缺点及解决
- 缺点:
- 函数执行完后, 函数内的局部变量没有释放, 占用内存时间会变长
- 容易造成内存泄露
- 解决:
能不用闭包就不用
及时释放
function fn1() { var arr = new Array(100000) function fn2() { console.log(arr.length) } return fn2 } var f = fn1() f() f = null //让内部函数成为垃圾对象-->回收闭包
Ⅷ-内存溢出与内存泄露
- 内存溢出
- 一种程序运行出现的错误
- 当程序运行需要的内存超过了剩余的内存时, 就出抛出内存溢出的错误
- 内存泄露
占用的内存没有及时释放
内存泄露积累多了就容易导致内存溢出常见的内存泄露:
意外的全局变量
没有及时清理的计时器或回调函数
闭包
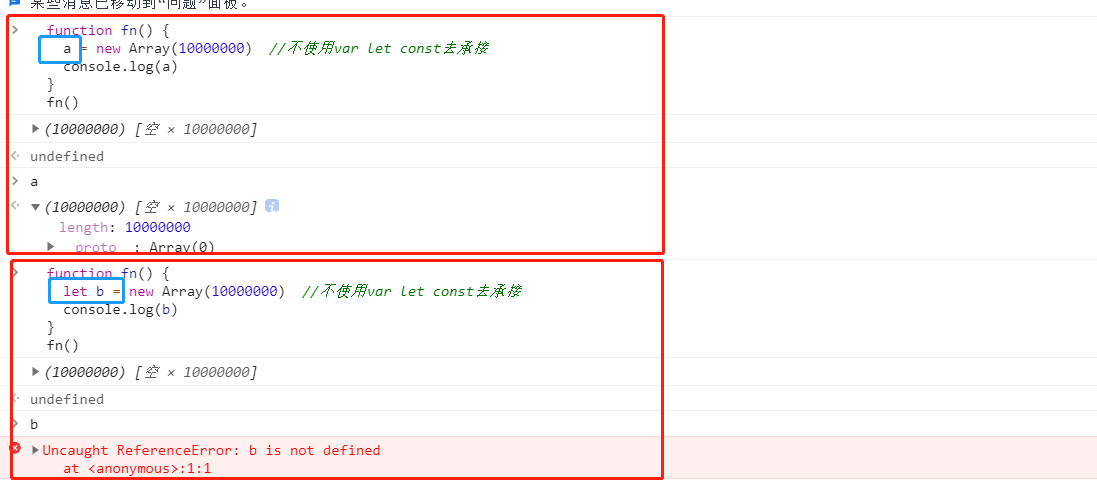
<script type="text/javascript"> // 1. 内存溢出 var obj = {} for (var i = 0; i < 10000; i++) { obj[i] = new Array(10000000) console.log('-----') } // 2. 内存泄露 // 意外的全局变量 function fn() { a = new Array(10000000) //不使用var let const去承接 console.log(a) } fn() // 没有及时清理的计时器或回调函数 var intervalId = setInterval(function () { //启动循环定时器后不清理 console.log('----') }, 1000) // clearInterval(intervalId) // 闭包 function fn1() { var a = 4 function fn2() { console.log(++a) } return fn2 } var f = fn1() f() // f = null </script>不使用let const var等去声明,实际上是挂载到[
window]上的,所以导致内存泄露
Ⅸ-相关面试题1
<script type="text/javascript"> //代码片段一 -->没有产生闭包:因为内部函数没有调用外部变量 var name = "The Window"; var object = { name: "My Object", getNameFunc: function () { return function () { return this.name; }; } }; alert(object.getNameFunc()()); //? the window //函数体的this是window //代码片段二 var name2 = "The Window"; var object2 = { name2: "My Object", getNameFunc: function () { //此处的this指向是[getNameFunc],他是对象中的属性,所以this指向就是object var that = this; return function () { //此处用的是保存的 that return that.name2; }; } }; alert(object2.getNameFunc()()); //? my object </script>
- 代码片段一:
- 函数体的
this指向是[window]- 没有产生闭包:因为内部函数没有调用外部变量
- 代码片段二为何指向是对象?
- this指向是调用它的[
getNameFunc],他是对象中的属性,所以this指向就是object- 产生了闭包
Ⅹ-相关面试题2,这个太难了,看不懂就算了
<script type="text/javascript"> function fun(n, o) { console.log(o) return { fun: function (m) { return fun(m, n) } } } var a = fun(0) //undefined a.fun(1) //0 a.fun(2) //0 a.fun(3) //0 var b = fun(0).fun(1).fun(2).fun(3) //undefined 0 1 2 var c = fun(0).fun(1) //undefined 0 c.fun(2)//1 -->经过上方定义后 n固定为1 c.fun(3)//1 -->此处是陷阱!!! 一直没有改到n,所以一直是1 </script>
三、面向对象高级
此部分要求你对前方函数高级部分的1、原型与原型链比较熟悉,如果掌握不够好理解会相对困难
1、对象创建模式
Ⅰ-Object构造函数模式
方式一: Object构造函数模式
- 套路: 先创建空Object对象, 再动态添加属性/方法
- 适用场景: 起始时不确定对象内部数据
- 问题: 语句太多
/*一个人: name:"Tom", age: 12*/ // 先创建空Object对象 //var p = new Object() p = {} //此时内部数据是不确定的 // 再动态添加属性/方法 p.name = 'Tom' p.age = 12 p.setName = function (name) { this.name = name } //测试 console.log(p.name, p.age) p.setName('Bob') console.log(p.name, p.age)
Ⅱ-对象字面量模式
方式二: 对象字面量模式
- 套路: 使用{}创建对象, 同时指定属性/方法
- 适用场景: 起始时对象内部数据是确定的
- 问题: 如果创建多个对象, 有重复代码
//对象字面量模式 var p = { name: 'Tom', age: 12, setName: function (name) { this.name = name } } //测试 console.log(p.name, p.age) p.setName('JACK') console.log(p.name, p.age) var p2 = { //如果创建多个对象代码很重复 name: 'Bob', age: 13, setName: function (name) { this.name = name } }
Ⅲ-工厂模式
方式三: 工厂模式
- 套路: 通过工厂函数动态创建对象并返回
- 适用场景: 需要创建多个对象
- 问题:
对象没有一个具体的类型, 都是Object类型//返回一个对象的函数===>工厂函数 function createPerson(name, age) { var obj = { name: name, age: age, setName: function (name) { this.name = name } } return obj } // 创建2个人 var p1 = createPerson('Tom', 12) var p2 = createPerson('Bob', 13) // p1/p2是Object类型 function createStudent(name, price) { var obj = { name: name, price: price } return obj } var s = createStudent('张三', 12000) // s也是Object
Ⅳ-自定义构造函数模式
方式四: 自定义构造函数模式
- 套路: 自定义构造函数, 通过new创建对象
- 适用场景: 需要创建多个
类型确定的对象,与上方工厂模式有所对比- 问题: 每个对象都有相同的数据, 浪费内存
<script type="text/javascript"> //定义类型 function Person(name, age) { this.name = name this.age = age this.setName = function (name) { this.name = name } } var p1 = new Person('Tom', 12) p1.setName('Jack') console.log(p1.name, p1.age) console.log(p1 instanceof Person) function Student(name, price) { this.name = name this.price = price } var s = new Student('Bob', 13000) console.log(s instanceof Student) var p2 = new Person('JACK', 23) console.log(p1, p2) </script>
Ⅴ-构造函数+原型的组合模式
方式六: 构造函数+原型的组合模式-->
最好用这个写法
- 套路: 自定义构造函数, 属性在函数中初始化, 方法添加到原型上
- 适用场景: 需要
创建多个类型确定的对象- 放在原型上可以节省空间(只需要加载一遍方法)
<script type="text/javascript"> //在构造函数中只初始化一般函数 function Person(name, age) { this.name = name this.age = age } Person.prototype.setName = function (name) { this.name = name } var p1 = new Person('Tom', 23) var p2 = new Person('Jack', 24) console.log(p1, p2) </script>
2、继承模式
Ⅰ-原型链继承
方式1: 原型链继承
1. 套路 - 定义父类型构造函数 - 给父类型的原型添加方法 - 定义子类型的构造函数 - 创建父类型的对象赋值给子类型的原型 - `将子类型原型的构造属性设置为子类型`-->此处有疑惑的可以看本笔记[函数高级部分的1、原型与原型链](#1、原型与原型链) - 给子类型原型添加方法 - 创建子类型的对象: 可以调用父类型的方法 2. 关键 - `子类型的原型为父类型的一个实例对象`<script type="text/javascript"> //父类型 function Supper() { this.supProp = '父亲的原型链' } //给父类型的原型上增加一个[showSupperProp]方法,打印自身subProp Supper.prototype.showSupperProp = function () { console.log(this.supProp) } //子类型 function Sub() { this.subProp = '儿子的原型链' } // 子类型的原型为父类型的一个实例对象 Sub.prototype = new Supper() // 让子类型的原型的constructor指向子类型 // 如果不加,其构造函数找的[`new Supper()`]是从顶层Object继承来的构造函数,指向[`Supper()`] Sub.prototype.constructor = Sub //给子类型的原型上增加一个[showSubProp]方法,打印自身subProp Sub.prototype.showSubProp = function () { console.log(this.subProp) } var sub = new Sub() sub.showSupperProp() //父亲的原型链 sub.showSubProp() //儿子的原型链 console.log(sub) /** Sub {subProp: "儿子的原型链"} subProp: "儿子的原型链" __proto__: Supper constructor: ƒ Sub() showSubProp: ƒ () supProp: "父亲的原型链" __proto__: Object */ </script>
① 示例图
注意:此图中没有体现[constructor构造函数],会在下方构造函数补充处指出
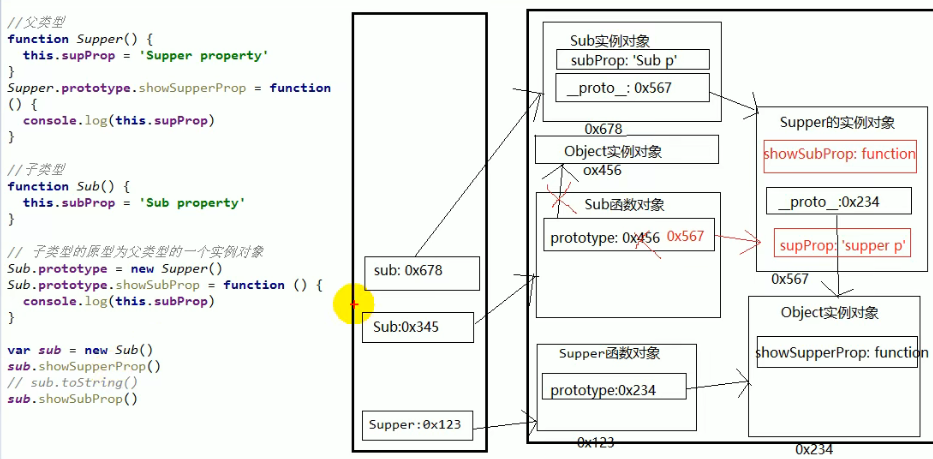
② 构造函数补充
对于代码中[
Sub.prototype.constructor = Sub]是否有疑惑?如果不加,其构造函数找的[
new Supper()]是从顶层Object继承来的构造函数,指向[Supper()],虽然如果你不加这句话,大体上使用是不受影响的,但是你有一个属性指向是错误的,如果在大型项目中万一万一哪里再调用到了呢?
- 这里可以补充一下constructor 的概念:
constructor 我们称为构造函数,因为它指回构造函数本身- 其作用是让某个构造函数产生的 所有实例对象(比如f) 能够找到他的构造函数(比如Fun),用法就是f.constructor
- 此时实例对象里没有constructor 这个属性,于是沿着原型链往上找到Fun.prototype 里的constructor,并指向Fun 函数本身
- constructor本就存在于原型中,指向构造函数,成为子对象后,如果该原型链中的constructor在自身没有而是在父原型中找到,所以指向父类的构造函数
- 由于这里的继承是直接改了构造函数的prototype 的指向,所以在 sub的原型链中,Sub.prototype 没有constructor 属性,反而是指向了一个super 实例
- 这就让sub 实例的constructor 无法使用了。为了他还能用,就在那个super 实例中手动加了一个constructor 属性,且指向Sub 函数
Ⅱ-借用构造函数继承(假的)
方式2: 借用构造函数继承(假的)
- 套路:
- 定义父类型构造函数
- 定义子类型构造函数
- 在子类型构造函数中调用父类型构造
- 关键:
在子类型构造函数中通用call()调用父类型构造函数
- 作用:
- 能借用父类中的构造方法,但是不灵活
function Person(name, age) { this.name = name this.age = age } function Student(name, age, price) { //此处利用call(),将 [Student]的this传递给Person构造函数 Person.call(this, name, age) // 相当于: this.Person(name, age) /*this.name = name this.age = age*/ this.price = price } var s = new Student('Tom', 20, 14000) console.log(s.name, s.age, s.price)[
Person]中的this是动态变化的,在[Student]中利用[Person.call(this, name, age)]改变了其this指向,所以可以实现此效果
Ⅲ-组合继承
方式3: 原型链+借用构造函数的组合继承
- 利用原型链实现对父类型对象的方法继承
- 利用call()借用父类型构建函数初始化相同属性
<script type="text/javascript"> function Person(name, age) { this.name = name this.age = age } Person.prototype.setName = function (name) { this.name = name } function Student(name, age, price) { Person.call(this, name, age) // 为了得到属性 this.price = price } Student.prototype = new Person() // 为了能看到父类型的方法 Student.prototype.constructor = Student //修正constructor属性 Student.prototype.setPrice = function (price) { this.price = price } var s = new Student('Tom', 24, 15000) s.setName('Bob') s.setPrice(16000) console.log(s.name, s.age, s.price) </script>
四、线程机制与事件机制
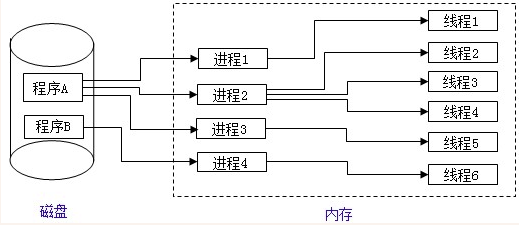
1、进程与线程
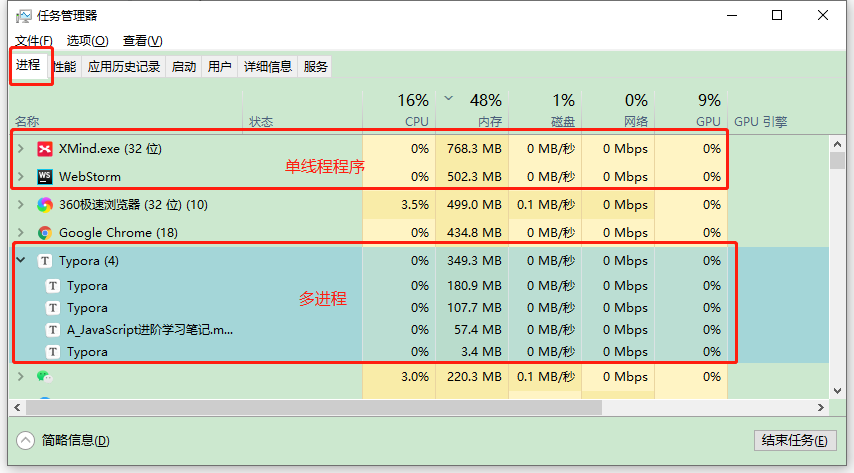
Ⅰ- 进程
- 程序的一次执行,它
占有一片独有的内存空间- 可以通过windows任务管理器查看进程
- 可以看出每个程序的内存空间是相互独立的
Ⅱ-线程
概念:
- 是进程内的一个独立执行单元
- 是程序执行的一个完整流程
- 是CPU的最小的调度单元
Ⅲ-进程与线程
- 应用程序必须运行在某个进程的某个线程上
- 一个进程中至少有一个运行的线程:主线程 -->进程启动后自动创建
- 一个进程中也可以同时运行多个线程:此时我们会说这个程序是多线程运行的
- 多个进程之间的数据是不能直接共享的 -->内存相互独立(隔离)
线程池(thread pool):保存多个线程对象的容器,实现线程对象的反复利用
Ⅳ-引出的问题
① 何为多进程与多线程?
多进程运行: 一应用程序可以同时启动多个实例运行
多线程: 在一个进程内, 同时有多个线程运行
②比较单线程与多线程?
多线程:
- 优点:能有效提升CPU的利用率
- 缺点
- 创建多线程开销
- 线程间切换开销
- 死锁与状态同步问题
单线程:
- 优点:顺序编程简单易懂
- 缺点:效率低
③ JS是单线程还是多线程?
JS是单线程运行的 , 但使用H5中的 Web Workers可以多线程运行
- 只能由一个线程去操作DOM界面
- 具体原因可看下方3、JS是单线程的部分给出的详解
④ 浏览器运行是单线程还是多线程?
都是多线程运行的
⑤ 浏览器运行是单进程还是多进程?
有的是单进程:
- firefox
- 老版IE
有的是多进程:
- chrome
- 新版IE
如何查看浏览器是否是多进程运行的呢? 任务管理器-->进程
2、浏览器内核
支撑浏览器运行的最核心的程序
Ⅰ-不同浏览器的内核
- Chrome, Safari : webkit
- firefox : Gecko
- IE : Trident
- 360,搜狗等国内浏览器: Trident + webkit
Ⅱ-内核由什么模块组成?
主线程
- js引擎模块 : 负责js程序的编译与运行
- html,css文档解析模块 : 负责页面文本的解析(拆解)
- dom/css模块 : 负责dom/css在内存中的相关处理
- 布局和渲染模块 : 负责页面的布局和效果的绘制
分线程
- 定时器模块 : 负责定时器的管理
- 网络请求模块 : 负责服务器请求(常规/Ajax)
- 事件响应模块 : 负责事件的管理
图例

3、定时器引发的思考
<body> <button id="btn">启动定时器</button> <script type="text/javascript"> document.getElementById('btn').onclick = function () { var start = Date.now() console.log('启动定时器前...') setTimeout(function () { console.log('定时器执行了', Date.now() - start) //定时器并不能保证真正定时执行,一般会延迟一丁点 }, 200) console.log('启动定时器后...') // 做一个长时间的工作 for (var i = 0; i < 1000000000; i++) { //会造成定时器延长很长时间 ... } } </script> </body>
Ⅰ-定时器真是定时执行的吗?
- 定时器并不能保证真正定时执行
- 一般会延迟一丁点(可以接受), 也有可能延迟很长时间(不能接受)
Ⅱ-定时器回调函数是在分线程执行的吗?
在主线程执行的, JS是单线程的
Ⅲ-定时器是如何实现的?
事件循环模型,在下方给出详解
3、JS是单线程的
Ⅰ-如何证明JS执行是单线程的
setTimeout()的回调函数是在主线程执行的- 定时器回调函数只有在运行栈中的代码全部执行完后才有可能执行
// 如何证明JS执行是单线程的 setTimeout(function () { //4. 在将[timeout 1111]弹窗关闭后,再等一秒 执行此处 console.log('timeout 2222') alert('22222222') }, 2000) setTimeout(function () { //3. 过了一秒后 打印 timeout 1111并弹窗,此处如果不将弹窗关闭,不会继续执行上方222 console.log('timeout 1111') alert('1111111') }, 1000) setTimeout(function () { //2. 然后打印timeout() 00000 console.log('timeout() 00000') }, 0) function fn() { //1. fn() console.log('fn()') } fn() //---------------------- console.log('alert()之前') alert('------') //暂停当前主线程的执行, 同时暂停计时, 点击确定后, 恢复程序执行和计时 console.log('alert()之后')流程结果:
- 先打印了[
fn()],然后马上就打印了[timeout() 00000]- 过了一秒后 打印 timeout 1111并弹窗,此处如果不将弹窗关闭,不会继续执行上方222
- 在将[timeout 1111]弹窗关闭后,
再等一秒执行此处
- 问:为何明明写的是2秒,却关闭上一个弹窗再过一秒就执行?
- 解:并不是关闭后再计算的,而是一起计算的,alert只是暂停了主线程执行
Ⅱ-JS引擎执行代码的基本流程与代码分类
代码分类:
- 初始化代码
- 回调代码
js引擎执行代码的基本流程
- 先执行初始化代码: 包含一些特别的代码 回调函数(异步执行)
- 设置定时器
- 绑定事件监听
- 发送ajax请求
- 后面在某个时刻才会执行回调代码
Ⅲ-为什么js要用单线程模式, 而不用多线程模式?
- JavaScript的单线程,与它的用途有关。
- 作为浏览器脚本语言,JavaScript的主要用途是与用户互动,以及操作DOM。
- 这决定了它只能是单线程,否则会带来很复杂的同步问题
4、事件循环模型(Event Loop)机制
Ⅰ-概念引出
我们都知道,
javascript从诞生之日起就是一门单线程的非阻塞的脚本语言。这是由其最初的用途来决定的:与浏览器交互。单线程意味着,javascript代码在执行的任何时候,都只有一个主线程来处理所有的任务。
非阻塞:而非阻塞则是当代码需要进行一项异步任务(无法立刻返回结果,需要花一定时间才能返回的任务,如I/O事件)的时候,主线程会挂起(pending)这个任务,然后在异步任务返回结果的时候再根据一定规则去执行相应的回调。
单线程是必要的:也是javascript这门语言的基石,原因之一在其最初也是最主要的执行环境——浏览器中,我们需要进行各种各样的dom操作。试想一下 如果javascript是多线程的,那么当两个线程同时对dom进行一项操作,例如一个向其添加事件,而另一个删除了这个dom,此时该如何处理呢?因此,为了保证不会 发生类似于这个例子中的情景,javascript选择只用一个主线程来执行代码,这样就保证了程序执行的一致性。
当然,现如今人们也意识到,单线程在保证了执行顺序的同时也限制了javascript的效率,因此开发出了
web workers技术。这项技术号称可以让javaScript成为一门多线程语言。然而,使用web workers技术开的多线程有着诸多限制,例如:
所有新线程都受主线程的完全控制,不能独立执行。这意味着这些“线程” 实际上应属于主线程的子线程。另外,这些子线程并没有执行I/O操作的权限,只能为主线程分担一些诸如计算等任务。所以严格来讲这些线程并没有完整的功能,也因此这项技术并非改变了javascript语言的单线程本质。可以预见,未来的javascript也会一直是一门单线程的语言。
话说回来,前面提到javascript的另一个特点是“
非阻塞”,那么javascript引擎到底是如何实现的这一点呢?答案就是——event loop(事件循环)。
注:
虽然nodejs中的也存在与传统浏览器环境下的相似的事件循环。然而两者间却有着诸多不同,故把两者分开,单独解释。
Ⅱ-浏览器环境下JS引擎的事件循环机制
<!--
1. 所有代码分类
* 初始化执行代码(同步代码): 包含绑定dom事件监听, 设置定时器, 发送ajax请求的代码
* 回调执行代码(异步代码): 处理回调逻辑
2. js引擎执行代码的基本流程:
* 初始化代码===>回调代码
3. 模型的2个重要组成部分:
* 事件(定时器/DOM事件/Ajax)管理模块
* 回调队列
4. 模型的运转流程
* 执行初始化代码, 将事件回调函数交给对应模块管理
* 当事件发生时, 管理模块会将回调函数及其数据添加到回调列队中
* 只有当初始化代码执行完后(可能要一定时间), 才会遍历读取回调队列中的回调函数执行
-->
① 执行栈概念
执行上下文栈详情可以看上方笔记 -->函数高级的2、执行上下文与执行上下文栈,此处继续进行一次概述加深理解
当javascript代码执行的时候会将不同的变量存于内存中的不同位置:
堆(heap)和栈(stack)中来加以区分。其中,堆里存放着一些对象。而栈中则存放着一些基础类型变量以及对象的指针。但是我们这里说的执行栈和上面这个栈的意义却有些不同。
执行栈:当我们调用一个方法的时候,js会生成一个与这个方法对应的执行环境(context),又叫
执行上下文。这个执行环境中存在着这个方法的私有作用域、上层作用域的指向、方法的参数,这个作用域中定义的变量以及这个作用域的this对象。 而当一系列方法被依次调用的时候,因为js是单线程的,同一时间只能执行一个方法,于是这些方法被排队在一个单独的地方。这个地方被称为执行栈。当一个脚本第一次执行的时候,js引擎会解析这段代码,并将其中的同步代码按照执行顺序加入执行栈中,然后从头开始执行。如果当前执行的是一个方法,那么js会向执行栈中添加这个方法的执行环境,然后进入这个执行环境继续执行其中的代码。
当这个执行环境中的代码 执行完毕并返回结果后,js会退出这个执行环境并把这个执行环境销毁,回到上一个方法的执行环境。这个过程反复进行,直到执行栈中的代码全部执行完毕。此处继续拿出栈图加深理解:
从图片可知,一个方法执行会向执行栈中加入这个方法的执行环境,在这个执行环境中还可以调用其他方法,甚至是自己,其结果不过是在执行栈中再添加一个执行环境。这个过程可以是无限进行下去的,
除非发生了栈溢出,即超过了所能使用内存的最大值。以上的过程说的都是同步代码的执行。那么当一个异步代码(如发送ajax请求数据)执行后会如何呢?
刚刚说过js的另一大特点是非阻塞,实现这一点的关键在于下面要说的这项机制——
事件队列(Task Queue)。

② 事件队列(Task Queue)
JS引擎遇到一个异步事件后并不会一直等待其返回结果,而是会将这个事件挂起,继续执行执行栈中的其他任务,当一个异步事件返回结果后,js会将这个事件加入与当前执行栈不同的另一个队列,我们称之为
事件队列。被放入事件队列不会立刻执行其回调,而是
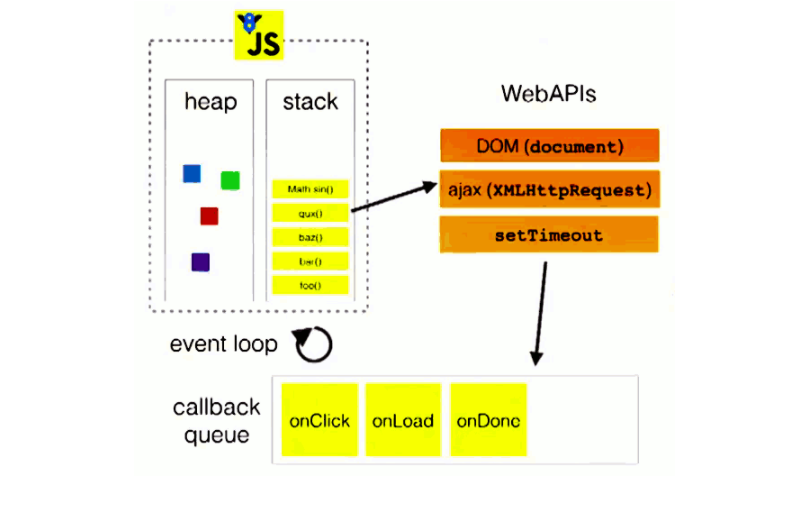
等待当前执行栈中的所有任务都执行完毕, 主线程处于闲置状态时,主线程会去查找事件队列是否有任务。如果有,那么主线程会从中取出排在第一位的事件,并把这个事件对应的回调放入执行栈中,然后执行其中的同步代码...,如此反复,这样就形成了一个无限的循环。这个过程被称为“事件循环(Event Loop)”的原因。这里还有一张图来展示这个过程:
图中的stack表示我们所说的执行栈,web apis则是代表一些异步事件,而callback queue即事件队列。
以上的事件循环过程是一个宏观的表述,实际上因为异步任务之间并不相同,因此他们的执行优先级也有区别。
不同的异步任务被分为两类:微任务(micro task)和宏任务(macro task),此部分看下方详解
Ⅲ-宏任务(macro task)与微任务(micro task)
宏任务与微任务亦属于Ⅱ-浏览器环境下JS引擎的事件循环机制内知识点,但本人觉得比较重要,将其提高至重要知识点
① 宏任务队列与微任务队列解释
顾名思义,宏任务放至宏任务队列(
简称宏队列)中、微任务放至微任务队列(简称微队列)中
- JS中用来存储待执行回调函数的队列包含2个不同特定的列队
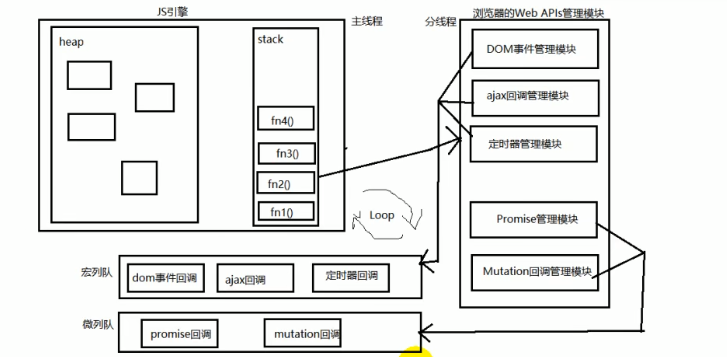
宏队列:用来保存待执行的宏任务(回调),比如:定时器回调/ajax回调/dom事件回调微队列:用来保存待执行的微任务(回调),比如:Promise的回调/muntation回调
- JS执行时会区别这2个队列:
- JS执行引擎首先必须执行所有的
初始化同步任务代码- 每次准备取出第一个
宏任务执行前,都要将所有的微任务一个一个取出来执行前面我们介绍过,在一个事件循环中,异步事件返回结果后会被放到一个任务队列中。然而,根据这个异步事件的类型,这个事件实际上会被放到对应的宏任务队列或者微任务队列中去。并且在当前执行栈为空的时候,主线程会 查看微任务队列是否有事件存在。如果不存在,那么再去宏任务队列中取出一个事件并把对应的回调函数到加入当前执行栈;如果存在,则会依次执行队列中事件对应的回调,直到微任务队列为空,然后去宏任务队列中取出最前面的一个事件,把对应的回调加入当前执行栈...如此反复,进入循环。
我们只需记住:**
当前执行栈执行完毕时会立刻先处理所有微任务队列中的事件,然后再去宏任务队列中取出一个事件。同一次事件循环中,微任务永远在宏任务之前执行**
② 原理图
③ 由代码逆向理解宏任务与微任务
代码示例
setTimeout(() => { console.log('timeout callback1()')//立即放入宏队列 Promise.resolve(3).then( value => { console.log('Promise onResolved3()', value)//当这个宏任务执行后 立马放入微队列,所以这个微任务执行完后下个宏任务才能执行 } ) }, 0) setTimeout(() => { console.log('timeout callback2()') //立即放入宏队列, }, 0) Promise.resolve(1).then( value => { console.log('Promise onResolved1()', value)//立即放入微队列 setTimeout(() => { console.log('timeout callback3()', value) //立即放入宏任务 }, 0) } ) Promise.resolve(2).then( value => { console.log('Promise onResolved2()', value)//立即放入微队列 } ) console.log('同步代码') //同步代码立即执行结果
'同步代码', 'Promise onResolved1()', 'Promise onResolved2()', 'timeout callback1()', 'Promise onResolved3()', 'timeout callback2()', 'timeout callback3()'
Ⅳ-node环境下的事件循环机制
不学node的小伙伴就跳过此部分直接去下一节Web Workers笔记吧
① 与浏览器环境有何不同?
在node中,事件循环表现出的状态与浏览器中大致相同。不同的是node中有一套自己的模型。node中事件循环的实现是依靠的libuv引擎。我们知道node选择chrome v8引擎作为js解释器,v8引擎将js代码分析后去调用对应的node api,而这些api最后则由libuv引擎驱动,执行对应的任务,并把不同的事件放在不同的队列中等待主线程执行。
因此实际上node中的事件循环存在于libuv引擎中。
② 事件循环模型
下面是一个libuv引擎中的事件循环的模型:
//libuv引擎中的事件循环的模型 ┌───────────────────────┐ ┌─>│ timers │ │ └──────────┬────────────┘ │ ┌──────────┴────────────┐ │ │ I/O callbacks │ │ └──────────┬────────────┘ │ ┌──────────┴────────────┐ │ │ idle, prepare │ │ └──────────┬────────────┘ ┌───────────────┐ │ ┌──────────┴────────────┐ │ incoming: │ │ │ poll │<──connections─── │ │ └──────────┬────────────┘ │ data, etc. │ │ ┌──────────┴────────────┐ └───────────────┘ │ │ check │ │ └──────────┬────────────┘ │ ┌──────────┴────────────┐ └──┤ close callbacks │ └───────────────────────┘注:模型中的每一个方块代表事件循环的一个阶段
这个模型是node官网上的一篇文章中给出的,我下面的解释也都来源于这篇文章。我会在文末把文章地址贴出来,有兴趣的朋友可以亲自与看看原文。
③ 事件循环各阶段详解
从上面这个模型中,我们可以大致分析出node中的事件循环的顺序:
外部输入数据-->轮询阶段(poll)-->检查阶段(check)-->关闭事件回调阶段(close callback)-->定时器检测阶段(timer)-->I/O事件回调阶段(I/O callbacks)-->闲置阶段(idle, prepare)-->轮询阶段...
这些阶段大致的功能如下:
- timers(定时器检测阶段): 这个阶段执行定时器队列中的回调如
setTimeout()和setInterval()。- I/O callbacks(I/O事件回调阶段): 这个阶段执行几乎所有的回调。但是不包括close事件,定时器和
setImmediate()的回调。- idle, prepare: 这个阶段仅在内部使用,可以不必理会。
- poll(轮询阶段): 等待新的I/O事件,node在一些特殊情况下会阻塞在这里。
- check(检查阶段):
setImmediate()的回调会在这个阶段执行。- close callbacks(关闭事件回调阶段): 例如
socket.on('close', ...)这种close事件的回调。下面我们来按照代码第一次进入libuv引擎后的顺序来详细解说这些阶段:
poll(轮询阶段)
当一个v8引擎将js代码解析后传入libuv引擎后,循环首先进入poll阶段。poll阶段的执行逻辑如下: 先查看poll queue中是否有事件,有任务就按先进先出的顺序依次执行回调。 当queue为空时,会检查是否有setImmediate()的callback,如果有就进入check阶段执行这些callback。但同时也会检查是否有到期的timer,如果有,就把这些到期的timer的callback按照调用顺序放到timer queue中,之后循环会进入timer阶段执行queue中的 callback。 这两者的顺序是不固定的,受到代码运行的环境的影响。如果两者的queue都是空的,那么loop会在poll阶段停留,直到有一个i/o事件返回,循环会进入i/o callback阶段并立即执行这个事件的callback。
值得注意的是,poll阶段在执行poll queue中的回调时实际上不会无限的执行下去。
有两种情况poll阶段会终止执行poll queue中的下一个回调:1.所有回调执行完毕。2.执行数超过了node的限制。
check(检查阶段)
check阶段专门用来执行
setImmediate()方法的回调,当poll阶段进入空闲状态,并且setImmediate queue中有callback时,事件循环进入这个阶段。
close callbacks(关闭事件回调阶段)
当一个socket连接或者一个handle被突然关闭时(例如调用了
socket.destroy()方法),close事件会被发送到这个阶段执行回调。否则事件会用process.nextTick()方法发送出去。
timers(定时器检测阶段)
这个阶段以先进先出的方式执行所有到期的timer加入timer队列里的callback,一个timer callback指得是一个通过setTimeout或者setInterval函数设置的回调函数。
I/O callbacks(I/O事件回调阶段)
如上文所言,这个阶段主要执行大部分I/O事件的回调,包括一些为操作系统执行的回调。例如一个TCP连接生错误时,系统需要执行回调来获得这个错误的报告。
④ process.nextTick,setTimeout与setImmediate的区别与使用场景
在node中有三个常用的用来推迟任务执行的方法:process.nextTick,setTimeout(setInterval与之相同)与setImmediate
这三者间存在着一些非常不同的区别:
process.nextTick()
尽管没有提及,但是实际上node中存在着一个特殊的队列,即nextTick queue。这个队列中的回调执行虽然没有被表示为一个阶段,当时这些事件却会在每一个阶段执行完毕准备进入下一个阶段时优先执行。当事件循环准备进入下一个阶段之前,会先检查nextTick queue中是否有任务,如果有,那么会先清空这个队列。与执行poll queue中的任务不同的是,这个操作在队列清空前是不会停止的。这也就意味着,错误的使用
process.nextTick()方法会导致node进入一个死循环。。直到内存泄漏。使用这个方法比较合适呢?下面有一个例子:
const server = net.createServer(() => {}).listen(8080); server.on('listening', () => {});这个例子中当,当listen方法被调用时,除非端口被占用,否则会立刻绑定在对应的端口上。这意味着此时这个端口可以立刻触发listening事件并执行其回调。然而,这时候
on('listening)还没有将callback设置好,自然没有callback可以执行。为了避免出现这种情况,node会在listen事件中使用process.nextTick()方法,确保事件在回调函数绑定后被触发。
setTimeout()和setImmediate()
在三个方法中,这两个方法最容易被弄混。实际上,某些情况下这两个方法的表现也非常相似。然而实际上,这两个方法的意义却大为不同。
setTimeout()方法是定义一个回调,并且希望这个回调在我们所指定的时间间隔后第一时间去执行。注意这个“第一时间执行”,这意味着,受到操作系统和当前执行任务的诸多影响,该回调并不会在我们预期的时间间隔后精准的执行。执行的时间存在一定的延迟和误差,这是不可避免的。node会在可以执行timer回调的第一时间去执行你所设定的任务。
setImmediate()方法从意义上将是立刻执行的意思,但是实际上它却是在一个固定的阶段才会执行回调,即poll阶段之后。有趣的是,这个名字的意义和之前提到过的process.nextTick()方法才是最匹配的。node的开发者们也清楚这两个方法的命名上存在一定的混淆,他们表示不会把这两个方法的名字调换过来---因为有大量的node程序使用着这两个方法,调换命名所带来的好处与它的影响相比不值一提。
setTimeout()和不设置时间间隔的setImmediate()表现上及其相似。猜猜下面这段代码的结果是什么?setTimeout(() => { console.log('timeout'); }, 0); setImmediate(() => { console.log('immediate'); });实际上,答案是不一定。没错,就连node的开发者都无法准确的判断这两者的顺序谁前谁后。这取决于这段代码的运行环境。运行环境中的各种复杂的情况会导致在同步队列里两个方法的顺序随机决定。但是,在一种情况下可以准确判断两个方法回调的执行顺序,那就是在一个I/O事件的回调中。下面这段代码的顺序永远是固定的:
<script type="text/javascript"> const fs = require('fs'); fs.readFile(__filename, () => { setTimeout(() => { console.log('timeout'); }, 0); setImmediate(() => { console.log('immediate'); }); }); </script>答案永远是:
immediate timeout因为在I/O事件的回调中,setImmediate方法的回调永远在timer的回调前执行。
5、Web Workers
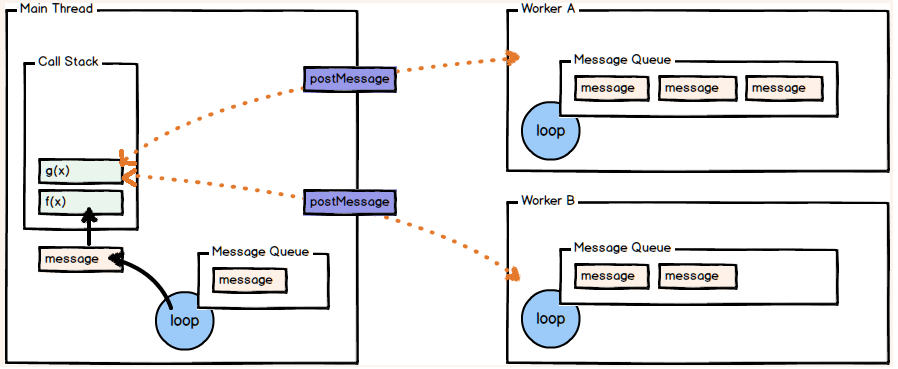
想了解更多可以点击链接查看更多,此处只是大致了解学习 -->Web Workers
- H5规范提供了js分线程的实现, 取名为: Web Workers
- 相关API
- Worker: 构造函数, 加载分线程执行的js文件
- Worker.prototype.onmessage: 用于接收另一个线程的回调函数
- Worker.prototype.postMessage: 向另一个线程发送消息
- 不足
- worker内代码不能操作DOM(更新UI)
- 不能跨域加载JS
- 不是每个浏览器都支持这个新特性
Ⅰ-抛砖引玉,引出用处
还是拿斐波那契(Fibonacci)数列来做例子,这东西效率低,可以拿来模拟
<script type="text/javascript"> // 1 1 2 3 5 8 f(n) = f(n-1) + f(n-2) function fibonacci(n) { return n <= 2 ? 1 : fibonacci(n - 1) + fibonacci(n - 2) //递归调用 } // console.log(fibonacci(7)) var input = document.getElementById('number') document.getElementById('btn').onclick = function () { var number = input.value var result = fibonacci(number) alert(result) } </script>当我运行此行代码,传入计算数值为50左右(有的甚至更低),整个页面就会卡住好久的时间不能操作(计算结束后才会弹窗,但是未弹窗的这段时间用户并不能进行操作),这时候就会发现单线程的弊端了
Ⅱ-尝试使用
- H5规范提供了js分线程的实现, 取名为: Web Workers
- 相关API
- Worker: 构造函数, 加载分线程执行的js文件
- Worker.prototype.onmessage: 用于接收另一个线程的回调函数
- Worker.prototype.postMessage: 向另一个线程发送消息
- 不足
- worker内代码不能操作DOM(更新UI)
- 不能跨域加载JS
- 不是每个浏览器都支持这个新特性
① 主线程
- 创建一个Worker对象
- 绑定[主线程接收分线程返回的数据]方法
- 主线程向分线程发送数据,然后等待接受数据
- 接收到分线程回馈的数据,将数据进行处理(如弹窗)
<body> <input type="text" placeholder="数值" id="number"> <button id="btn">计算</button> <script type="text/javascript"> var input = document.getElementById('number') document.getElementById('btn').onclick = function () { var number = input.value //创建一个Worker对象 var worker = new Worker('worker.js') // 绑定接收消息的监听 worker.onmessage = function (event) { //此处变成回调代码,会在初始化工作完成后才会进行 console.log('主线程接收分线程返回的数据: '+event.data) alert(event.data) } // 向分线程发送消息 worker.postMessage(number) console.log('主线程向分线程发送数据: '+number) } // console.log(this) // window </script> </body>
② 分线程
将计算放置分线程中
注意:alert(result) ----> alert是window的方法, 在分线程不能调用,分线程中的全局对象不再是window, 所以在分线程中不可能更新界面<script type="text/javascript"> //worker.js function fibonacci(n) { return n <= 2 ? 1 : fibonacci(n - 1) + fibonacci(n - 2) //递归调用 } console.log(this) this.onmessage = function (event) { var number = event.data console.log('分线程接收到主线程发送的数据: ' + number) //计算 var result = fibonacci(number) postMessage(result) console.log('分线程向主线程返回数据: ' + result) // alert(result) alert是window的方法, 在分线程不能调用 // 分线程中的全局对象不再是window, 所以在分线程中不可能更新界面 } </script>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号