B站自动爬取器并制作词云
效果
词云展示

弹幕展示
爬取弹幕过程
基本步骤
1.寻找视频url
2.构造请求头
3.寻找弹幕地址
4.根据弹幕地址运用正则或xpath爬取
寻找B站视频的url
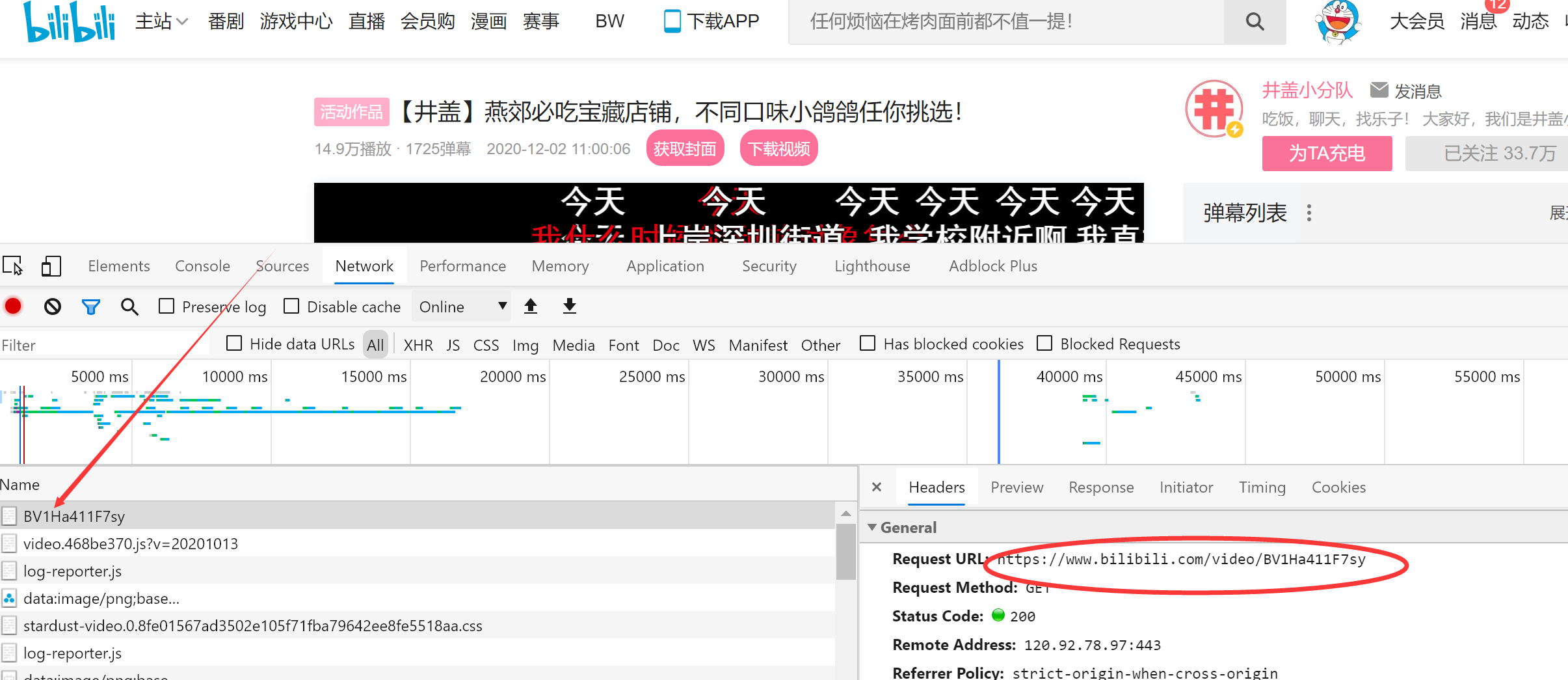
制作请求头
headers = {"User-Agent": "浏览器中的User-Agent"}
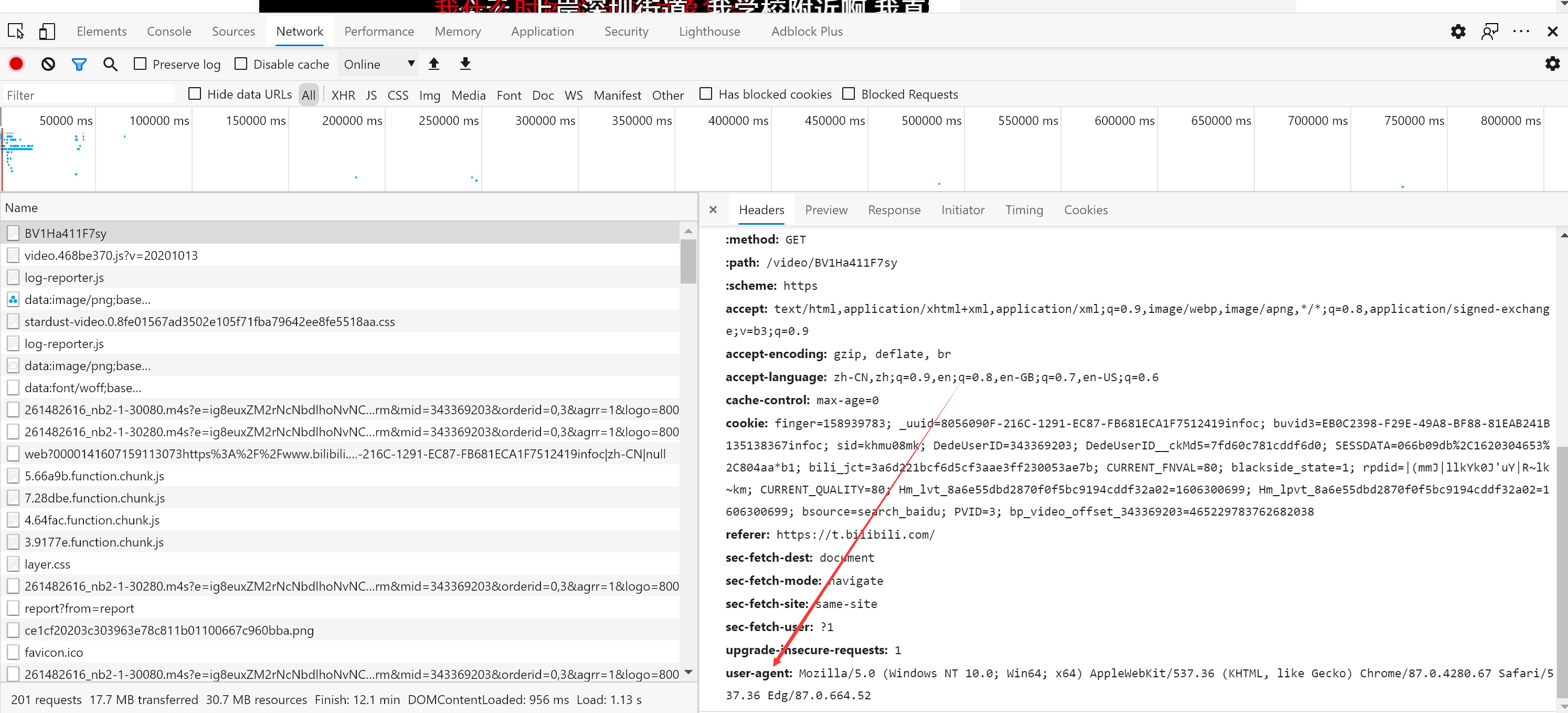
弹幕地址
1.代码通过这位博主改进的(https://www.cnblogs.com/wuren-best/p/12566297.html)
2.由于B站弹幕地址改变变得越来越难寻找到 但通过原来的弹幕地址改变下oid还是可以爬取到的
运用xpath爬取弹幕
弹幕包含在xml中的

html = etree.HTML(response.content)
word_list = html.xpath("//d/text()")
词云制作
fp = open("%s弹幕.text" % self.get_tile(), 'r', encoding='utf-8')
text = fp.read()
# 字体为.TTF格式的
wd = WordCloud(background_color='white', width=300, height=316, margin=2,
font_path='钟齐段宁行书.TTF').generate(text)
plt.figure(dpi=500)
# 显示词云
plt.imshow(wd)
# 去除x,y 轴
plt.axis('off')
plt.show()
# 保存词云
wd.to_file("%s弹幕.jpg" % self.get_tile())
完整代码
# coding=utf-8
import requests
from lxml import etree
import re
from wordcloud import WordCloud, STOPWORDS, ImageColorGenerator
import matplotlib.pyplot as plt
class BiliSpider:
def __init__(self, BV, oid):
# 构造要爬取的视频url地址
self.BVurlBV = BV
self.BVurloid = oid
self.BVurl = "https://m.bilibili.com/video/" + BV
self.headers = {
"User-Agent": "Mozilla/5.0 (Linux; Android 8.0; Pixel 2 Build/OPD3.170816.012) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Mobile Safari/537.36"}
# 弹幕都是在一个url请求中,该url请求在视频url的js脚本中构造
def getXml_url(self):
# 获取该视频网页的内容
response = requests.get(self.BVurl, headers=self.headers)
html_str = response.content.decode()
# 使用正则找出该弹幕地址
# 弹幕地址为https://comment.bilibili.com/oid.xml
# 格式为:https://comment.bilibili.com/168087953.xml
# 我们分隔出的是地址中的弹幕文件名,即 168087953
getWord_url = self.BVurloid
# 组装成要请求的xml地址
xml_url = "https://comment.bilibili.com/{}.xml".format(getWord_url)
return xml_url
# Xpath不能解析指明编码格式的字符串,所以此处我们不解码,还是二进制文本
def parse_url(self, url):
response = requests.get(url, headers=self.headers)
# print(response.content)
return response.content
# 弹幕包含在xml中的<d></d>中,取出即可
def get_word_list(self, str):
html = etree.HTML(str)
word_list = html.xpath("//d/text()")
return word_list
# 标题及up主名
def get_tile(self):
response = requests.get(self.BVurl, headers=self.headers)
# print(response.text)
html_str = response.content.decode()
html = etree.HTML(html_str)
up_name = html.xpath('//span/text()')[1]
up_tile = html.xpath('//h1/text()')[0]
tile = []
for i in up_name, up_tile:
tile.append(i)
# print(up_name)
# print(up_tile)
# print(tile)
return tile[0]+tile[1]
# BV1ZV411a7vy 261482616
# 保存弹幕为文本格式
def save_file(self, data):
"""
保存弹幕
:param data: 弹幕信息
:return:
"""
with open("%s弹幕.text" % self.get_tile(), 'w', encoding='utf8') as f:
for line in data:
f.write(line)
f.write('\n')
# 词云
def wardcloud_(self):
fp = open("%s弹幕.text" % self.get_tile(), 'r', encoding='utf-8')
text = fp.read()
wd = WordCloud(background_color='white', width=300, height=316, margin=2,
font_path='钟齐段宁行书.TTF').generate(text)
plt.figure(dpi=500)
# 显示词云
plt.imshow(wd)
# 去除x,y 轴
plt.axis('off')
plt.show()
# 保存词云
wd.to_file("%s弹幕.jpg" % self.get_tile())
def run(self):
# 1.根据BV号获取弹幕的地址
start_url = self.getXml_url()
# 2.请求并解析数据
xml_str = self.parse_url(start_url)
# print(start_url)
word_list = self.get_word_list(xml_str)
# 3.打印
for word in word_list:
print(word)
# 4.保存
self.save_file(word_list)
# 5.词云
self.wardcloud_()
if __name__ == '__main__':
BVName = input("请输入要爬取的视频的BV号:")
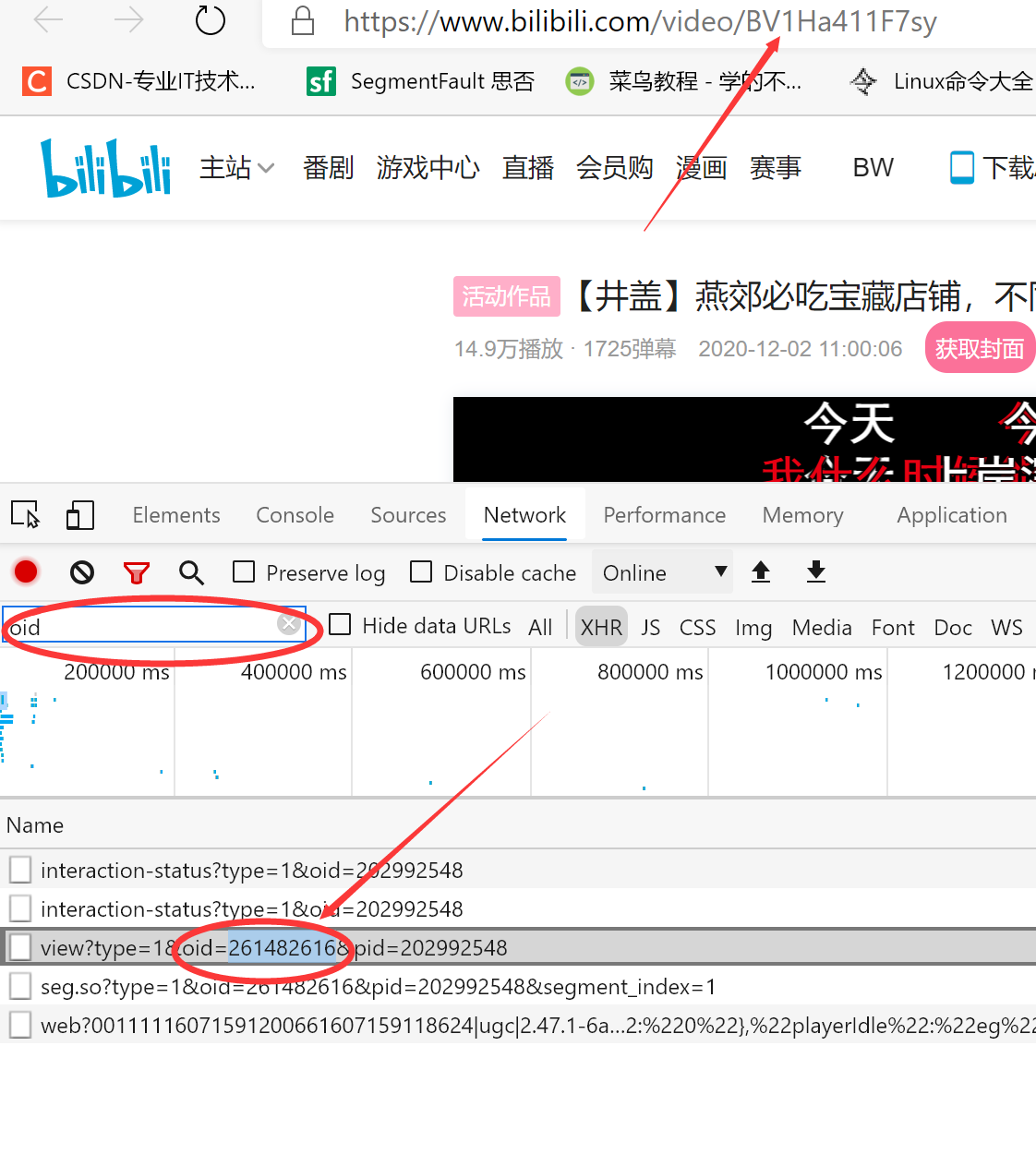
oid = input("请输入要爬取的视频的oid(F12中找oid)号:")
spider = BiliSpider(BVName, oid)
spider.run()
注:BV号和oid

 浙公网安备 33010602011771号
浙公网安备 33010602011771号