
webmagic 爬虫示例1
webmagic 中文官方文档
1.maven配置
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-core</artifactId>
<version>0.5.2</version>
</dependency>
<dependency>
<groupId>us.codecraft</groupId>
<artifactId>webmagic-extension</artifactId>
<version>0.5.2</version>
</dependency>
2.代码示例
import us.codecraft.webmagic.Page; import us.codecraft.webmagic.Request; import us.codecraft.webmagic.Site; import us.codecraft.webmagic.Spider; import us.codecraft.webmagic.pipeline.ConsolePipeline; import us.codecraft.webmagic.pipeline.FilePipeline; import us.codecraft.webmagic.processor.PageProcessor; import us.codecraft.webmagic.selector.Html; import java.io.FileNotFoundException; import java.io.FileOutputStream; import java.util.HashSet; import java.util.List; import org.jsoup.Jsoup; import org.jsoup.nodes.Document; import org.jsoup.nodes.Element; import org.jsoup.select.Elements; public class AniMusicProcessor implements PageProcessor {
//设置域名,重试次数,休眠时间 private Site site = Site.me().setDomain("chinacoat.net").setRetryTimes(3).setSleepTime(300); public void process(Page page) {
//获取href标签所有链接 List<String> links = page.getHtml().css("a.list_td_a ","href").all(); //加入请求队列中 page.addTargetRequests(links); if (page.getUrl().get().matches(".*list_ch01.asp.*")){ } else { //获取标签中内容 page.putField("html4", page.getHtml().xpath("//table[contains(@class, 'exh_info_table')]//tr[8]//td/text()|" + "//table[contains(@class, 'exh_info_table')]//tr[8]//td/p/text()|" + "//table[contains(@class, 'exh_info_table')]//tr[8]//td//div/text()|" + "table[contains(@class, 'exh_info_table')]//tr[8]//td//span/text()").nodes() ); page.putField("html3", page.getHtml().xpath("//table[contains(@class, 'exh_info_table')]//tbody//tr[1]//td[2]/text()").all()); } } public Site getSite() { return site; } public static void main(String[] args) { AniMusicProcessor an = new AniMusicProcessor(); Spider.create( an ).addUrl('')//此处填写url .addPipeline( new ConsolePipeline() ).run(); } }
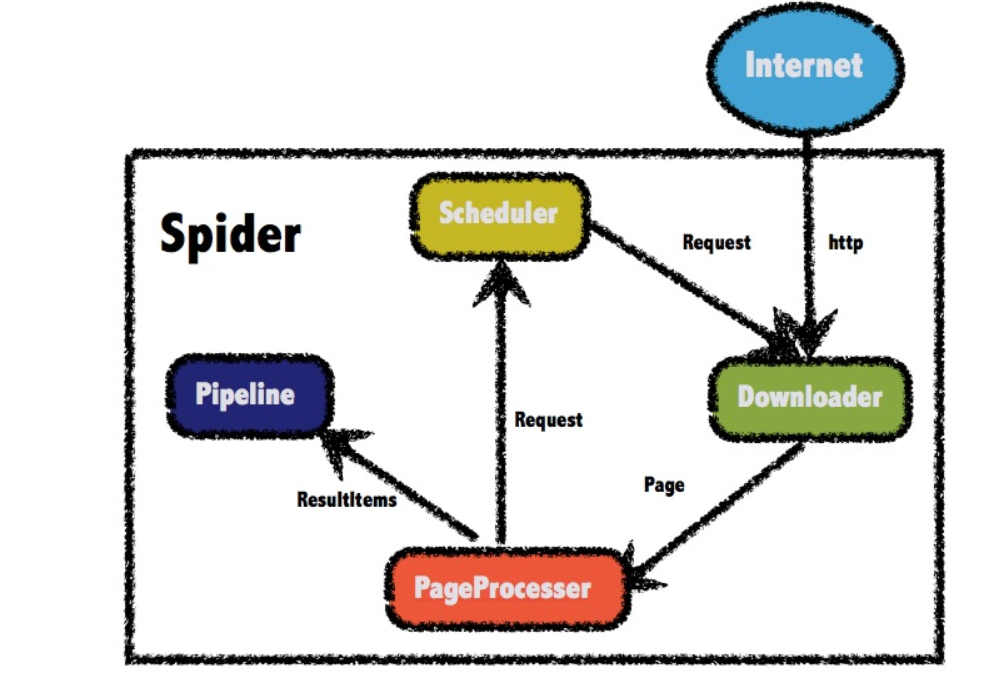
1.2.1 WebMagic的四个组件
1.Downloader
Downloader负责从互联网上下载页面,以便后续处理。WebMagic默认使用了Apache HttpClient作为下载工具。
2.PageProcessor
PageProcessor负责解析页面,抽取有用信息,以及发现新的链接。WebMagic使用Jsoup作为HTML解析工具,并基于其开发了解析XPath的工具Xsoup。
在这四个组件中,PageProcessor对于每个站点每个页面都不一样,是需要使用者定制的部分。
3.Scheduler
Scheduler负责管理待抓取的URL,以及一些去重的工作。WebMagic默认提供了JDK的内存队列来管理URL,并用集合来进行去重(一般使用布隆过滤器)。也支持使用Redis进行分布式管理。
除非项目有一些特殊的分布式需求,否则无需自己定制Scheduler。
4.Pipeline
Pipeline负责抽取结果的处理,包括计算、持久化到文件、数据库等。WebMagic默认提供了“输出到控制台”和“保存到文件”两种结果处理方案。
Pipeline定义了结果保存的方式,如果你要保存到指定数据库,则需要编写对应的Pipeline。对于一类需求一般只需编写一个Pipeline。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号