Dicom患者信息获取乱码分析
开发的软件在读取CT机的Dicom文件时,其中的患者信息出现乱码,产生原因是因为Dicom使用了默认的字符集,导致不能正常解析中文。
开发环境
Fo-Dicom
VS2022
.net6+
问题现象
开发的CT软件,从CT的Dicom文件中读取到的患者姓名、性别出现了乱码。
同时将此Dicom以RadiAnt打开,也是一样的问题。
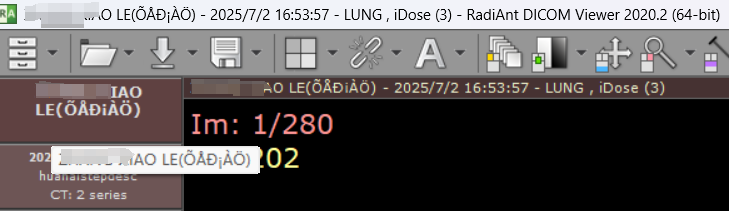
排查过程
开始怀疑是在扫描CT时出现了异常,导致Dicom的PatientName标签中汉字异常。但debug时尝试将PatientName以如下方式读取时:
var item = dicomDataset.GetDicomItem<DicomElement>(dicomTag); if (item == null) return string.Empty; byte[] bytes = item.Buffer.Data; string txt = Encoding.GetEncoding("GB18030").GetString(bytes).Trim('\0');
发现是能还获取到患者姓名的。于是怀疑是DICOM的字符集可能是有问题。看了Dicom中的Specific Character Set,确认此是有问题的。
原因分析
在 DICOM 文件中,Specific Character Set (0008,0005) 的值为 ISO_IR 100 时无法正常解析中文,是因为该字符集实际上是 Latin-1(ISO-8859-1),仅支持西欧语言字符,不包含中文字符。
以下为Dicom中Specific Character Set截图:

(1) ISO_IR 100 的本质
-
ISO_IR 100 是 DICOM 标准中定义的字符集标识符,对应 ISO-8859-1(Latin-1)。 - Latin-1 的局限性:
- 仅支持 256 个字符(0x00-0xFF),覆盖 西欧字母(如
ä,ñ,é),但不包含任何中文字符。 - 中文字符在 Latin-1 编码下会被解析为乱码(如
张三→ÕÅСÀÖ)。
- 仅支持 256 个字符(0x00-0xFF),覆盖 西欧字母(如
(2) DICOM 的字符集处理逻辑
- 当
Specific Character Set被声明为ISO_IR 100时,解析器会强制使用 Latin-1 解码所有字符串标签(如PatientName)。 - 如果实际数据是中文(如 GB18030/UTF-8 编码),则必然解析失败。
解决方案
(1) 修改 Specific Character Set 为中文编码
在写入或修改 DICOM 文件时,显式声明支持中文的字符集:
(2) 支持的 DICOM 中文编码标识符
| 字符集 | DICOM 标识符 | 适用范围 |
|---|---|---|
| GB18030 | "GB18030" |
中国国家标准(全覆盖) |
| GBK | "GBK" |
兼容 GB2312(较旧系统) |
| UTF-8 | "ISO_IR 192" |
国际通用(推荐) |
建议使用GB18030,其它字符集不能完全覆盖,一些人的人名中有生僻字的话又会出现乱码。
(3) 修复已存在的文件
若文件已错误写入 ISO_IR 100,需重新编码数据:
建议
在国内DICOM字符集建议使用GB18030,其它字符集不能完全覆盖,一些人的人名中有生僻字的话又会出现乱码。
*****有道无术,术尚可求;有术无道,止于术。*****

 浙公网安备 33010602011771号
浙公网安备 33010602011771号