
IP一致性论文
IP一致性:指的是给定输入的图像,要求保持图像中的ID不变,IP可能是Identity Property,要求能够识别出是同一个身份。
目前通过IP的一致性技术,可以用于短视频短剧上,是一个新兴的市场技术。
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Paper : https://papers.cool/arxiv/2308.06721
Page : https://ip-adapter.github.io/
类似于ControlNet,想要在已经预训练的网络中增加Adapter(类似于LLM中),从而维持IP一致性。
动机:目前如果在预训练中的网络中添加额外的信息,通常是直接和其他信息(Text)Concat在一起通过Cross-Layer,本文认为这样子会导致信息融合在一起,无法保证单一模态的信息强度,就容易导致IP变形。
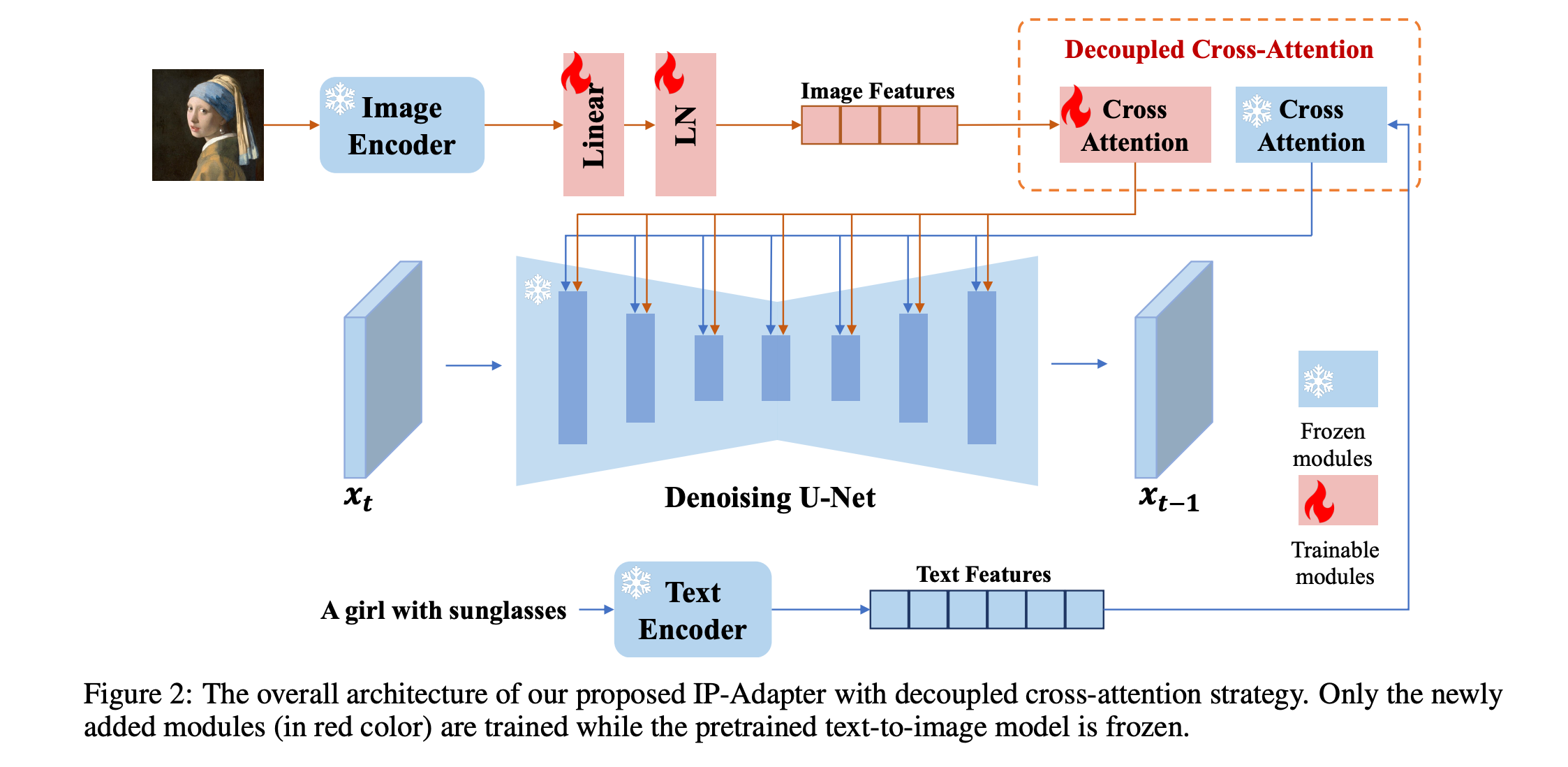
通过使用两个cross-attn,将不同模态的信息分离,但是在这两个cross-attn的Q数输入是一致的。具体公式如下
需要注意的是两个Cross-áttn的Query输入是一致的,而对于文本的cross-attn是完全冻结的。
DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
Project page: https://dreambooth.github.io/

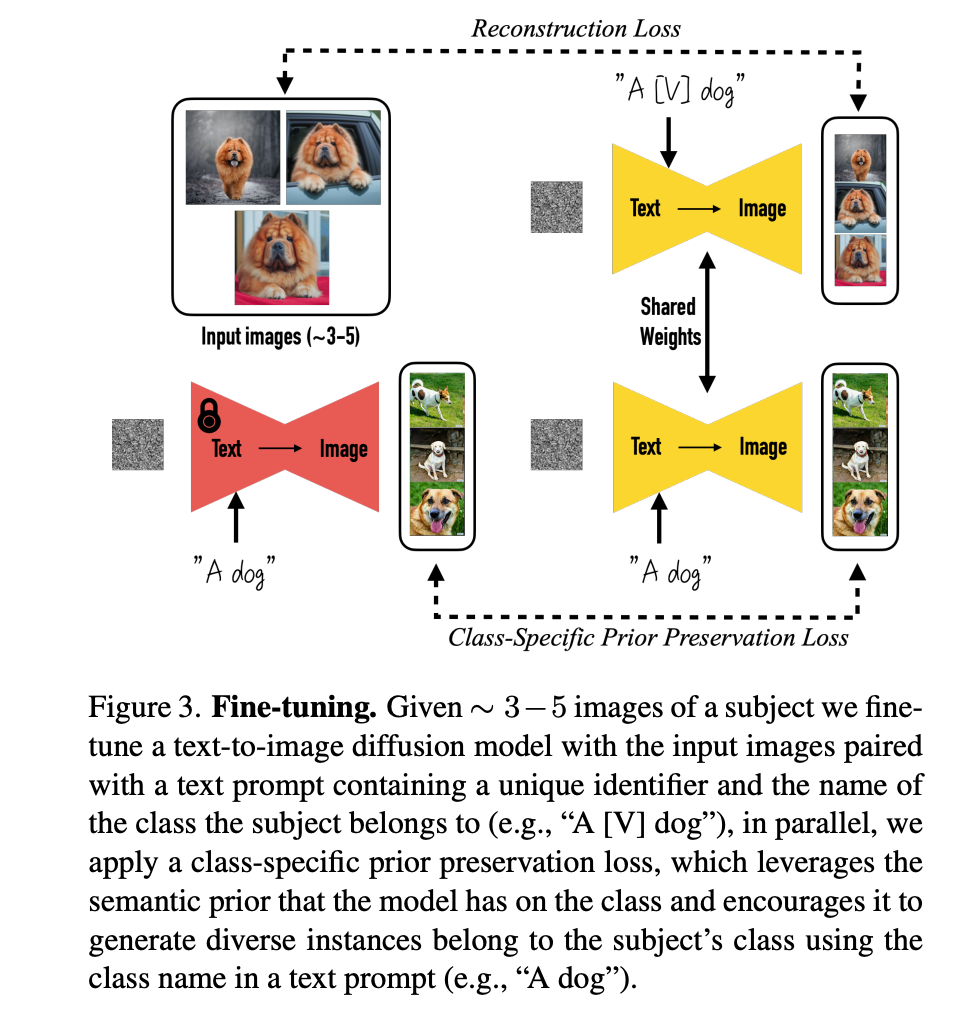
DreamBooth可以给定3~5张主体图像,微调预训练模型,生成主体类似的图像,它的核心思想通过微调模型,使得TextEncoder的某个特定token可以和模型生成的特定主体(Obeject)相联系,例如将Kitty和我家的狗联系起来,如果输入的prompt含有“Kitty”,那么模型生成的图像中,主体就是我家的狗。
Method:
- 如何设计训练数据。文本提示采用简单的结构,通常包含一个独特标识符和主体的类别名称。例如,"A [V] dog",其中"[V]"是独特标识符,"dog"是主体的类别名称。V实在 tokenizer寻找出现频数较少的。
- 为了防止模型在微调过程中逐渐忘记如何生成与目标主体相同类别的其他主体(即语言漂移),作者提出了一种类别特定先验保留损失(Class-specific Prior Preservation Loss)。先在一个类别中生成几张图像,要求模型在微调的时候,对于该类别生成尽量一致的图像,只有在输入特定的token的时候,才生成特定的主体。
-
微调预训练模型:使用少量(大约3-5张)特定主体的图像对预训练的文本到图像扩散模型进行微调。这样做的目的是将特定主体的实例嵌入到模型的输出域中。
-
使用唯一标识符:为每个主体分配一个独特的标识符,并在文本提示中结合使用这个标识符和主体的类别名称(例如,“一个[V]狗”),这样可以帮助模型在保持类别先验的同时,学习将标识符与特定主体绑定。
-
设计文本提示:为了简化过程并避免编写详细的图像描述,作者选择使用简单的文本提示,如“a [V] [class]”,这有助于将模型对特定类别的先验知识与主体的独特标识符结合起来。
-
罕见标识符(Rare-token Identifiers):为了避免模型对标识符有预先的知识,作者寻找词汇表中的罕见标记,并将其反转到文本空间,以最小化标识符具有强先验的概率。
-
类别特定先验保留损失(Class-specific Prior Preservation Loss):为了解决语言漂移问题(即模型在微调后逐渐忘记如何生成与目标主体相同类别的其他主体),作者提出了一种新的损失函数。这种损失函数通过使用模型自身生成的样本来监督模型,以保留类别先验,并鼓励生成多样化的图像。
在Diffuser中有DreamBooth的实现,可以支持微调TextEncoder和UNet,在训练前生成class images。
InstantID : Zero-shot Identity-Preserving Generation in Seconds (2024.01)
这篇论文试图解决的问题是个性化图像合成中的一个关键挑战:在保持高保真度的同时,如何实现零次拍摄(zero-shot)的身份(ID)保持生成。论文讨论了以下几个方面的问题:
-
现有方法的局限性:现有的个性化图像生成方法,如Textual Inversion、DreamBooth和LoRA等,虽然在生成与参考图像风格、主题或角色ID一致的图像方面取得了显著进展,但它们的实际应用受到高存储需求、漫长的微调过程以及需要多个参考图像的限制。
-
ID嵌入方法的挑战:现有的基于ID嵌入的方法虽然只需要一次前向推理,但面临一些挑战,如需要对大量模型参数进行微调、与社区预训练模型不兼容,或者无法保持高面部保真度。
-
身份细节的精确保留:人类面部身份(ID)涉及更微妙的语义,并且需要比一般风格或对象更高的细节和保真度标准,这使得生成精确保留身份细节的图像成为一个特别具有挑战性的任务。
目前,需要资源:
DreamBooth(需要>5张图片,微调整个模型) > IP-Adapter(需要>5张图片,只用微调Image Embedding的crossAttention Layer) \(\approx\) InstantID(需要1张脸部图片,微调一个IdentityNet)
Method
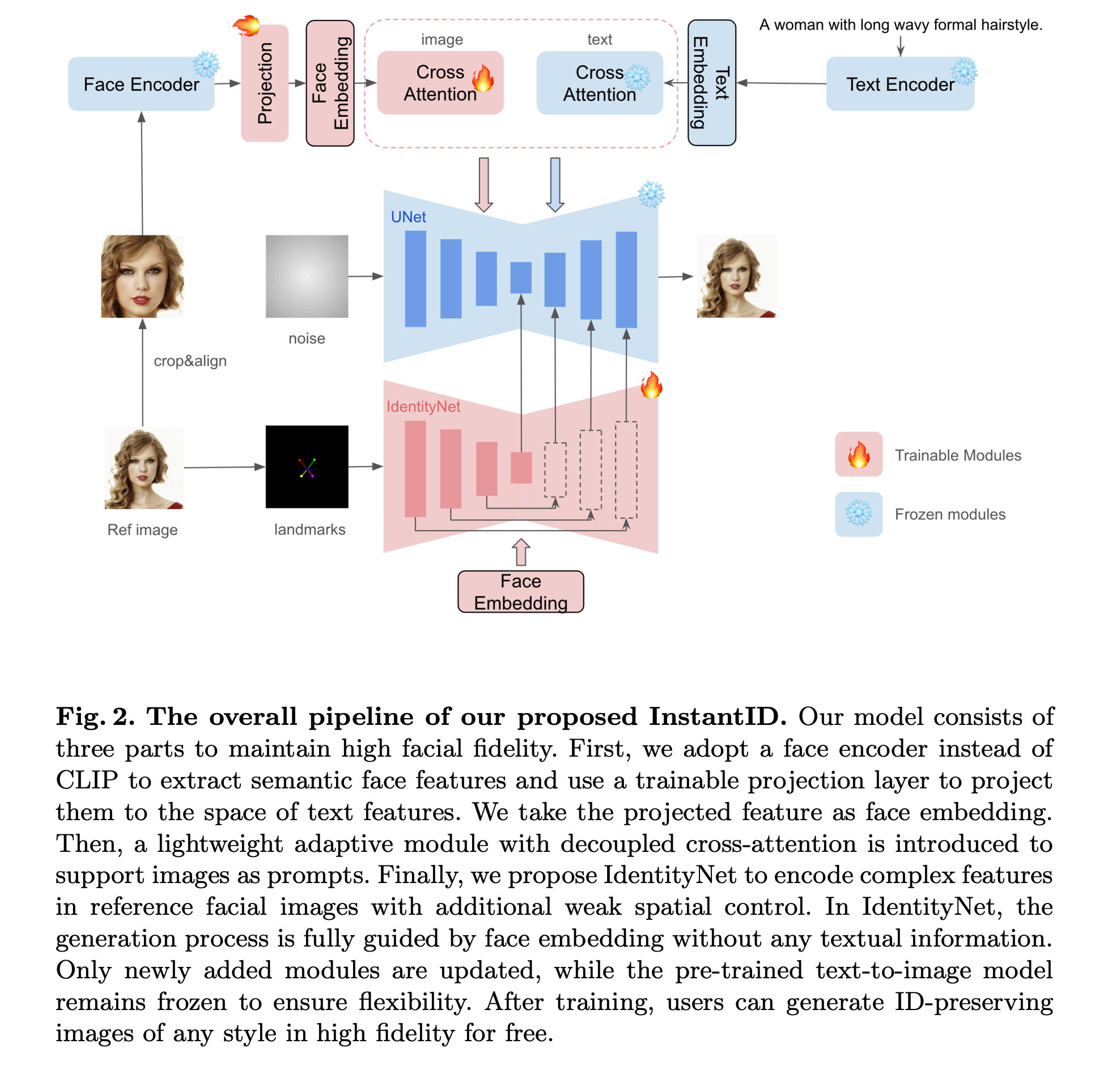
论文提出了一种名为InstantID的方法来解决零次拍摄身份保持图像生成的问题。InstantID的核心设计包括以下几个关键部分:
-
ID嵌入:使用预训练的面部模型(目前非常成熟的人脸识别模型来提取Embedding)来提取参考面部图像中的身份嵌入,这些嵌入包含了丰富的语义信息,如身份、年龄和性别等。与CLIP图像嵌入相比,这种方法能够提供更强的语义细节和更高的保真度。
-
图像适配器:引入了一个轻量级的适配器模块,该模块具有解耦的交叉注意力机制(和IP-Adapter一致),允许将图像作为视觉提示与文本提示一起用于图像生成过程。这种设计使得InstantID能够灵活地处理各种风格的图像个性化。
-
IdentityNet:设计了一个IdentityNet(就是一个ControlNet,只不过额外的监督信号是Face Embedding),它通过整合面部图像、面部关键点图像和文本提示来引导图像生成过程。IdentityNet在生成过程中完全由面部嵌入指导,而不使用任何文本信息,从而确保了面部身份的保留。
训练和推理策略:在训练过程中,只优化Image Adapter和IdentityNet的参数,而保持预训练文本到图像扩散模型的参数不变。在推理过程中,InstantID能够通过单步前向传播生成身份保持的图像,无需微调。

它的模型能够在保证Face的特征情况下,使用文本对于人脸生成进行控制,也是小红书之前火了一阵子的模型.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号