python 正则表达式
前言
最近在学习Python,发现在力扣做字符串题目时,不用正则表达式效率太低了,于是现在也是补补正则表达式的薄弱点
匹配规则
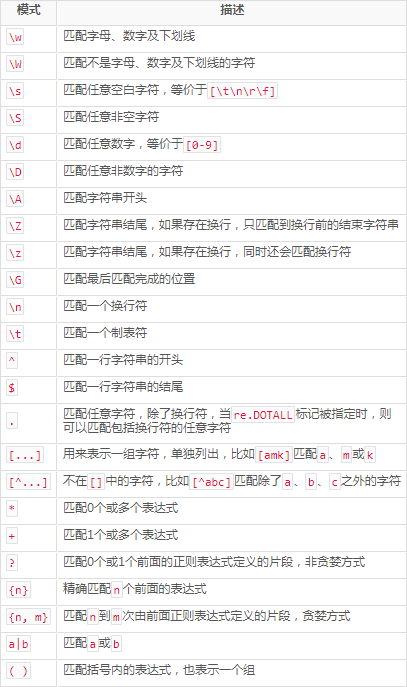
re模板函数
在Python 1.5版本起就增加了re的模块,他能提供我们所有的正则表达式功能。这样我门在写Python的时候更能得心应手。下面我就简单的介绍一下re模块的三个函数,match,search,findall。
match函数:match()方法的原理是只有当被搜索字符串的开头匹配模式的时候它才能查找匹配对象
代码讲解:这里第一个返回结果正是字符串'dog cat dog'匹配到的第一个dog,所以能够正常返回,但是第二个字符串第一个单词为dog,匹配项是cat,不能匹配所以返回为None
mymatch = re.match(r'dog','dog cat dog') print(mymatch.group(0)) 返回结果:'dog' mymatch = re.match(r'cat','dog cat dog') print(mymatch.group(0)) 返回结果:'None' # 这里的group是对匹配对象进行分组,这里可以忽略,示意为匹配到的第一个对象
search函数:search()方法的匹配对象可以不受字符串位置的影响,能够在给定字符串匹配到你想要的任意位置的子字符串,但是它只能匹配到第一个对应的字符串,也就是说如果字符串当中有2个可以匹配的字符串,它只打印匹配到的第一个字符串
代码讲解:这里就只打印了匹配到的第一个big
mymatch = re.search(r'big','not big dog cat big') print(mymatch.group(0)) 返回结果:big
findall函数:findall()方法的匹配对象可以找出给定字符串中所有要查找的子字符串。返回一个list进行输出
代码讲解:这里所有返回字符,都是用list形式打印出来的
mymatch = re.findall(r'big','not big dog')) print(mymatch) # or print(re.findall(r'big','not big dog'))
返回结果:【'big'】
练习题
1、匹配一行文字中的所有开头的字母内容
输入:"i love you not because of who you are, but because of who i am when i am with you"
输出:['i', 'l', 'y', 'n', 'b', 'o', 'w', 'y', 'a', 'b', 'b', 'o', 'w', 'i', 'a', 'w', 'i', 'a', 'w', 'y']
import re s="i love you not because of who you are, but because of who i am when i am with you" content=re.findall(r"\b\w",s) print(content)
题外:\s和\b的区别
import re s="dehjkgfehkfe abc djekdjekdj" content = re.findall(r"\babc\b",s) print(content) # 输出结果【'abc'】 content1 = re.findall(r"\sabc\s",s) print(content1) # 输出结果【' abc '】
结论:这里我们可以看出\b输出的是abc,而\s上面我们有提到是匹配任意空白字符,这里可以得出\babc\b代表着要输出abc前面和后面都必须符合带空格的要求。我也查了一些资料,发现网上给定的\b解释为,一个单词前后为空或者空格键都可以当做\b解释,如"hello Word“这里的hello前面就有一个\b,o后面又一个\b,其中中间无论都少个空格也算一个\b,W前面一个\b,d后面算一个\b。
import re s="hello word" content = re.findall(r"\bhello\b",s) print(content) # 输出结果:【'hello'】 content1 = re.findall(r"\shello\s",s) print(content1) # 输出结果:【】
2.匹配一行文字中所有带数字的内容

 浙公网安备 33010602011771号
浙公网安备 33010602011771号