go筑基篇(三)
【一】数据类型
1、基本数据类型
1.1 字符串类型
使用双引号""来定义字符串,字符串中可以使用转义字符(如\n:换行符、\t:tab 键等)来实现换行、缩进等效果,这种定义方式被称为字符串字面量(string literal)。但双引号字面量不能跨行,如果想要在源码中嵌入一个多行字符串时,就必须使用`反引号(esc下面那个键),反引号会将所有字符原样输出。
注:使用单引号引起来的是unicode编码(编排了全世界字符对应的值,它只规定了每个字符编码是多少,并没有规定数值怎么存储,而UTF-8、UTF-16...规定了unicode的值怎么存储)表里字符对应的值
go语言统一使用unicode编码,但unicode编码兼容了ASCII编码表(即ASCII编码表里字符对应的值和unicode编码表里字符对应的值一致),但没有兼容gbk编码表,它把中文又重新编排了
s := "你\n好" fmt.Println(s) str := `你 好 \n ` fmt.Println(str) s2 := '我' fmt.Printf("%T,%d,%c, %q \n", s2, s2, s2, s2)
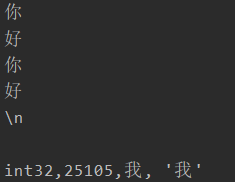
根据ASCII码表值构建字符串
slice := [] byte{65, 66, 67}//或[]uint8{65, 66, 67} str2 := string(slice) //转化为字符串 fmt.Println(str2) //ABC
根据unicode字符集构建字符串
slice := [] rune{65, 66, 25105}//或[]int32{65, 66, 25105} str2 := string(slice) //转化为字符串 fmt.Println(str2) //AB我
切片能转换类型为字符串,字符串也能转换类型为切片
s2 := "ABC" slice2 := []byte(s2) //转化为切片类型 fmt.Println(slice2) //【65 66 67】
使用技巧:
字符串常见操作方式
str := `我是东风hello world` fmt.Println(strings.Contains(str, "东风")) //true。包含后一个字符才返回true fmt.Println(strings.ContainsAny(str, "wo")) //true。只要有一个字符是前一个字符包含的就返回true fmt.Println(strings.Count(str, "o")) //2.统计o在前一个字符串出现的次数 fmt.Println(strings.HasPrefix(str, "我是")) //true.判断是否以我是开开头的字符串 fmt.Println(strings.HasSuffix(str, "ld")) //true.判断是否以ld结尾的字符串 fmt.Println(strings.Index(str, "东")) //6。返回字符第一次出现的位置索引。一个汉字代表三个字节。不存在返回-1 fmt.Println(strings.IndexAny(str, "那是东风")) //3。返回任意字符第一次出现位置 fmt.Println(strings.LastIndex(str, "o")) //19。查找o最后一次出现的位置索引 sliceStr1 := []string {"我", "是", "风"} str2 := strings.Join(sliceStr1, "-") //字符串拼接,使用-作为拼接符 fmt.Println(str2) //我-是-风 slice3 := strings.Split(str2, "-") //切割为切片类型数组 fmt.Printf("%T,%v \n", slice3, slice3) //[]string,[我 是 风] fmt.Println(strings.Repeat(str, 2)) //我是东风hello world我是东风hello world。字符串重复拼接指定次数 fmt.Println(strings.Replace(str, "o", "嘴", 2)) //我是东风hell嘴 w嘴rld。把o替换为嘴,替换指定个数o fmt.Println(strings.ToUpper(str)) //字符全部转换为大写 fmt.Println(str[6 : 12]) //东风。截取索引从6到12(不包含12)的字符串
字符串类型转换
b, err := strconv.ParseBool("true") //字符串转换为bool类型,成功时err值为 nil if err == nil { fmt.Printf("%T,%v \n", b, b) //bool,true } s,_ := strconv.ParseFloat("3.1415", 64) fmt.Printf("%T,%v \n", s, s) //float64,3.1415 i,_:= strconv.ParseInt("315123", 10, 8) //字符串转换为整型。把字符串当做10进制数,把原数据位数当做8bit fmt.Printf("%T,%v \n", i, i) //int64,127。因为315123超出int8最大数据127表示范围.所以这里显示127 ui,_:= strconv.ParseUint("315123", 10, 8) //字符串转换为整型。把字符串当做10进制数,把原数据范围当做8bit fmt.Printf("%T,%v \n", ui, ui) //uint64,255 i2,_:= strconv.ParseInt("315123", 10, 64) //字符串转换为整型。把字符串当做10进制数,把原数据范围当做8bit fmt.Printf("%T,%v \n", i2, i2) //int64,315123。 // 一般都是把原数据当做64bit看待处理,转换后数据也都是转换成64位 s2 := strconv.FormatFloat(4.1615, 'G', 4,64) //格式标记(b、e、E十进制指数、f、g、G大指数),精度4,指定浮点类型(32:float32、64:float64) fmt.Printf("%T,%v \n", s2, s2) //string,4.162 s3 := strconv.FormatInt(312, 10) //把312当做10进制转化为字符串 fmt.Printf("%T,%v \n", s3, s3) //string,312 //整型、字符串转换最常用是下面2种,简单些 simpleInt, _ := strconv.Atoi("-32") //把字符串转换为int类型 fmt.Printf("%T,%v \n", simpleInt, simpleInt) //int,-32 simpleStr := strconv.Itoa(890) //把整型转换为字符串 fmt.Printf("%T,%v \n", simpleStr, simpleStr) //string,890
关于中文字符串的处理
Go 语言 UTF-8 包提供了处理 Uncode 字符的方法,如 RuneCountInString() 函数用于计算长度,
str := "我" + "是" //字符串拼接 fmt.Println(str) //若使用len()函数的返回值的类型为 int,表示字符串的 ASCII 字符个数或字节长度 //ASCII 字符串遍历直接使用下标。Unicode 字符串遍历用 for range theme := "学" for _, s := range theme { //使用for i := 0; i < len(theme); i++ 只能遍历ASCII字符,使用for...range才能遍历unicode字符 fmt.Printf("%T, %c,%v\n", s, s, s) //int32, 学,23398 } //bytes.Buffer 是可以缓冲并可以往里面写入各种字节数组的。字符串也是一种字节数组,使用 WriteString() 方法进行写入。 //使用.WriteString()缓冲字节数组,再通过.String() 方法将缓冲转换为字符串 s1 := "我" s2 := "是" var stringBuffer bytes.Buffer // 声明字节缓冲 stringBuffer.WriteString(s1) // 把字符串写入缓冲 stringBuffer.WriteString(s2) fmt.Println(stringBuffer.String()) // 将缓冲以字符串形式输出
1.2 布尔类型
Go语言是使用
var isExist bool = true fmt.Printf("数据类型%T,值%t", isExist, isExist) //数据类型bool,值true
1.3 数字类型
1.3.1整数
如int、uint 和 uintptr
uint8,无符号 8 位整型 (0 到 255)
uint16,无符号 16 位整型 (0 到 65535)
uint32,无符号 32 位整型 (0 到 4294967295)
uint64,无符号 64 位整型 (0 到 18446744073709551615)
int8,有符号 8 位整型 (-128 到 127)
int16,有符号 16 位整型 (-32768 到 32767)
int32,有符号 32 位整型 (-2147483648 到 2147483647)
int64,有符号 64 位整型 (-9223372036854775808 到 9223372036854775807)
byte,类似 uint8,这2个类型的变量值可互换
rune,类似 int32,这2个类型的变量值可互换
uint,32 或 64 位(由操作系统决定),但不能和unit32、unit64类型变量值互换
int,32 或 64 位,但不能和unit32、unit64类型变量值互换
uintptr,无符号整型,用于存放一个指针
一般声明变量时如果不加上int位数会以操作系统位数为主,如果32位操作系统则int大小为int32,如果是64为操作系统则int大小为64位。
var num int = 23 var num2 int64 num2 = num // cannot use num (type int) as type int64 in assignment
如果声明变量不指定类型,而是使用类型推断,则系统默认推断为int类型
var num = 23 fmt.Printf("%T,%d", num, num) //int,23
1.3.2 浮点数
表示形式有float32、float64两张
var star float32 = 23.12
fmt.Printf("%T,%f", star, star) //float32,23.12000
fmt.Print(star) //23.12
var score = 23.12
fmt.Printf("%T,%f", score, score) //float64,23.120000
虽然格式化输入默认是保留6位小数,单真正使用Print打印输出是原来多少位就显示多少位。
如果不指定浮点类型,则类型推断默认推断为float64类型
1.3.3 复数
2、复合类型(派生类型)
2.1 数组类型(array)
数组是特定类型的定长的容器。因为长度固定,所以go语言很少直接使用数组。
数组的声明语法如下:var 数组变量名 [元素数量]元素Type
声明方式一(先声明变量,再通过下标赋值):
var arr [4] int //声明存储容量容量为4,数据类型为int类型的数组 arr[0] = 12 arr[1] = 23 fmt.Println("数组中实际存储的数据量", len(arr)) //4 fmt.Println("数组中能够存储的最大数量", cap(arr)) //4
因为数组是定长的容器,所以它的长度和容量是相同的。数组一旦创建,它的大小就不能改变了。
数值型数组初始化以后,没赋值,默认初始值为[0 0 0 0]
声明方式二(声明时直接赋值):
var arr = [4] string {"cdf", "age"} //不指定下标,默认下边0、1、2依次递增 var arr = [4] string {1: "cdf", 3:"174cm"} //指定元素下标声明数组 arr := [4] string {1: "cdf", 3:"174cm"} //简短声明,在变量中一般会根据变量自动推断变量类型。但这里已经指定了类型
使用var和通过:=简短声明变量的区别:
var能声明全局变量,:=只能声明局部变量.
var要指定变量类型,:=可不指定变量类型,它会推断出类型。
声明方式三(长度的位置使用“...”省略号,通过初始化值的个数来计算数组长度):
arr := [...] string {1: "cdf", 2:"174cm"} fmt.Println("长度", arr) //因为最大下标为2,所以数组长度为3
使用方式
// 打印索引和元素 for i, v := range arr { fmt.Printf("%d %s\n", i, v) } // 打印元素。如果只需要元素,不需要下标,可以使用下划线_来舍弃索引值 for _, v := range arr { fmt.Printf("%s\n", v) } fmt.Println(arr[len(arr) -1]) //打印最后一个元素
数组占用的是连续的内存空间,如果获取数组的地址,其实是获取数组首元素的地址,叫做首地址
冒泡排序
arr := [...] int {5, 1, 23, 17, 3} for loop := 1; loop < len(arr); loop++ { //轮数 for j := 0; j < len(arr) - loop;j++ { //每一轮对各下标循环比较 if arr[j] > arr[j+1] { arr[j+1],arr[j] = arr[j], arr[j+1] //交换2个值 } } }
多维数组:
声明多维数组的语法如下所示:
var array_name [size1][size2]...[sizen] array_type
arr := [3][4] int {{1,3,5,7}, {2, 12}, {9,13,19,0}} for _, arr1 := range arr { for _, value := range arr1 { fmt.Print(value, "\t") } fmt.Println() }
2.2 切片类型(slice)
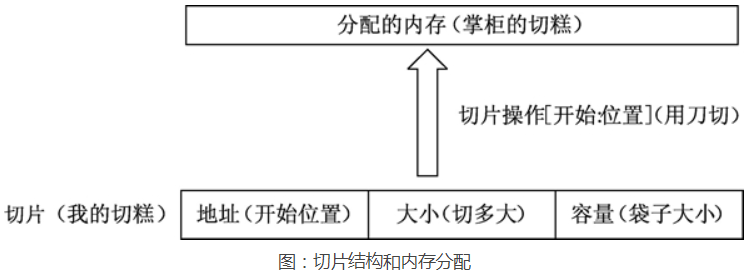
和数组对应的类型是 Slice(切片),Slice 是长度不固定的动态数组,功能也更灵活。
切片是通过声明一个未指定大小的数组来定义:
var identifier []type
声明方式一(先声明切片变量,再向切片里追加元素):
var sliceArr []int sliceArr = append(sliceArr, 1) //向切片追加一个元素 sliceArr = append(sliceArr, 12, 23, 78) //向切片添加多个元素 fmt.Printf("len=%d cap=%d slice=%v\n",len(sliceArr),cap(sliceArr),sliceArr) //查看切片的长度、容量、打印切片
声明方式二(简短声明,声明时初始化值):
numbers := []int{0,1,2,3} numbers = append(numbers, 123) //初始化值后依然可以向切片追加元素 fmt.Printf("len=%d cap=%d slice=%v\n",len(numbers), cap(numbers), numbers)
声明方式三(使用make函数构造切片):
语法:make( []Type, size, cap ) //数据类型、长度、切片容量
numbers := make([]int, 3, 4) //初始化切片,默认长度为3,即[0 0 0] numbers = append(numbers, 1, 2) //向切片追加元素,[0 0 0 1 2] numbers[4] = 12 //可以使用下标赋值追加元素。可以扩容 fmt.Printf("len=%d cap=%d slice=%v\n",len(numbers), cap(numbers), numbers) //len=5 cap=8 slice=[0 0 0 1 12],为什么容量是8,因为元素长度超过初始容量4,就会再次扩容为现有容量的一倍容量
注:使用make函数构造切片,可以针对切片索引下标追加元素,而其它声明方式不允许这么操作
使用技巧:
向切片里追加另一个切片的所有元素
sliceArr := []int{0,1,2,3} numbers := make([]int, 0, 4) //初始化值[] numbers = append(numbers, 1, 2)//[1 2] numbers = append(numbers, sliceArr...) //向切片numbers里追加切片sliceArr里所有元素。...代表展开切片里的元素 fmt.Printf("len=%d cap=%d slice=%v\n",len(numbers), cap(numbers), numbers) //len=6 cap=8 slice=[1 2 0 1 2 3]
向切片追加另一个切片的部分元素
numbers = append(numbers, sliceArr[2:]...)//把切片aliceArr从下标2到最后的元素追加到切片numbers fmt.Printf("len=%d cap=%d slice=%v\n",len(numbers), cap(numbers), numbers) //[1 2 2 3]
切片截取
sliceArr := []int{0,1,2,3} fmt.Println(sliceArr[0:2]) //截取索0~2(不包含2)的元素为一个新的切片.[0, 1] fmt.Println(sliceArr[:2]) //默认从0截取.[0, 1] fmt.Println(sliceArr[2:]) //从下标为2的索引截取到最后。[2, 3] fmt.Println(sliceArr[:]) //:左边默认最小下标,右边默认最大下标,相当于从最小截取到最大。[0, 1, 2, 3]
容器地址:
切片(slice)是对数组的一个连续片段的引用,所以切片是一个引用类型。切片指向的是数组的地址。容器每次扩容时切片地址都会发生改变,这也是为什么append后要再次赋值给原变量的原因。
sliceArr := []int{0,1,2,3} //容量为4,长度为4 fmt.Printf("%p\n", sliceArr) //地址:0xc00000a340 打印切片,其实就是打印切片的底层数组地址.切片本身也有地址,使用&sliceArr打印的是切片地址 sliceArr = append(sliceArr, 2) //第一次扩容,按4的一倍扩容,容量为8.如果以后再扩容就是8的一倍,容量会变成16 fmt.Printf("%p\n", sliceArr) //因为扩容,地址改变0xc00000c200 sliceArr = append(sliceArr, 3,4,5,6) //长度为8,不需要再次扩容,地址没变 fmt.Printf("%p\n", sliceArr) //0xc00000c200
var sliceArr []int //长度为0,容量为0 fmt.Printf("%p\n", sliceArr) //0x0 sliceArr = append(sliceArr, 1) //追加数据,容量不足,进行扩容,容量为1 fmt.Printf("%p\n", sliceArr) //地址改变,容量为1。0xc0000a2078 sliceArr = append(sliceArr, 2) fmt.Printf("%p\n", sliceArr) //再次追加数据后,容量不足,再次扩容。容量为2,地址改变。0xc0000a20b0 sliceArr = append(sliceArr, 3) //再次追加数据,容量不足,再次扩容。容量为2的一倍,即4.地址改变. fmt.Printf("%p\n", sliceArr) //0xc0000a01a0 sliceArr = append(sliceArr, 4) //因为只追加一个数据,此时长度为4,容量为4.因为容量足够使用,不会扩容,地址不变。 fmt.Printf("%p\n", sliceArr) //0xc0000a01a0
无论对数组或切片进行截取,截取以后都是切片类型。因为切片就是对数组连续片段的一个引用。
arr := [4] int {1,3,5,7} fmt.Printf("%T,%p\n", arr, &arr) //[4]int,0xc0000a0140 数组类型 sliceArr := arr[:] fmt.Printf("%T,%p\n", sliceArr, sliceArr) //[]int,0xc0000a0140 变为切片地址。切片是个地址,即数组地址 sliceArr2 := arr[:2] fmt.Printf("%T,%p\n", sliceArr2, sliceArr2) //[]int,0xc0000a0140
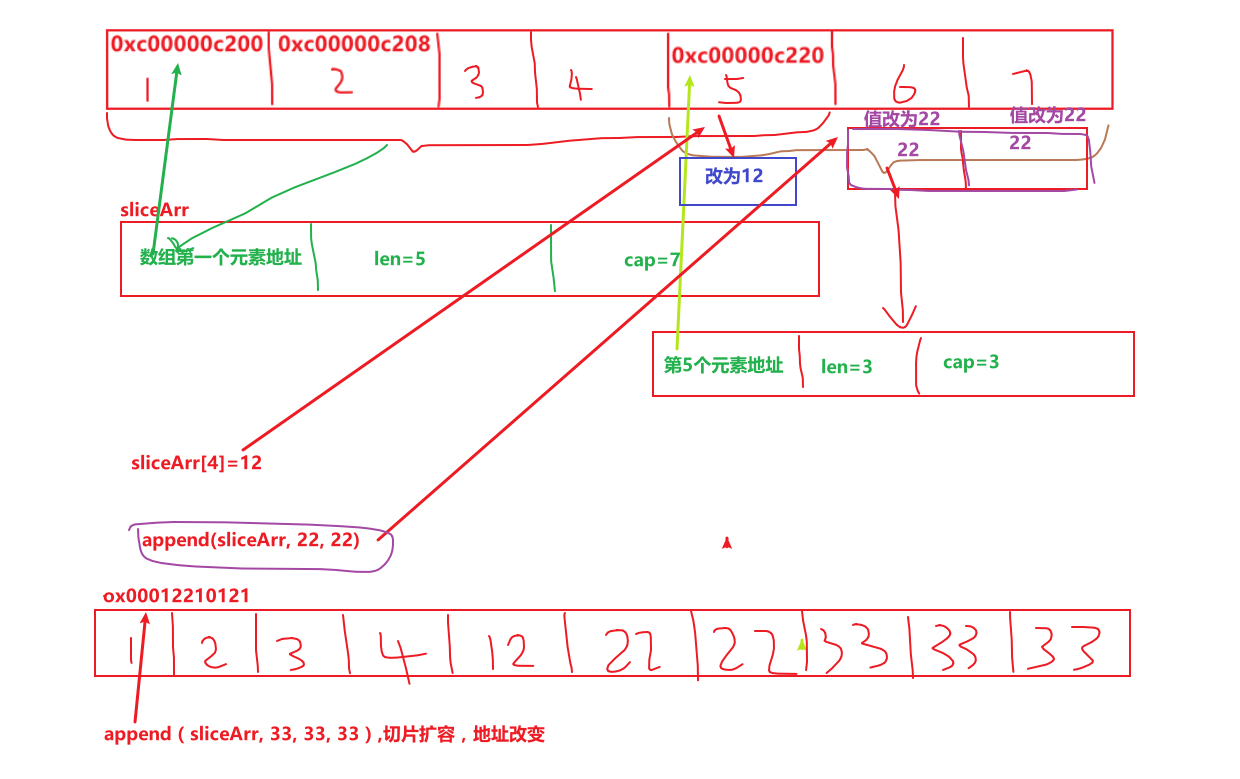
切片本身是不存储数据的,只有它通过地址指向的底层数组才存储数据。操作任意一个切片其实就是操作底层数组,如果切片指向的数组地址没改变,其它切片都可能受影响。
arr := [7] int {1,2,3,4,5,6,7} fmt.Printf("%T,%p,%p,%p,%p\n", arr, &arr, &arr[0], &arr[1], &arr[4]) //[7]int,0xc00000c200,0xc00000c200,0xc00000c208,0xc00000c220.类型数组 sliceArr := arr[0:5] fmt.Printf("%T,len%d,cap%d,%p\n", sliceArr, len(sliceArr),cap(sliceArr),sliceArr) ////[]int,len5,cap7,0xc00000c200。类型切片。容量是索引位置到数组最后一个元素的长度 sliceArr2 := arr[4:] fmt.Printf("%T,len%d,cap%d,%p\n", sliceArr2, len(sliceArr2),cap(sliceArr2),sliceArr2)//[]int,len3,cap3,0xc00000c220.类型切片,容量是从索引位置到数组最后一个元素的长度。 sliceArr[4] = 12 fmt.Printf("%v,%v,%v\n", arr, sliceArr, sliceArr2) //[1 2 3 4 12 6 7],[1 2 3 4 12],[12 6 7] //第5个元素5变为12.对数组和其他切片都造成了影响 sliceArr = append(sliceArr, 22, 22) fmt.Printf("%v,%v,%v\n", arr, sliceArr, sliceArr2) //[1 2 3 4 12 22 22],[1 2 3 4 12 22 22],[12 22 22] //追加元素,其实就是从第一个切片的最后一个位置,即数组第六位开始追加,其实是改变值。对其他切片造成影响 sliceArr = append(sliceArr, 33, 33, 33) fmt.Printf("%v,%v,%v\n", arr, sliceArr, sliceArr2) //[1 2 3 4 12 22 22],[1 2 3 4 12 22 22 33 33 33],[12 22 22] //因为容量改变,产生一个新数组地址存储数据。对其它切片不再造成影响
扩展:
按传值特点划分,数据类型分为值类型和引用类型。
值类型传递的是数据的副本(即将数据拷贝一份传递,对原数据没有影响),值类型有int、float、string、bool、array、struct
引用类型因为存储的是数据的内存地址,所以传递的时候传递的是引用地址。包括slice、map、chan
深拷贝,拷贝的是数据本身,所以值类型数据都是深拷贝。
浅拷贝,拷贝的是数据地址,所以引用类型都是浅拷贝。
切片深拷贝2种实现方式:
1、把另一个切片的每个值一个个拷贝进去 2、使用copy拷贝
slice1 := []int {1, 3, 5, 7} slice2 := make([]int, 0, 4) slice2 = append(slice2, slice1...) //把里面每个值一个个拷贝进去或使用for循环append fmt.Printf("%p,%p,%v,%v \n", slice1, slice2, slice1, slice2) copy(slice2, slice1) //使用copy实现深拷贝 fmt.Printf("%p,%p,%v,%v", slice1, slice2, slice1, slice2)
2.3 Map 类型
Map可以理解为关联数组,给定 key,就可以迅速找到对应的 value。map 这种数据结构在其他编程语言中也称为字典(Python)、hash 和 HashTable 等。
map 可以根据新增的 key-value 动态的伸缩,因此它不存在固定长度或者最大限制,但是也可以选择标明 map 的初始容量 capacity。
map 是引用类型,可以使用如下方式声明:
var mapname map[keytype]valuetype
map声明3种方式
方式一(先声明,后初始化):
var map1 map[string] string //默认值nil map1 = map[string]string{"name": "cdf", "age" : "27"} map1["height"] = "174cm" fmt.Printf("%T, %v \n", map1, map1)
额先声明map变量,此时map变量初始值是nil。不能直接通过key-value向nil值的map里分配数据,必须先初始化值,才能通过下标来分配数据
方式二(声明时直接初始化):
map2 := map[string]string{"name": "cdf", "age" : "27"} fmt.Printf("%T, %v \n", map2, map2)
方式三(使用make来构造map):
map3 := make(map[string]string, 2) //指定map容量2 map3["height"] = "178cm" fmt.Printf("%T, %p, %v \n", map3, map3, map3) //map[string]string, 0xc00006e450, map[height:178cm] map3 = map[string]string{"name": "cdf", "age" : "27"} fmt.Printf("%T, %p, %v \n", map3, map3, map3) //map[string]string, 0xc00006e4b0, map[age:27 name:cdf] map3["height"] = "178cm" fmt.Printf("%T, %p, %v \n", map3, map3, map3) //map[string]string, 0xc00006e4b0, map[age:27 height:178cm name:cdf]
使用技巧:
map增删改查
map3 := make(map[string]string, 2) map3 = map[string]string{"name": "cdf", "age" : "27"} map3["height"] = "178cm" //修改 delete(map3, "height") //删除 value, ok := map3["weight"] //查看,存在这个key,ok为true,否咋为false if false == ok { fmt.Printf("%T, %p, %v \n", value, map3, ok) //map[string]string, 0xc00006e4b0, map[age:27 height:178cm name:cdf] }
map里数值从小到大排序输出
map1 := map[int]string {1:"cdf", 13:"df", 7:"cx", 2:"dandan"}
sliceSort := make([]int, 0, len(map1))
for key,_ := range map1 {
sliceSort = append(sliceSort, key)
}
sort.Ints(sliceSort)
for _, inx := range sliceSort {
fmt.Println(inx, map1[inx])
}
map结合切片。如把map存入切片
map1 := map[string]string{"name": "cdf", "age" : "27"} //声明2个map map2 := map[string]string{"name": "caoxiao", "age" : "27"} sliceMap := make([]map[string]string, 0, 2) //声明切片,切片数据类型为map类型 sliceMap = append(sliceMap, map1) //把map存入切片 sliceMap = append(sliceMap, map2) fmt.Printf("%T, %v \n", sliceMap, sliceMap) //[]map[string]string, [map[age:27 name:cdf] map[age:27 name:caoxiao]] for _,nameInfo := range sliceMap { //遍历切片 fmt.Println(nameInfo["name"], nameInfo["age"]) //打印map值 }
以上是切片存map,若是map存map呢?
mapMap := make(map[string]map[string]string) //这样声明即可。map的key是字符串类型,值是map类型。
map是引用类型
map1 := map[string]string{"name": "cdf", "age" : "27"} mapMap := make(map[string]map[string]string) mapMap["key1"] = map1 mapMap2 := mapMap mapMap2["key1"]["name"] = "caoxiao" fmt.Println(mapMap) //map[key1:map[age:27 name:caoxiao]]
发现当map引用赋值后,一个map的改变会影响另一个map。说明是引用类型
2.4 结构化类型(struct)
Go语言中array是定长索引数组,slice切片是不定长索引数组,map是关联数组,他们都只能存储同一类型的数据。若存储不同类型的数据,可以使用结构体,结构体是类型中带有成员的复合类型。
结构体成员是由一系列的成员变量构成,这些成员变量也被称为“字段”。字段有以下特性:
- 字段拥有自己的类型和值。
- 字段名必须唯一。
- 字段的类型也可以是结构体,甚至是字段所在结构体的类型
结构体声明
结构体声明之前需要先定义结构体,然后仔使用定义的结构体进行声明。
使用type关键字定义结构体
type 类型名 struct { 字段1 字段1类型 字段2 字段2类型 … }
如定义一个Person类型的结构体:
type Person struct { name string age int height float32 }
结构体的定义只是一种内存布局的描述,只有当结构体实例化时,才会真正地分配内存,因此必须在定义结构体并实例化后才能使用结构体的字段。
结构体实例化后字段的默认值是字段类型的默认值,例如 ,数值为 0、字符串为 ""(空字符串)、布尔为 false、指针为 nil 等。
方式一(使用var声明结构体来完成实例化):
var p1 Person fmt.Printf("%T,%p,%v\n",p1, &p1, p1) //main.Person,0xc000004480,{ 0 0}
结构体赋值
使用.来访问结构体的成员变量进行赋值
p1.name = "cdf" fmt.Printf("%T,%p,%v\n",p1, &p1, p1) //main.Person,0xc000004480,{cdf 0 0}
方式二(使用简短声明):
使用简短声明初始化结构体的值进行实例化
初始化分3种
1、使用简短声明初始化空值,再赋值
p2 := Person{} fmt.Printf("%T,%p,%v\n",p2, &p2, p2) //main.Person,0xc000004540,{ 0 0} p2.name = "cdf" fmt.Printf("%T,%p,%v\n",p2, &p2, p2) //main.Person,0xc000004540,{cdf 0 0}
2、简短声明时,通过键值对方式初始化结构体的值
p3 := Person{name:"cdf", age:27, height:171.4}
fmt.Printf("%T,%p,%v\n",p3, &p3, p3) //main.Person,0xc0000045e0,{cdf 27 171.4}
使用键值对初始化结构体字段值的顺序可以和定义结构体的字段顺序不一致
3、简短声明时,使用值列表初始化结构体的字段值
他的值的顺序必须和结构体定义的字段顺序一致
p3 := Person{"cdf", 27, 171.4}
fmt.Printf("%T,%p,%v\n",p3, &p3, p3) //main.Person,0xc0000045e0,{cdf 27 171.4}
方式三(使用new):
使用new关键字进行实例化,结构体在实例化后会形成指针类型的结构体。
new 关键字还可用于对类型(包括切片、整型、浮点数、字符串等)进行实例化
格式:
ins := new(T)
其中:
T 为类型,可以是结构体、整型、字符串等。
ins:T 类型被实例化后保存到 ins 变量中,ins 的类型为 *T,属于指
如:
p4 := new(Person) //实例化Person类型,P4是一个指针 fmt.Printf("%T, %p, %p, %v\n",p4, &p4, p4, p4) //*main.Person, 0xc000006030, 0xc000004640, &{ 0 0} p4.name = "cdf" fmt.Printf("%T, %p, %p, %v\n",p4, &p4, p4, p4) //*main.Person, 0xc000006030, 0xc000004640, &{cdf 0 0}
它类似于
var p1 Person //实例化结构体 var p4 *Person //定义结构体指针 p4 = &p1 fmt.Printf("%T, %p, %p, %v\n",p4, &p4, p4, p4) //*main.Person, 0xc0000cc018, 0xc000098420, &{ 0 0} p4.name = "cdf" //(*p4).name = "cdf" fmt.Printf("%T, %p, %p, %v\n",p4, &p4, p4, p4) //*main.Person, 0xc0000cc018, 0xc000098420, &{cdf 0 0}
方式四(使用&取地址操作):
对结构体进行&取地址操作时,视为对该类型进行一次 new 的实例化操作,取地址格式如下:
ins := &T{}
其中:
T 表示结构体类型。
ins 为结构体的实例,类型为 *T,是指针类型。
p4 := &Person{} fmt.Printf("%T, %p, %p, %v\n",p4, &p4, p4, p4) //*main.Person, 0xc0000cc018, 0xc000098420, &{ 0 0} p4.name = "cdf" //(*p4).name = "cdf" fmt.Printf("%T, %p, %p, %v\n",p4, &p4, p4, p4) //*main.Person, 0xc0000cc018, 0xc000098420, &{cdf 0 0}
或取地址操作时直接赋值
p4 := &Person{ name: "cdf", age: 27, height: 1.23, //最后一个字段后面也必须有逗号,如果右花括号和最后一个字段在同一行可以省略最后一个字段的逗号 } fmt.Printf("%T, %p, %p, %v\n",p4, &p4, p4, p4) //*main.Person, 0xc000006028, 0xc000004480, &{cdf 27 1.23}
匿名结构体
匿名结构体没有类型名称,无须通过 type 关键字定义就可以直接使用。
发现匿名结构体的结构类型有些不一样
p4 := struct{ name string age int height float32 } { name: "cdf", age: 27, height: 1.23, } fmt.Printf("%T, %p, %v\n",p4, &p4, p4) //struct { name string; age int; height float32 }, 0xc000098420, {cdf 27 1.23}
匿名字段
匿名字段只能通过类型取值,这也导致结构体中各值的类型不能重复,否则报错
type Person struct { //定义匿名字段结构体 string int float32 } p4 := Person{ "cdf", 27, 1.23, } fmt.Printf("%T, %p, %v\n",p4, &p4, p4) //main.Person, 0xc000004480, {cdf 27 1.23} fmt.Println(p4.int) //27。通过类型取值
结构体嵌套(聚合关系)
一个结构体嵌套另一个结构体
type Person struct { name string age int } type Student struct { p Person //嵌套另一个结构体,有结构体名这就是嵌套,他们是一种组合关系,而不是继承关系 school string } stu := Student{ p:Person{ name: "cdf", age: 27, }, school: "北大", } fmt.Printf("%T, %p, %v\n",stu, &stu, stu) //main.Student, 0xc00006e330, {{cdf 27} 北大} fmt.Println(stu.p.age) //27。
结构体继承
继承嵌套的是另一个结构体的类型,没结构体名
type Person struct { name string age int } type Student struct { Person //继承必须是匿名字段,类似于派生 school string } stu := Student{Person: Person{name: "cdf", age: 27,}, school: "北大",} //键值对时初始化用Person:Person,值列表时使用Person,如stu := Student{Person{ "cdf", 27}, "北大"} fmt.Printf("%T, %p, %v\n",stu, &stu, stu) //main.Student, 0xc00006e330, {{cdf 27} 北大} fmt.Println(stu.Person.age) //27。通过类型取值
继承关系的结构体字段会被提升,如上面的name或age都是提升字段,可以简写,如stu.Person.age可以简写为
fmt.Println(stu.age) //27
结构体可以包含一个或多个匿名(或内嵌)字段,即这些字段没有显式的名字,只有字段的类型是必须的,此时类型就是字段的名字。匿名字段本身可以是一个结构体类型,即结构体可以包含内嵌结构体。
Go语言中的继承是通过内嵌或组合匿名结构体(没有显示的名字)来实现的,所以可以说,在Go语言中,相比较于继承,组合更受青睐。
2.5 Channel 类型
Go语言
2.6 函数类型(function)
在Go语言中,函数也是一种类型,可以和其他类型一样保存在变量中。
var f func() //声明func()类型的变量f,此时f就被俗称为“回调函数”,此时f的值为 nil fmt.Printf("%T,%v \n", f, f) //func(),<nil> f = run //将 run() 函数作为值,赋给函数变量 f,此时 f 的值为run()函数 fmt.Printf("%T,%v \n", f, f) //func(),0xf87440 f() //使用函数变量f进行函数调用,实际调用的是run()函数 func run() { //定义了一个 run() 函数。 fmt.Println("runing...") }
函数声明包括函数名、形式参数列表、返回值列表(可省略)以及函数体。
多参数函数
sum(1, 4) //调用 func sum(a int, b int) { //定义sum函数 sum := a + b fmt.Printf("%T,%d", sum, sum) }
如果参数类型一致可简写为 func sum(a, b int) { ....}
可变参数函数
一个函数里类型一致,但形参个数不确定,可以使用参数名...参数类型来接收多个参数
sum(1, 4) func sum(nums ... int) { fmt.Printf("%T,%d", nums, nums) //[]int,[1 4] }
可变参数会用切片类型去接收形参
如果不同类型的参数,可变参数只能放在参数的最后面,一个函数只能有一个可变参数
getUserScore("王娜", 89, 74, 100) func getUserScore(username string, scores ... int) { totalScore := 0 for i := 0; i < len(scores); i++ { //遍历切片,计算总和 totalScore += scores[i] } fmt.Printf("学生%s的总分是%d", username, totalScore) //学生王娜的总分是263 }
参数传递
值传递:int、string、float、bool、struct、array都是值传递,函数体操作的是实参的拷贝
引用传递:sclice、map、channel都是引用传递,函数体操作的是实参的地址,会改变实参变量
下面演示slice切片类型参数传递
score := []int {98, 79, 100, 67} getUserScore(score) //通过函数改变变量 score值 fmt.Printf("%T,%v \n", score, score) //发现原变量score值已发生改变 []int,[98 99 100 67] func getUserScore(scoreParam []int) { scoreParam[1] = 99 //改变第二个元素值 fmt.Printf("%T,%v\n", scoreParam, scoreParam) //输出切片类型数据[]int,[98 99 100 67] }
函数返回值
函数有返回值时必须指定返回类型,否则报错
只有一个返回类型
res := sum(12, 14)
func sum(a int, b int) (int) { //指定返回类型
s := a + b
return s
}
如果只有一个返回类型,返回数据类型可以省略括号,写为 func sum(a int, b int) int){ .......}
如果返回值是同一种类型,则用括号将多个返回值类型括起来,用逗号分隔每个返回值的类型
多返回值
res1, res2 := getValue(12, 14) func getValue(a int, b int) (int, int) { return a, b }
纯类型的返回值对于代码可读性不是很友好,特别是在同类型的返回值出现时,无法区分每个返回参数的意义
带有变量名的返回值
Go语言支持对返回值进行命名,这样返回值就和参数一样拥有参数变量名和类型。
命名的返回值变量的默认值为类型的默认值,即数值为 0,字符串为空字符串,布尔为 false、指针为 nil 等
省略返回值,命名返回值时,可以在 return 中不填写返回值列表,
在函数体中直接对函数返回值进行赋值,在函数结束前需要显式地使用 return 语句进行返回
res1, res2 := getValue() //返回1 2 func getValue() (a int, b int) { b = 2 //直接对返回值进行赋值 a = 1 return //相当于返回a, b }
命名返回值,但在return语句填写返回值列表
res1, res2 := getValue() //此时返回2,1 func getValue() (a int, b int) { b = 2 //虽然命名了返回值 a = 1 return b, a //但return列表会和函数变量返回值按顺序对应
}
return列表的值与函数返回值一一对应
2.7 指针类型(Pointer)
指针也是一个变量,只不过它存储的是另一个变量的内存地址。
如果变量a存储了变量b的内存地址,那么变量a是一个指向变量b的指针(或变量a持有变量b的地址)
每个变量在运行时都拥有一个地址,这个地址代表变量在内存中的位置。Go语言中通过在变量名前面添加&操作符(前缀)来获取变量的内存地址(取地址操作),格式如下:
var num int = 12 ptr := &numfmt.Printf("类型:%T,内存地址:%p \n", ptr, ptr) //类型:*int,内存地址:0xc00000e0b0
变量 num 的地址使用变量 ptr 进行接收,ptr 的类型为*T,称做 T 的指针类型,*代表指针
声明指针,*T代表指针变量的类型,它指向T类型的值
var var_name *var-type //var_name指针变量名,var-type指针类型,*号用于指定一个变量作为一个指针
列如:
var num int = 12
var p1 *int //声明指针变量p1
fmt.Printf("类型:%T,内存地址:%v \n", p1, p1) //类型:*int,内存地址:<nil>
p1 = &num //p1指向num的内存地址
fmt.Printf("类型:%T,指针值:%v,指针变量地址:%v \n", p1, p1, &p1) //类型:*int,指针值:0xc00000e0b0,指针变量地址:0xc000006028
指针变量虽然存储着另一个变量的内存地址,但它也有属于自己的内存地址
如何获取地址所存储的数据,使用*var_name
fmt.Printf("类型:%T,内存地址存储的数据:%v \n", *p1, *p1) //类型:int,内存地址:12
*p1 = 13 //改变内存地址存储的数据
fmt.Printf("类型:%T,内存地址:%v \n", *p1, *p1) //类型:int,内存地址:13
指针的指针
var num int = 12 var p1 *int //声明指针变量p1 p1 = &num //p1指向num的内存地址 //类型:*int,p1所存储的值,即num的内存地址:0xc00000e0b0,p1的内存地址地址:0xc000006028 fmt.Printf("类型:%T,p1所存储的值,即num的内存地址:%v,p1的内存地址地址:%v \n", p1, p1, &p1) var p2 **int //声明指针的指针 p2 = &p1 //存储指针变量p1的内存地址 //类型:**int,p2的内存地址0xc000006038,p2存储的值,即p1的内存地址0xc000006028, p1存储的值,即num的内存地址0xc00000e0b0, num值12 fmt.Printf("类型:%T,p2的内存地址%v,p2存储的值,即p1的内存地址%v, p1存储的值,即num的内存地址%v, num值%v \n", p2, &p2, p2, *p2, **p2)
数组指针和指针数组
数组指针:*[length]dataType
指针数组:[length]*dataType
//如果存储的是另一个数组的地址,该变量叫做数组指针。特点:变量是指针,存储的是数组自身变量的地址 arr := [4]int{1, 4, 6, 9} var p1 *[4]int //声明数组指针 p1 = &arr fmt.Println(p1) //&[1 4 6 9] fmt.Printf("%p,%p\n", p1, &p1) //0xc00000a340,0xc000006028 (*p1)[0] = 100 fmt.Println(arr) //[100 4 6 9] //可简写为 p1[0] = 200 fmt.Println(arr) //[200 4 6 9] //如果数组里存储的是地址,该数组叫做指针数组。特点:变量是数组,存储数据类型是指针(即数组里存储的是各元素地址) age := 28 height := 176 arr2 := [2]*int{&age, &height} fmt.Println(arr2) // [0xc0000a20b0 0xc0000a20b8] *arr2[0] = 100 fmt.Println(age) //100
此外还有**[length]dataType,*[length]*dataType等
2.8 接口类型(interface)
接口是一种类型,也是一种抽象结构。在面向对象世界中接口一般用来定义对象的行为动作的,而在go中接口是一组方法签名。
为什么要使用接口?
接口最大的意义是解耦合(程序之间的关联性越低越好),接口的本质把功能的定义和功能的实现分离开。
Go语言中没有类似于 implements 的关键字。 Go编译器将自动在需要的时候检查两个类型之间的实现关系。
go语言的接口使用非侵入式设计(即不需要显示声明哪个类型实现了这个接口,绝大部分语言的接口都是侵入式的:像public xxx implements interface,必须指明实现了哪个接口,它自身具有耦合性),非侵入式设计是 Go 语言设计师经过多年的大项目经验总结出来的设计之道。
只有让接口和实现者真正解耦,编译速度才能真正提高,项目之间的耦合度也会降低不少
接口定义:
type 接口类型名 interface{ 方法名1( 参数列表1 ) 返回值列表1 方法名2( 参数列表2 ) 返回值列表2 … }
Go语言的接口在命名时,一般会在单词后面添加 er,如有写操作的接口叫 Writer,有字符串功能的接口叫 Stringer。
Go语言提供的很多包中都有接口,例如 io 包中提供的 Writer 接口。Go语言的每个接口中的方法数量不会很多。
Go语言希望通过一个接口精准描述它自己的功能,而通过多个接口的嵌入和组合的方式将简单的接口扩展为复杂的接口。
当方法名和这个接口类型名的首字母都是大写时,这个方法可以被接口所在的包(package)之外的代码访问
实现接口必备2个条件:
1、接口中所有方法都被实现
2、在类型中实现与接口签名一致的方法(签名包括方法名、参数列表、返回参数列表)。即实现接口类型中的方法的名称、参数列表、返回参数列表中的任意一项都必须与接口要实现的方法一致。
注:接口方法的实现包括通过多个结构嵌入到一个结构体中拼凑起来共同实现。
一个类型可以同时实现多个接口,而接口间彼此独立,不知道对方的实现。
接口的用法:
1、一个函数如果接受接口类型作为参数,那么实际上可以传入该接口的任意实现类型对象作为参数
2、定义一个类型为接口类型,实际上可以赋值为任意实现类对象
func main() { m := Mouse{name: "鼠标"} m.start() //调用方法,显示:鼠标 开始工作 } //定义接口 type USB interface { start() end() } //实现类 type Mouse struct { name string } func (m Mouse) start() { //在类型中实现与接口签名一致的方法 fmt.Println(m.name, "开始工作") } func (m Mouse) end() { //实现接口里的所有方法 fmt.Println(m.name,"结束工作") }
定义一个接口类型,实际上可以赋值为任意实现类对象
var usb USB //声明usb接口对象 usb = m //把m实现类对象赋值给usb接口,定义一个类型为接口类型,实际上可以赋值为任意实现类对象 usb.start() //可以调用实现类对象中的方法 fmt.Println(usb.name) //报错:无法调用鼠标里的name。接口对象不能调用实现类当中的属性
一个函数如果接受接口类型作为参数,那么实际上可以传入该接口的任意实现类型对象作为参数
testInterface(m) //可以传入改接口的任意实现类作为参数
func testInterface(usb USB) { //使用接口类型作为参数
usb.start()
usb.end()
}
空接口
接口中一个方法也没有叫空接口,可以把任意类型看成这接口的实现
type em interface {} //定义一个空接口类型em var obj1 em = "小麦" //声明obj1接口为空接口,可以把任意类型看成这接口的实现赋值非空接口 var obj2 em = 100 fmt.Println(obj1, obj2) //小麦 100
作用:定义一个函数可以接收任意类型的数据,那函数的参数可以使用空接口
writeData(123) //123 func writeData(d interface{}) { //声明匿名空接口d,它可以接收任意类型的参数,因为任意类型都可以看做是空接口的实现,都可赋值给它 fmt.Println(d) }
像fmt.Println为什么能输出任意参数,那是因为它的参数空接口可变参
func Println(a ...interface{}) (n int, err error) { return Fprintln(os.Stdout, a...) }
空接口还可在切片、容器中使用,这样他们就能存储任意类型的数据
var map1 = make(map[string]interface{}) //值为任意类型 map1["name"] = "cdf" map1["age"] = 32 fmt.Println(map1) var map2 = make(map[interface{}]interface{}) //key、value为任意类型 map2["name"] = "cdf" map2[1] = 32 fmt.Println(map2) slice1 := make([]interface{}, 0, 10) //长度0,容量10 slice1= append(slice1, "cdf", 32) //添加内容 fmt.Println(slice1)
接口嵌套:
要实现Mouse不仅要呢实现taste()方法,还要实现Mouse接口里嵌套的Eat、Speak接口里的方法
func main() { var p = Person{} p.eatFood() //调用接口Eat里的方法或接口Mouse里的方法 p.SpeakLanguage() //调用接口Speak里的方法或接口Mouse里的方法 p.taste() //调用接口Mouse里的方法 } type Eat interface { eatFood() } type Speak interface { speakLanguage() } type Mouse interface { Eat Speak taste() } type Person struct { } func (p Person) eatFood() { //实现了接口Eat fmt.Println("吃 食物") } func (p Person) SpeakLanguage() { //实现了接口Speak fmt.Println("讲话") } func (p Person) taste() { //实现接口Mouse里的方法 fmt.Println("品尝味道") }
实现体嵌套:
接口的方法可以通过在类型中嵌入其他类型或者结构体来实现。
因为GameService嵌套的Logger已经实现了Log()方法,所以GameService无需去再次实现一次接口Service里的Log方法
func main() { var s Service = new(GameService) s.Start() s.Log("hello") } // 一个服务需要满足能够开启和写日志的功能 type Service interface { Start() // 开启服务 Log(string) // 日志输出 } type Logger struct { // 日志器 } func (g *Logger) Log(msg string) { // 实现Service的Log()方法 fmt.Println("输出日志" + msg) } type GameService struct { // 游戏服务 Logger // 嵌入日志结构体 } func (g *GameService) Start() { // 实现Service的Start()方法 fmt.Println("开始启动游戏") }
3、类型转换
并不是所有所有数据类型之间都能互相转换,像布尔类型就不能和整型之间互相转换。只有兼容类型,如浮点型、整型之间才能互相转换。
注意:go语言是静态语言,要求定义、赋值、运算必须类型一致。此时就需要类型转换
var num1 float64 = 19.6 num2 := 19 var num3 float32 num3 = float32(num1) + float32(num2) //必须转换数据类型才能进行运算 fmt.Println(num3) sum := num1 + 100 //转型是针对变量来说的,常数100与变量运算就不需要转型 fmt.Println(sum)
【二】运算符
1、运算符类型
1.1 算术运算符
算数运算符有
| + | 相加 | A + B 输出结果 30 |
| - | 相减 | A - B 输出结果 -10 |
| * | 相乘 | A * B 输出结果 200 |
| / | 相除 | B / A 输出结果 2 |
| % | 求余 | B % A 输出结果 0 |
| ++ | 自增 | A++ 输出结果 11 |
| -- | 自减 | A-- 输出结果 9 |
a := 10 b := 2 sum := a + b fmt.Printf("%d + %d=%d\n", a, b, sum) sub := a - b fmt.Printf("%d - %d=%d\n", a, b, sub) mod := a % b fmt.Printf("%d %% %d = %d \n", a, b, mod)
注意格式化输出时,%是占位符,若想输出取余%需要在取余%前加占位%,即%%
1.2 关系运算符
关系运算符的结果总是布尔类型true或false
| == | 检查两个值是否相等,如果相等返回 True 否则返回 False。 | (A == B) 为 False |
| != | 检查两个值是否不相等,如果不相等返回 True 否则返回 False。 | (A != B) 为 True |
| > | 检查左边值是否大于右边值,如果是返回 True 否则返回 False。 | (A > B) 为 False |
| < | 检查左边值是否小于右边值,如果是返回 True 否则返回 False。 | (A < B) 为 True |
| >= | 检查左边值是否大于等于右边值,如果是返回 True 否则返回 False。 | (A >= B) 为 False |
| <= | 检查左边值是否小于等于右边值,如果是返回 True 否则返回 False。 | (A <= B) 为 True |
a := 1 b := 2 res := a >= b fmt.Printf("类型:%T,值:%t", res, res) //类型:bool,值:false
1.3 逻辑运算符
go预言中或是短路或,与是短路与
| && | 逻辑 AND 运算符。 如果两边的操作数都是 True,则条件 True,否则为 False。 | (A && B) 为 False |
| || | 逻辑 OR 运算符。 如果两边的操作数有一个 True,则条件 True,否则为 False。 | (A || B) 为 True |
| ! | 逻辑 NOT 运算符。 如果条件为 True,则逻辑 NOT 条件 False,否则为 True。 | !(A && B) 为 True |
1.4 位运算符
计算机中只识别二进制0或1,而位运算符是针对二进制位操作的。
假定 A = 60; B = 13
0011 1100 0000 1101
| & | 按位与运算符"&"是双目运算符。 其功能是参与运算的两数各对应的二进位相与。对应位都是1才是1 | (A & B) 结果为 12, 二进制为 0000 1100 |
| | | 按位或运算符"|"是双目运算符。 其功能是参与运算的两数各对应的二进位相或。对应位有一个是1就是1 | (A | B) 结果为 61, 二进制为 0011 1101 |
| ^ | 按位异或运算符"^"是双目运算符。 其功能是参与运算的两数各对应的二进位相异或,当两对应的二进位相异时,结果为1。对应位不同才是1 | (A ^ B) 结果为 49, 二进制为 0011 0001 |
| &^ | 位清空,a &^ b,两个数运算时,b的位为1取0,为0时取a对应的位值 | (a &^ b)结果为48, 二进制为0011 0000 |
| << | 左移运算符"<<"是双目运算符。左移n位就是乘以2的n次方。 其功能把"<<"左边的运算数的各二进位全部左移若干位,由"<<"右边的数指定移动的位数,高位丢弃,低位补0。 | A << 2 结果为 240 ,二进制为 1111 0000 |
| >> | 右移运算符">>"是双目运算符。右移n位就是除以2的n次方。 其功能是把">>"左边的运算数的各二进位全部右移若干位,">>"右边的数指定移动的位数。 | A >> 2 结果为结果为15,二进制为 0000 1111 |
a := 15 res := a >> 2 fmt.Printf(":%d,二进制:%b\n", a, a) //15,值:0000 1111 fmt.Printf(":%d,二进制:%b\n", res, res) //3,二进制:0000 0011(其中11已经被右移去掉)
1.5 赋值运算符
| = | 简单的赋值运算符,将一个表达式的值赋给一个左值 | C = A + B 将 A + B 表达式结果赋值给 C |
| += | 相加后再赋值 | C += A 等于 C = C + A |
| -= | 相减后再赋值 | C -= A 等于 C = C - A |
| *= | 相乘后再赋值 | C *= A 等于 C = C * A |
| /= | 相除后再赋值 | C /= A 等于 C = C / A |
| %= | 求余后再赋值 | C %= A 等于 C = C % A |
| <<= | 左移后赋值 | C <<= 2 等于 C = C << 2 |
| >>= | 右移后赋值 | C >>= 2 等于 C = C >> 2 |
| &= | 按位与后赋值 | C &= 2 等于 C = C & 2 |
| ^= | 按位异或后赋值 | C ^= 2 等于 C = C ^ 2 |
| |= | 按位或后赋值 | C |= 2 等于 C = C | 2 |
a := 15 a <<= 2 fmt.Printf("%d,值:%b\n", a, a) //类型:60,值:111100
1.6 其他运算符
| & | 返回变量存储地址 | &a; 将给出变量的实际地址。 |
| * | 指针变量。 | *a; 是一个指针变量 |
a := 15 var ptr *int = &a fmt.Printf("类型:%T,值:%d\n", ptr, *ptr) //类型:*int,值:15
2、运算符优先级
| 7 | ! ++ -- | 逻辑运算符、算数运算符 |
| 6 | * / % << >> & &^ | 算数运算符、位运算符 |
| 5 | + - | ^ | 算数运算符、位运算符 |
| 4 | == != < <= > >= | 赋值运算符、关系运算符 |
| 3 | <- | 通道操作运算符 |
| 2 | && | 逻辑运算符 |
| 1 | || | 逻辑运算符 |
【三】流程控制
程序的流程控制结构分三种:
顺序结构:从上向下,逐行执行
选择结构:条件满足才会执行,如分支语句if、switch、select
循环结构:条件满足后反复执行,如for
1、条件语句if....else if ....else
1.1 算术运算符
注:if 和左花括号{必须在同一行.右花括号}必须和else if在同一行.else if不能合并写
var score int
fmt.Println("请输入数值")
fmt.Scanln(&score)
if score > 90 {
fmt.Println("优")
} else if score > 80 {
fmt.Println("良")
} else {
fmt.Println("加油")
}
if语句其他写法if statement;condition{ ....}
statement一般做变量声明,但此变量作用域只能在if语句块内访问
if score := 92;score > 90 { //声明并初始化score变量,但它的作用域只局限于if语句块 fmt.Println(score,"优") //可访问score } else { fmt.Println(score,"加油") //可访问score } fmt.Println(score) //不可访问score
1.2 switch
break;强制结束case语句。fallthrough强制穿透,当某个case匹配以后,下一个case无需匹配,直接穿透执行。
如果省略switch后变量,相当于直接作用在true上,case语句可以使用表达式
score := 81
switch {
case score > 90:
fmt.Println("优秀")
case score > 80 :
fmt.Println("良好")
fallthrough
case score > 60 :
fmt.Println("及格")
default:
fmt.Println("有待提高")
}
输出良好、及格
1.3 for
语法:for 表达式1;表达式2;表达式3 {...}
go里面没有while,for 表达式2 {.....},就相当于while 表达式 {......}
for {.....} 就相当于while true {......}
for i := 0;i < 5; i++ { fmt.Println(i) } i := 0 for i< 5 { fmt.Println(i) i++ }
continue和break控制跳出循环,如果是多层循环,可以使用标签形式跳出内层循环
loop: for i := 1;i <= 9; i++ { for j := 1; j<=i;j++ { if j == 2 { break loop } fmt.Printf("%d x %d = %d\t", i, j, i*j) } fmt.Println() }
1.4 goto
语法:
goto label
....
label: statement
for i := 1;i <= 9; i++ { if i == 2 { goto onError } fmt.Println(i) } onError: fmt.Println("非法值")
输入 1 非法值
参考:
Go语言流程控制
http://c.biancheng.net/golang/flow_control/
------------恢复内容结束------------

 浙公网安备 33010602011771号
浙公网安备 33010602011771号