因为之前学习并使用了Kafka,所以专门查看了有关zookeeper相关的资料,看了大量的博客及官网资料,也因为有些地方理解不清楚向认识的专业人士进行了咨询,这里对这段时间的学习进行总结。
ZooKeeper特性
顺序性,client的updates请求都会根据它发出的顺序被顺序的处理;
原子性, 一个update操作要么成功要么失败,没有其他可能的结果;
一致的镜像,client不论连接到哪个server,展示给它都是同一个视图;
可靠性,一旦一个update被应用就被持久化了,除非另一个update请求更新了当前值
实时性,对于每个client它的系统视图都是最新的
ZooKeeper集群
有关Zookeeper的集群,这里要引用官网的一张图
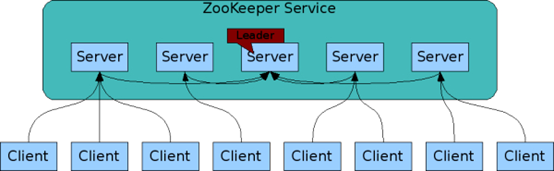
对上面这张图的各角色的描述如下

上面这张图需要重点说明的有如下几点:
1、 Zookeeper集群的读写模式采用的是写任意。即不论是Leader还是Follower还是Observe均能接收到写请求,但是Follower和Observe会把写请求转发给Leader。
这个地方的理解可能有点拗,就是所有Zookeeper Server只响应来自Leader的写请求,如果不是Leader发起的就先转发给Leader。为什么这么做可以参考下面的数据一致性。
2、 所谓集群,对外来说就是一个整体,上面Client与Server的链接均为通过负载均衡获取。
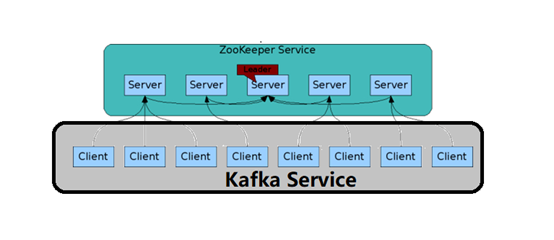
3、 对于kafka而言,每一个Broker服务就是上图中的Client。如果kafka也采用集群的方式,上面的图就应该变成下面这样。
数据一致性
对于任何一个Client,不论你连接的是Zookeeper集群的哪个Server,得到的都是同一个数据视图。
Zookeeper集群最大一个特点就是解决分布式一致性问题。简单讲,数据一致性就是指在对一个副本数据进行更新的同时,必须确保也能更新其他副本(其他副本可能在各个不同的服务器节点),否则不同副本之间的数据将不再一致。
ZooKeeper是如何做到这一点的,就是采用了paxos算法。
过程详解:
1 ,客户端发请求:执行 Client 程序,比如说,我们连接到的是 follower,那么我们就跟 follower 说,我要新增一条数据。
2 ,上报:follower 是没有权利进行事务性操作的( 增,删,改,都属于事务性操作 ),follower 把请求上报给 leader 。
3 ,广播:leader 将新增数据的消息发送给集群中的所有节点。
4 ,过半数成功原则:如果一半以上的机器新增数据成功,那么就认为数据已经新增成功了,将新增成功的结果发送给接受请求的 follower。
5 ,响应:follower 告诉 Cleint 客户端,新增成功
其余的知识点这里就不写了,可以通过下面几篇博客来参考。
Zookeeper的功能以及工作原理https://www.cnblogs.com/felixzh/p/5869212.html
ZooKeeper学习第一期---Zookeeper简单介绍https://www.cnblogs.com/sunddenly/p/4033574.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号