一个增量文本聚类的方法
我们最近在做一个 AI Video Editor 网站, 其中我们有一个分析相似的视频脚本的能力,我们叫 Best Viral Video Hook.
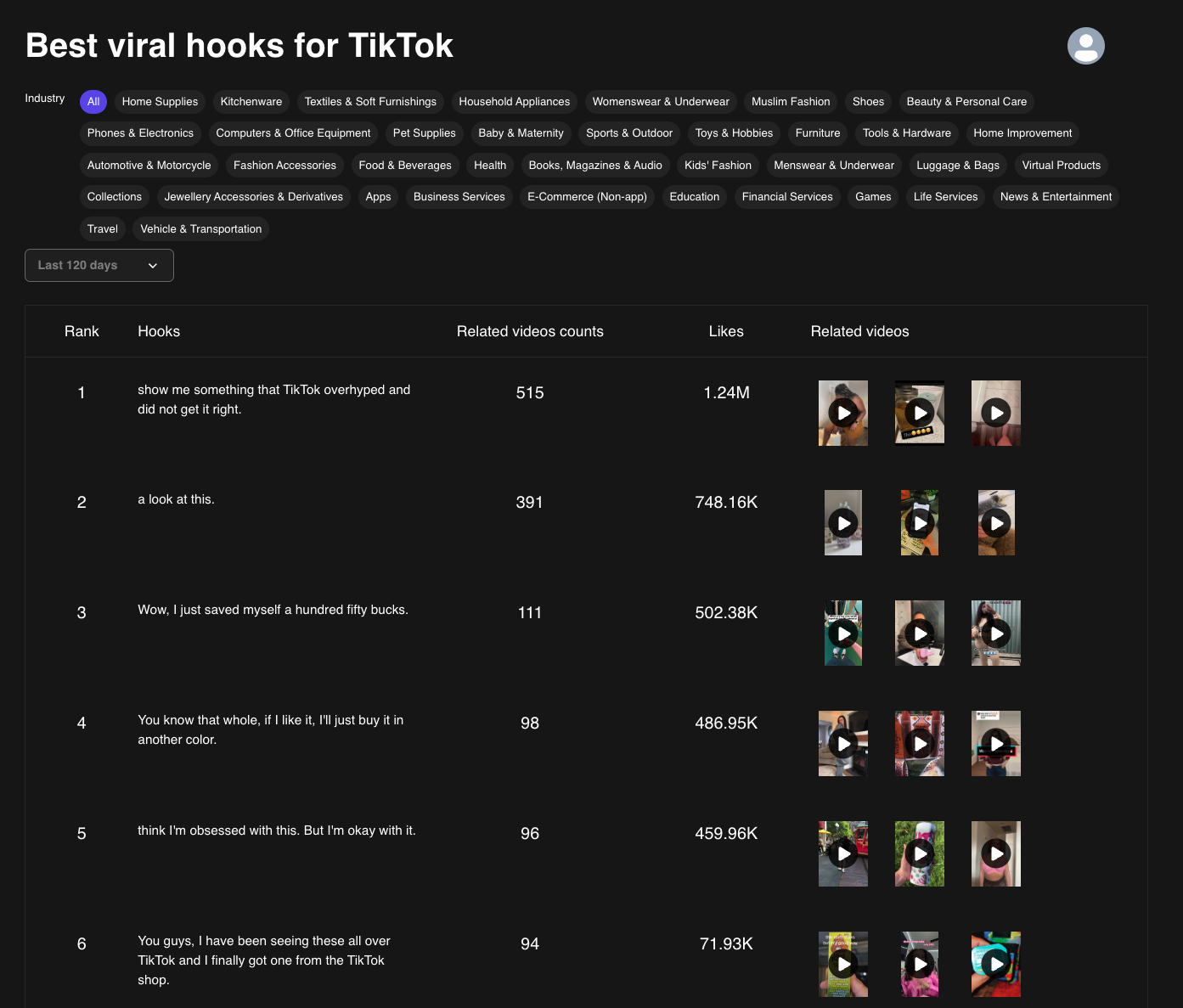
这里面有一个命题:我们只希望针对新增的文本进行聚类,而且不能改变旧的文本分类。
所以我们做了一个这样子的算法:
- 使用LLM的Embedding,对每一个文本进行Embedding;
- 使用AnnoyIndex做向量搜索;把相似度大于某个值的脚本认为是同一个分类。
- 保存所有数目大于2的分类。
每天进行新增的文本聚类的时候,
- 把新增的文本的embedding加入AnnoyIndex
- 将之前所有数目大于2的分类都重新找一遍,如果新的文本,在旧的分类里面,则直接归入旧的分类;
- 把新文本,没有聚类的,全部重新聚类一次;如果找到2个或以上的相似文本,则找到这组的文本最小ID,用这个ID的embedding重新找一次,用最小ID作为组的ID
这样子我们就用AnnoyIndex做了一个增量的聚类算法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号