spark+scala配置及一个初始化项目
内容
选择这些版本是考虑到版本的稳定性
- spark2.4.5
- Hadoop2.7.7
- jdk1.8
- scala与spark对应版本(不需要安装)
对于hadoop和spark的安装主要参考这两篇
https://blog.csdn.net/qq_37833810/article/details/88185476
https://blog.csdn.net/qq_37833810/article/details/88188801?spm=1001.2014.3001.5502
之后就可以创建出第一个项目了
- 先创建一个普通的maven项目(记得在Intellij idea中先安装对应的scala插件)
![image]()
- 添加项目架构
![image]()
- 选择对应的scala结构
![image]()

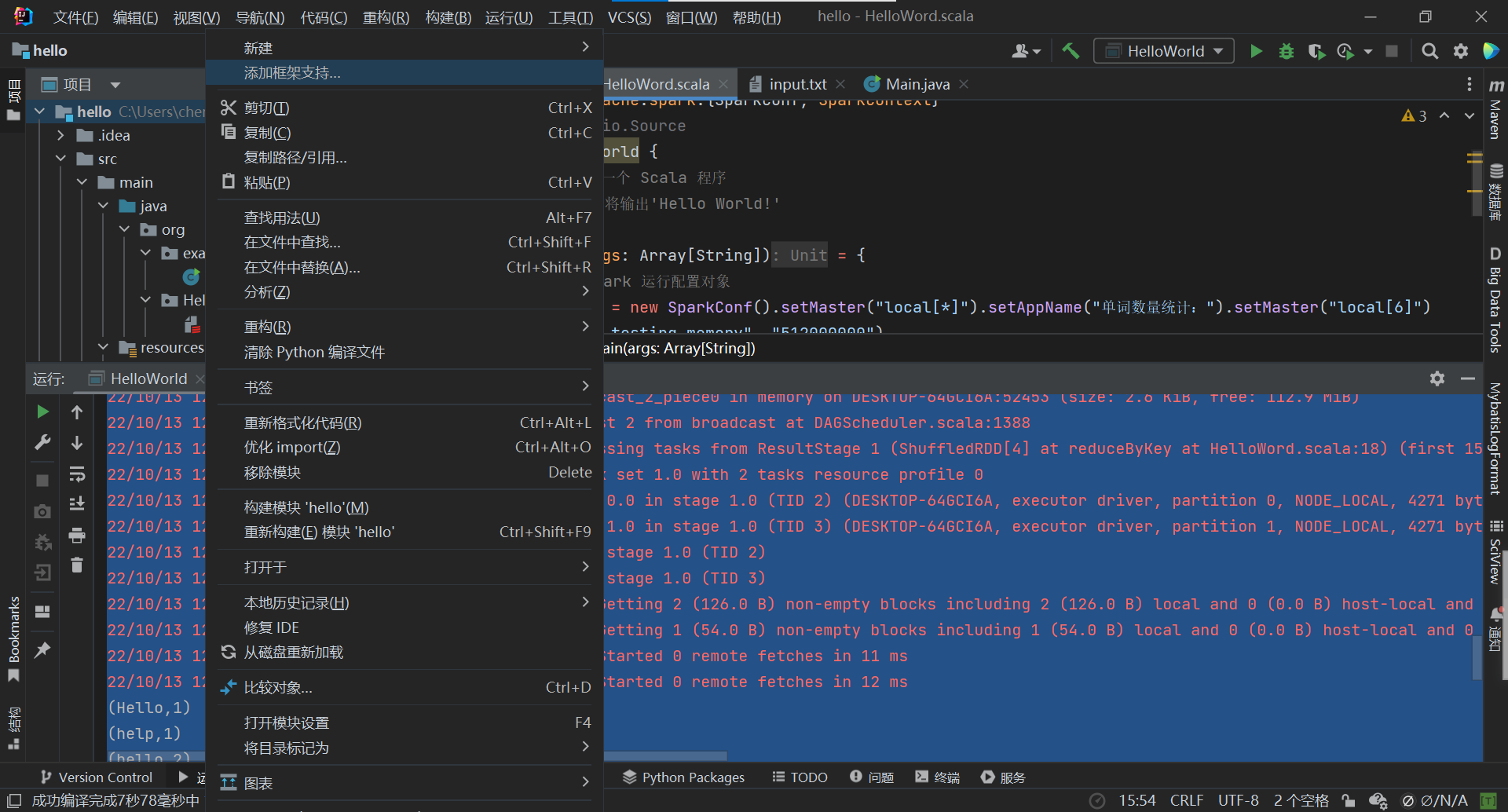
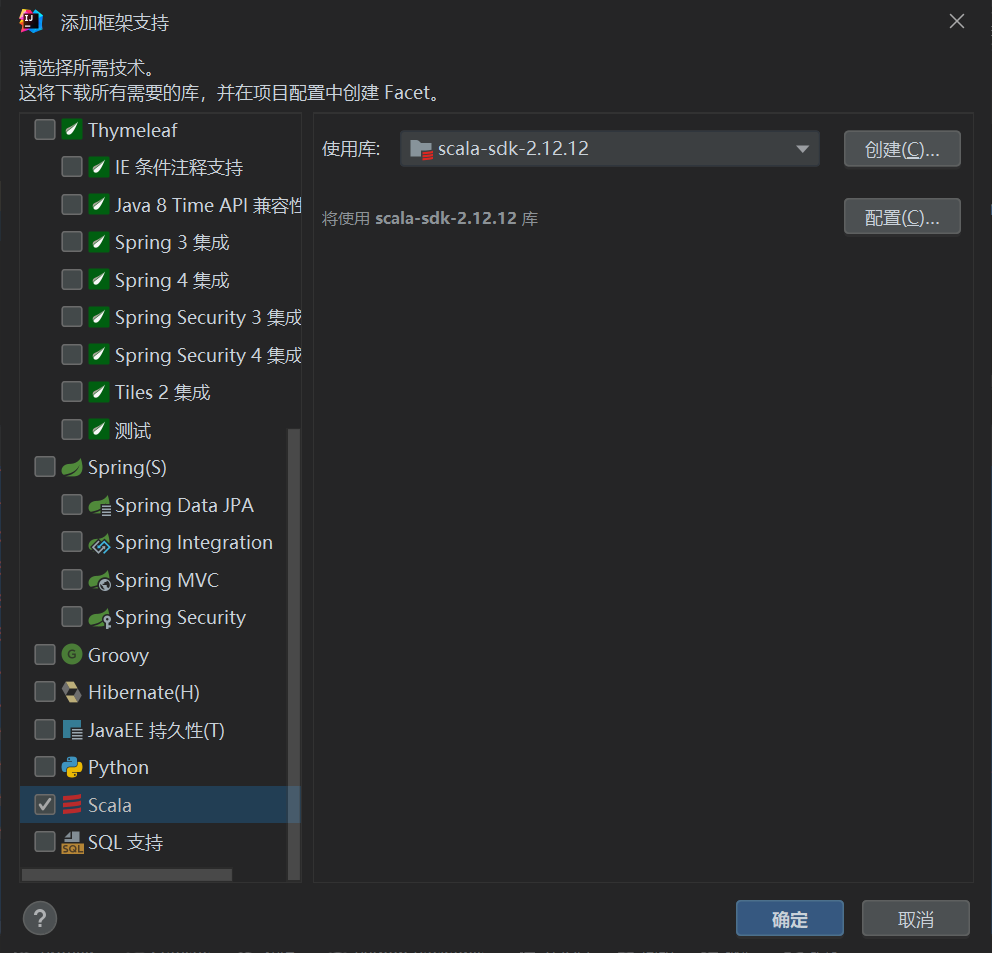
在版本的控制中需要参考不同版本的spark项目对应的scala版本,然后就正常识别运行了
项目结构
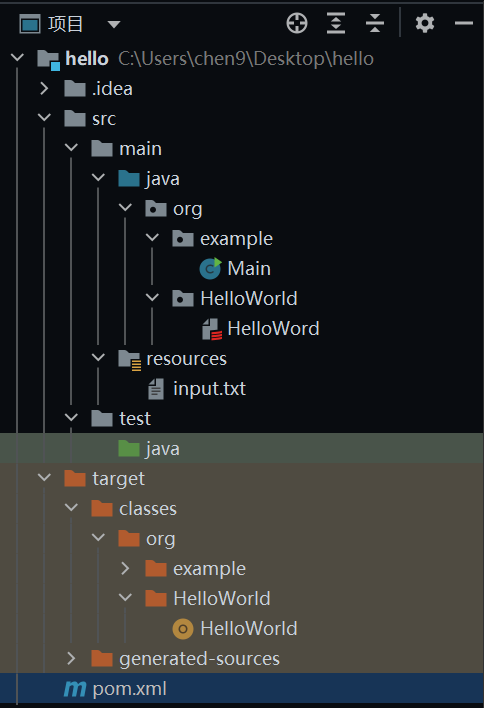
代码
这是一个简单的词汇统计的代码
- 先在对应的pom文件中添加对应的依赖
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.1.2</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.1.2</version>
<!-- <scope>provided</scope>-->
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-mllib -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.12</artifactId>
<version>3.1.2</version>
<scope>provided</scope>
</dependency>
</dependencies>
- 在文件中添加对应的java文件
package org.HelloWorld
import org.apache.spark.{SparkConf, SparkContext}
import scala.io.Source
object HelloWorld {
def main(args: Array[String]) = {
// 创建 Spark 运行配置对象
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("单词数量统计:").setMaster("local[6]")
.set("spark.testing.memory", "512000000")
// 创建 Spark 上下文环境对象(连接对象)
val sc = new SparkContext(sparkConf)
val lines = sc.textFile("src/main/resources/input.txt")
val pairs = lines.flatMap(s => s.split("\\b"))
.map(w => (w, 1))
val counts = pairs.reduceByKey((a, b) => a + b)
counts.foreach(println)
}
}
然后经过一小段时间的编译后就可以看到结果了
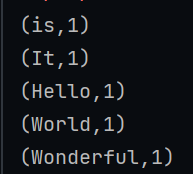
意外情况
在配置hadoop和spark完成后,发现一个报错信息
WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
找了很多博客也没找到结果,但是后来发现其实也不影响程序运行

 浙公网安备 33010602011771号
浙公网安备 33010602011771号