
数据结构
定义
我国的大学从1970年左右开始讲授数据结构,数据结构是什么?并没有一个统一的定义,一般认为研究数据元素,数据元素之间的关系及其操作的一门学科。其他一些概念,如数据对象表示多个数据元素,可理解为子集的概念。
在我们学习的高级程序语言设计中,设置了很多的数据类型,这些数据类型是经过一定抽象的,在硬件层面也有自己的数据类型。在数据结构课程中,我们使用抽象数据类型,抽象数据类型可以简单理解为数据类型,它通过数据元素、数据元素之间的关系、运算来完整表述。在我们定义一个抽象数据类型时候,只要数学特性保持不变,外面的模块对这个变化就是无感知的。个人理解,数据结构是元素和关系(D,S);抽象数据类型是元素和关系和运算(D,S,P)。
抽象数据类型的设计 -> 讨论逻辑结构;抽象数据类型的表示和实现 -> 讨论物理(存储)结构。例如有序表是逻辑结构,顺序表是存储结构。
算法的(渐近)时间复杂度,T(n)=O(f(n)),T(n)可以看作是基本语句的频度,可以直接代入不等式求解。
线性表
顺序表插入平均移动元素次数n/2,删除的平均移动次数(n-1)/2。
若以线性表表示集合并进行集合的各种运算,应先对表中元素进行排序。
1 索引结构与散列技术(+顺序存储、链式存储是四种基本的存储结构)
1.1 索引结构
索引存储时需要建立索引表和数据表,从数据表的各个记录中抽取关键字建立索引表,索引表是有序排列的,数据表中的各个记录不要求有序。如果每条记录都对应一条索引,那么这样的索引称为稠密索引。通常来讲,一个索引对应一块数据,数据是分块有序的,取每块有序的分块中最大关键字建立索引表。数据查找某个关键字key时,先在索引表中找到第一个超过key的关键字,然后找到该关键字对应的分块的起始地址,第二步,在该分块中进行顺序查找,直至找到或者找不到。索引查找的性能介于顺序查找和二分查找之间。
多级索引,当单个索引表过大,在内存中无法存放时,可以继续向上建立二级索引、三级索引等。一般而言,只有最上层的索引在内存中,下层的索引以及数据都需要访问外存。所以通过建立m叉树的方式,减少索引层级,减少访问外存的次数。多级索引仍然是一种静态索引结构,当数据变化时,索引变动较大。可以采用树表这种动态索引的方式。
1.2 散列技术
元素个数是n,表长是m,负载因子α=n/m,一般α值的范围是0.65~0.9,可以通过元素个数计算合适的表长。散列需要选择合适的散列(哈希)函数,使不同的元素尽可能计算出不同的函数值。除留法是一种方法,通常选取不超过表长的最大质数作为余数。解决冲突有两种方法,开放寻址法和拉链法。
2 静态查找表(实现search方法)
2.1 顺序表
从后往前查找,位置从1开始,可以将第0位置设置为需要查找的key,作为哨兵,避免了不断做位置的比较,检查表有没有遍历完成,这种方式可以提高一倍的查找性能。
一般我们说,查找成功的平均查找长度,查找不成功的比较次数(可以认为是n+1次,0为哨兵位置)。在查找成功的情况下,如果需要查找的记录等概率出现,那么平均查找长度是(n+1)/2,如果在非等概率的情况下,我们从后往前访问,可以有两种优化方式:1、每条记录增加查找频数,按照频数排序整张表 2、最近查找的记录总是移动到表的最后面。
2.2 有序表
采用二分查找,mid=(low+high)/2,每次比较查找的key和mid位置的元素,如果相等,查找成功,否则更新low为mid+1或者high为mid-1。查找失败的终止条件是区间长度小于0,即low>high。
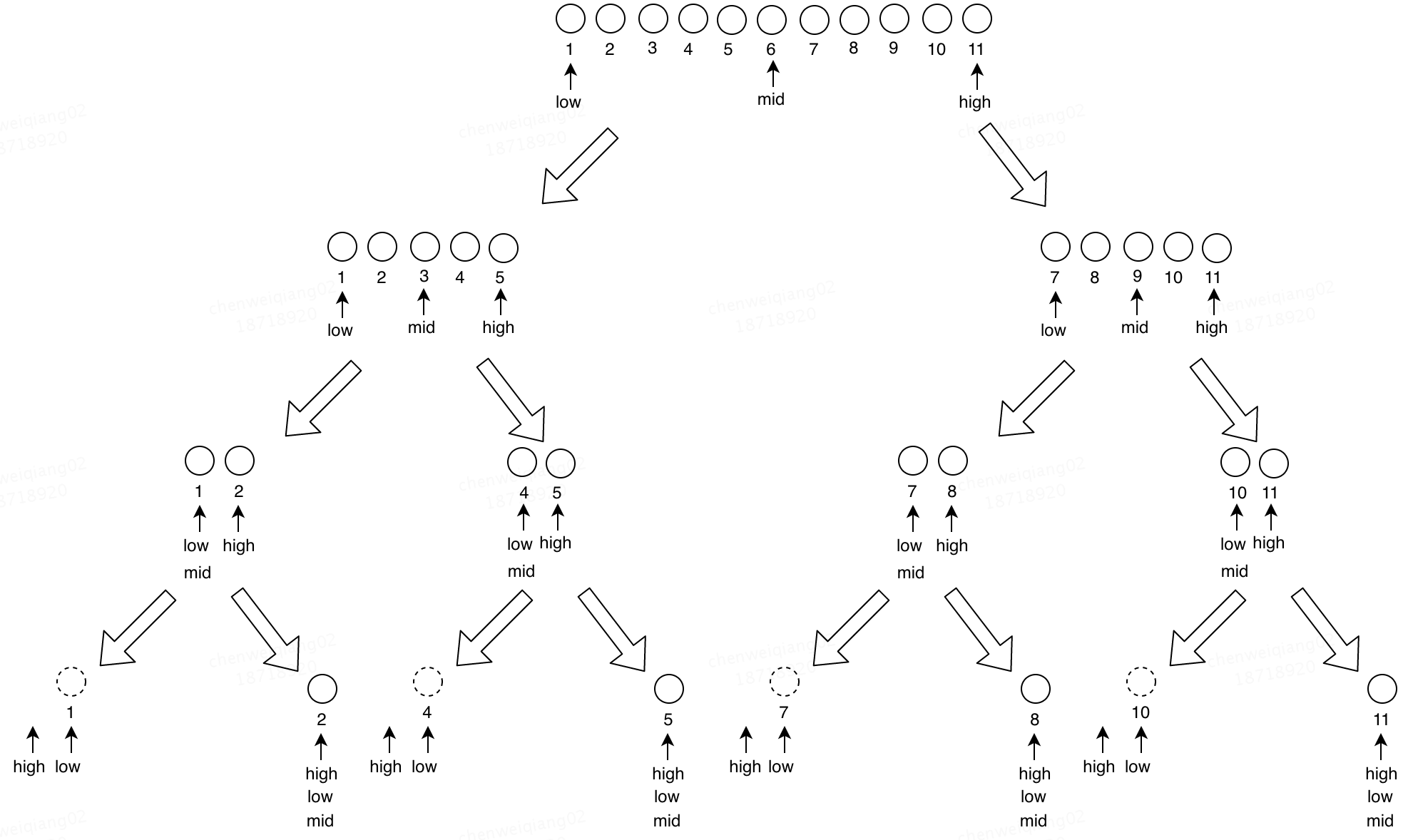
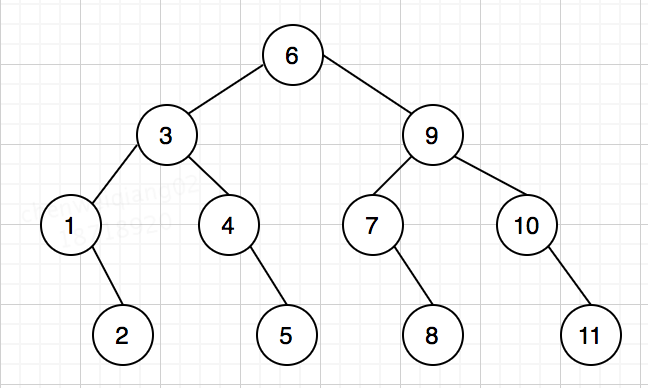
生成的判定树简化后如下(如果元素个数是2h-1,那么刚好生成高度为h的满二叉树):

 浙公网安备 33010602011771号
浙公网安备 33010602011771号