Redis 数据存储格式
- redis自身是一个Map类型的存储方式,其中所有的数据都是采用key:value的形式存储
- 我们讨论的数据类型指的是存储的数据的类型,也就是value部分的类型,key部分永远都是字符串
使用场景
- 字符串:用的最多,做缓存;做计数器
- 列表: 简单的消息队列
- 字典(hash):缓存
- 集合:去重
- 有序集合:排行榜
String类型
-
存储的数据:单个数据,是最简单的数据存储类型,也是最常用的数据存储类型
-
存储数据的格式:一个name对应一个value来存储
-
存储内容:通常使用字符串,如果字符串以整数的形式展示,可以作为数字操作使用(但是仍是字符串)
String操作
import redis
conn = redis.Redis()
1.set(name, value, ex=None, px=None, nx=False, xx=False)
# 在Redis中设置值,默认,不存在则创建,存在则修改
# 参数:
# ex,过期时间(秒)
# px,过期时间(毫秒)
# nx,如果设置为True,则只有name不存在时,当前set操作才执行,值存在,就修改不了,执行没效果
# xx,如果设置为True,则只有name存在时,当前set操作才执行,值存在才能修改,值不存在,不会设置新值
conn.set('hobby','篮球',ex=3)
conn.set('hobby','篮球',px=3)
conn.set('name','lqz',nx=True)
conn.set('name','lqz',nx=False)
conn.set('hobby','篮球',xx=True)
conn.set('hobby','篮球',xx=False)
# redis---》实现分布式锁,底层基于nx实现的
2.setnx(name, value)
# 设置值,只有name不存在时,执行设置操作(添加),如果存在,不会修改
# 等同于:conn.set('name','xxx',nx=True)
conn.setnx('name', '刘亦菲')
3.setex(name, time, value)
# 设置值
# 参数:
# time,过期时间(数字秒 或 timedelta对象)
conn.setex('age', 3, '19')
# 等同于:conn.set('age','19',ex=3)
4.psetex(name, time_ms, value)
# 设置值
# 参数:
time_ms,过期时间(数字毫秒 或 timedelta对象
conn.psetex('name',3000,'刘亦菲')
5.mset(*args, **kwargs)
# 批量设置值
# 如:
mset(k1='v1', k2='v2')
或
mget({'k1': 'v1', 'k2': 'v2'})
conn.mset({'name': '刘亦菲', 'hobby': '篮球'})
6.get(name)
# 获取值
print(str(conn.get('name'),encoding='utf-8'))
print(conn.get('name'))
7.mget(keys, *args)
# 批量获取
# 如:
mget('k1', 'k2')
或
r.mget(['k3', 'k4'])
res=conn.mget('name','hobby')
res=conn.mget(['name','hobby'])
print(res)
8.getset(name, value)
# 设置新值并获取原来的值
res=str(conn.getset('name','迪丽热巴'),encoding='utf-8')
res=conn.getset('name','迪丽热巴')
print(res)
9.getrange(key, start, end)
# 获取子序列(根据字节获取,非字符)
# 参数:
# name,Redis 的 name
# start,起始位置(字节)
# end,结束位置(字节)
# 如: "迪丽热巴" ,0-3表示 "迪"
res = str(conn.getrange('hobby', 0, 2), encoding='utf-8') # 字节长度,不是字符长度 前闭后闭区间
print(res)
10.setrange(key, start, end)
# 修改字符串内容,从指定字符串索引开始向后替换(新值太长时,则向后添加)
# 参数:
# offset,字符串的索引,字节(一个汉字三个字节)
# value,要设置的值
conn.setrange('name',2,'bbb')
11.setbit(name, offset, value)
# 对name对应值的二进制表示的位进行操作
# 参数:
# name,redis的name
# offset,位的索引(将值变换成二进制后再进行索引)
# value,值只能是 1 或 0
# 注:如果在Redis中有一个对应: n1 = "foo",
那么字符串foo的二进制表示为:01100110 01101111 01101111
所以,如果执行 setbit('n1', 7, 1),则就会将第7位设置为1,
那么最终二进制则变成 01100111 01101111 01101111,即:"goo"
12.getbit(name, offset)
# 获取name对应的值的二进制表示中的某位的值 (0或1)
13.bitcount(key, start=None, end=None)
# 获取name对应的值的二进制表示中 1 的个数
# 参数:
key,Redis的name
start,位起始位置
end,位结束位置
14.bitop(operation, dest, *keys)
# 获取多个值,并将值做位运算,将最后的结果保存至新的name对应的值
# 参数:
# operation,AND(并) 、 OR(或) 、 NOT(非) 、 XOR(异或)
# dest, 新的Redis的name
# *keys,要查找的Redis的name
# 如:
bitop("AND", 'new_name', 'n1', 'n2', 'n3')
# 获取Redis中n1,n2,n3对应的值,然后讲所有的值做位运算(求并集),然后将结果保存 new_name 对应的值中
15.strlen(name)
# 返回name对应值的字节长度(一个汉字3个字节)
res=conn.strlen('hobby') # 统计字节长度
print(res)
16.incr(self, name, amount=1)
# 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。
# 参数:
# name,Redis的name
# amount,自增数(必须是整数)
conn.incr('age')
# 注:同incrby
17.incrbyfloat(self, name, amount=1.0)
# 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。
# 参数:
# name,Redis的name
# amount,自增数(浮点型)
conn.incrbyfloat('age',1.2)
18.decr(self, name, amount=1)
# 自减 name对应的值,当name不存在时,则创建name=amount,否则,则自减。
# 参数:
# name,Redis的name
# amount,自减数(整数)
conn.decrby('age')
conn.decrby('age',-1)
19.append(key, value)
# 在redis name对应的值后面追加内容
# 参数:
# key, redis的name
# value, 要追加的字符串
conn.append('name','yyds')
conn.close()
需要记住的string操作
1 set
2 get
3 strlen # 字节长度
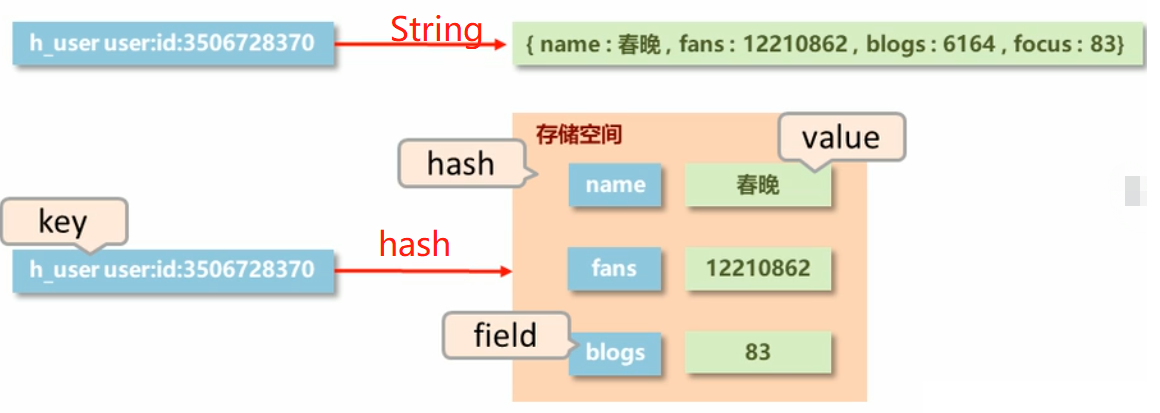
hash类型
- 对象类数据的存储如果具有较为频繁的更新需求,String操作会显得笨重,存容易,改麻烦。
- 为了区别与Redis中的键值对的称呼,hash中的键成为field,而key特指Redis的键。
- 新的存储需求:对一系列存储的数据进行编组,方便管理,典型应用存储对象信息
- 需要的内存结构:一个存储空间保存多少个键值对数据
- hash类型:底层使用哈希表结构实现数据存储
hash基本操作
import redis
conn = redis.Redis()
1.hset(name, key, value)
# name对应的hash中设置一个键值对(不存在,则创建;否则,修改)
# 参数:
# name,redis的name
# key,name对应的hash中的key
# value,name对应的hash中的value
# 注:
# hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)
conn.hset('userinfo','name','lqz')
conn.hset('userinfo',mapping={'age':19,'hobby':'篮球'})
2.hmset(name, mapping)
# 在name对应的hash中批量设置键值对,被弃用了,以后都使用hset
3.hget(name,key)
# 在name对应的hash中获取根据key获取value
res=conn.hget('userinfo','name')
print(res)
4.hmget(name, keys, *args)
# 参数:
# name,reids对应的name
# keys,要获取key集合,如:['k1', 'k2', 'k3']
# *args,要获取的key,如:k1,k2,k3
res=conn.hmget('userinfo',['name','age'])
res = conn.hmget('userinfo', 'name', 'age')
print(res)
5.hgetall(name)
# 获取name对应hash的所有键值
print(re.hgetall('xxx').get(b'name'))
6.hlen(name)
# 获取name对应的hash中键值对的个数
res=conn.hlen('userinfo')
print(res)
7.hkeys(name)
# 获取name对应的hash中所有的key的值
res=conn.hkeys('userinfo')
print(res)
8.hvals(name)
# 获取name对应的hash中所有的value的值
res=conn.hvals('userinfo')
print(res)
9.hexists(name, key)
# 检查name对应的hash是否存在当前传入的key
res = conn.hexists('userinfo', 'name')
res = conn.hexists('userinfo', 'name1')
print(res)
10.hdel(name,*keys)
# 将name对应的hash中指定key的键值对删除
print(re.hdel('xxx','sex','name'))
res = conn.hdel('userinfo', 'age')
print(res)
11.hincrby(name, key, amount=1)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
# 参数:
# name,redis中的name
# key, hash对应的key
# amount,自增数(整数)
conn.hincrby('userinfo', 'age', 2)
12.hincrbyfloat(name, key, amount=1.0)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
# 参数:
# name,redis中的name
# key, hash对应的key
# amount,自增数(浮点数)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
# hgetall 会一次性全取出,效率低,可以能占内存很多
# 分批获取,hash类型是无序
# 插入一批数据
for i in range(1000):
conn.hset('hash_test','id_%s'%i,'鸡蛋_%s号'%i)
res=conn.hgetall('hash_test') # 可以,但是不好,一次性拿出,可能占很大内存
print(res)
13.hscan(name, cursor=0, match=None, count=None)
# 增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而放置内存被撑爆
# 参数:
# name,redis的name
# cursor,游标(基于游标分批取获取数据)
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
# 如:
# 第一次:cursor1, data1 = r.hscan('xx', cursor=0, match=None, count=None)
# 第二次:cursor2, data1 = r.hscan('xx', cursor=cursor1, match=None, count=None)
# ...
# 直到返回值cursor的值为0时,表示数据已经通过分片获取完毕
res = conn.hscan('hash_test', cursor=0, count=5)
print(len(res[1])) #(数字,拿出来的10条数据) 数字是下一个游标位置
14.hscan_iter(name, match=None, count=None)
# 利用yield封装hscan创建生成器,实现分批去redis中获取数据
# 参数:
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数
res=conn.hscan_iter('hash_test',count=10)
print(res) # generator 只要函数中有yield关键字,这个函数执行的结果就是生成器 ,生成器就是迭代器,可以被for循环
# for i in res:
# print(i)
conn.close()
需要记住的hash操作
1 hset
2 hget
3 hmget
4 hlen
5 hdel
6 hscan_iter # 获取所有值,但是省内存 等同于hgetall
List类型
- 数据存储需求:存储多个数据,并对数据进入存储空间的顺序进行区分
- 需要的存储数据:一个存储空间保存多个数据,且通过数据可以体现进入顺序
- list类型:保存多个数据,底层使用双向链表存储结构实现
List操作
import redis
conn = redis.Redis()
1.lpush(name,values)
# 在name对应的list中添加元素,每个新的元素都添加到列表的最左边
# 如:
# r.lpush('oo', 11,22,33)
# 保存顺序为: 33,22,11
conn.lpush('girls', '刘亦菲', '迪丽热巴')
conn.lpush('girls', '周淑怡')
2.rpush(name, values) 表示从右向左操作
conn.rpush('girls', '小红')
3.lpushx(name,value)
# 在name对应的list中添加元素,只有name已经存在时,值添加到列表的最左边
conn.lpushx('boys','小刚')
conn.lpush('boys','小刚')
conn.lpushx('girls','小刚')
4.rpushx(name, value) 表示从右向左操作
5.llen(name)
# name对应的list元素的个数
res = conn.llen('girls')
print(res)
6.linsert(name, where, refvalue, value))
# 在name对应的列表的某一个值前或后插入一个新值
# 参数:
# name,redis的name
# where,BEFORE或AFTER(小写也可以)
# refvalue,标杆值,即:在它前后插入数据(如果存在多个标杆值,以找到的第一个为准)
# value,要插入的数据
conn.linsert('girls','before','迪丽热巴','古力娜扎')
conn.linsert('girls', 'after', '小红', '小绿')
conn.linsert('girls', 'after', '小黑', '小嘿嘿') # 没有标杆,插入不进去
7.lset(name, index, value)
# 对name对应的list中的某一个索引位置重新赋值
# 参数:
# name,redis的name
# index,list的索引位置
# value,要设置的值
conn.lset('girls',1,'xxx')
8.lrem(name, value, num)
# 在name对应的list中删除指定的值
# 参数:
# name,redis的name
# value,要删除的值
# num, num=0,删除列表中所有的指定值;
# num=2,从前到后,删除2个;
# num=-2,从后向前,删除2个
conn.lrem('girls',1,'xxx') # 从左侧开始,删除1个
conn.lrem('girls',-1,'xxx') # 从右侧开始,删除1个
conn.lrem('girls',0,'xxx') # 从左开始,全删除
9.lpop(name)
# 在name对应的列表的左侧获取第一个元素并在列表中移除,返回值则是第一个元素
res=conn.lpop('girls')
print(res)
10.rpop(name) 表示从右向左操作
11.lindex(name, index)
# 在name对应的列表中根据索引获取列表元素
res = str(conn.lindex('girls', 1), encoding='utf-8')
print(res)
12.lrange(name, start, end)
# 在name对应的列表分片获取数据
# 参数:
# name,redis的name
# start,索引的起始位置
# end,索引结束位置
res=conn.lrange('girls',0,2) # 前闭后闭区间
print(res)
13.ltrim(name, start, end)
# 在name对应的列表中移除没有在start-end索引之间的值
# 参数:
# name,redis的name
# start,索引的起始位置
# end,索引结束位置(大于列表长度,则代表不移除任何)
conn.ltrim('girls',2,3)
14.rpoplpush(src, dst)
# 从一个列表取出最右边的元素,同时将其添加至另一个列表的最左边
# 参数:
# src,要取数据的列表的name
# dst,要添加数据的列表的name
15.blpop(keys, timeout)
# 将多个列表排列,按照从左到右去pop对应列表的元素
# 参数:
# keys,redis的name的集合
# timeout,超时时间,当元素所有列表的元素获取完之后,阻塞等待列表内有数据的时间(秒), 0 表示永远阻塞
res=conn.blpop('boys')
print(res)
16.brpop(keys, timeout),从右向左获取数据
"""
爬虫实现简单分布式:多个url放到列表里,往里不停放URL,程序循环取值,但是只能一台机器运行取值,可以把url放到redis中,多台机器从redis中取值,爬取数据,实现简单分布式
"""
17.brpoplpush(src, dst, timeout=0)
# 从一个列表的右侧移除一个元素并将其添加到另一个列表的左侧
# 参数:
# src,取出并要移除元素的列表对应的name
# dst,要插入元素的列表对应的name
# timeout,当src对应的列表中没有数据时,阻塞等待其有数据的超时时间(秒),0 表示永远阻塞
conn.close()
需要记住的list操作
1 lpush
2 lpop
3 llen
4 lrange



 浙公网安备 33010602011771号
浙公网安备 33010602011771号