多任务和端到端学习
迁移学习
迁移学习(Tranfer Learning)是将一个神经网络从一个任务中学到的知识和经验,运用到另一个任务中。
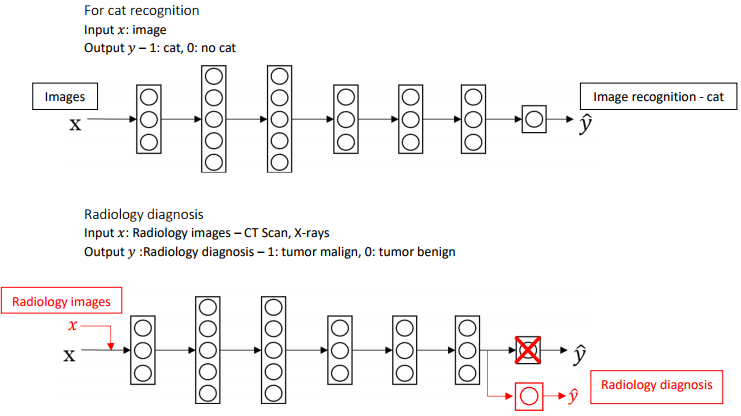
如上图中,将为猫识别器构建的神经网络迁移应用到放射诊断中,因为猫识别器的神经网络已经学习到了关于图像的结构和性质等方面的知识,所以只要先删除神经网络的中最后一层,输出层的权重值也改为随机初始化的值,随后输入新的训练数据进行训练,就完成了以上的迁移学习。
如果你有一个小数据集,就只训练输出层前的最后一层,或者也许是最后一两层, 并保持其他参数不变。
如果你有足够多的数据,你可以重新训练神经网络中剩下的所有层。如果重新训练神经网络中的所有参数,则在这个图像识别的初始阶段称为预训练(Pre-Training),它将预先初始化各个神经网络的权重值,之后的权重更新过程便称为微调(Fine-Tuning)。
符合下面的条件时,进行迁移学习才是有意义的:
- 两个任务使用的数据集相同;
- 拥有更多数据的任务到数据较少的任务;
- 任务底层神经网络的某些功能对另一个任务有帮助。
多任务学习
多任务学习(Multi-Task Learning)是采用一个神经网络来同时执行多个任务,且这些任务的执行可以相互促进。

在自动驾驶技术中,车辆必须同时检测视野范围内的各种物体,这时就要用到多任务学习,训练一个神经网络来检测多种物体,这样可以做到一些早期特征在不同类型的对象间共享。假如要同时识别行人、汽车、路标、交通灯,则上图片的标签将表示为:
其中每一行分别表示四个要识别的物体,0或1代表无或有。其中的某些项目就算没有标记出来,并不产生影响。
神经网络的结构和损失函数将如下图所示:
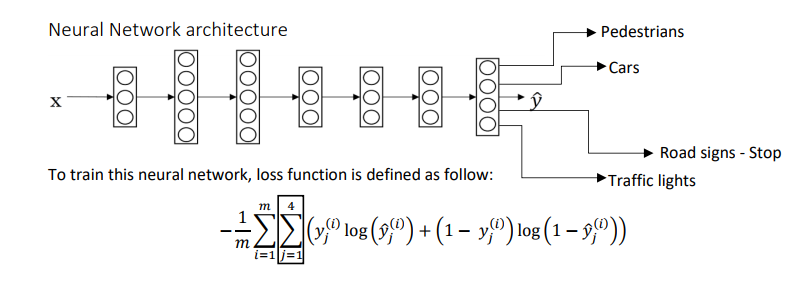
符合下面的条件时,采用多任务学习才是有意义的:
- 进行的任务都能从共享的较低级别功能中受益;
- 对每个任务拥有的数据量相当;
- 有能力训练足够大的神经网络来完成所有任务。
端到端学习
端到端深度学习(End-to-end Deep Learning)是将处理或学习系统简化为一个神经网络。
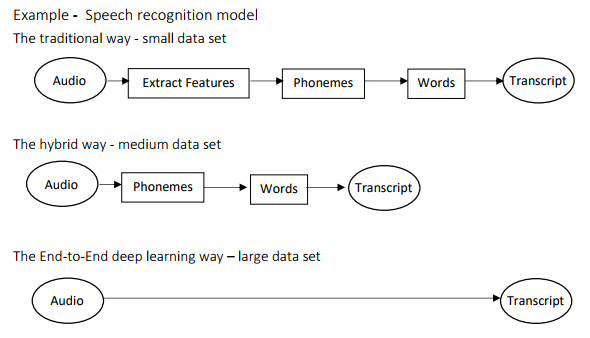
如图,传统的语音识别系统,是由声学模型、词典、语言模型构成,而其中的语音模型和语言模型是分别训练的,而不同的语言也有不同的语言模型,比如英语和中文。而端到端的语音识别系统,从语音特征(输入端)到文字串(输出端)中间就只需要一个神经网络模型。
端到端深度学习并不能应用于每一个问题,因为它需要大量的标记数据。它主要应用于音频转录,图像捕捉,图像合成,机器翻译,自驾车转向等。
端到端学习的优点:
端到端学习真的只是让数据说话。所以如果你有足够多的(x, y)数据,那么不管从x到y最适合的函数映射是什么,如果你训练一个足够大的神经网络,希望这个神经网络能自己搞清楚,而使用纯机器学习方法,直接从x到y输入去训练的神经网络,可能更能够捕获数据中的任何统计信息,而不是被迫引入人类的成见。
端到端深度学习的第二个好处就是这样,所需手工设计的组件更少,所以这也许能够简化你的设计工作流程,你不需要花太多时间去手工设计功能,手工设计这些中间表示方式。
端到端学习的缺点:
它可能需要大量的数据。要直接学到这个x到y的映射,你可能需要大量(x, y)数据。
另一个缺点是,它排除了可能有用的手工设计组件。如果你没有很多数据,你的学习算法就没办法从很小的训练集数据中获得洞察力。所以手工设计组件在这种情况,可能是把人类知识直接注入算法的途径。我觉得学习算法有两个主要的知识来源,一个是数据,另一个是你手工设计的任何东西,可能是组件,功能,或者其他东西。所以当你有大量数据时,手工设计的东西就不太重要了,但是当你没有太多的数据时,构造一个精心设计的系统,实际上可以将人类对这个问题的很多认识直接注入到问题里,进入算法里应该挺有帮助的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号