
第一次个人编程作业
https://github.com/chaukiching/personal-project.git
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 30 | 30 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 300 | 400 |
| · Design Spec | · 生成设计文档 | 20 | 20 |
| · Design Review | · 设计复审 | 20 | 15 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 30 | 30 |
| · Design | · 具体设计 | 250 | 300 |
| · Coding | · 具体编码 | 250 | 300 |
| · Code Review | · 代码复审 | 60 | 60 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 200 | 200 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 60 | 60 |
| · Size Measurement | · 计算工作量 | 30 | 10 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 80 |
| · 合计 | 1310 | 1505 |
二、计算模块接口
1.计算模块接口的设计与实现过程。设计包括代码如何组织,比如会有几个类,几个函数,他们之间关系如何,关键函数是否需要画出流程图?说明你的算法的关键(不必列出源代码),以及独到之处。
① 设计要求
本题敏感词检测的要求大致可分为两类:中文敏感词 和 英文敏感词 。
以下情况为中文敏感词:
- 敏感词中插入除字母、数字、换行的若干字符,如当山寨为敏感词词汇时,山_寨,山@寨,山 寨等。
- 敏感词用谐音替换、拼音替代、拼音首字母替代,如shan寨,栅寨,山Z等。
- 敏感词为繁体、拆分偏旁部首,如氵去工力等。
以下情况为英文敏感词:
- 英文文本不区分大小写,在敏感词中插入若干除换行、字母外等其他符号,也属于敏感词,如hello为敏感词时,he_llo,h%ell@o,he llo。
② 因此,我的解题思路就是:
首先,用read函数读取敏感词文件中的敏感词时,判断敏感词的类型,若为中文,则先利用Utf8ToGbk函数将中文从utf-8编码转换为GBK编码,再利用hanzipinyin函数转换为拼音,并将这些敏感词内容记录。
其次,利用search函数,按例文每行,每个敏感词进行遍历查找。当敏感词为中文,利用前面存入的中文和拼音查找到敏感词时,添加标记f=1来说明可能找到了敏感词,并将字符记录下来,若不符合要求则f=0,查找到敏感词后记录(谐音替换、拆分偏旁部首较为困难,由于能力有限,思考很久没想出解决方法);当敏感词为英文,方法一样,只要注意英文敏感词的要求即可。
最后,用print函数将得到的答案在文件中输出。
③ 函数:
- hanzi():实现中文敏感词的查找功能。
- yinwen():实现英文敏感词的查找功能。
- search():作为程序核心,用于读取例文文件,按行对敏感词分类判断,调用hanzi函数及yinwen函数进行查找。
- read():读取敏感词词汇文件。
- print():输出答案文件。
- hanzipinyin():将中文敏感词转换为拼音。
- Utf8ToGbk():将文件读取的中文由utf-8编码转换为GBK编码。
2.计算模块接口部分的性能改进。记录在改进计算模块性能上所花费的时间,描述你改进的思路,并展示一张性能分析图(由VS 2019、JProfiler或者Jetbrains系列IDE自带的Profiler的性能分析工具自动生成),并展示你程序中消耗最大的函数。
① 性能分析图:
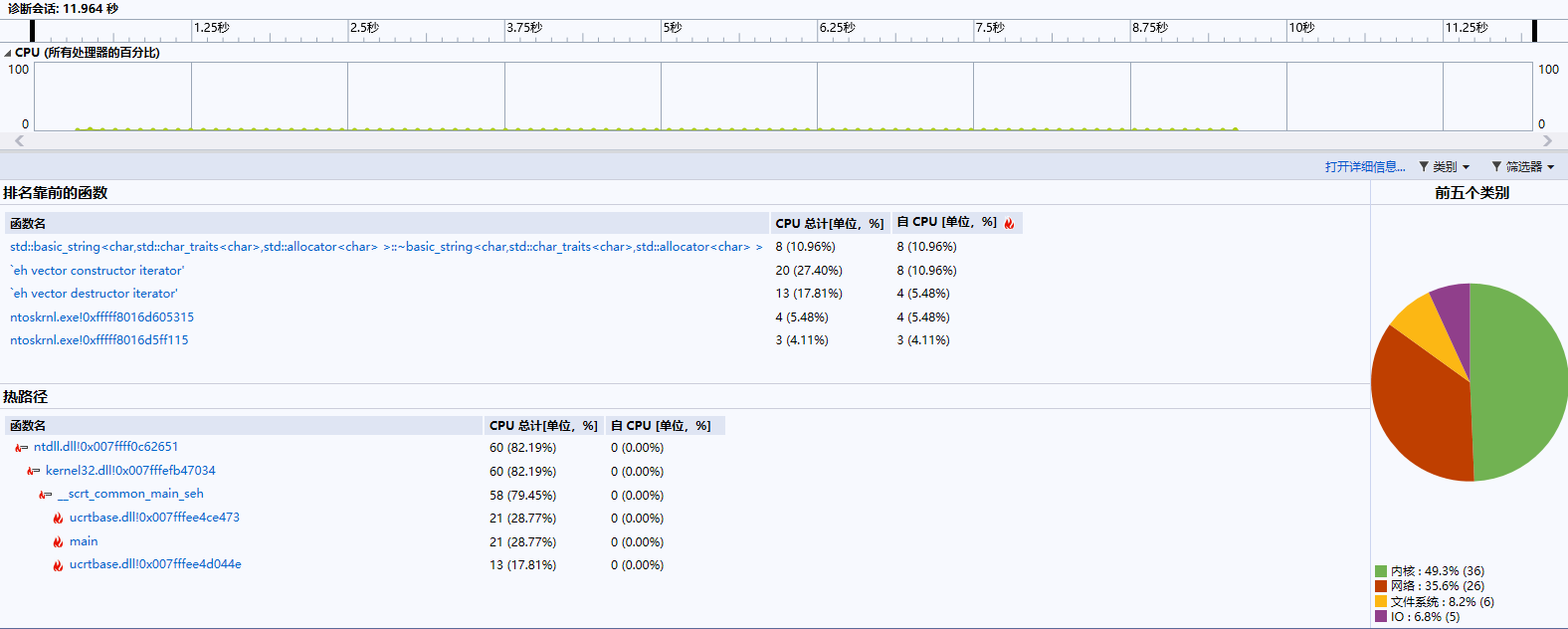
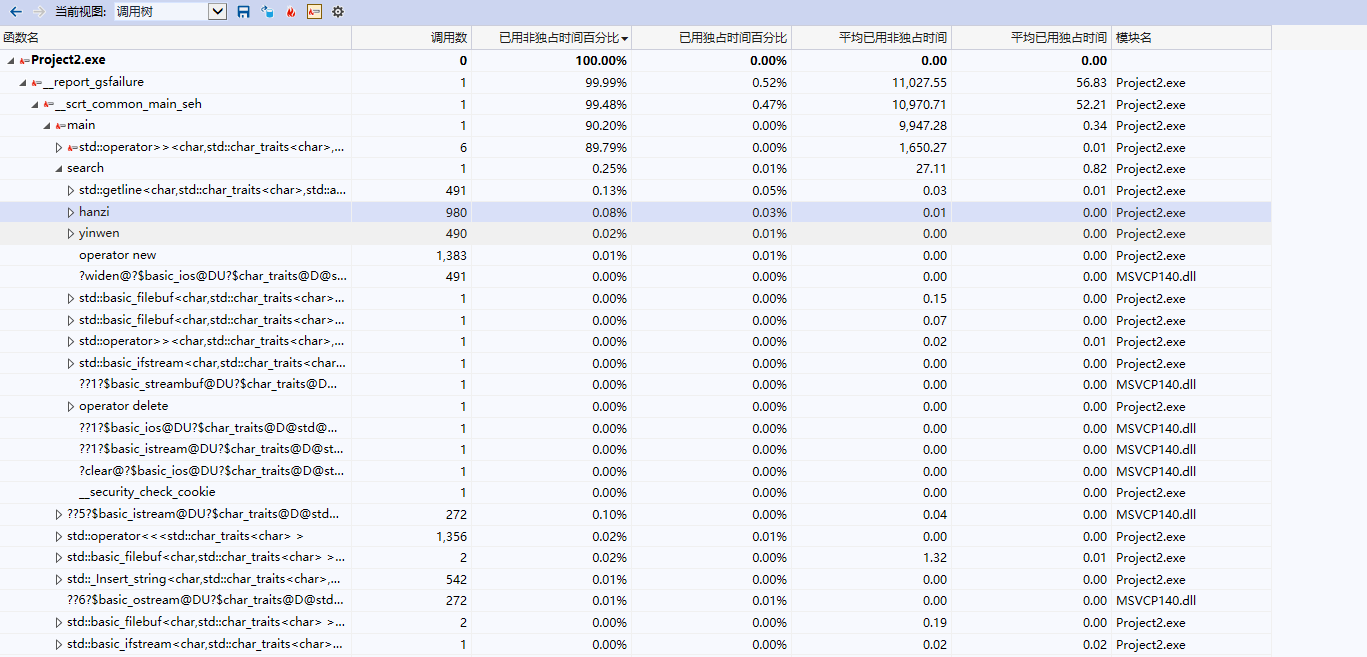
- 根据性能分析图来看,可以看出程序在打开文件读取数据的时间占了极大比例,由于程序对敏感词以及例文进行遍历查询的操作,多次使用for语句和if语句调用search函数、hanzi函数以及yinwen函数来查找例文中的敏感词,因此耗费了大量时间。
② 程序中消耗最大的函数:
int hanzi(string ans, string org,int num,int n, int j)
{
for (int i = 0, m = 0, f = 0; i < org.length(); i++)
{
if (org[i] == w[n].word[m] && org[i + 1] == w[n].word[m + 1] && org[i + 2] == w[n].word[m + 2])//utf-8汉字占3字节
{
f = 1;//作为判断是否遇到敏感词的标志*/
ans = ans + org[i] + org[i + 1] + org[i + 2];
m = m + 3;
if (m > w[n].word.length() - 1 && ans.length() > w[n].word.length() - 1)//超出长度则表示已找到敏感词,并开始继续查找
{
m = 0;
f = 0;
s[num].words = w[n].word;
s[num].anss = ans;
s[num].h = j;
num++;
ans = "";
continue;
}
i = i + 2;
continue;
}
if (org[i] >= '0' && org[i] <= '9' || org[i] >= 'A' && org[i] <= 'Z' || org[i] >= 'a' && org[i] <= 'z')
{
f = 0;
ans = "";
continue;
}//敏感词中插入字母、数字、换行的若干字符就不属于敏感词
if (f == 1)
ans = ans + org[i];
}
return num;
}
int yinwen(string ans, string org,int num, int n, int j)
{
for (int i = 0, m = 0, f = 0; i < org.length(); i++)
{
if ((org[i] >= 'A' && org[i] <= 'Z') || (org[i] >= 'a' && org[i] <= 'z'))
{
if (org[i] == w[n].word[m] || org[i] - w[n].word[m] == 32 || w[n].word[m] - org[i] == 32)//英文文本不区分大小写,在敏感词中不能插入换行、字母
{
f = 1;//作为判断是否遇到敏感词的标志*/
ans = ans + org[i];
m = m + 1;
if (m > w[n].word.length() - 1)//超出长度则表示已找到敏感词,并开始继续查找
{
m = 0;
f = 0;
s[num].words = w[n].word;
s[num].anss = ans;
s[num].h = j;
num++;
ans = "";
}
}
else
{
f = 0;
m = 0;
ans = "";
}
continue;
}
if (f == 1)
ans = ans + org[i];
}
return num;
}
int search(int j,int num,int l)
{
string org;
cin >> org;
ifstream ifile;
ifile.open(org);// 以读模式打开待检测文件
if (!ifile)
{
cout << "open fail" << endl;
}
else
{
while (getline(ifile, org))// 从文件读取每行例文
{
j++;
for (int n = 0; n < l; n++)//用循环查找每个敏感词
{
string ans;
if (w[n].hanying == 1)//如果敏感词为汉字
num = hanzi(ans, org, num, n, j);
if (w[n].hanying == 0)//如果敏感词为英文
num = yinwen(ans, org, num, n, j);
}
}
}
ifile.close();// 关闭打开的文件
return num;
}
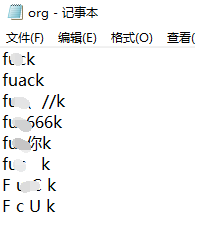
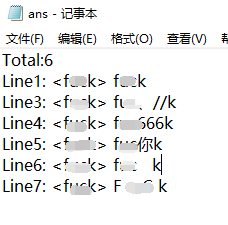
3.计算模块部分单元测试展示。展示出项目部分单元测试代码,并说明测试的函数,构造测试数据的思路。并将单元测试得到的测试覆盖率截图,发表在博客中。
① 中文测试结果:


② 英文测试结果:
4.计算模块部分异常处理说明。在博客中详细介绍每种异常的设计目标。每种异常都要选择一个单元测试样例发布在博客中,并指明错误对应的场景。
① 输入错误的文件路径出现异常
ifstream ifile;
ifile.open(words);// 以读模式打开敏感词词汇文件
if (!ifile) cout << "open fail" << endl;
- 若找不到所要打开的文件,则会报错。
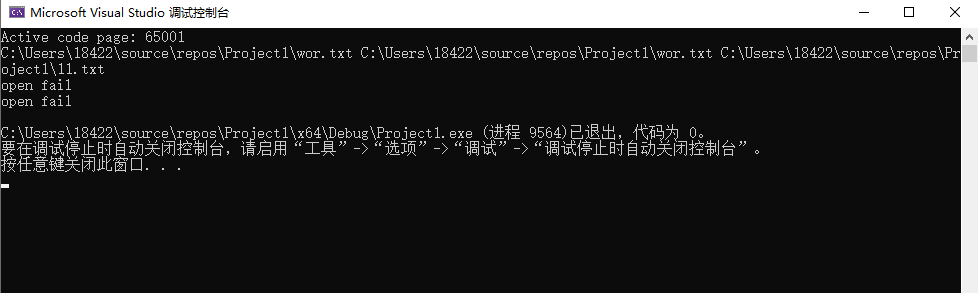
② 读取一行文件内容出现异常
ifstream ifile;
ifile.open(org);// 以读模式打开待检测文件
if (!ifile) cout << "open fail" << endl;
else
while (getline(ifile, org))
- 遍历例文时使用ifile>>输入,若遇到一行里的空格则会停止。
- 因此要使用getline(ifile, )读取整行。

三、心得
在完成本次作业过程的心得体会
- 在本次作业的过程中,遇到了很多问题,在同学和百度的帮助下也解决了许多问题,例如:C++程序以读模式打开文件读取数据,并经过程序运行后写入其他文件中;了解了github的用法,PSP表格的作用,明白了utf-8编码每个汉字占用3个字节等等知识。由于测试的时候是按照传递命令行参数的方式提供文件的位置,因此还学习了如何在程序里接受命令行参数,最后按照命令行参数的要求修改了代码。本次作业做了很久,但结果仍然不令我满意,很多复杂的操作没有完成好,原来的解题思路没有得到完成,做完最大的感受就是发现了自己和别人的差距很大,以及自己能力的不足。希望在本次作业以后,自己能够多学点东西,多请教老师和同学,在实践中提升自我吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号