如何快速学习新技术之--kafka优化参数项
如何快速学习新技术之我见--之kafka优化参数
前言
首先技术都是相通的,任何技术也都不是凭空出现的,它多半是借鉴了前人的经验的基础上形成的。
在此我以kafka作为例子。因为这个东西对我来说就是新学的。
这篇博文,其实重要的不是kafka本身,而是一种思路。你懂的。:-)
学习路径
原理 -> 理清各个组件功能与基本配置 ->搭建环境 ->配置参数,基本命令 ->高级功能(如高可用,性能优化,定位问题方法等)
思考问题
在学习之前,先问自己几个问题。
1)Kafka是干什么的?
2)Kafka为何那么快?
3)Kafka是如何处理消息的?
4)Kafka如何进行调优?
关于如何调优化,可以继续问自己几个问题?
4.1)Kafka消费速度赶不上,生产速度会发生什么?
4.2)哪些资源可能会成为瓶颈(CPU,IO,RAM,网络)
4.3)Kafka既然是使用JAVA开发的,那是否存在JAVA GC方面的问题?
5)Kafka如何进行监控,需要监控哪些指标?
Kafka简介
Kafka是一个分布式消息队列。
Kafka对消息保存时根据Topic进行归类,发送消息者称为Producer,消息接受者称为Consumer。
此外kafka集群有多个kafka实例组成,每个实例(server)称为broker。无论是kafka集群,还是consumer都依赖于zookeeper集群保存一些meta信息,来保证系统可用性。
架构图
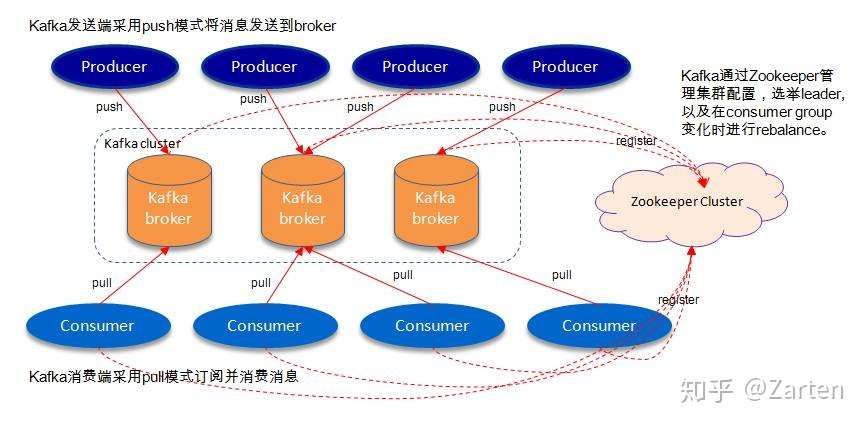
如上图,一个kafka架构包括若干个Producer(服务器日志、业务数据、web前端产生的page view等),若干个Broker(kafka支持水平扩展,一般broker数量越多集群的吞吐量越大),若干个consumer group,一个Zookeeper集群(kafka通过Zookeeper管理集群配置、选举leader、consumer group发生变化时进行rebalance)。
名称解释
- Broker
消息中间件处理节点(服务器),一个节点就是一个broker,一个Kafka集群由一个或多个broker组成
- Topic
Kafka对消息进行归类,发送到集群的每一条消息都要指定一个topic
- Partition
物理上的概念,每个topic包含一个或多个partition,一个partition对应一个文件夹,这个文件夹下存储partition的数据和索引文件,每个partition内部是有序的
- Producer
生产者,负责发布消息到broker
- Consumer
消费者,从broker读取消息
- ConsumerGroup
每个consumer属于一个特定的consumer group,可为每个consumer指定group name,若不指定,则属于默认的group,一条消息可以发送到不同的consumer group,但一个consumer group中只能有一个consumer能消费这条消息
问题解答
1)Kafka是干什么的?
Kafka是一个分布式消息队列,采用了典型的生产者与消费者模型
2)Kafka为何那么快?
Kafka使用了顺序写入,nmap印射等技术。具体可以去找找网上相关资料。
3)Kafka是如何处理消息的?
生产者发送消息,消费者通过消息订阅的方式消费消息
4)Kafka如何进行调优?
关于如何调优化,可以继续问自己几个问题?
3.1)Kafka消费速度赶不上,生产速度会发生什么?
当consumer消费速度过慢时,大量的数据堆积,造成系统的异常
3.2)哪些资源可能会成为瓶颈(CPU,IO,RAM,网络)
这点真的与MySQL(又说MySQL,谁叫我是MySQL DBA呢)是相通的,任何应用都是在利用现有的资源的情况下(至于资源提前规划,那又是另一个课题),实现效能的最大化。
MySQL因为是数据库软件,面临着大量的数据变更,通常最大可能的瓶颈大都出现在IO上(我这并不是说,其它资源不会成为瓶颈)。
Kafka是消息队列,其面临者大量的数据交互及持久化,所以CPU,网络更有可能成为瓶颈。下面的优化参数可以看到,大部分都是针对这两个资源所做的优化。
3.3)Kafka既然是使用JAVA开发的,那是否存在JAVA GC方面的优化?
是的,GC问题肯定存在的,可以通过GC参数来优化。
5)Kafka如何进行监控?
这点,我还真没研究清楚。毕竟暂还未看到上线真实系统的机会。
不过,没关系。至少我知道如果要监控,肯定少不了监控消息的消费情况,是否有累积等。磁盘与网络等相关OS信息。
等有时间再仔细研究一下。
kafka性能优化
1.partition数量配置
partition数量由topic的并发决定,并发少则1个分区就可以,并发越高,分区数越多,可以提高吞吐量。
创建topic时指定topic数量
2.日志保留策略设置
#当kafka broker的被写入海量消息后,会生成很多数据文件,占用大量磁盘空间,kafka默认是保留7天,建议根据磁盘情况配置,避免磁盘撑爆。
log.retention.hours=72
#段文件配置1GB,有利于快速回收磁盘空间,重启kafka加载也会加快(如果文件过小,则文件数量比较多,kafka启动时是单线程扫描目录(log.dir)下所有数据文件)
log.segment.bytes=1073741824
3.文件刷盘策略
为了大幅度提高producer写入吞吐量,需要定期批量写文件。建议配置:
#每当producer写入10000条消息时,刷数据到磁盘
log.flush.interval.messages=10000
#每间隔1秒钟时间,刷数据到磁盘
log.flush.interval.ms=1000
4.网络和io操作线程配置优化
一般num.network.threads主要处理网络io,读写缓冲区数据,基本没有io等待,配置线程数量为cpu核数加1.
#broker处理消息的最大线程数
num.network.threads=xxx
num.io.threads主要进行磁盘io操作,高峰期可能有些io等待,因此配置需要大些。配置线程数量为cpu核数2倍,最大不超过3倍.
#broker处理磁盘IO的线程数
num.io.threads=xxx
#加入队列的最大请求数,超过该值,network thread阻塞
queued.max.requests=5000
#server使用的send buffer大小。
socket.send.buffer.bytes=1024000
#server使用的recive buffer大小。
socket.receive.buffer.bytes=1024000
5.异步提交(kafka.javaapi.producer)
采用同步:1000条8s;
采用异步:100条或3s异步写入,速度提升为1w条2s(ProducerConfig)
#request.required.acks属性取值含义
##0:这意味着生产者producer不等待来自broker同步完成的确认继续发送下一条(批)消息。此选项提供最低的延迟但最弱的耐久性保证(当服务器发生故障时某些数据会丢失,如leader已死,但producer并不知情,发出去的信息broker就收不到)。
##1:这意味着producer在leader已成功收到的数据并得到确认后发送下一条message。此选项提供了更好的耐久性为客户等待服务器确认请求成功(被写入死亡leader但尚未复制将失去了唯一的消息)。
##-1:这意味着producer在follower副本确认接收到数据后才算一次发送完成。 此选项提供最好的耐久性,我们保证没有信息将丢失,只要至少一个同步副本保持存活。
##三种机制,性能依次递减 (producer吞吐量降低),数据健壮性则依次递增。
request.required.acks=0
producer.type=async
##在异步模式下,一个batch发送的消息数量。producer会等待直到要发送的消息数量达到这个值,之后才会发送。但如果消息数量不够,达到queue.buffer.max.ms时也会直接发送。
batch.num.messages=100
##默认值:200,当使用异步模式时,缓冲数据的最大时间。例如设为100的话,会每隔100毫秒把所有的消息批量发送。这会提高吞吐量,但是会增加消息的到达延时
queue.buffering.max.ms=100
##默认值:5000,在异步模式下,producer端允许buffer的最大消息数量,如果producer无法尽快将消息发送给broker,从而导致消息在producer端大量沉积,如果消息的条数达到此配置值,将会导致producer端阻塞或者消息被抛弃。
queue.buffering.max.messages=1000 ##发送队列缓冲长度
##默认值:10000,当消息在producer端沉积的条数达到 queue.buffering.max.meesages 时,阻塞一定时间后,队列仍然没有enqueue(producer仍然没有发送出任何消息)。此时producer可以继续阻塞或者将消息抛弃,此timeout值用于控制阻塞的时间,如果值为-1(默认值)则 无阻塞超时限制,消息不会被抛弃;如果值为0 则立即清空队列,消息被抛弃。
queue.enqueue.timeout.ms=100
JVM优化:
Kafka JVM参数可以直接修改启动脚本bin/kafka-server-start.sh 中的变量值。下面是一些基本参数,也可以根据实际的gc状况和调试GC需要增加一些相关的参数。
export KAFKA_HEAP_OPTS="-Xmx4G -Xms4G -Xmn2G -XX:PermSize=64m -XX:MaxPermSize=128m -XX:SurvivorRatio=6 -XX:CMSInitiatingOccupancyFraction=70 -XX:+UseCMSInitiatingOccupancyOnly"
总结
其实说了这么多,我也都是纸上谈兵。因为我根本没有实战项目用到Kafka。所谓的这些参数是否真有其用,还不得而知。
但至少如果真上线一个kafka系统,我知道从哪开始,需要注意哪些点。
换而言之,为何你去某些公司面试,面试官一定会问你原理性的东西,而且越是高级职位,问得越深入呢?
因为,目前的系统都很庞大,我们不可能不停的尝试。原理性的东西是减少你的试错成本的最有效手段。所谓上兵伐谋。
参考资料
https://www.jianshu.com/p/c575c7aec4dd
https://blog.csdn.net/u013063153/article/details/73826403
https://zhuanlan.zhihu.com/p/38269875
https://www.cnblogs.com/technologykai/articles/10845557.html
https://www.cnblogs.com/xinxiucan/p/12666967.html
https://www.pianshen.com/article/228823676/
https://cloud.tencent.com/developer/article/1602749

 浙公网安备 33010602011771号
浙公网安备 33010602011771号