MongoDB的学习
MongoDB学习笔记
1.简介
- 基于分布式文件存储数据库(就是一个数据库
- C++语言编写
- 支持的数据结构非常松散,是类似json的bson格式(后期插入修改数据写JSON
JSON(JavaScript Object Notation, JS 对象简谱)是一种轻量级的数据交换格式
bson(二进制JSON)
种类
关系型:Oracle、MySQL、SQLite 、SQL Server等
非关系型(Not Only SQL):MongoDB(文档)、Redis/Memcache(内存)
关系型和非关系型数据库软件区别
相同点:都是数据库软件,用来存放项目数据
不同点:
关系型:1.遵循SQL标准,换句话说语法大同小异、2.有库和表约束等
非关系型:1.没有统一标准、2.一般键值对形式存储、3.读取速度更快
2.在不同平台下安装MongoDB
win系统下安装并启动服务
步骤1:下载 https://www.mongodb.com/download-center/community
步骤2:解压
步骤3:创建服务
bin/mongod.exe --install --dbpath 磁盘路径 --logpath 日志路径
//留心1:比如通过管理员身份运行DOS窗口 否则没有权限创建失败
//留心2:得提前创建数据和日志存放目录
步骤4:启动服务
net start mongodb
步骤5:登录(验证是否安装成功
bin/mongo
Linux系统下安装并启动服务
#步骤1:下载
curl -O https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-rhel80-4.4.5.tgz//curl— transfer a URL
#步骤2:解压
tar -zxvf mongodb-linux-x86_64-rhel80-4.4.5.tgz
#步骤3:将解压包拷贝到指定目录
mv mongodb-linux-x86_64-rhel80-4.4.5/ /usr/local/mongodb
#步骤4:创建数据存放目录与日志存放目录
mkdir -p /usr/local/mongodb/data /usr/local/mongodb/logs
#步骤5:启动MongoDB服务
/usr/local/mongodb/bin/mongod --dbpath=/usr/local/mongodb/data --logpath=/usr/local/mongodb/logs/mongodb.log --logappend --port=27017 --fork
3.一些基本的操作
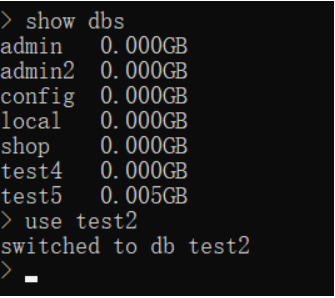
查看数据库
语法:show databases
可以简写为show dbs
选择数据库:use 数据库名(如果没有则隐式创建)
查看集合
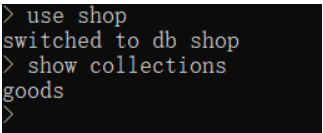
语法:show collections
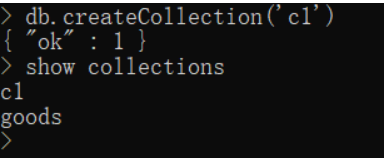
创建集合
语法:db.createCollection('集合名')
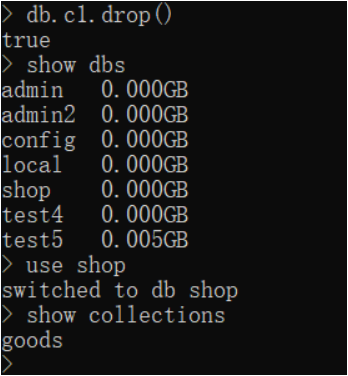
删除集合
语法:db.集合名.drop()
删除数据库
首先选中数据库 use 数据库名
然后db.dropDatabase()
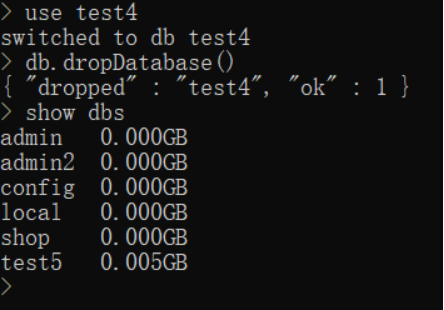
4.关于CURD
C增(create)
语法:db.集合名.insert(JSON数据)
说明:集合存在-则直接插入数据,集合不存在-隐式创建
在test1数据库的c3集合中插入数据(姓名叫何松林年龄18岁)
use test1
db.c3.insert({uname:"小何", age:18})
留心1:数据库和集合不存在都隐式创建
留心2:对象的键统一不加引号方便看,但是查看集合数据时系统会自动加
留心3:mongodb会给每条数据增加一个全球唯一的_id键

_id的组成
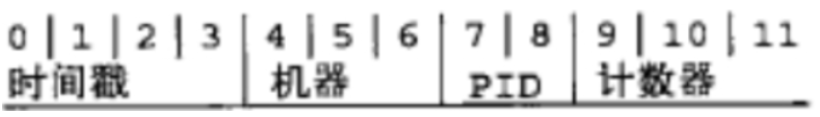
在_id中表现为24位16进制数据
id可以被自定义(但是实战中强烈不建议)
db.c1.insert({_id:1, uname:"小何", age:18})

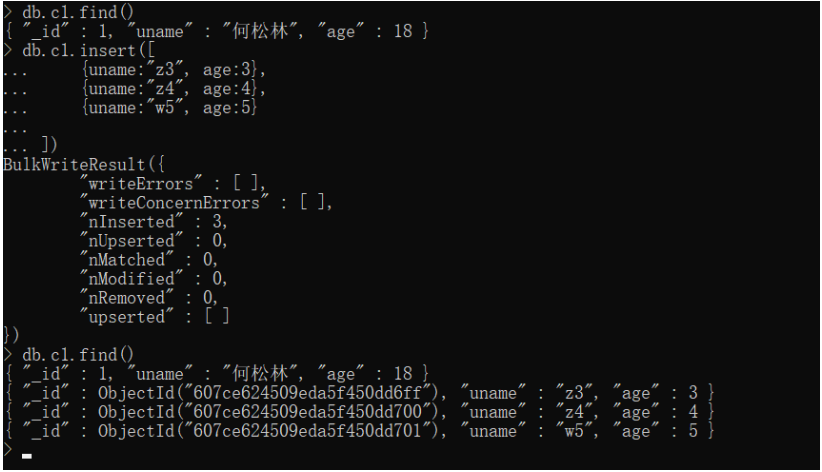
插入多条数据的方式
db.c1.insert([
{uname:"z3", age:3},
{uname:"z4", age:4},
{uname:"w5", age:5}
])
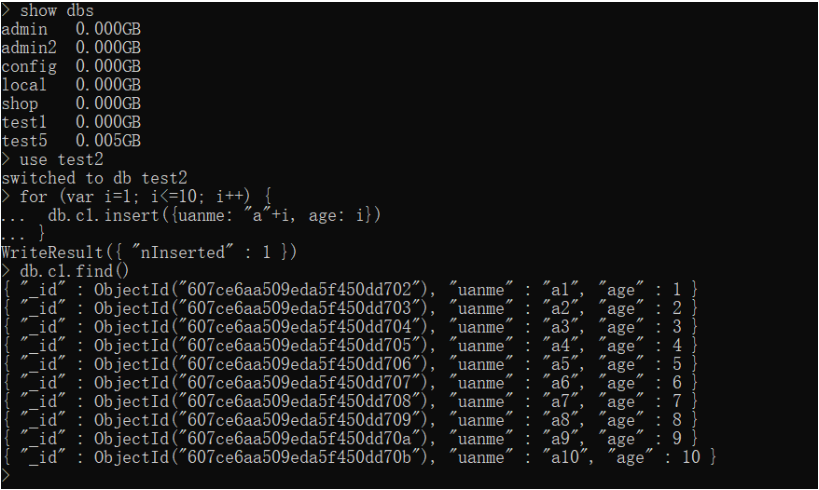
mongodb底层使用JS引擎实现的,所以支持部分js语法
可以写for循环
use test2
for (var i=1; i<=10; i++) {
db.c1.insert({uanme: "a"+i, age: i})
}
R查(read)
基础语法:db.集合名.find(条件 [,查询的列])
条件
查询所有数据 {}或者不写
查询age=6的数据 {age:6}
既要age=6又要性别=男 {age:6,sex:'男'}
查询的列(可选参数
不写 - 这查询全部列(字段
{age:1} 只显示age列(字段
{age:0} 除了age列(字段都显示
留心:不管你怎么写系统自定义的_id都会在
升级语法:
db.集合名.find({键:值}) 注:值不直接写
{运算符:值}
db.集合名.find({
键:{运算符:值}
})
| 运算符 | 作用 |
|---|---|
| $gt | 大于 |
| $gte | 大于等于 |
| $lt | 小于 |
| $lte | 小于等于 |
| $ne | 不等于 |
| $in | in |
| $nin | not in |
查询age大于5的数据
db.c1.find({age:{$gt:5}})

查询age为1,4,8的数据
db.c1.find({age:{$in:[1,4,8]}})

只查看age列,或者不看age列
db.c1.find({},{age:1})
db.c1.find({},{age:0})
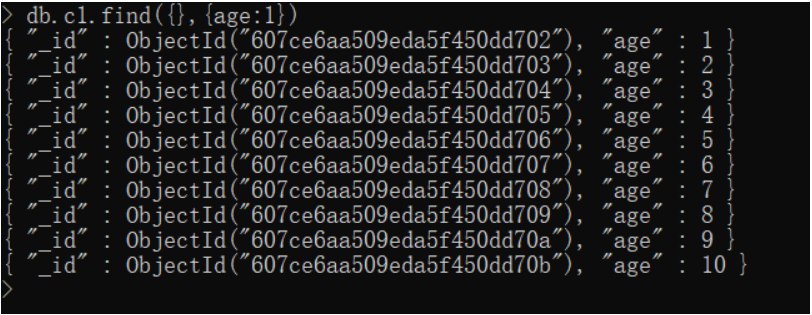
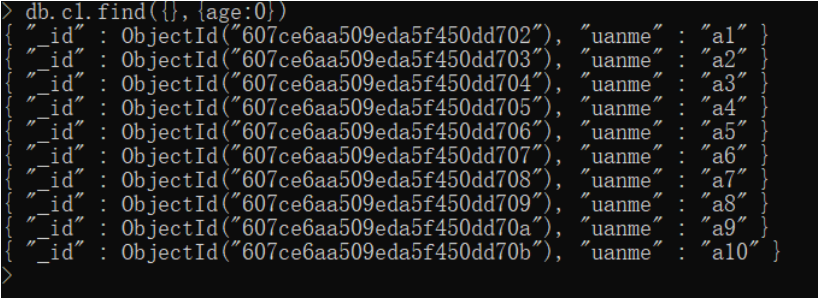
U改(update)
基础语法: db.集合名.update(条件, 新数据 [,是否新增,是否修改多条])
是否新增:指条件匹配不到数据则插入(true是插入,false否不插入默认)
是否修改多条:指将匹配成功的数据都修改(true是,false否默认)
升级语法
说明:
是否新增:指匹配不到数据则插入(true-是插入,false-否不插入默认)
是否修改多条:将匹配成功的数据都修改(true-是,false-否默认)
db.集合名.update(条件, 新数据)
{修改器: {键:值}}
| 修改器 | 作用 |
|---|---|
| $inc | 递增 |
| $rename | 重命名列 |
| $set | 修改列值 |
| $unset | 删除列 |
将{uname:"a1"}改为{uname:"a10"}
db.c1.update({uname:"a1",{uname:"a10"}})
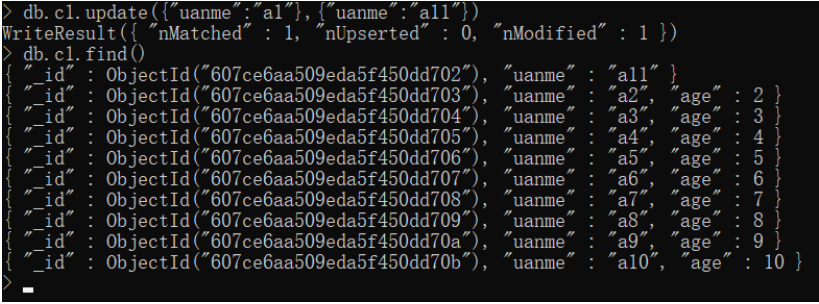
默认不加修改器是替换而不是修改
加上修改器
db.c1.update({uname:"a4"}, {$set: {uname: "a44"}})
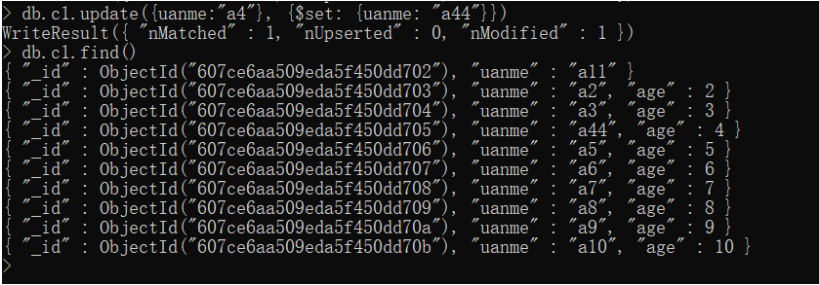
给a44的age增加10
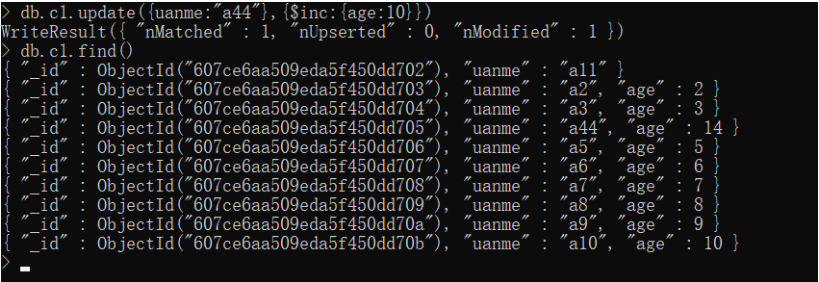
db.c1.update({uanme:"a44"},{$inc:{age:10}})
D删(delete)
语法:db.集合名.remove(条件 [, 是否删除一条] )
注意:是否删除一条 true是,false否 默认
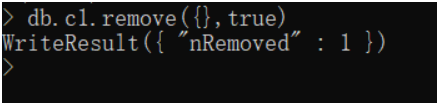
db.c1.remove({},true)
db.c1.remove({})

5.排序
排序
-
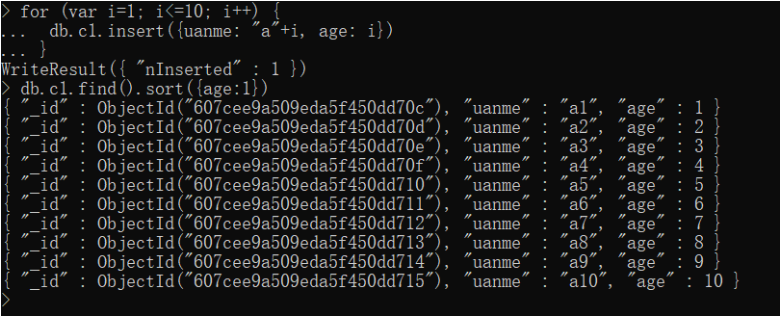
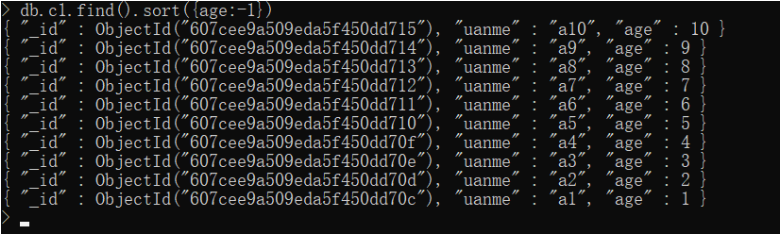
语法:db.集合名.find().sort(JSON数据)
-
说明:键-就是要排序的列/字段、值:1 升序 -1 降序
-
练习:年龄升序&降序
![image]()
![image]()
Limit与Skip方法
-
语法:db.集合名.find().sort().skip(数字).limit(数字)
-
说明:skip跳过指定数量(可选),limit限制查询的数量
-
练习:1-降序查询查询2条,2-降序跳过2条并查询2条


6.聚合查询
概念
聚合查询
顾名思义就是把数据聚起来,然后统计
语法
db.集合名称.aggregate([
{管道:{表达式}}
....
])
常用管道
$group 将集合中的文档分组,用于统计结果
$match 过滤数据,只要输出符合条件的文档
$sort 聚合数据进一步排序
$skip 跳过指定文档数
$limit 限制集合数据返回文档数
....
常用表达式
$sum 总和 $sum:1同count表示统计
$avg 平均
$min 最小值
$max 最大值
...
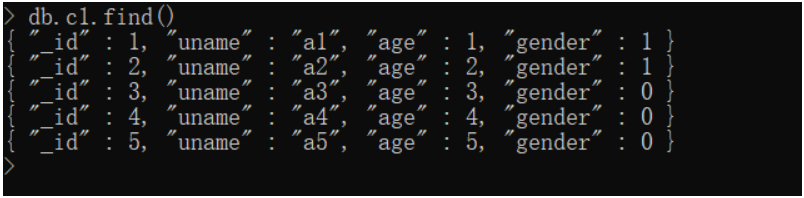
//实例 统计男生与女生的age总数
db.c1.aggregate([
{
$group:{
_id: "$gender",
rs: {$sum: "$age"}
}
}
])
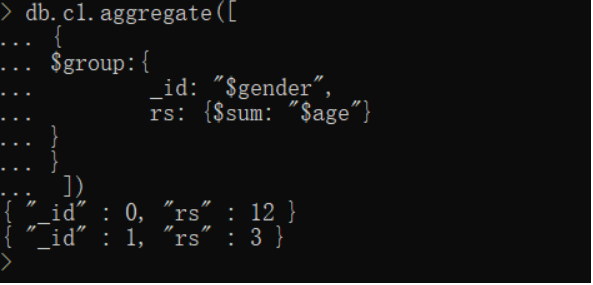
//统计男生与女生的总人数
db.c1.aggregate([
{
$group:{
_id: "$gender",
rs: {$sum:1}
}
}
])
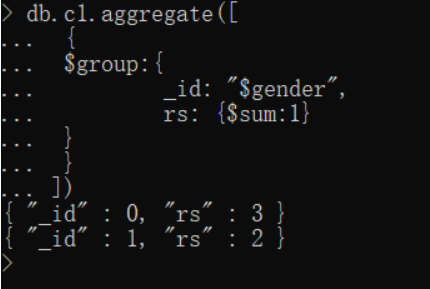
//统计所有人的总年龄以及总人数
db.c1.aggregate([
{
$group:{
_id: null,
total_num: {$sum:1},
total_avg: {$avg: "$age"}
}
}
])
7.索引
数据库中的索引
说明:索引是一种排序好的便于快速查询的数据结构
作用:帮助数据库高效的查询数据
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。
这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。
索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构
createIndex() 方法
createIndex()方法基本语法格式如下所示:
>db.collection.createIndex(keys, options)
语法中 Key 值为你要创建的索引字段,1 为指定按升序创建索引,如果你想按降序来创建索引指定为 -1 即可。
createIndex() 接收可选参数,可选参数列表如下:
| Parameter | Type | Description |
|---|---|---|
| background | Boolean | 建索引过程会阻塞其它数据库操作,background可指定以后台方式创建索引,即增加 "background" 可选参数。 "background" 默认值为false。 |
| unique | Boolean | 建立的索引是否唯一。指定为true创建唯一索引。默认值为false. |
| name | string | 索引的名称。如果未指定,MongoDB的通过连接索引的字段名和排序顺序生成一个索引名称。 |
| dropDups | Boolean | 3.0+版本已废弃。在建立唯一索引时是否删除重复记录,指定 true 创建唯一索引。默认值为 false. |
| sparse | Boolean | 对文档中不存在的字段数据不启用索引;这个参数需要特别注意,如果设置为true的话,在索引字段中不会查询出不包含对应字段的文档.。默认值为 false. |
| expireAfterSeconds | integer | 指定一个以秒为单位的数值,完成 TTL设定,设定集合的生存时间。 |
| v | index version | 索引的版本号。默认的索引版本取决于mongod创建索引时运行的版本。 |
| weights | document | 索引权重值,数值在 1 到 99,999 之间,表示该索引相对于其他索引字段的得分权重。 |
| default_language | string | 对于文本索引,该参数决定了停用词及词干和词器的规则的列表。 默认为英语 |
| language_override | string | 对于文本索引,该参数指定了包含在文档中的字段名,语言覆盖默认的language,默认值为 language. |
db.c1.createIndex( { "name": 1 }, { expireAfterSeconds: 3600 } )
实例
创建100000条数据
//选择数据库
use test5;
//向数据库中添加数据
for(var i=0;i<100000;i++){
db.c1.insert({'name':"aaa"+i,"age":i});
}

给name添加普通索引,命令:
db.c1.createIndex({name:1})
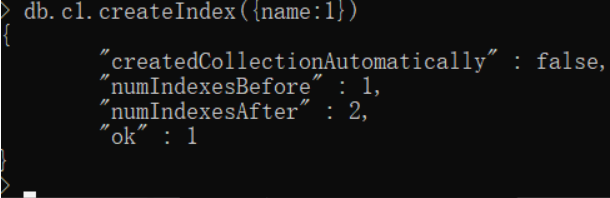
查看当前索引,命令:
db.c1.getIndexes()
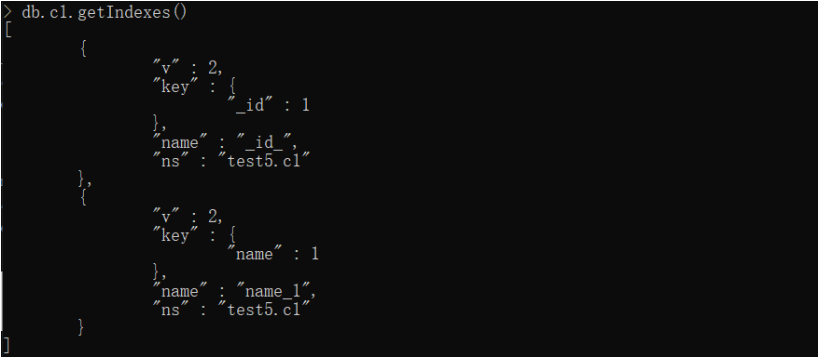
删除name索引,命令:
db.c1.dropIndex('name_1')

通过多个字段来进行索引(关系型中被称为复合索引),命令:
db.c1.createIndex({name:1,age:1})

创建唯一索引,首先将全部索引删除:
db.c1.dropIndexes()
然后创建唯一索引:
db.c1.createIndex({name:1}, {unique: "name"})
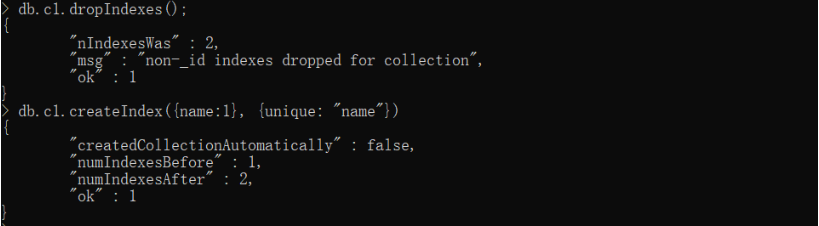
创建完唯一索引后不允许同一个字段拥有相同的两项。首先换到一个没有创建唯一索引的数据集:

再来验证创建好唯一索引的数据集能否插入相同字段名的不同数据:
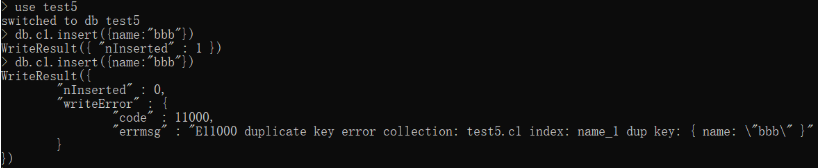
分析索引的作用
语法:
db.c1.find({age:18}).explain('executionStats');
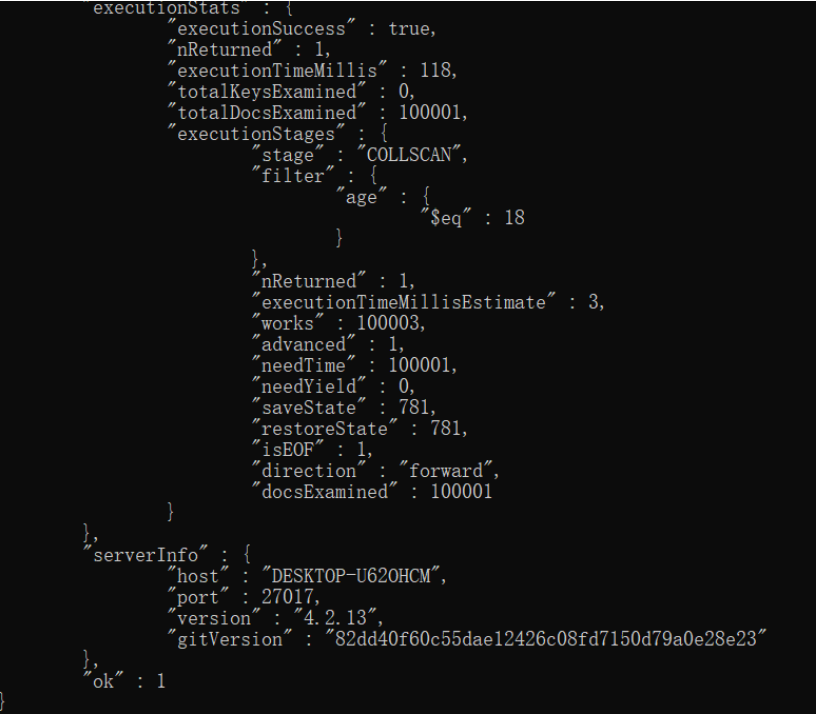
COLLSCAN 全表扫描
使用索引:
#创造普通索引
db.c1.createIndex({age:1})
#再执行以下命令
db.c1.find({age:18}).explain('executionStats');
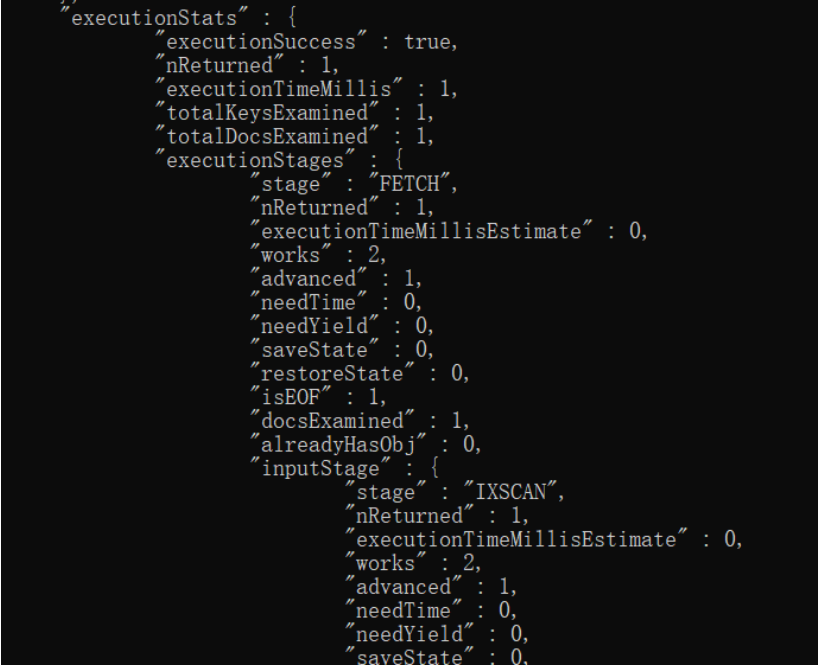
FETCH 根据索引去检索指定document
总结:索引的创建可以大大缩减索引所需的时间,但是索引本身占用一定的磁盘资源,每次插入和修改数据都需要更新索引,所以开发者需要按需创建索引。
8.备份与恢复
备份命令
导出数据语法:mongodump -h -port -u -p -d -o
导出语法说明
-h host 服务器IP地址(一般不写 默认本机
-port 端口(一般不写 默认27017
-u user 账号
-p pwd 密码
-d database 数据库(留心:数据库不写则导出全局
-o open 备份到指定目录下
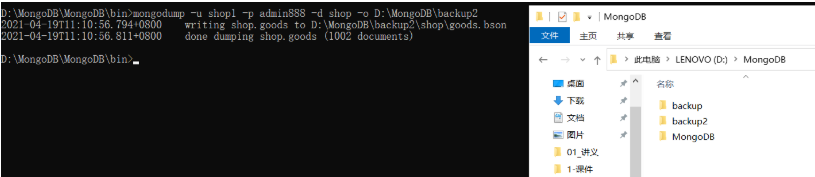
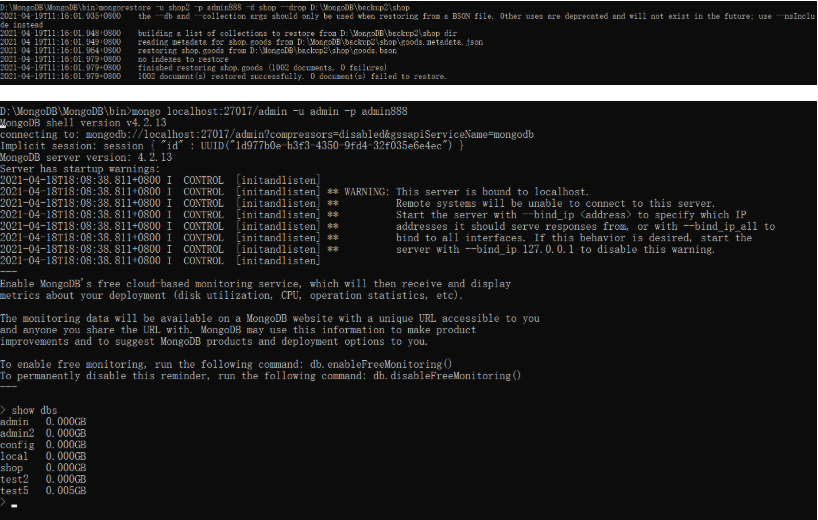
备份所有数据库:mongodump -u admin -p admin888 -o D:\MongoDB\backup
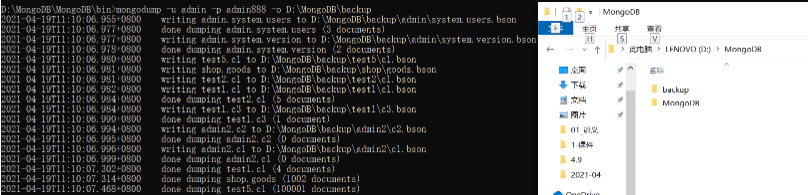
备份指定数据库:mongodump -u shop -p admin888 -d shop -o D:\MongoDB\backup2
全部恢复
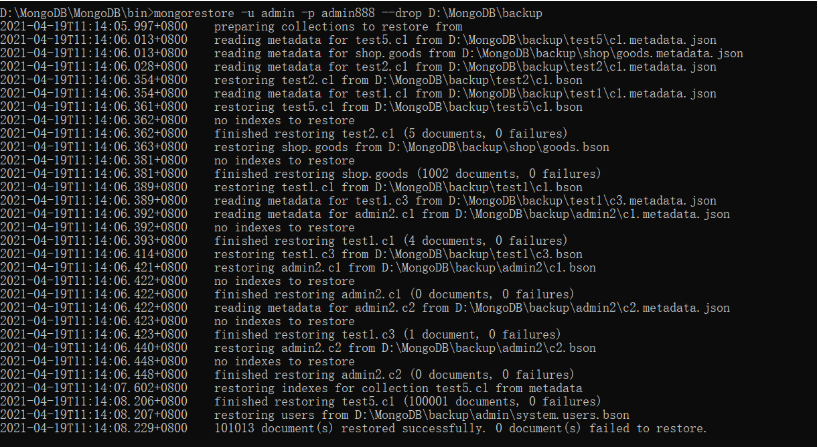
还原数据语法:mongorestore -h -port -u -p -d --drop 备份数据目录
还原数据说明:
-h
-port
-u
-p
-d 不写则还原全部数据库
--drop 先删除数据库再导入
还原所有数据库:mongorestore -u admin -p admin888 --drop D:\MongoDB\backup
指定恢复
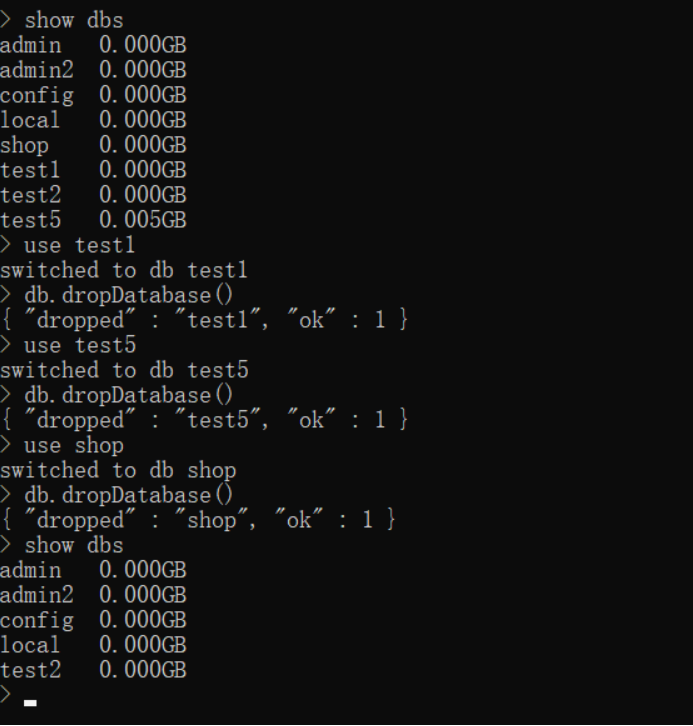
删除指定数据库shop以及非指定数据库test1
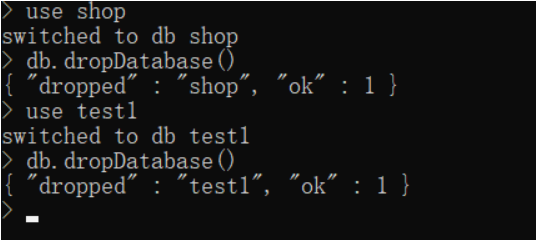
还原指定数据库:mongorestore -u shop2 -p admin888 -d shop --drop D:\MongoDB\backup2\shop
9.权限机制
在使用数据库的过程中,直接输入命令就可以登录数据库,这在实际操作中时不允许的,所以需要开启验证模式。
语法:
创建账号
db.createUser({
"user" : "账号",
"pwd": "密码",
"roles" : [{
role: "角色",
db: "所属数据库"
}]
})
角色
#角色种类
超级用户角色:root
数据库用户角色:read、readWrite;
数据库管理角色:dbAdmin、userAdmin;
集群管理角色:clusterAdmin、clusterManager、clusterMonitor、hostManager;
备份恢复角色:backup、restore;
所有数据库角色:readAnyDatabase、readWriteAnyDatabase、userAdminAnyDatabase、dbAdminAnyDatabase
#角色说明
root:只在admin数据库中可用。超级账号,超级权限;
read:允许用户读取指定数据库;
readWrite:允许用户读写指定数据库;
dbAdmin:允许用户在指定数据库中执行管理函数,如索引创建、删除,查看统计或访问system.profile;
dbAdminAnyDatabase:只在admin数据库中可用,赋予用户所有数据库的dbAdmin权限;
clusterAdmin:只在admin数据库中可用,赋予用户所有分片和复制集相关函数的管理权限;
userAdmin:允许用户向system.users集合写入,可以找指定数据库里创建、删除和管理用户;
userAdminAnyDatabase:只在admin数据库中可用,赋予用户所有数据库的userAdmin权限;
readAnyDatabase:只在admin数据库中可用,赋予用户所有数据库的读权限;
readWriteAnyDatabase:只在admin数据库中可用,赋予用户所有数据库的读写权限;
开启验证模式
操作步骤
1. 添加超级管理员
2. 退出卸载服务
3. 重新安装需要输入账号密码的服务(注在原安装命令基础上加上--auth即可
4. 启动服务 -> 登陆测试
步骤1:添加超级管理员
use admin
db.createUser({
"user" : "admin",
"pwd": "admin888",
"roles" : [{
role: "root",
db: "admin"
}]
})
步骤2:退出卸载服务
bin\mongod --remove
步骤3:安装需要身份验证的MongoDB服务
bin\mongod --install --dbpath D:\MongoDB\MongoDB\data --logpath D:\MongoDB\MongoDB\logs\mongodb2.log --auth
net start mongodb
步骤4:启动服务 -> 登录测试
通过超级管理员账号登陆
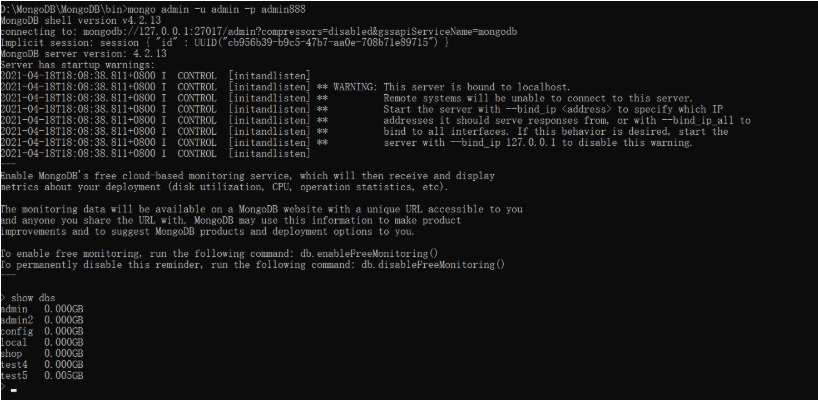
方法1:mongo 服务器IP地址:端口/数据库 -u 用户名 -p 密码
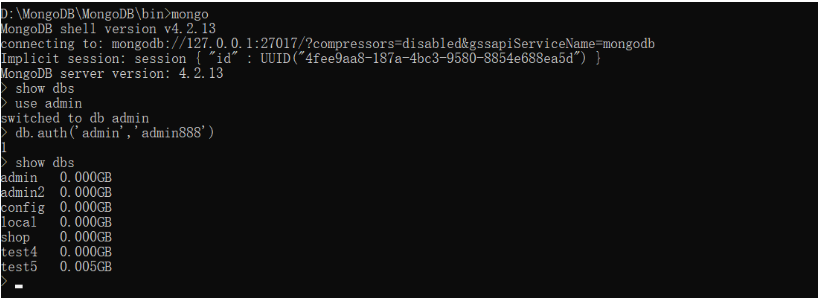
方法2:a-先登录,b-选择数据库,c-输入db.auth(用户名,密码)
对不同用户设置不同的权限
以下为验证
以admin身份登录
新建shop数据库内包含goods数据集,在数据集中插入1000条数据,建立两个shop管理员,shop1能读该数据库,shop2能读能写该数据库,以下是以shop1登录该数据库的演示
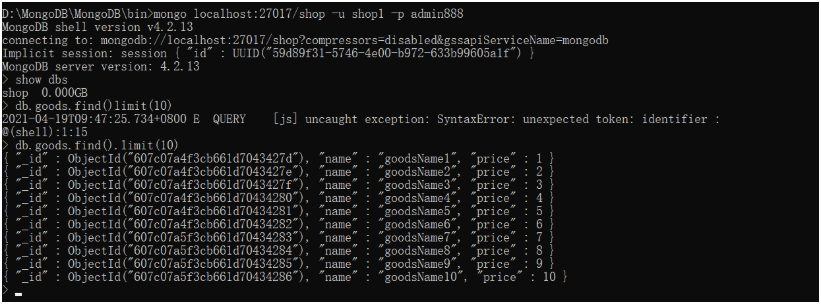
验证是否能写:

以shop2登录该数据库
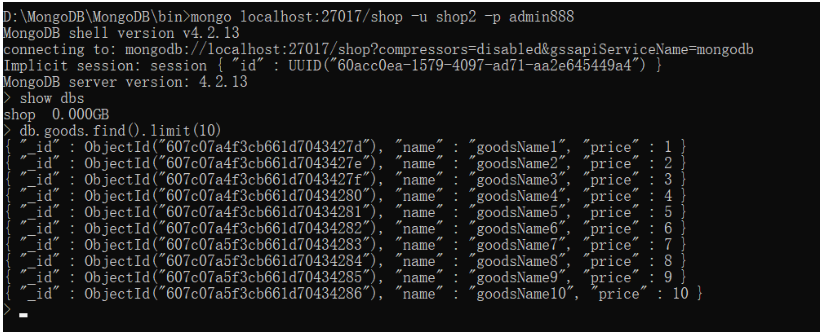
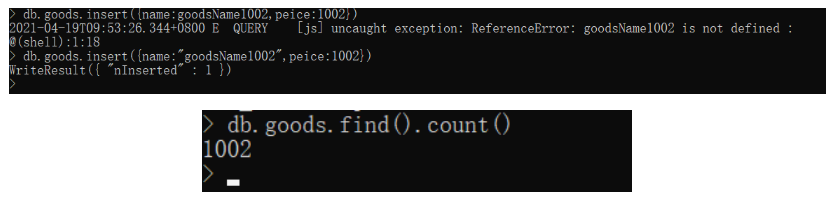
验证是否能写
10.副本集-Replica Sets
简介
MongoDB中的副本集(Replica Set)是一组维护相同数据集的mongod服务。 副本集可提供冗余和高可用性,是所有生产部署的基础。 也可以说,副本集类似于有自动故障恢复功能的主从集群。通俗的讲就是用多台机器进行同一数据的异 步同步,从而使多台机器拥有同一数据的多个副本,并且当主库当掉时在不需要用户干预的情况下自动 切换其他备份服务器做主库。而且还可以利用副本服务器做只读服务器,实现读写分离,提高负载。
(1)冗余和数据可用性 复制提供冗余并提高数据可用性。 通过在不同数据库服务器上提供多个数据副本,复制可提供一定级别 的容错功能,以防止丢失单个数据库服务器。 在某些情况下,复制可以提供增加的读取性能,因为客户端可以将读取操作发送到不同的服务上, 在不 同数据中心维护数据副本可以增加分布式应用程序的数据位置和可用性。 您还可以为专用目的维护其他 副本,例如灾难恢复,报告或备份。
(2)MongoDB中的复制副本集是一组维护相同数据集的mongod实例。 副本集包含多个数据承载节点和可选的一个仲裁节点。 在承载数据的节点中,一个且仅一个成员被视为主节点,而其他节点被视为次要(从)节点。 主节点接收所有写操作。 副本集只能有一个主要能够确认具有{w:“most”}写入关注的写入; 虽然在某 些情况下,另一个mongod实例可能暂时认为自己也是主要的。主要记录其操作日志中的数据集的所有 更改,即oplog。辅助(副本)节点复制主节点的oplog并将操作应用于其数据集,以使辅助节点的数据集反映主节点的数据集。 如果主要人员不在,则符合条件的仲裁将举行选举以选出新的主要人员。
(3)主从复制和副本集区别 主从集群和副本集最大的区别就是副本集没有固定的“主节点”;整个集群会选出一个“主节点”,当其挂 掉后,又在剩下的从节点中选中其他节点为“主节点”,副本集总有一个活跃点(主、primary)和一个或多 个备份节点(从、secondary)。
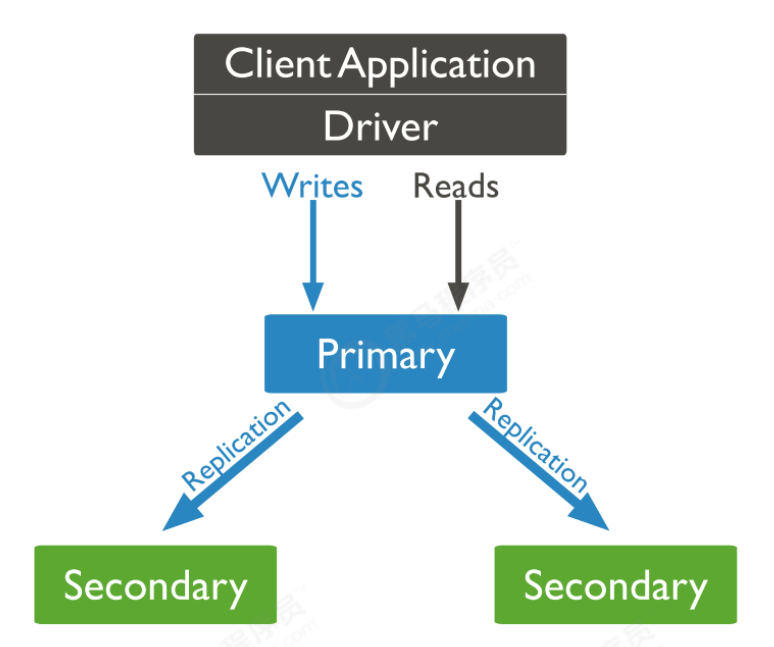
副本集的三个角色
副本集有两种类型三种角色
两种类型:
主节点(Primary)类型:数据操作的主要连接点,可读写。
次要(辅助、从)节点(Secondaries)类型:数据冗余备份节点,可以读或选举。
三种角色:
主要成员(Primary):主要接收所有写操作。就是主节点。
副本成员(Replicate):从主节点通过复制操作以维护相同的数据集,即备份数据,不可写操作,但可 以读操作(但需要配置)。是默认的一种从节点类型。
仲裁者(Arbiter):不保留任何数据的副本,只具有投票选举作用。当然也可以将仲裁服务器维护为副 本集的一部分,即副本成员同时也可以是仲裁者。也是一种从节点类型。
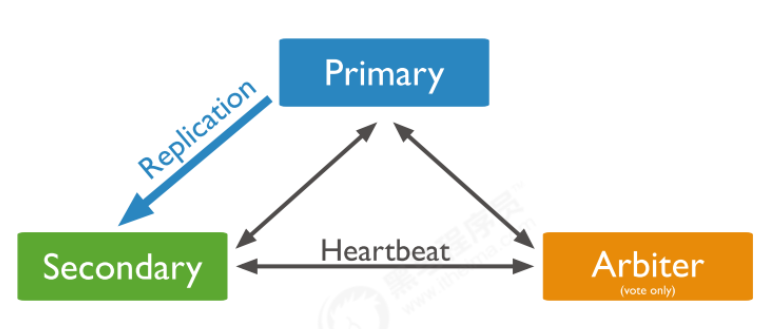
关于仲裁者的额外说明: 您可以将额外的mongod实例添加到副本集作为仲裁者。 仲裁者不维护数据集。 仲裁者的目的是通过 响应其他副本集成员的心跳和选举请求来维护副本集中的仲裁。 因为它们不存储数据集,所以仲裁器可 以是提供副本集仲裁功能的好方法,其资源成本比具有数据集的全功能副本集成员更便宜。 如果您的副本集具有偶数个成员,请添加仲裁者以获得主要选举中的“大多数”投票。 仲裁者不需要专用 硬件。 仲裁者将永远是仲裁者,而主要人员可能会退出并成为次要人员,而次要人员可能成为选举期间的主要 人员。 如果你的副本+主节点的个数是偶数,建议加一个仲裁者,形成奇数,容易满足大多数的投票。 如果你的副本+主节点的个数是奇数,可以不加仲裁者。
副本集架构目标
一主一副本一仲裁
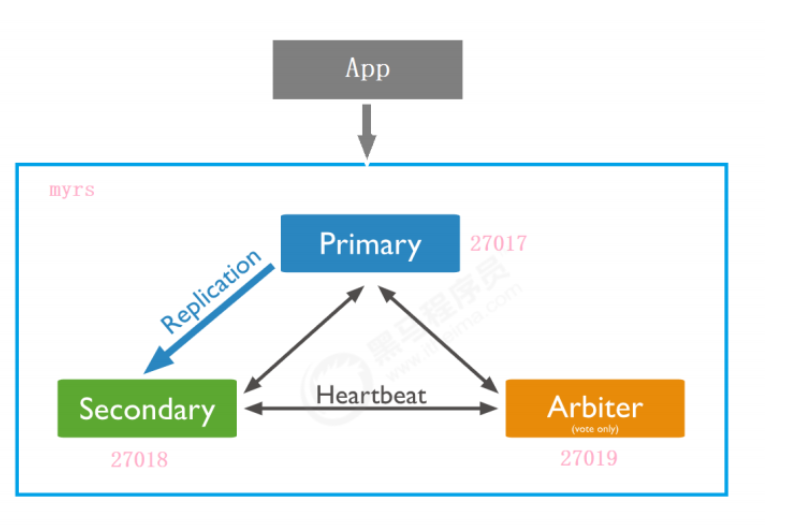
副本集的创建
创建主节点
建立存放数据和日志的目录
#-----------myrs
#主节点
mkdir -p /mongodb/replica_sets/myrs_27017/log
mkdir -p /mongodb/replica_sets/myrs_27017/data/db
#新建或者修改配置文件
vim /mongodb/replica_sets/myrs_27017/mongod.conf
systemLog:
#MongoDB发送所有日志输出的目标指定为文件
destination: file
#mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径
path: "/mongodb/replica_sets/myrs_27017/log/mongod.log"
#当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日志文件的末>尾。
logAppend: true
storage:
#mongod实例存储其数据的目录。storage.dbPath设置仅适用于mongod。
dbPath: "/mongodb/replica_sets/myrs_27017/data/db"
journal:
#启用或禁用持久性日志以确保数据文件保持有效和可恢复。
enabled: true
processManagement:
fork: true
pidFilePath: "/mongodb/replica_sets/myrs_27017/log/mongod.pid"
net:
bindIp: localhost,192.168.0.102
port: 27017
replication:
replSetName: myrs
启动节点:
/usr/local/mongodb/bin/mongod -f /mongodb/replica_sets/myrs_27017/mongod.conf
创建副本节点
建立存放数据和日志的目录
#-----------myrs
#副本节点
mkdir -p /mongodb/replica_sets/myrs_27018/log
mkdir -p /mongodb/replica_sets/myrs_27018/data/db
#新建副本节点的配置文件
vim /mongodb/replica_sets/myrs_27018/mongod.conf
systemLog:
#MongoDB发送所有日志输出的目标指定为文件
destination: file
#mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径
path: "/mongodb/replica_sets/myrs_27018/log/mongod.log"
#当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日志文件的末>尾。
logAppend: true
storage:
#mongod实例存储其数据的目录。storage.dbPath设置仅适用于mongod。
dbPath: "/mongodb/replica_sets/myrs_27018/data/db"
journal:
#启用或禁用持久性日志以确保数据文件保持有效和可恢复。
enabled: true
processManagement:
fork: true
pidFilePath: "/mongodb/replica_sets/myrs_27018/log/mongod.pid"
net:
bindIp: localhost,192.168.0.102
port: 27018
replication:
replSetName: myrs
#启动
/usr/local/mongodb/bin/mongod -f /mongodb/replica_sets/myrs_27018/mongod.conf
创建仲裁节点
#-----------myrs
#仲裁节点
mkdir -p /mongodb/replica_sets/myrs_27019/log
mkdir -p /mongodb/replica_sets/myrs_27019/data/db
vim /mongodb/replica_sets/myrs_27019/mongod.conf
systemLog:
#MongoDB发送所有日志输出的目标指定为文件
destination: file
#mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径
path: "/mongodb/replica_sets/myrs_27019/log/mongod.log"
#当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日志文件的末>尾。
logAppend: true
storage:
#mongod实例存储其数据的目录。storage.dbPath设置仅适用于mongod。
dbPath: "/mongodb/replica_sets/myrs_27019/data/db"
journal:
#启用或禁用持久性日志以确保数据文件保持有效和可恢复。
enabled: true
processManagement:
fork: true
pidFilePath: "/mongodb/replica_sets/myrs_27019/log/mongod.pid"
net:
bindIp: localhost,192.168.0.102
port: 27019
replication:
replSetName: myrs
#启动
/usr/local/mongodb/bin/mongod -f /mongodb/replica_sets/myrs_27019/mongod.conf
初始化配置副本集和主节点
#登录
/usr/local/mongodb/bin/mongo --host=192.168.0.102 --port=27017
准备初始化新的副本集:
语法:
rs.initiate()
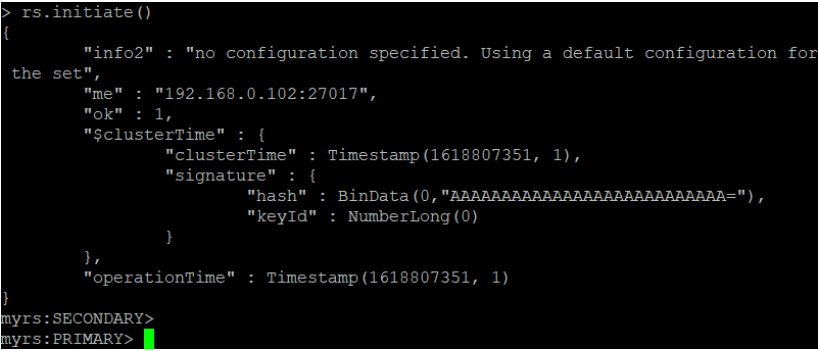
提示:
1)“ok”的值为1,说明创建成功。
2)命令行提示符发生变化,变成了一个从节点角色,此时默认不能读写。稍等片刻,回车,变成主节 点。
查看副本集的配置内容
语法:
rs.conf(configuration)
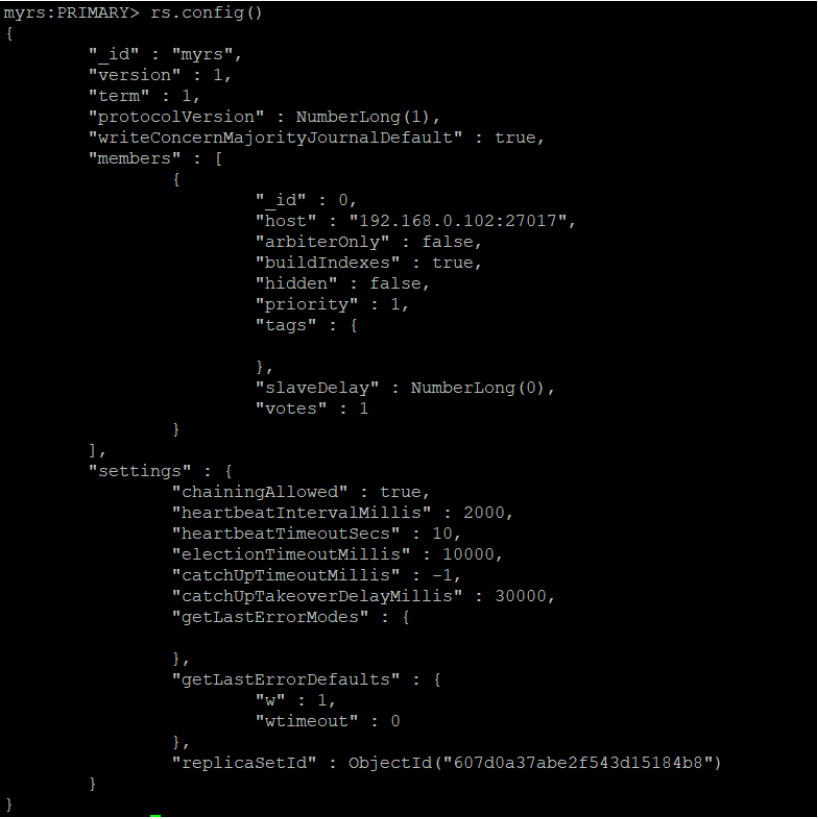
提示:
rs.config() 是该方法的别名。
configuration:可选,如果没有配置,则使用默认主节点配置。
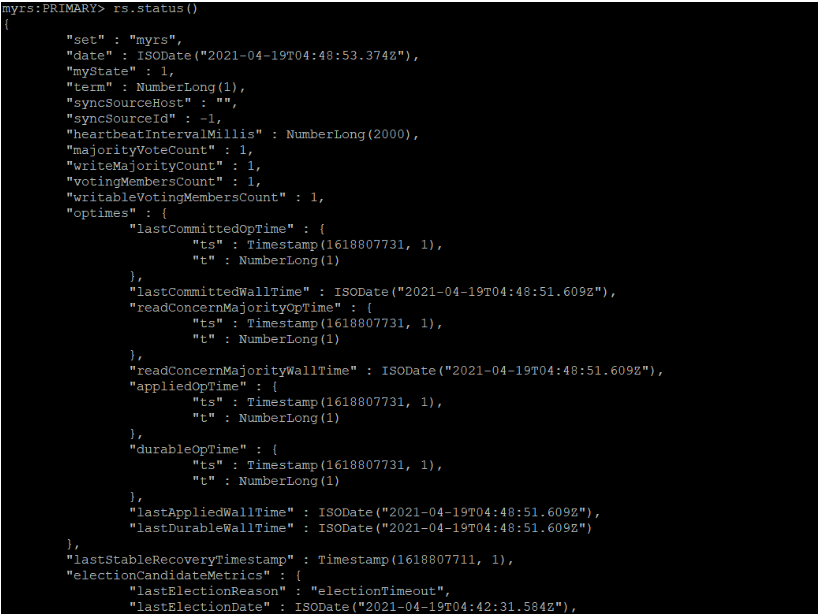
查看副本集的状态
rs.status()
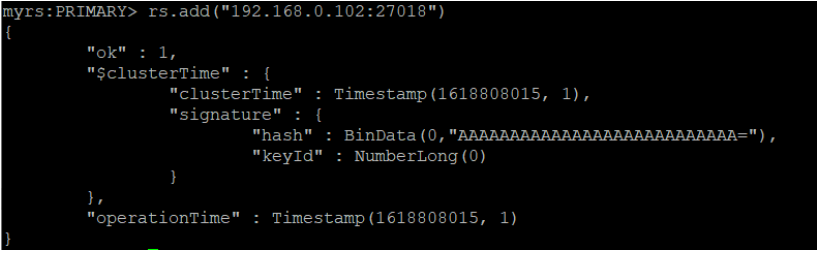
添加副本从节点
语法:
rs.add(host, arbiterOnly)
实例:
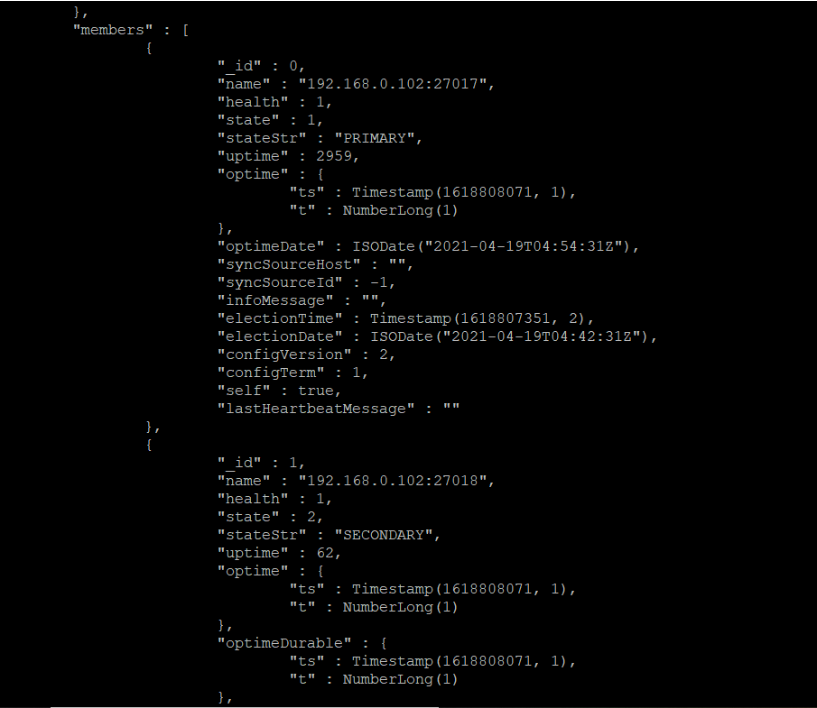
查看当前的副本集状态
rs.status()
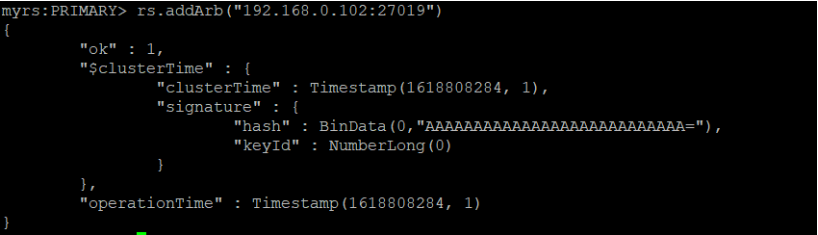
添加仲裁从节点
语法:
rs.addArb(host)
实例:
副本集的数据读写操作
首先登录副本集主节点:
mongo --host=192.168.0.102 --port=27017
写入和读取数据

然后退出,登录到从节点
mongo --host=192.168.0.102 --port=27018
当前状态下无法读取数据,因为slaveok未置true
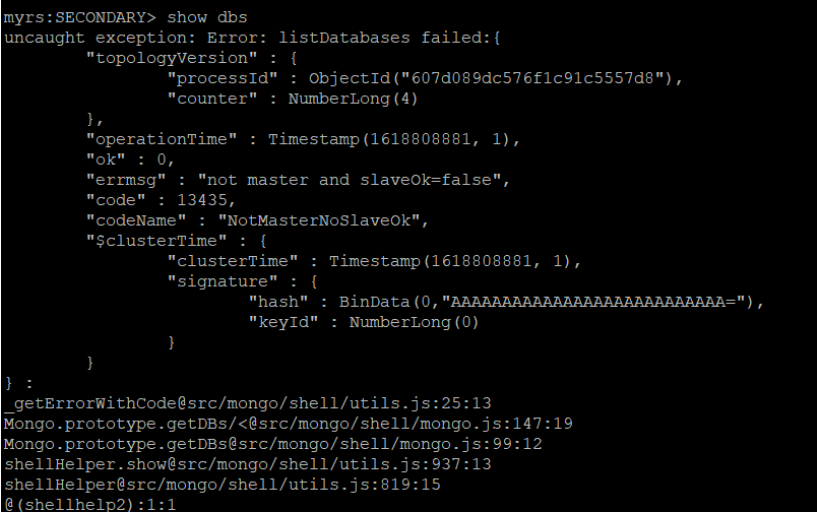
如何修改?
rs.slaveOk()

存在错误信息,可能由于版本信息不同,此处的slaveOk的修改要换成secindaryOk,修改过后即可查询
进入仲裁节点
mongo --host=192.168.0.102 --port=27019
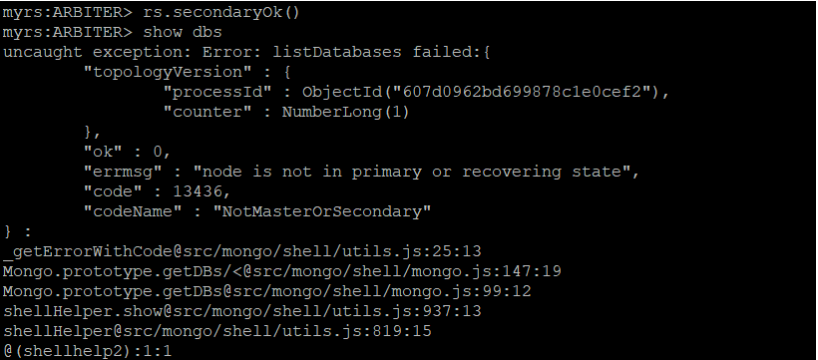
11.分片
分片概念
分片(sharding)是一种跨多台机器分布数据的方法, MongoDB使用分片来支持具有非常大的数据集 和高吞吐量操作的部署。
换句话说:分片(sharding)是指将数据拆分,将其分散存在不同的机器上的过程。
有时也用分区 (partitioning)来表示这个概念。
将数据分散到不同的机器上,不需要功能强大的大型计算机就可以储存 更多的数据,处理更多的负载。 具有大型数据集或高吞吐量应用程序的数据库系统可以会挑战单个服务器的容量。
例如,高查询率会耗 尽服务器的CPU容量。工作集大小大于系统的RAM会强调磁盘驱动器的I / O容量。
有两种解决系统增长的方法:垂直扩展和水平扩展。
垂直扩展意味着增加单个服务器的容量,例如使用更强大的CPU,添加更多RAM或增加存储空间量。
可用技术的局限性可能会限制单个机器对于给定工作负载而言足够强大。此外,基于云的提供商基于可用 的硬件配置具有硬性上限。结果,垂直缩放有实际的最大值。
水平扩展意味着划分系统数据集并加载多个服务器,添加其他服务器以根据需要增加容量。虽然单个机器的总体速度或容量可能不高,但每台机器处理整个工作负载的子集,可能提供比单个高速大容量服务 器更高的效率。扩展部署容量只需要根据需要添加额外的服务器,这可能比单个机器的高端硬件的总体 成本更低。权衡是基础架构和部署维护的复杂性增加。 MongoDB支持通过分片进行水平扩展。
分片集群包含的组件
MongoDB分片群集包含以下组件:
分片(存储):每个分片包含分片数据的子集。 每个分片都可以部署为副本集。
mongos(路由):mongos充当查询路由器,在客户端应用程序和分片集群之间提供接口。
config servers(“调度”的配置):配置服务器存储群集的元数据和配置设置。 从MongoDB 3.4开 始,必须将配置服务器部署为副本集(CSRS)。
分片集群架构目标
两个分片节点副本集(3+3)+一个配置节点副本集(3)+两个路由节点(2),共11个服务节点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号