机器学习笔记2
10. Neural network
10.1 neuron model
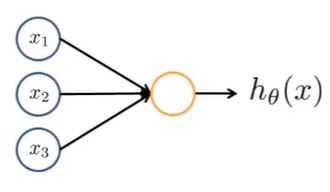
上图便是一个简单的neuron model,\(x_1,x_2,x_3\)是神经元的输入,\(h_\theta(x)\)是神经元的输出。
吴恩达在视频中讲到,会在输入的时候添加一个\(x_0\)的输入,这个输入被叫做bias unit 或者 bias neuron,而且这个\(x_0\)总是等于1(具体的表示如下图所示)。
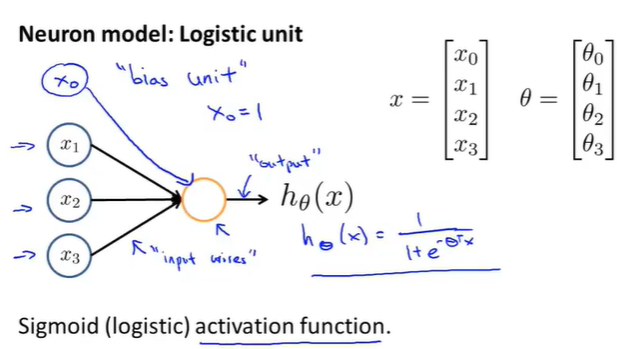
对于上图中的神经元模型,我们定义其是一个:an artificial neuron with a Sigmoid or a logistic activation funciton。
因此在神经网络网络中,对于一个非线性的函数\(h_\theta(x)\)有了一个新的terminology——激活函数(激活函数的引入可以很好的解决非线性的问题,并且还能很好的控制数值的范围,符合概率的性质)。
1989年一个著名的结果,称为通用逼近定理(universal approximation theorem),指出只要激活函数是类sigmoid,并且要近似的函数是连续的,一个单一隐藏层的神经网络可以精确地近似到你想要的程度。
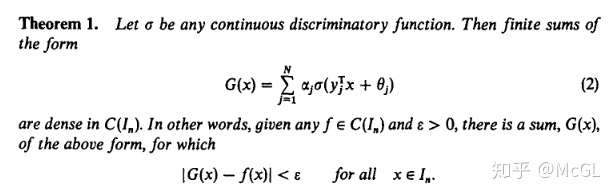
另外,参数\(\theta\)一直被称作是一个参数矩阵,但是在许多的神经网络的文献中也有了一个新的terminology——weights。
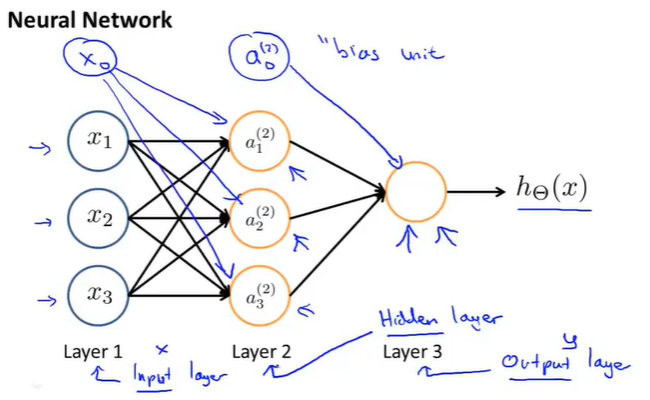
神经网络其实是一组neuron构成的一个网络,如下图所示:
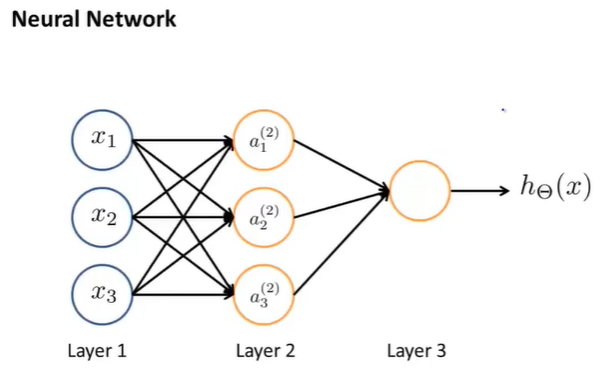
上图中有三个输入,三个神经元\(a_i^{(j)}\)。
接下来再简单引入一些术语或者说明:
- layer1被称作是输入层input layer
- layer3是输出层 output layer
- layer2是隐藏层(非输入层和输出层,也就是说在Supervised Learning中是“看不到”像layer2这样的神经元的,因此被称作是隐藏层,需要注意的是,隐藏层不止一层,往往有很多层)。
- 同样还是有\(x_0\)和\(a_0\)这样的bias unit(有时是不会画出的)
接下来进一步解释神经网络是如何工作的或者说如何进行计算的。
首先还是要简单介绍一个术语或者是表达方式:

\(a_i^{(j)}\)表示一个激活项activation——用于计算并输出某一特定层的神经元。
另外神经网络被\(\Theta\)矩阵给参数化表示了,也即权重矩阵。
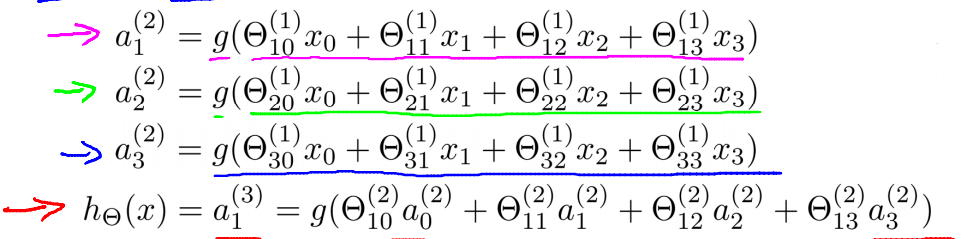
其中\(\Theta^1\)是一个3*4的矩阵,那么用一般化来表示就是——如果第j层有\(s_j\)个单元,第j+1层有\(s_{j+1}\)个单元,那么\(\Theta^j\)就是一个\(s_{j+1}\times(s_j+1)\)维的矩阵(因为需要添加一个值为1的bias unit)。
其实到这里就可以看出所谓的神经网络就是由logistic regression分类器一层层连接起来的产物,通过这种连接,可以构造出复杂的非线性函数用于分类,创造出更好的模型出来。
10.2 forward propagation
这一节主要来说明如何向量化参数,参数之间的关系又是怎样的。
还是以下图为例:
定义\(z_1^{(2)}=\Theta_{10}^{(1)}x_0+\Theta_{11}^{(1)}x_1+\Theta_{12}^{(1)}x_2+\Theta_{13}^{(1)}x_3\),同理可知\(z_2^{(1)},z_3^{(1)}\)。
令\(x=\begin{bmatrix}x_0\\x_1\\x_2\\x_3\end{bmatrix},z^{(2)}=\begin{bmatrix}z_1^{(2)}\\z_2^{(2)}\\z_3^{(2)}\end{bmatrix}=\Theta^{(1)}x,那么a^{(2)}=g(z^{(2)})\),同理可知\(h_\Theta(x)=a^{(3)}=g(z^{(3)})\)。
这就是一个向量化的过程,同时也是一个forward propagation
10.3 example and intuition
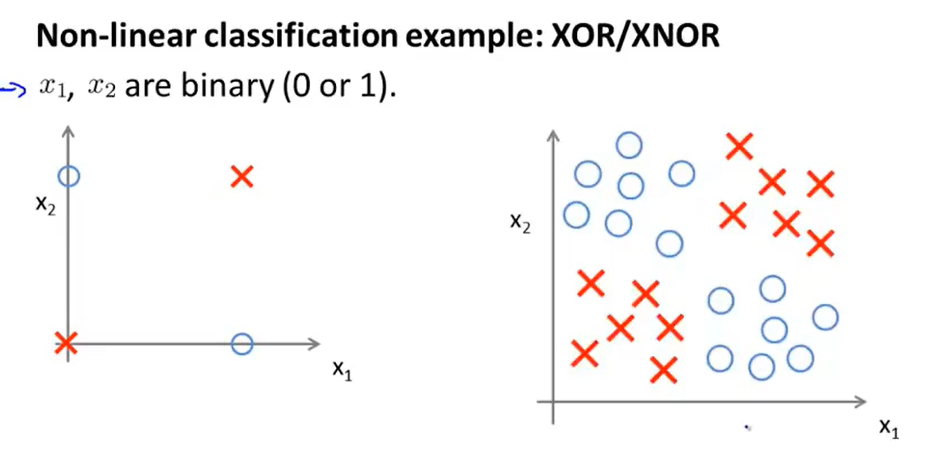
我们可以将左图看做是右图的一个简化版,用于实现分类。
用叉号表示正样本,用圆圈表示负样本。这个例子就是求\(y=x_1 \: XOR \:x_2\)或者\(y=x_1 \: XNOR\: x_2\)两种方式来是实现划分(注意x的取值只是0或者1),这个例子用异或来实现。
如何套用神经网络呢?
再举一个更简单的例子——与运算:
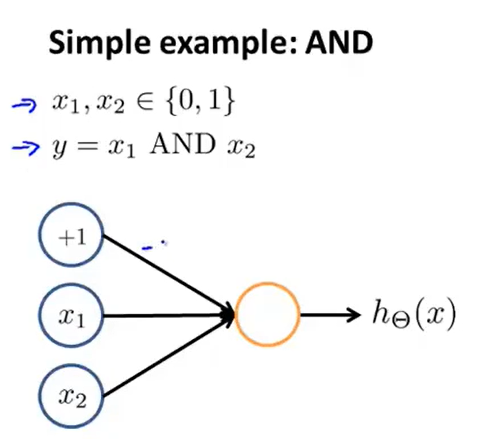
同样需要添加一个值为1的bias unit,那么此时我们假设已经求出了参数或者说权重矩阵,即\(y=(-30+20x_1+20x_2)\),即\(\Theta^{(1)}=\begin{bmatrix}-30\\20\\20\end{bmatrix}\)。
根据sigmoid函数的特性:
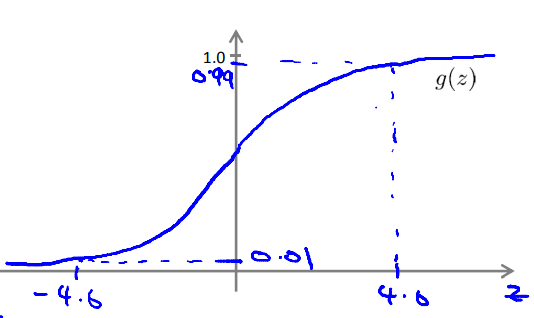
我们根据真值表来严重这个参数求的效果是不是具有与运算的效果:
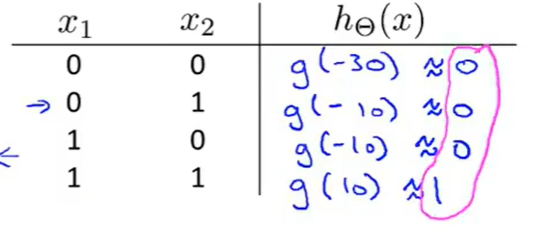
结果是可以的,因此可以说神经网络找到了一组合适的参数值。
我们会发现,不管怎么凑数都是凑不出异或的表达式的,但是异或是可以进一步拆分的:\(a\:XNOR\:b= (\overline{a}\bigwedge{\overline{b}})\bigvee(a\bigwedge{b})\)
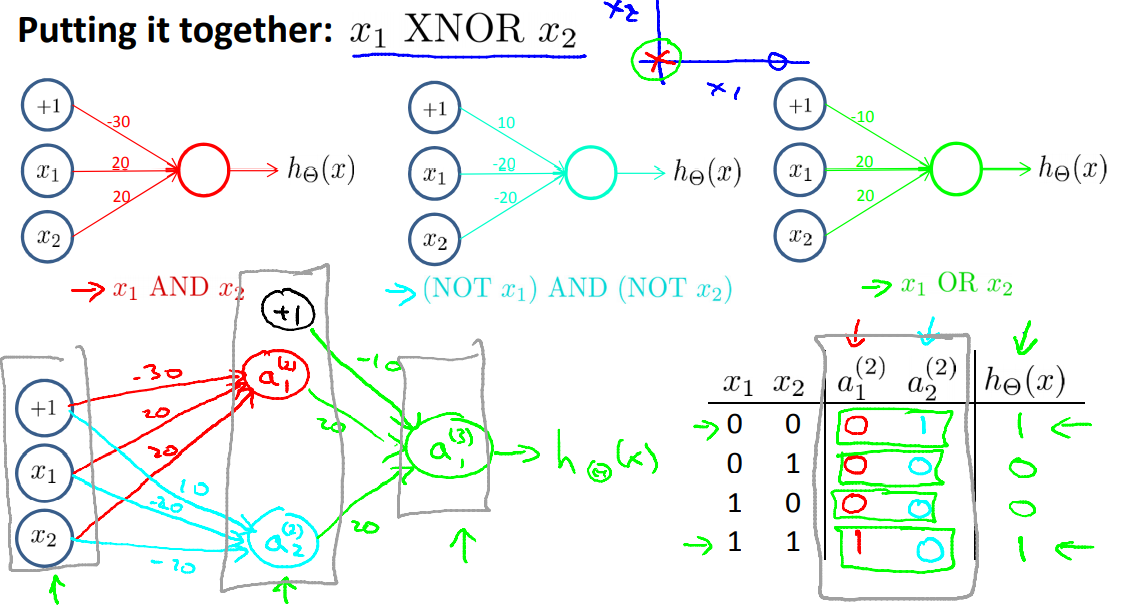
秒啊。
当然这只是两层的简单神经网络,针对于再复杂一些的模型,那就需要更加复杂的神经网络来表达了。
10.4 multi-class classification
多元分类问题其实本质上就是一个一对多的问题。
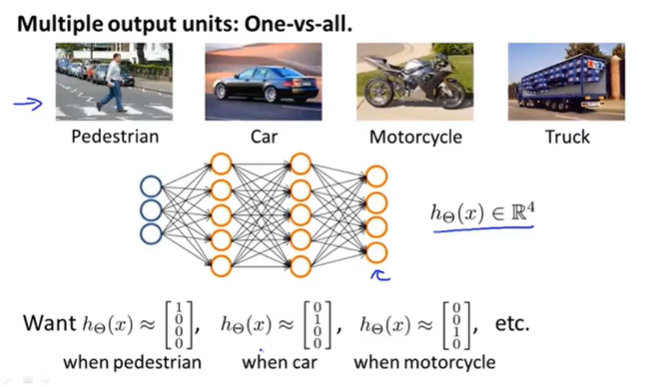
假设需要对pedestrain、car、motorcycle和truck进行分类,输出层的第一个单元用来判断是否是行人,第二个单元用来判断是否是汽车依此类推。
有了神经网络的设计思路,那么剩下的就是需要构建数据训练集了,不再使用以前提到的y=1,y=2,y=3,y=4的这种思路,而是使用向量来表示,正如下图所表示的:
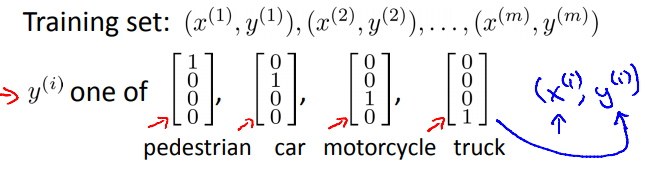
因此一个训练样本就可以表示为\((x^i,y^i)\)了,其中\(x^i\)是四种图像中的一种图像\(y^i\)是上述y中对应于\(x^i\)的向量。那么剩下的工作就是找到合适的参数来表示\(h_\theta(x)=y\)。
11. Cost Function of neural network
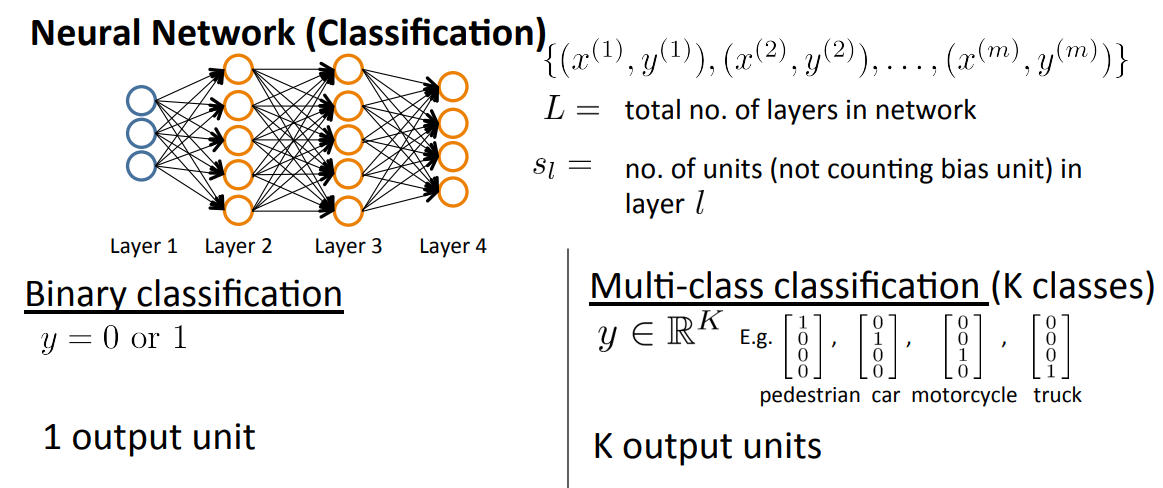
讲到分类问题,最简单的就是二元分类问题,也就是可以通过logistic regression便可以解决的问题,若要是构建神经网络,那么其输出单元就只有1个;
但是如果是多类分类问题,那么只能够用神经网络来解决了,对应的话,在神经网络的输出层会有K(k>=3)个输出单元。
同样地,在损失函数上也会定义出不同的表达形式。
在Logistic regression中,cost function的定义方式如下:
\(J(\theta)=-[\frac{1}{m}\sum\limits_{i=1}^my^{(i)}logh_\theta(x^{(i)})+(1-y^{(i)})log(1-h_\theta(x^{(i)}))+\frac{\lambda}{2m}\sum\limits_{j=1}^n\theta_j^2]\)$
那么在神经网络中,损失函数的定义方式如下:
- \(h_\Theta(x)\)是一个k维向量(最后的输出层),同样\(y_k\)也是一个k维向量,因此k表示第k个输出元素(表示效果如上图pedestrian、car、motorcycles 和 truck);
- m是数据集的大小,上标i表示第i个数据;
- \(\Theta_{ji}^l\)表示第l层第j项neuron的第i个参数;
- 与logistic regression中一样不需要求bias unit,故i从1开始计算,因为\(\Theta_0\)在计算过程中通常是与\(x_0/a_0\)来表示的,也是说不需要把第0项加入到regularization中,但是即便加入了计算也没有关系,最后的结果也影响不大,但是一般情况下倾向于不加入来处理的;
12. Back propagation algorithm
先安利一个讲解Backpropagation可视化的视频——3B1B
12.1 introduction
根据定义的损失函数:\(J(\Theta)=-[\frac{1}{m}\sum\limits_{i=1}^m\sum\limits_{k=1}^K y_k^{(i)}log h_\Theta(x^{(i)})_k+(1-y_k^{(i)})log (1-h_\Theta(x^{(i)}))_k]+\frac{\lambda}{2m}\sum\limits_{l=1}^{L-1}\sum\limits_{j=1}^{s_l}\sum\limits_{i=1}^{s_{l+1}}(\Theta_{ji}^{(l)})^2\)
我们需要去求函数对每一项的偏导数。为了便于计算,先对数据做一些规范化的表示:
为了计算偏导数,便引入了backpropagation algorithm。
定义:\(\delta_j^{(l)}\)表示第l层第j个节点的偏差值
针对于上图,便可以定义\(\delta_j^{(4)}=a_j^{(4)}-y_j=h_\theta(x)_j-y_j\)(至于为什么这样来表示,我觉得是对\(J(\Theta)\)求偏导之后的结果,相当于平方和求导之后结果,也就是说\(\delta\)是一个偏导数值的第一项,而且还是一个4维向量)。
那么用一般的形式表示就是\(\delta^{(4)}=a^{(4)}-y\)表示第4层的所有偏差值。
同理:\(\delta_3=(\Theta^{(3)})^T\delta^{(4)}.*g'(z^{(3)})=(\Theta^{(3)})^T\delta^{(4)}.*(a^{(3)}.*(1-a^{(3)}))\),其中“.*”是matlab中的运算
那么\(\frac{\partial J(\Theta)}{\partial \Theta_{ij}}=a_j^{(l)}\delta_i^{(l+1)}\),j表示第j个参数,i表示第i项。
整个计算方法流程如下:

所有的\(D_{ij}^{(l)}\)加起来就是此次参数的差值。要记住j表示第j个参数,i表示第i项。
这一部分的具体分析可看附件《Backpropagation》一文中的详述以及简单神经网络的搭建实现
12.2 Back propagation intuition
其实要说Back propagation算法,还是需要知道forward propagation,因为这两个算法是相互的,或者说是方向相反的两种计算方法。
还是简单介绍一下forward propagation:
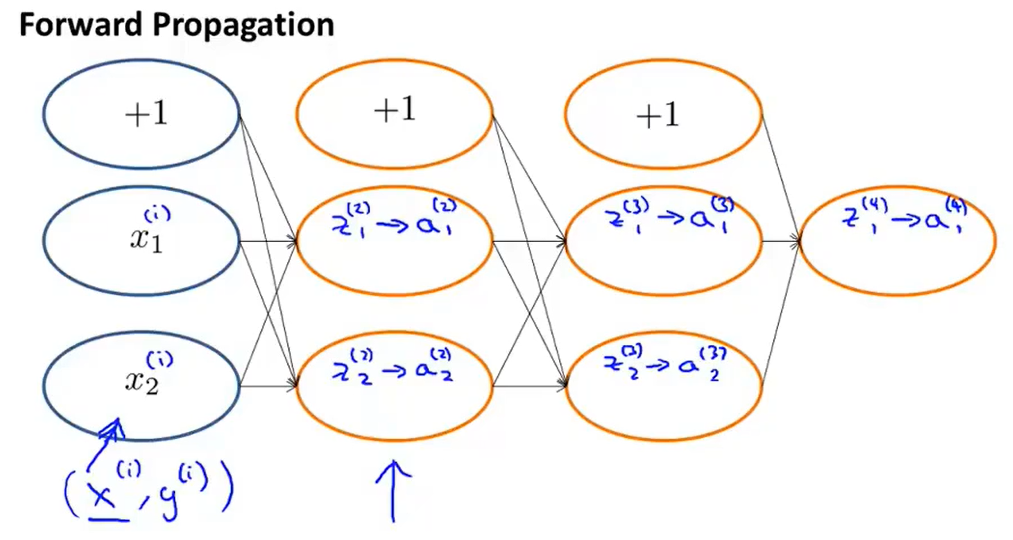
如上图所示,简单的四层神经网络,输入是(xi,yi),除了输入输出层之外,其他的节点都是需要再套用一个激活函数——sigmoid函数,也就是上图中”z-->a“的体现。
那么反向传播是做什么的呢?
假设最后的输出只有一个节点(如果有多个的话,之需要在公式中添加一个求和符号即可):

(注意:上述第一个cost(i)函数写错了)
接下来就是定义了一个\(\delta\)
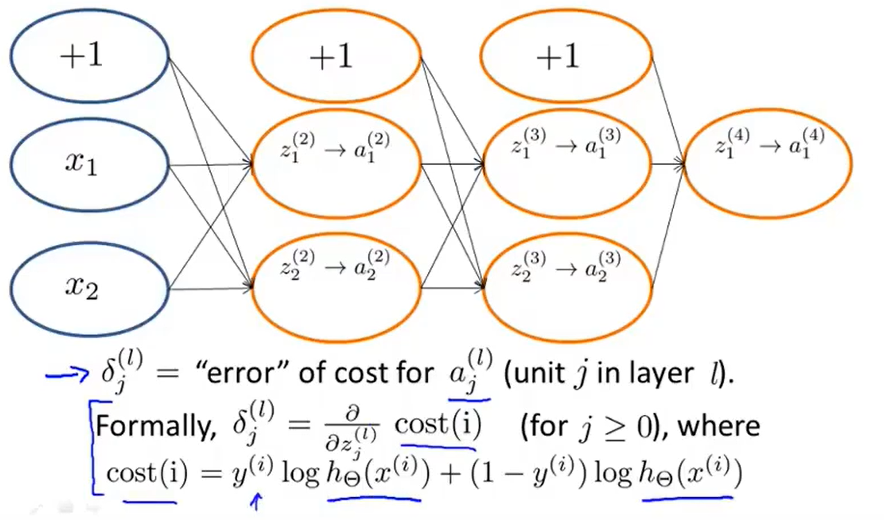
举一个例子来说明\(\delta\)的用处是什么或者说怎么使用:
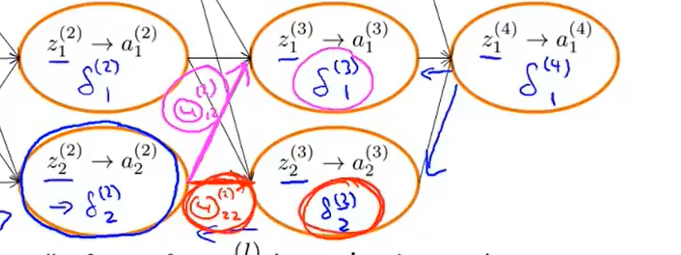
如上图所示,\(\delta_2^{(2)}=\Theta_{22}^{(1)}*\delta_2^{(3)}+\Theta_{12}^{(2)}*\delta_1^{(3)}\),同样其他节点也是同样的计算,其实本质上就是一层层的迭代。
一般来说是不需要去考虑bias unit偏置单元的,因为其数值恒为1,故在计算的时候,是不需要去考虑的。
12.3 Gradient checking
在反向传播的过程中会出现一个bug,当在运用梯度下降或其他先进的算法的时候,看起来是处于一个正常工作的状态,损失函数也在不断地减小,但是神经网络会在相比于没有bug的前提下数量级会高一个数量级。
因此gradient checking可以在梯度下降或者类似梯度下降的算法中,保证forward propagation和back propagation的结果是100%正确的。
实现方法:
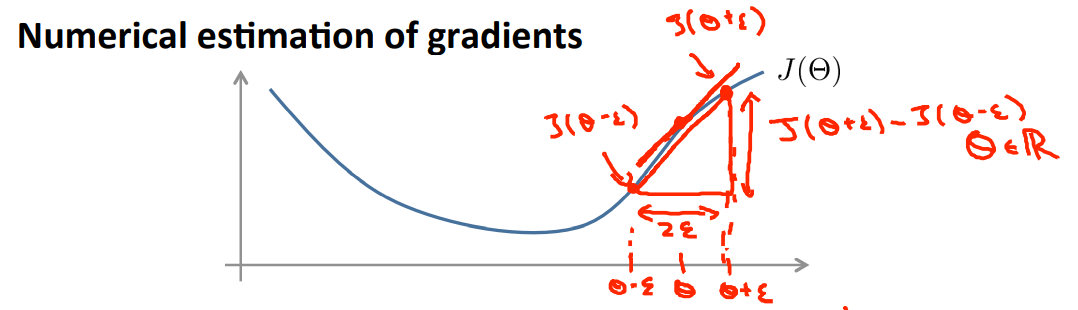
如上图所示,假设在\(\theta\)点处的导数是\(J(\theta)'\),那么取\(\varepsilon\)(大约在1e-4左右),在\(\theta\)的两边各取一个点,分别为\(\theta+\varepsilon和\theta-\varepsilon\),那么函数值分别为\(J(\theta+\varepsilon)和J(\theta-\varepsilon)\)。
若\(\frac{J(\theta+\varepsilon)-J(\theta-\varepsilon)}{2\varepsilon}\)与\(\frac{\text{d}J(\theta)}{d\theta}\)近似相等,我们便认为此时的数值是正确的。
那么在矩阵中表示方法如下:

这个方法是用于检验反向传播的正确性的,也就是说需要依据下面的方法:

其中,最重要也是最关键的部分就是在训练模型之前时候你需要关闭这gradient checking,否则会导致整个训练过程很慢,虽然反向传播很快,但是gradient checking是很慢的,因此如果确定了反向传播的过程是正确,那么就关闭即可
Note:
我认为这个gradient checking是用于在代码编写完成之后进行检验测试的,并非在训练的过程中不断地取检验,因为怕手误导致代码出现问题,一旦确定代码没有问题,便可以进行模型的构建了,当然这里的前提是自己搭建网络来验证的
Gradient checking - 极客锋行 - 博客园 (cnblogs.com)这篇文章比较详细了讲解了什么是Grandiet checking,以及其计算的过程(在forward propagation和back propagation计算过程中跟吴恩达的讲解有些出入,而且back propagation的过程感觉是错误的,没有体现sigmoid函数的求偏导数的过程,可以选择性的看),就是先将矩阵转化为一个一维数组,然后再加减\(\varepsilon\),再转换为矩阵用于计算\(J(\theta)\)
12.4 random initialization
一开始构建神经网络的时候,需要对参数\(\Theta\)进行初始化,那应该选多少呢?
如果初始化全为0或者是全相同的,那么在前向传播的时候,每一个节点的数据都是相同的,那么在反向传播的时候也会导致求偏导数的结果也是相同的,这就会导致,不管进行多少次的传播,都不能收敛,因此需要有一个很好的取值策略才能保证收敛。
一般取\(\varepsilon\)为一个接近于1的值,并且保证\(\Theta_{ij}^{(l)} \in [-\varepsilon,\varepsilon]\)是随机取值即可。
12.5 summary
这一部分主要是总结neural network从搭建到训练的过程:
- 隐藏层的单元的个数一般是输入层特征个数的2~3倍,隐藏层的数量当然越多越好,但是层数多的同时也会导致计算速度太慢;
- 初始化weight,这部分在[12.4](#12.4 random initialization)中讲到了该如何选取;
- forward propagation
- 计算损失函数\(J(\Theta)\)
- back propagation,计算偏导数\(\frac{\partial J(\Theta)}{\partial \Theta_{ij}^l}\)

- 使用gradient checking对比back propagation的\(\frac{\partial J(\Theta)}{\partial \Theta_{ij}^l}\)与数值计算的导数差值
- 使用梯度下降或者更加高级的类似梯度下降的算法来最小化cost function \(J(\Theta)\)
13. Advice for applying machine learning
假设已经构造出自己的hypothesis,进一步便可以得到损失函数\(J(\theta)=\frac{1}{2m}[\sum \limits_{i=1}^m(h_\theta(x^{(i)})-y^{i})^2+\lambda\sum\limits_{j=1}^n\theta_j^2]\)。,但是在预测的时候发现效果太差,那么可能需要改进的地方有如下所示:
- get more test examples
- try smaller sets of features
- try getting additional features
- try adding ploynomial features(\(x_1^2,x_2^2,x_1x_2,etc\).)
- try decreasing \(\lambda\)
- try increasing \(\lambda\)
- ……
但是怎么多该怎没选呢,不能盲目或者靠直觉去选择,比如增加数据集这一种方法,多则6个月来实现,如果到最后发现效果还是不理想,那么这种方法显然会浪费我们大量的时间,得不偿失。因此需要有一种方法可以实现辅助选择——可以帮助我们筛选哪种方法是可以进一步提高效果的。
Machine Learning diagnostic方法即是上面提到解决思想:

13.1 Evaluating a hypothesis
我们知道在训练模型的过程中,会出现过拟合的问题,那么如何判断模型的训练效果呢,或者说如何评估所得到的hypothesis呢?
采用的方法是:
将整个data set 分成两份,其中70%用于训练模型,也就是train set,剩下的30%用于测试模型,也就是test set。
其中数据集的选择要是随机选择的,如果一开始的data set是基于某一权重进行排序的,那就将其打乱之后再去随机选取train set 和 test set。
对于linear regression的处理流程就是:
- 先在train set上进行训练得到参数——最小化cost Function\(J(\theta)\)
- 然后计算在test set 上的误差—— \(J_{test}(\theta)=\frac{1}{2test}\sum \limits_{i=1}^{m_{test}}(h_{\theta}(x_{test}^{(i)})-y_{test}^{(i)})^2\)
那么对于logistic regression或者classification problem的处理流程如下:
- 先在train set上进行训练得到参数——最小化cost function\(J(\theta)\)
- 然后计算在test set 上的误差—— \(J_{test}(\theta)=\frac{1}{2test}\sum \limits_{i=1}^{m_{test}}y_{test}^{(i)}log(h_{\theta}(x_{test}^{(i)}))+(1-y_{test}^{(i)})log(1-h_{\theta}(x_{test}^{(i)}))\)
- 有时还有另外一种测试方法——misclassification error(也叫做0/1 misclassification error,其中1表示预判错误,0表示预判正确):
$ error(h_\theta(x),y)=\begin{cases}1, & \left.\begin{matrix}h_\theta(x)>=0.5,y=0\h_\theta(x)<0.5,y=1\end{matrix}\right}error \0, & \left.\begin{matrix}h_\theta(x)>=0.5,y=1\h_\theta(x)<0.5,y=0\end{matrix}\right}correct\end{cases} $
那么此时\(J_{test}(\theta)=\frac{1}{m_{test}} \sum \limits_{i=1}^{m_{test}}error(h_\theta(x)^{(i)},y^{(i)})\)
13.2 Model selection and training/validation/ test set
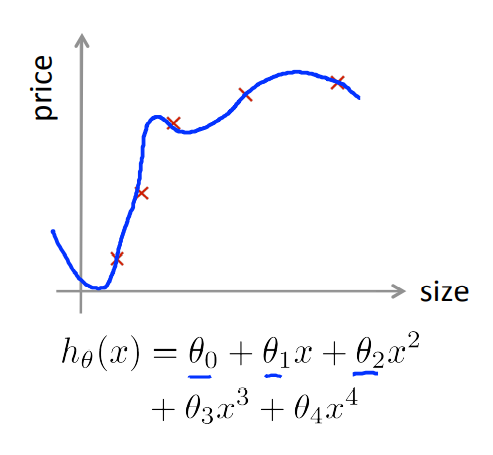
一开始我们通过训练集去不断forward propagation 和 back propagation得到了最后的参数,但是呢,最后得出的模型虽然在train set 上表现得很好,但是在实际使用或者说在其他数据集上的表现就没有那么好了,我们称为这种现象是overfitting。
因为我们训练的模型是要能够泛化generalization,那么问题就来了,如何选择模型呢?
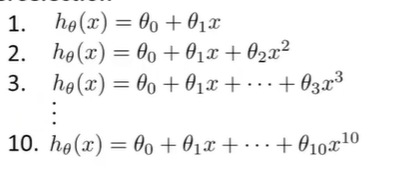
假设存在上述的10个模型,定义d是degree of polynomial(这个d其实可以看做是一个在test set 中需要确定来下的参数)。
因此第一个模型的d=1,第二个模型的d=2,同理,最后一个模型的d=10。
在训练之后,每个模型都能得出一组参数\(\Theta^{(i)}\),既然要选出合适的模型,那么采取的方式就是看这些模型在测试集test set上的误差\(J_{test}(\Theta^{(i)})\)最小的。
假设第五个式子在test set上的表现最好,那么接下来就有另外一个问题,也是最重要的问题,这个选出来的模型的泛化能力generalization怎么样呢?
结果还是不能保证效果如何,那不妨再对数据集进行划分:
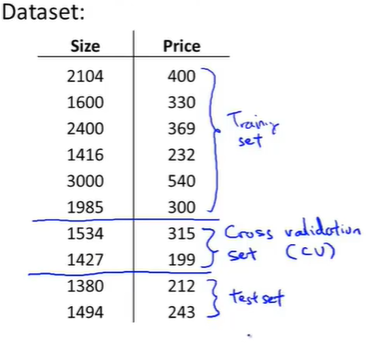
按照3:1:1比例,将数据分为train 、validation(cross validation) and test set三个数据集。

简单来说:
- 先是通过train set来最小化cost function(根据不同的hypothesis,可以得出不同的参数\(\Theta\)),就比如说那10个hypothesis,这样就可以一个个得出在同一套train set下的参数\(\Theta\)。
- 用validation set进行测试上一步得出的10个模型的效果(这次不再使用test set用于测试),其实就是本质上还是拟合参数,不过这次拟合的参数是d。
- 最后用test set来计算generalization的效果。
13.3 diagnosing bias vs variance
如果在运行一个算法的时候,效果不是很理想,那么多半是出现了这两种情况:
1)偏差过大;2)方差过大;
或者对应着说是:
1)underfitting problem ;2)overfitting problem;
(可以用射箭来比喻,偏差小代表射得准,方差小代表射得稳)
那么搞清楚是这两种情况的哪一种,或者说这两种问题都存在至关重要,这样才能对症下药。
还是以下面这张图做说明,当hypothesis的维数不同的时候,对数据的拟合程度也不尽相同,根据下图所示的结果,可以得出当d(definition of degree of ploynomail)等于2的时候,是拟合程度最好的。
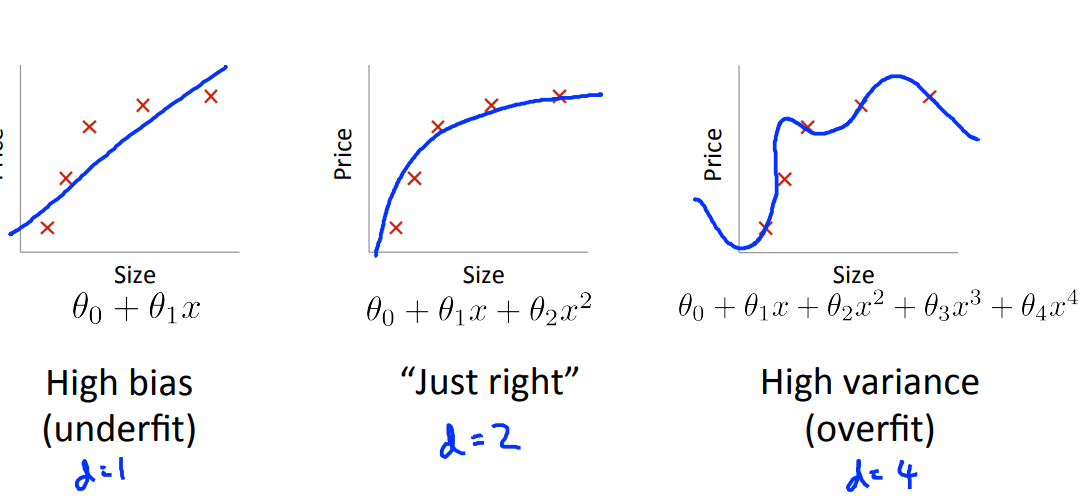
根据[13.2](13.2 Model selecition and training/validation/ test set)中提到的数据的划分,我们针对training error 和 cross validation error进行讨论,根据上图的结论,我们可以在下图的直角坐标系(维度d与误差的关系图,其中d最大为3)中画出\(J_{train}(\theta)\)的曲线,可以发现,随着d的增加,train error是不断变小的:
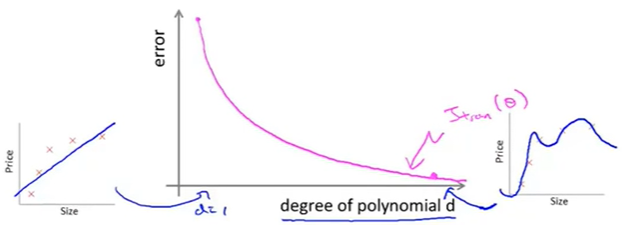
同理,我们还可以得出cross validation error 的效果图如下:
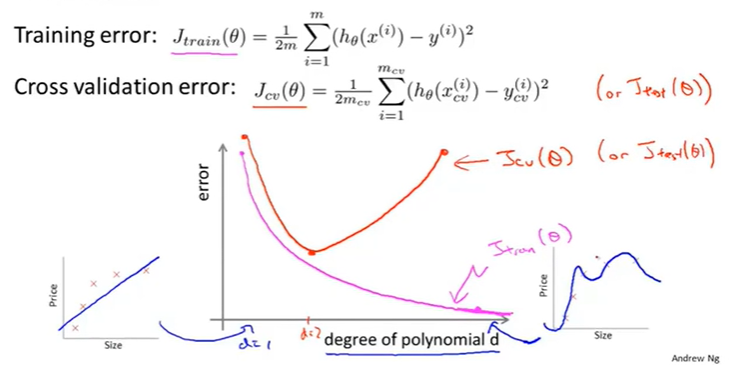
可以看出\(J_{cv}(\theta)\)(红色的曲线)不是随着d的增加而不断变小的,曲线的最低点也即是拟合最好的点(d=2)。
那么回到原来的问题,该怎么判断Learning algorithm是bias problem or variance problem(equivalent to problem of underfitting or overfitting)。
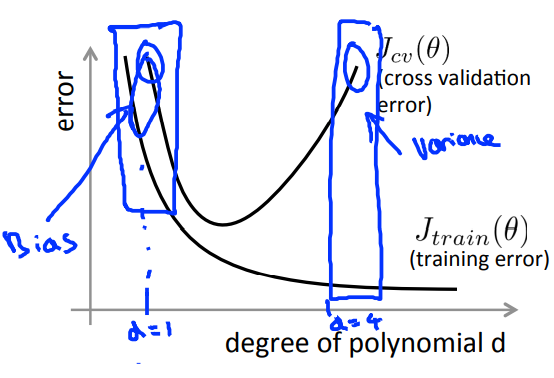
分析上图可以得出的结论为:
-
当是bais problem的时候:
\(\begin{cases} J_{train}(\theta)\:be \: high \\ J_{cv}(\theta)\approx J_{train}(\theta) \end{cases}\)
-
当是variance problem的时候:
\(\begin{cases}J_{train}(\theta)\:be\:low\\ J_{cv}(\theta)>>J_{train}(\theta) \end{cases}\)
以上便是对两种情况的得出的结论。
13.4 the relation of regularization and bias/variance
假设要对如下的式子进行拟合参数\(\theta\),但是为了防止overfitting问题,便引入了regularization项:
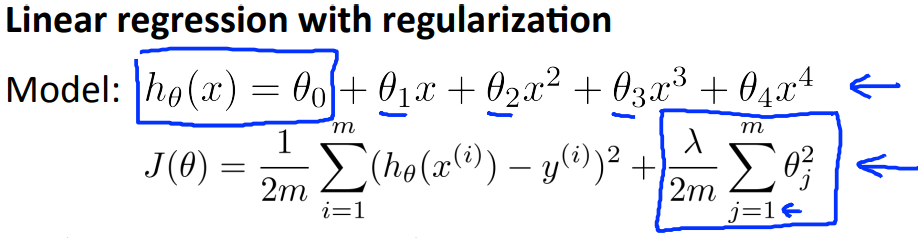
那么\(\lambda\)的取值大小与bias 和 variance有什么关系呢?
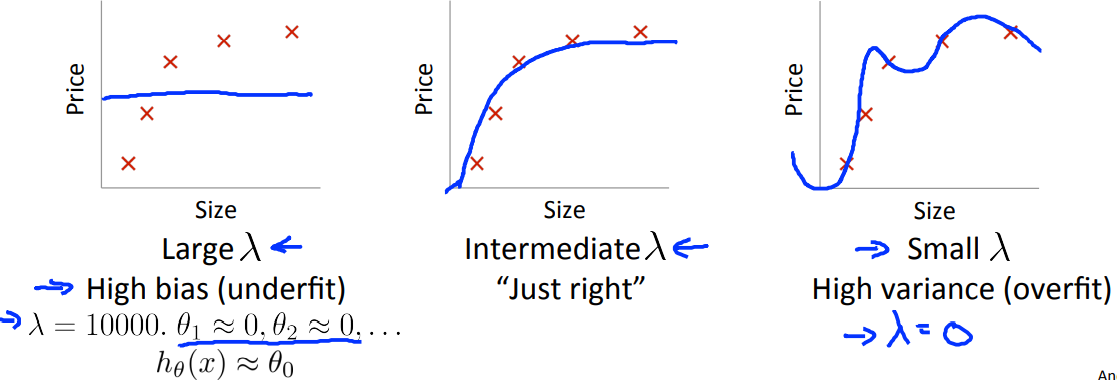
通过上图可以发现:
那么当\(\lambda\)过大的时候,相当于所有的参数\(\theta\)都已经接近于0,那么用图像表示就是一条直线,这种情况就是underfitting,即bias problem;
当\(\lambda\)过小的时候,regularization项几乎没有作用,可以认为是没有了regularization的用处,那么就会导致过拟合的问题,这就导致泛化效果不好,即variance problem。、
选择合适的\(\lambda\),才能很好地拟合数据,那么该如何选择这个参数\(\lambda\)呢?
\(h_\theta(x)\)是我们的模型,\(J_\theta(x)\)是算法学习的目标。假设以下面的模型为例。
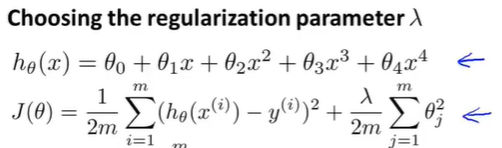
那么该如何选择参数\(\lambda\)呢?
-
假设我们在一个合适的范围内找到10个\(\lambda\);
-
然后将这些参数分别代入到\(J(\theta)\)(包含正则项的那个原始公式)中进行最小化这个值,然后边可以得到10组不同的\(\Theta\);
-
然后将这些参数再分别放到\(J_{cv}(\theta)\)中去,选择其中值最小的作为结果;
-
最后再在test set中经过\(J_{test}(\theta)\)进行评估泛化效果。
以上就是如何选择一个合适的参数的过程。
为了能够更加直观的展示当\(\lambda\)变化的时候,cross validation error 和 training error的变化情况,我们能够得出如下图所示的结果:
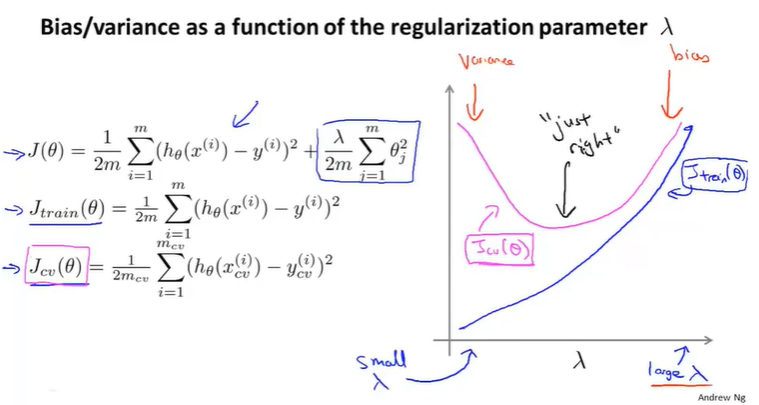
这里需要说明的是\(J(\theta)\)(包含正则化项的)用来求\(\theta\),然后为了比较\(\lambda\)对\(\theta\)的影响,用\(J_{train}\)和\(J_{cv}\)(都不包含正则化项)来绘制上图中的曲线,也就是说训练的时候是用\(J(\theta)\)来训练的,而\(J_{train}\)和\(J_{cv}\)是用来画线说明问题的。
在图像上我们可以看到,当\(\lambda\)过小的时候,偏差很小,但是方差很大;当\(\lambda\)过大的时候,偏差和方差都很大;也就说合适的\(\lambda\)取值应该是在中间的时候。
其实在实际过程中所得出的曲线并没有上述那么理想,实际的数据总是会有很多的噪点存在,那么就会导致有这个图像的曲线并非是光滑的,但是我们还是可以根据图像得出大体上推测出\(\lambda\)的取值是否合适。
13.5 Learning curve
如果想要检查自己的算法是否是正确的,或者想去improve performance of the algorithm的话,Learing curve是一个很好的工具。比如可以用于检测是否有bias problem 或者 variance problem等问题。
什么是学习曲线,其实这是一个抽象的概念,也就是说,学习曲线不是指单一的曲线,而是指一类曲线,上述讲到的坐标系(13.3【degree of the polynomial & error】和13.4【\(\lambda\) & error】中讲到的)就是有学习曲线,接下来讲到的两种也是学习曲线,目前来说学习的学习曲线主要有:【机器学习】学习曲线(learning curve) - 知乎 (zhihu.com)
那么接下来再引入一种学习曲线——【training set size & error】。
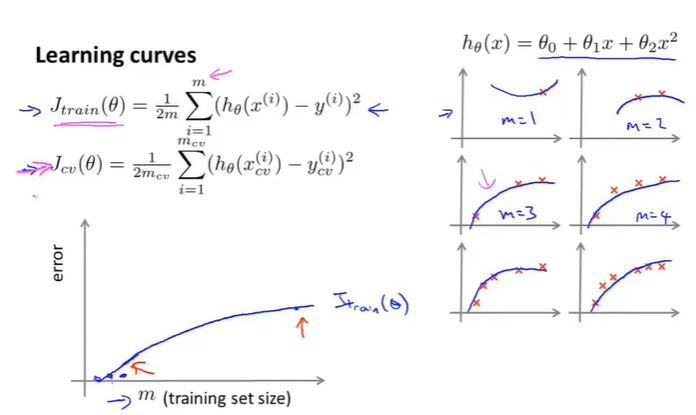
假设有100组数据,即m=100,但是我们想看看数据集的大小对learing algorithm的影响,因此我们人为的取m=1,m=2,m=10,m……这样的数据来验证。
如下图所示,假设hypothesis是一个二次方项的函数,那么当m=1,m=2,m=3的时候,可以发现\(J_{train}(\theta)\)函数拟合的非常好,loss是0(可能如果加入了正规化项会有轻微的偏差,但是影响不大)。
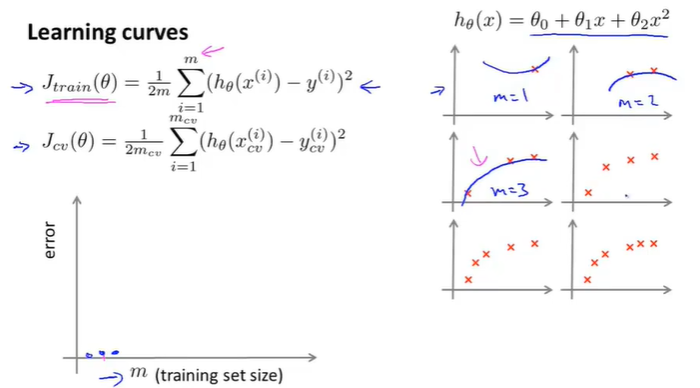
当m=4,m=5,m=6的时候,拟合效果就不如m=1和m=2,m=3的时候了,因此随着m的增大,\(J_{train}(\theta)\)也在不断地增大。效果如下图所示:
那么说完了\(J_{train}(\theta)\)的情况,\(J_{cv}(\theta)\)在cross validation set的情况是怎么样的呢?(这里吴恩达没有说cross validation set的数据集是不是从100-m中获取的,但是我猜测是这样的):
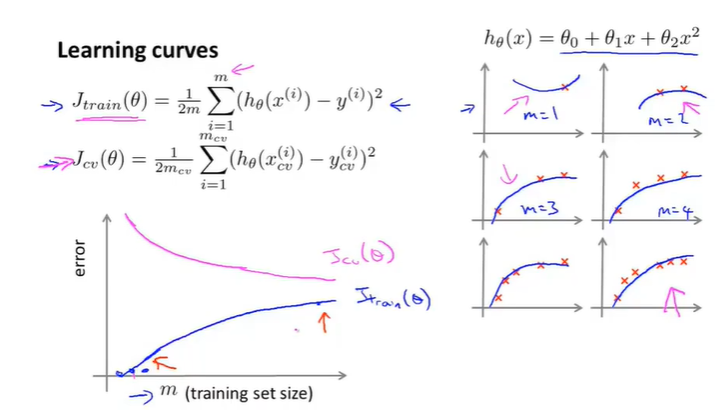
从上图中可以发现,一开始的\(J_{cv}(\theta)\)的效果很不好,因为在训练的时候,拟合程度还不够,因此会造成很大的偏差,但是随着训练集的增大,\(J_{cv}(\theta)\)的值也开始变小了,也就是说明有了很好的泛化能力。当然上述的情况还是一个理想的情况,只能说是一个大致的走向趋势。
那么我们看看在出现High bias(欠拟合)和High variance(过拟合)的问题前提下,两个曲线的变化情况是什么样子的。为了便于阐述,这里的hypothesis取一个简单的一次函数来表示。
-
在High bias的前提下得出两者曲线效果如下:
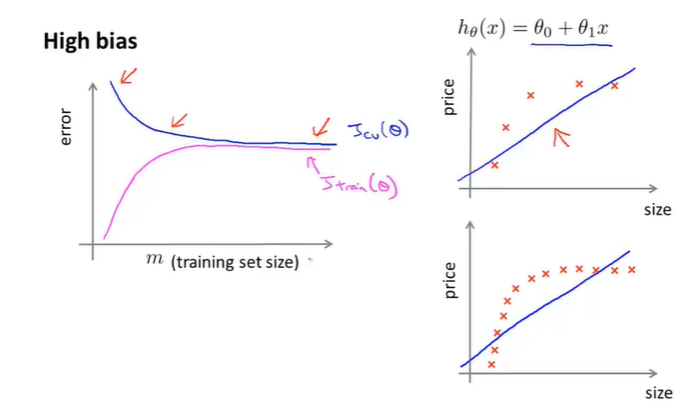
可以发现,随着训练集的增加,两者的值非常接近,这是因为参数少,而数据集很大,那么就会使两者的误差都很大,那么就会在图像上表示出曲线相近的情况。
那么可以得出一个结论:
- 如果说learning algorithm处于一个high bias的前提下,那么增加数据集对我们模型的优化的帮助几乎是没有用的,简而言之就是想通过增加数据集来实现模型优化是一个浪费时间的做法。
- 这也从侧面说明,知道自己的模型是否是处于high bias的情景下,对于修改模型的方法指明了方向,避免了增加数据来实现优化。
-
在High variance的前提下得出两者曲线效果如下:
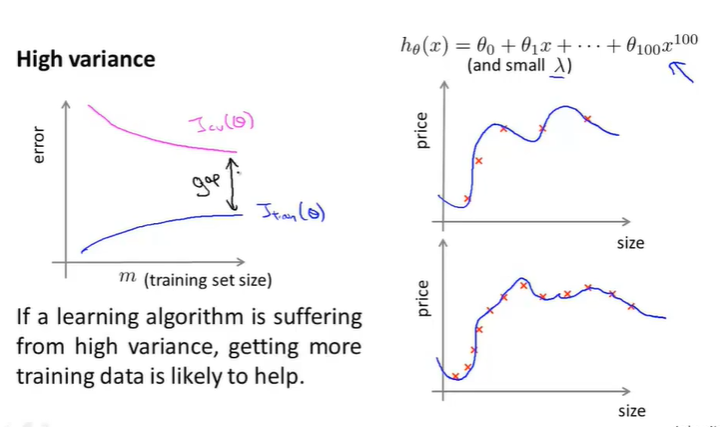
可以发现,随着m的增加,两者的值不是那么的接近。但是我们继续增加训练集的大小,在图像上表示就是,x坐标轴继续延伸,可以发现效果如下:
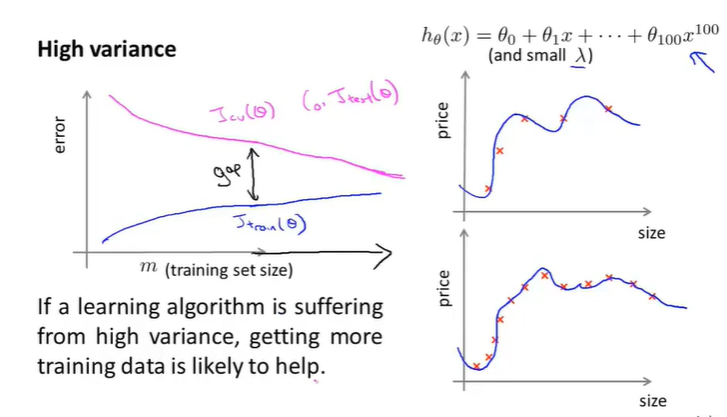
那么可以得出一个结论:
- 如果说learning algorithm处于一个high variance的前提下,那么增加数据集的大小对优化提高模型有一定的帮助。
13.6 summary
回到一开始在[13](#13. Advice for applying machine learning)里面一开始讲到的问题——如何进行优化自己的learning algorithm。
通过整个13的了解与学习,可以得出如下的结论:
- 当处于high variance 的时候 --> get more test examples
- 当处于high variance 的时候 --> try smaller sets of features
- 当处于high bias 的时候 --> try getting additional features
- 当处于high bias 的时候 --> try adding ploynomial features(\(x_1^2,x_2^2,x_1x_2,etc\).)
- 当处于high bias 的时候 --> try decreasing \(\lambda\)
- 当处于high variance 的时候 --> try increasing \(\lambda\)
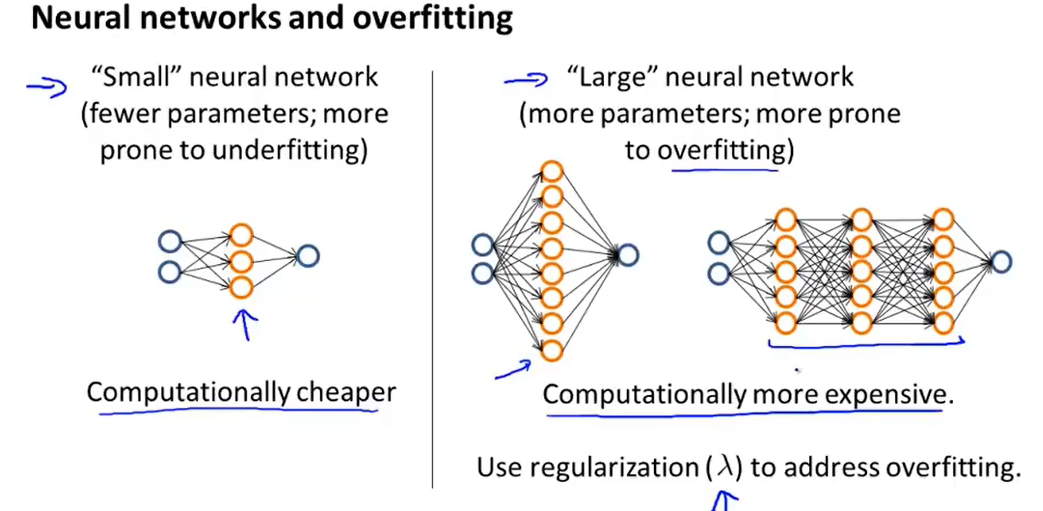
一般来说,一个更复杂的网络的拟合效果是优于一个简单的网络的,对于其表现出的过拟合的效果,可以通过调整正规项的参数\(\lambda\)来达到较好的拟合效果。那么至于隐藏层的个数,那就需要自己不断地去测试哪一个数量在cross validation上的效果最好,从而确定最后的隐藏层。
14. Machine learning system design
14.1 Prioritizing what to work on
假设现在需要设计一个神经网络——邮件的垃圾分类问题。

在设计一个垃圾邮件分类器的时候,应该如何设计才能在有限的时间内,获得高准确率和低错误率呢?
比如在设计spam classifier的时候,可能有以下的设计思路:

那么这一节的内容就是如何用系统的分析方法来选择一个“性价比”高的实现方法。
14.2 Error analysis
如果是想要准备设计一个机器学习的应用,那么通常最好的办法就是设计一个不是很复杂且有多特征的系统。或许这个系统并非很完美,并且效果也不是很好 ,那么具体地推荐方法就是:
- 开始设计一个简单的算法,并且可以快速实施的,然后在cross-validation set上测试这个算法;
- 画出learning curve来判断效果,进而决定是采用哪种策略优化(增加数量,降低特征数量……);
- Error analysis:这一步就是看在cross-validation set上运行的结果,比如是做了一个垃圾邮件分类器,分析出被错误分类的数据,找出其中的特征,看看能不能通过增加特征,来达到优化的目的。

比方说在被错误分类的数据100个例子中,有有关医疗的,卖假货的,盗取密码的,还有其他的:

假设有关盗取密码的有53个,那么重点攻克的就是从这53个样例中看是否有什么特征,可以进行优化。
比如可以从拼写错误,来源不正常,标点错误等:

那么在改进算法中另外一种方法——numerical evaluation(具体是什么后面会讲)。
先说应用的例子:

如上图所示,判定discount、discounts、discounted、discounting是否是一个意思,只需要用提词软件提取前个字母就可以了,但是如果遇到了university和universe就不能这样处理了。
那么这样的处理方法到底是不是一个好的方法呢,思路到底有没有错呢。此时Error analysis可能不能确定这个决定是否正确的,因此便引入了numerical evaluation的概念,其实通俗来讲就是通过数值来判断用提词软件与不用提词软件在cross validation上的效果,只不过是换了一种名字来叫。

假设得出的结论是不用提词软件的误差为5%,用提词软件的误差为3%,那么就说明用提词软件的优化策略是对的。
14.3 Error metrics for skewed classes
所谓的error metrics就是在14.2中提到的错误率——模型效果的反映值,但是纯粹靠这样一个小数不能断定算法的好坏,因为在某些特殊的情况下,单靠error metric是会出问题,比如这一小节要讲到的skewed classes。
以下面癌症分类的例子来说明什么是skewed classes,如下图所示:

假设存在这样一组数据集,患者人数占总数据集的0.5%,一开始的算法y1错误率(也就是上面说到的error metric)能维持在1%,从这个数据上来看,效果以及很好了。
那么假设我们纯粹是为了降低这个error metric ,定义一个非机器学习的算法,这个算法不管输入什么数据,输出都是0(根据定义y=0表示不生病),那么算法如下:
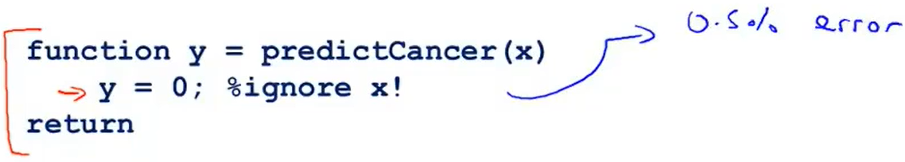
因为整个数据集的患者人数就是为0.5%,然而上面的这个“投机取巧”的算法的输出正好满足数据集,但是我们知道,这样的算法并不是一个好的算法,我们便称这样的一种情况是skewed classes——正样本(y=1)比负样本的数值非常非常小。
为了能更好的评价一个算法,便引入了一个新的判断标准——Precision & Recall
| actual class = 1 | actual class = 0 | |
|---|---|---|
| predict class = 1 | True positive | False positive |
| predict class = 0 | False negative | True negative |
通过图像来表示:

引入了四个名词,通过这四个名词来定义 Precision & Recall

-
Precision 表示为在预测是正样本的患者中,真正患者占在所有预测为正样本比值是多少。用公式表示就是:\(\frac{True \: positive}{True\:positive + False\:positive}\)

-
Recall的定义为在真正的患者中,正确预测为患者的比例是多少。那么用公式表示就是:\(\frac{True \: positive}{True \: positive+False \: negative}\)
通过这样的定义,我们就能够排除掉一开始定义的“投机取巧”的办法,因为那种办法recall值为0,那种方法是不会预测出正样本的。
通俗地来说,Precision 就是检索出来的条目中(比如:文档、网页等)有多少是准确的,Recall就是所有准确的条目有多少被检索出来了。
这样我们可以说一个算法的precision和 recall都高的时候,便认为是一个好的算法。
我们当然希望检索的结果P越高越好,R也越高越好,但事实上这两者在某些情况下是矛盾的。
需要注意的是,我们习惯性的定义正样本y=1表示我们希望预测的并且占总样本很小的分类

14.4 Trade off precision and recall
上一节讲到了skewed classes是什么,这一节主要是来讲一讲precision和recall的平衡问题和介绍一种有效将precision和recall作为evaluation metric的方法。
为什么要讲到这个平衡问题呢,因为与logistic regression的阈值定义有关。
还是以癌症患者确诊的例子为例,假设有100个需要检查的人,真正的癌症患者为20人,80人是正常人,设\(0<=h_{\theta}(x)<=1\):
- if predict y=1,\(h_{\theta}(x)>=0.5\)
- if predict y=0,\(h_{\theta}(x)<0.5\)
那么在设定为0.5的时候,检查出有50人是可疑患者,其中有10人是真正的患者,40人是误判的,那么此时的precision=\(\frac{10}{10+40}=0.2\),recall=\(\frac{10}{10+10}=0.5\)
那么现在想要提高这个阈值,也即是想要将判定癌症的标准提高,不妨设为0.7,那么:
- if predict y=1,\(h_{\theta}(x)>=0.7\)
- if predict y=0,\(h_{\theta}(x)<0.7\)
此时会得出high precision & low recall;
为什么是这样的结果呢,那么在设定为0.7的时候,检查出有30人是可疑患者,其中真正的患者人数是8人,22人是误判的,那么此时precision=\(\frac{8}{8+22}=0.36\),recall = \(\frac{8}{12+8}=0.4\)
那么现在开始想要更多地来确保不会出现漏诊的情况,也就是降低这个阈值,不妨设为0.3,那么:
- if predict y=1,\(h_{\theta}(x)>=0.3\)
- if predict y=0,\(h_{\theta}(x)<0.3\)
此时会得出high recall & low precision。
在设定阈值是0.3的时候,检查出有60人是可疑患者,其中真正的患者人数为20人,误判的是40人,此时precision=\(\frac{20}{20+40}=0.3\), recall=\(\frac{20}{20}=1\)
注:这只是假设,表达的是一个趋势而已。
那么我们就可以得出recall precision和threshold的关系图(还是一个大致图像,有可能是三条中的其中一条吧,但是还是想要表达的是一个趋势——recall与precision大体上呈现的是一个反比的关系):
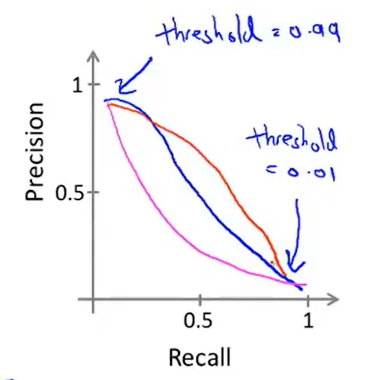
那么问题来了,到底该怎么确定这个recall与precison呢,也就是说下图中的三个算法,哪一个是比较好的呢?

这里采用的是一个由于历史问题留下的计算公式F1 Score来判断的,该值越高越好(这三组值是通过不断的计算在不同的threshold下,通过在cross validation数据集中进行得出的结果,最后认定algorithm1是最好的)。
14.5 Data for machine learning
这一节来讲用于训练的数据集大小,尽管之前讲到盲目地增加数据集的大小,得到的结果不一定是理想的,但是在某些条件下(至于是什么条件是这一节要讲到的),在有效的算法中增加数据集大小是一种有效提高算法表现的方法。
通过一项数据研究发现,这个例子类似于选词填空,通过增加数据集的大小,算法的表现能力不断地增强,并且还会出现一开始表现不好的算法在随着数据集的增大,表现能力逐渐强于一开始表现良好的算法了:
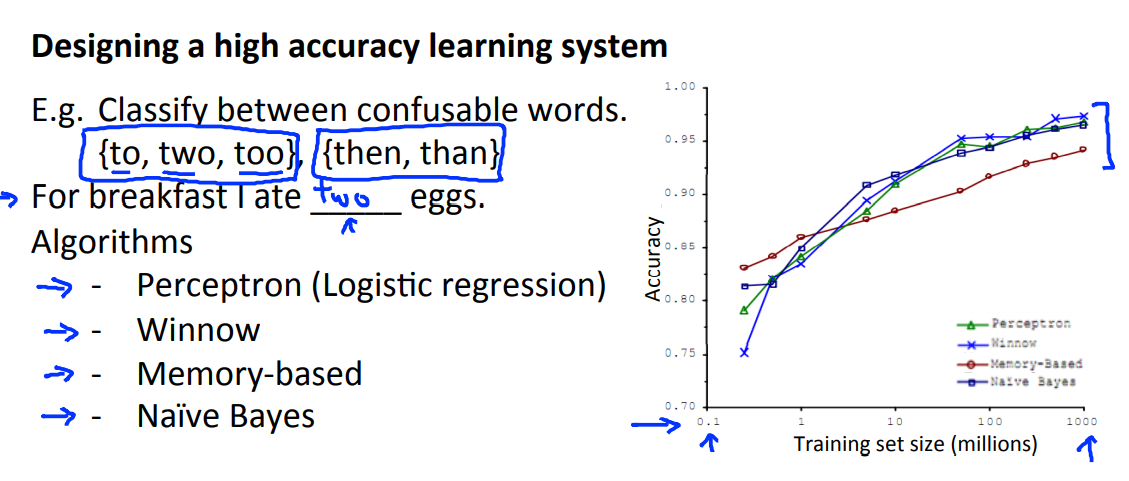
这就出现了一句话:It's not who has the best algorithm that wins. It's who has the most data.
那么究竟是什么时候上面那句话才是成立的呢?
假设我们有一个含有有效信息的数据集,这个数据集可以很好地预测出y,还是用了选词填空的例子。
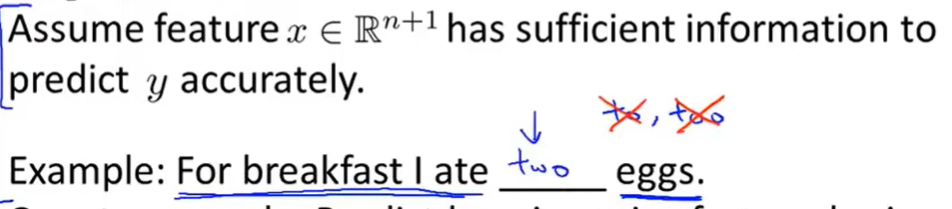
那么我们反过来想,什么样的是一个不好的数据呢?用预测房价的例子,这个数据集只有一个feature,假设是房间的大小,没有其他的了。那么训练的效果是相当差劲的,因为就算是一个房价预测的专家也不可能仅凭着房间的大小就可以预测出房价来。
那么边可以得出一个小结论——数据集一定要包含有效的属性。

只要是算法有很多的参数,数据集有很多的属性值,那么算法就有很低的bias;只要是数据集很大,数据集的数量级大于属性的数量级,那么算法就有很低的variance,不会出现过拟合的现象。
总得来说就是:数据集要有很多的属性,算法要有很多的参数,那么这样的模型一般在大量的数据集下训练,其效果是不会差的。
15. Support Vector Machines
15.1 Optimization object(其实这一部分我也不清楚是不是在说SVM)
这一小节是来简单地讲解svm的数学定义。
为了描述svm,就从logistic regression开始,通过这个来得出svm。
先考虑单数据的情况,下面是逻辑回归损失函数的定义,我们令\(Z=\theta^Tx\):
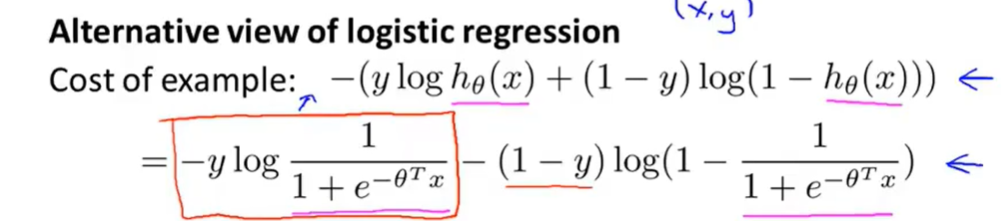
然后画出y=1的图像:
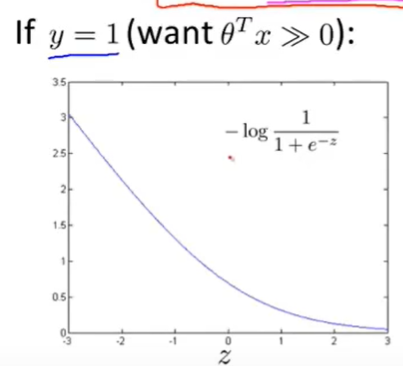
那么SVM的图像分成了两段来表示:
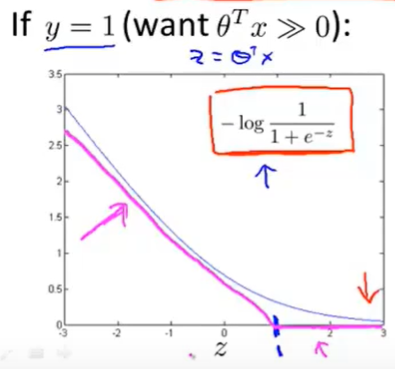
同理可以画出y=0的时候的图像:
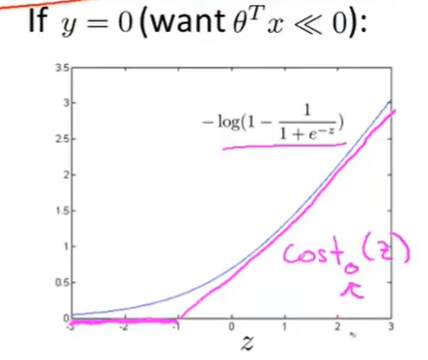
在这里定义当y=1的时候,SVM的函数表示为\(cost_1(z)\);当y=0的时候,SVM的函数表示为\(cost_0(z)\),因此便可以得出SVM的cost function:
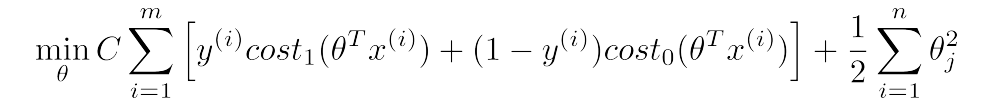
(注意式子中的C不是原始式子中的\(1/\lambda\))
与逻辑回归不同的是,SVM不会输出概率。
那么SVM的hypothesis数学定义如下:
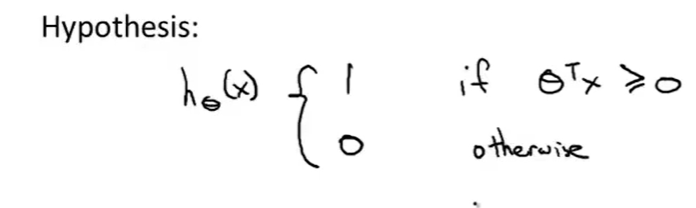
不同于[logistic regression](#7.1 Logistic regression),SVM进行直接的预测,不会像logistic regression中,hypothesis输出是一个概率,SVM直接输出0或者1。
15.2 Large Margin classifier
有时人们会把SVM叫做large margin classifier,这一节就来说明为什么叫做large margin classifier。
还是先从SVM的cost function=\(min_\theta\; C\sum\limits_{i=1}^m[y^{(i)}cost_1(\theta^Tx^{(i)})+(1-y^{(i)}cost_0(\theta^Tx^{(i)}))]+\frac{1}{2}\sum\limits_{i=1}^n\theta_i^2\)开始说起。

根据cost function的性质,为了最小化cost function,需要分为y=1和y=0两部分来讨论。
从图像上可知,要使cost function最小,肯定是让\(cost_1\)和\(cost_0\)最小,那么在图像上可以得出:
- y=0时,需要让\(cost_0(z)=0\),那么\(z\le-1\);
- y=1时,需要让\(cost_1(z)=0\),那么\(z \ge 1\);
至于这里为什么不是\(z\le0 \;or\; z \ge 0\)呢?尽管这样的话也是可以划分种类的,但是SVM中需要构建一个safety margin factor。那这与logistic有什么区别呢?
接下来要考虑一种情况,还是拿公式\(min_\theta\; C\sum\limits_{i=1}^m[y^{(i)}cost_1(\theta^Tx^{(i)})+(1-y^{(i)}cost_0(\theta^Tx^{(i)}))]+\frac{1}{2}\sum\limits_{i=1}^n\theta_i^2\)来说,当C很大的时候,比如是1000000,那么公式
\(min_\theta\; C\begin{matrix} \underbrace{\sum\limits_{i=1}^m[y^{(i)}cost_1(\theta^Tx^{(i)})+(1-y^{(i)}cost_0(\theta^Tx^{(i)}))]} \\item1 \end{matrix}+\begin{matrix} \underbrace{\frac{1}{2}\sum\limits_{i=1}^n\theta_i^2} \\item2 \end{matrix}\)中的第一项item1就应该接近于0才可以。
此时的优化问题就转化为选择参数C,来最小化cost function(使item1等于0)。
通过不断调整优化,会得到一条有趣的分界线,那么在图像上的展示效果是什么样子的呢?
我们拿一个线性可分的例子来说明:
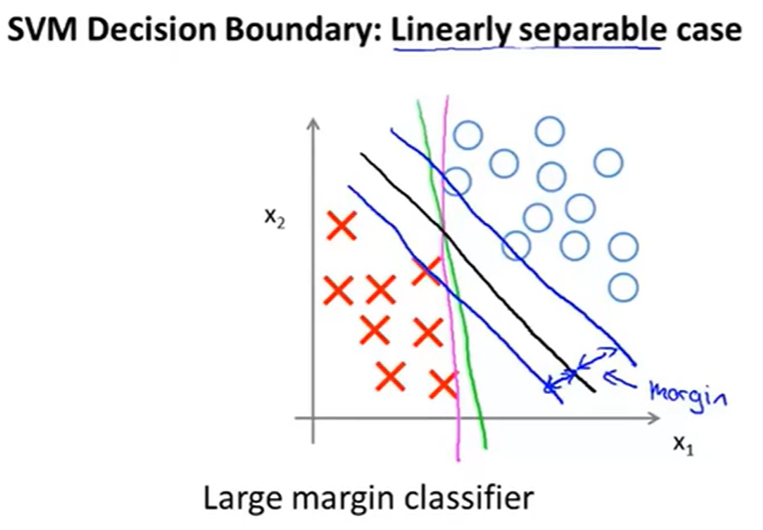
上图可以很好地解释为什么SVM有时也叫做large margin classifier,因为SVM在划分正负样本点的时候,会尽量找一条边界线,同时这个条边界线还与样本点有一定的距离margin(图中黑色的boundary是最好的一条,相比于红色和紫色的分界线,黑色的分界线有很好的robustness)。
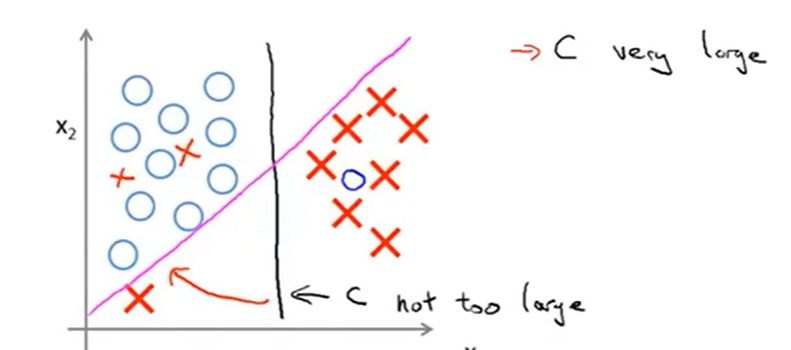
还要说明一点的是,这条分界线与公式中的常数C有什么关系呢?看下面这张图:
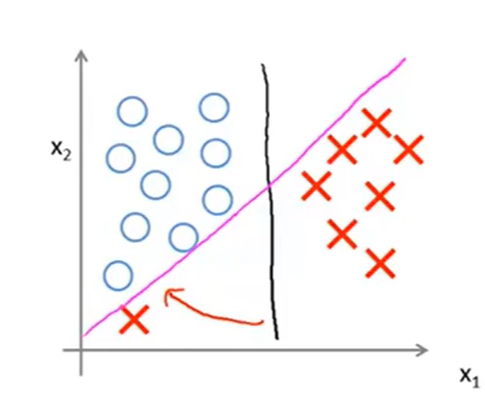
当C不是很大的时候,得出的分解线就是黑色的那一条,但是如果将C设置得很大,那么就会得到那条紫色的分解线。同样地因为SVM对异常点比较敏感,也会导致得出紫色的那条线,这可以认为是过拟合的问题(可以把常数C看做在logistic中的\(\lambda\)的效果)
同样地,如果数据不是线性可分的,如下图:
SVM仍然能够将其分出,至于分出的方法,可以先看这一篇博客的介绍部分(18条消息) Python3《机器学习实战》学习笔记(八):支持向量机原理篇之手撕线性SVM_Jack-Cui-CSDN博客。
15.3 The mathematics behind large margin classification
这一节将从数学推导的角度上来说明large margin。
首先回顾一下向量的点乘计算方法,即存在\(\vec{a}\)和\(\vec{b}\) ,那么\(\vec{ab}=a_1b_1+a_2b_2+...+a_nb_n=|a||b|cos\theta\)
依据这个向量的性质,来解释SVM中优化目标问题。
为了表达方便,这里规定n=2,\(\theta_0=0\).
那么SVM的优化目标函数为\(min_\theta \frac{1}{2}\sum\limits_{j=1}^n\theta_j^2\)(下图中的s.t.表示限制条件“Subject to”,至于为什么呢这个优化目标函数没有前一项了,这是因为是在C很大的前提下来进一步讨论的):
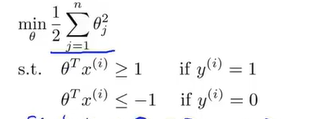
再结合向量的知识,可以对优化目标函数作进一步的表达如下:
\(min_\theta \frac{1}{2}\sum\limits_{j=1}^{n=2}\theta_j^2=\frac{1}{2}(\theta_1^2+\theta_2^2)=\frac{1}{2}(\sqrt{\theta_1^2+\theta_2^2})^2=\frac{1}{2}||\theta||^2\).
下一步要做的是考虑限制条件s.t.中的\(\theta^Tx\),和深度理解这一部分 。
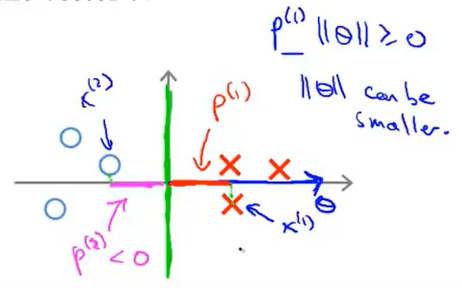
思考这个问题:\(\theta^Tx\)如何表示,以单数据集来为例,那么还是依据向量的点乘表示方法,我们假设存在一个正样本点\((x_1,x_2)\),那么就对应存在\((\theta_1,\theta_2)\)(注意这里为了表示方便,不考虑\(\theta_0\)),那么用图像来表示就是:
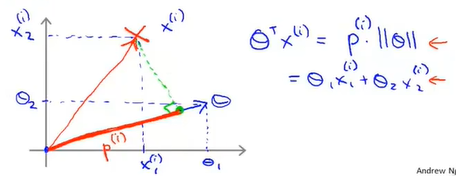
其中图像中\(p^{(i)}\)表示的是向量\(x^{(i)}\)在向量\(\theta^{(i)}\)上投影projection。
也就是说,限制条件s.t.可以用向量进行表示了,新的表示方式如下:
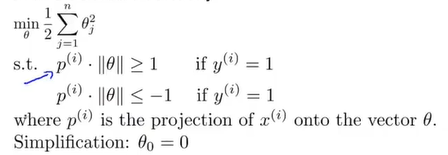
现在考虑一下下图中的样例(其中圆圈表示负样本,叉号表示正样本):
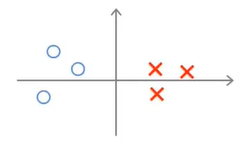
现在我们来看看SVM会选择什么样的决策边界。
假设存在这样一条边界(因为\(\theta_0=0\)所以边界线是经过原点的):
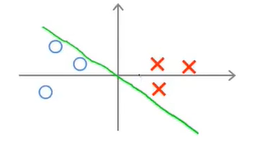
从图像中可以看出,这样一条边界不是最好的,因为存在样本点是靠近边界线的情况。那么SVM是怎么否定这条边界的呢?
首先要说明的是,\(\theta\)向量是垂直于边界的,\(\theta\)向量相当于边界向量的法向量,或者这样来,就是二元函数的参数向量与函数值正交(比如3x+4y=0就是与相邻(3,4)垂直),因为\(\theta\)现在就是参数,那么其对应的函数就是与其垂直的,理解这一点很重要。
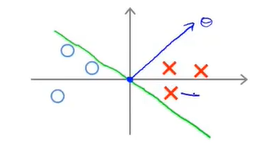
那么我们在正样本集和负样本集中选择两个点,那么与\(\theta\)的计算结果如下所示:
当前这样的情===》导致\(x^1\)与\(x^2\)在\(\theta\)向量上的投影很小===》但是又因为有限制方程的存在===》那么就会导致\(\theta\)偏大===>这就与min cost function矛盾了。因此这就不是一个好的方向了。
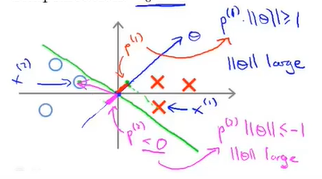
那么现在假如换了一条分界线如下:
那么\(\theta\)向量就是平行于x轴的向量:
那么还是取两个样本点,此时在\(\theta\)上的投影就会大很大,这样就可以进一步缩小\(\theta\)的取值了。
此时也就可以得到margin了(样本点到分界线的距离变大了):
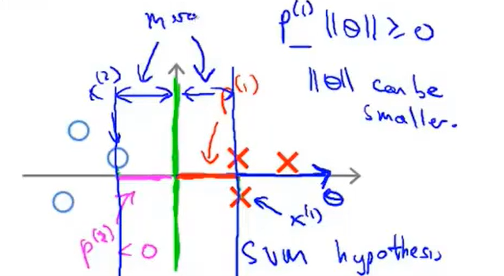
以上就是体现margin的大小是如何变化的。
15.4 Kernel 1
这一节主要是讲了如何构造一个复杂的非线性分类器,其中关键的技术就是Kernel。
假设存在如下图所示的一组训练集:
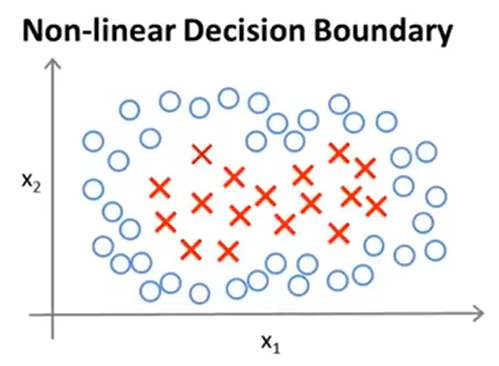
那么想要构造出一个boundary,其中一个办法就是构建出一个复杂的多项式集合(也是以前常用的思路):
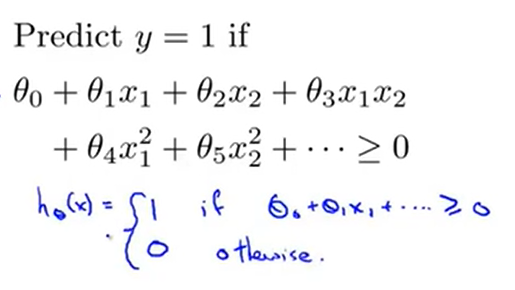
还有一种就是这一节要讲的方法:
首先是要先定义符号,hypothesis = \(\theta_0+\theta_1f_1+\theta_2f_2+\theta_3f_3+......\)
那么接下来的问题就是,如何选择\(f_i\)。
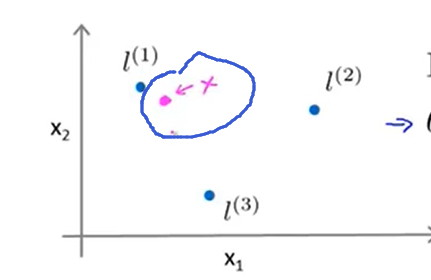
还是采取由浅入深的方式,假设有两个特征值x1和x2,再另外手动选取3个点\(l^1,l^2,l^3\),在图像上的表示效果如下:
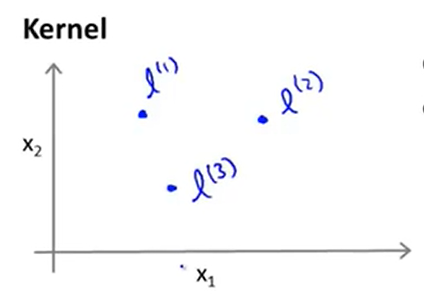
那么接下来就要进一步定义上面讲到的\(f_i\);
给定一个x(训练集中的数据),那么\(f_1=similarity(x,l^1)=exp(-\frac{||x-l^1||^2}{2\sigma^2})=exp(-\frac{\sum_{i=1}^n(x_i-l_i^1)^2}{2\sigma^2})\)(这里不考虑\(x_0\),因为\(x_0\equiv1\),这只是一个截距的影响)
同理可以得出f2和f3.
那么similarity函数就是Kernel function,然后这里用到的Kernel function是Gaussian kernel(kernel function有很多种,这里是用的Gaussian kernel)
以f1为例,针对x的位置情况可以分成两种:靠近\(l^1\);远离\(l^1\);
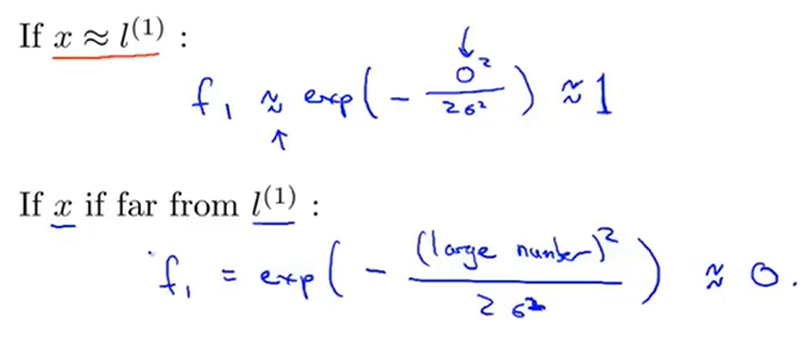
针对这两种情况,可以得出靠近我们手动选取的\(l^1\)的时候,f1近似等于1;反之近似等于0;
同理就可以得出x点与f2和f3的距离关系。
通过图像可以更直观地看出距离关系:
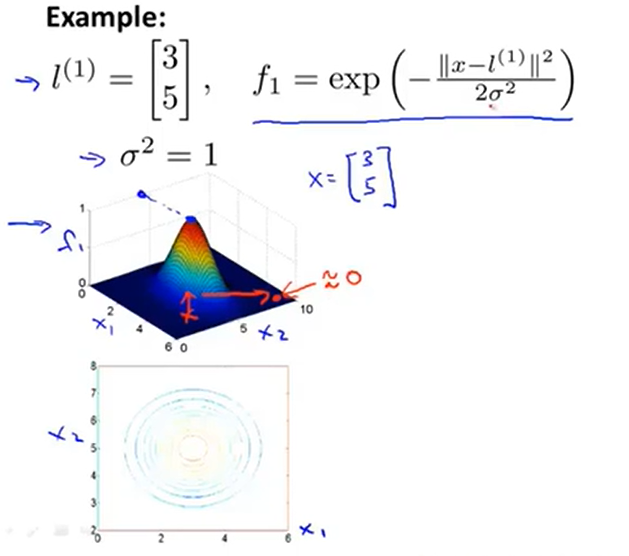
当越靠近我们选取的\(l^1=\begin {bmatrix} 3\\5\end {bmatrix}\)这个点的时候,那么kernel function的数值就越大。
同时参数\(\sigma\)的影响效果如下:
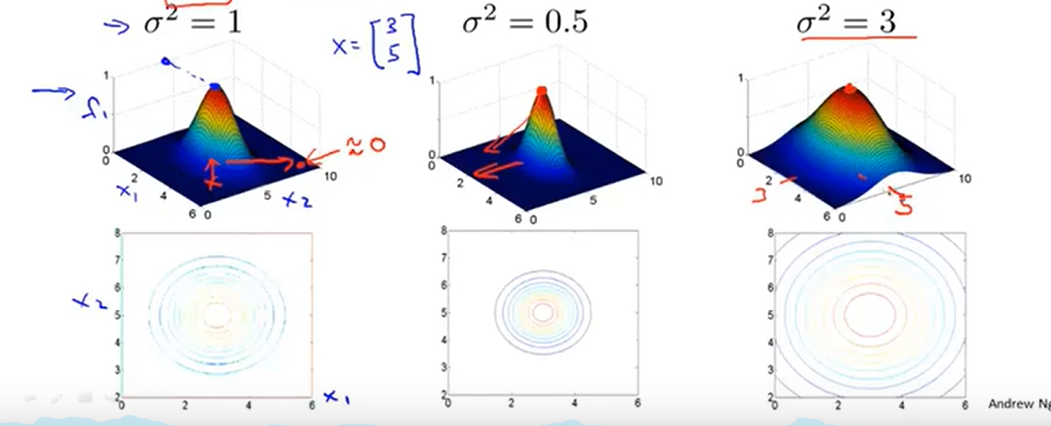
那么讲了那么多,如何判断非线性的边界呢?
定义:当\(hypothesis=\theta_0+\theta_1f_1+\theta_2f_2+\theta_3f_3 \ge 0\)的时候 ===》predict y=1;
假设已经拟合好了\(\theta_0=-0.5;\theta_1=1;\theta_2=1;\theta_3=0\)
这个函数那么是如何划分区域的呢?
存在一个x点,通过这个x点可以得出\(f_1 \approx 1;f_2 \approx 0; f_3 \approx 0\);
此时hypothesis = -0.5+1*1=0.5>=0.5,那么就是说明这个点是正样本;
同理,我们预测另一个点的时候,得出其是负样本点:

通过在训练集上不断枚举x点,最终发现,越是靠近\(l^1\)和\(l^2\)的点,结果就是1,那么就可以大体上得出这boundary了:

15.5 Kernel 2
上一节将了什么是Kernel function,那么这一节主要讲上一节中的提到的\(l^i\)点是怎么选择的?参数C和\(\sigma\)对bias和variance的影响是什么样子的呢?
首先是如何选择landmarks

上一节中讨论到,为了演示方便,选取了3个点作为landmark,但是实际的情况下并非需要有很多的landmark,这里采取的方法是将数据集中所有的点都作为landmark,也就是说选择如果数据集大小是m,那么landmark也就有m个:
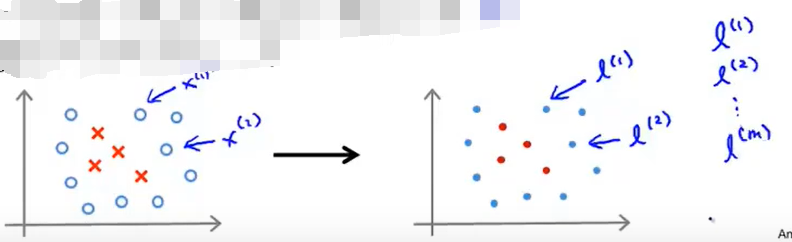
这样就可以得出一个m维的向量\([l^1\;l^2\;...l^m]\).
那么具体来说就是:
(对于x数据集的选择,可以是training set,也可以是cross validation set ,还可以是test set。
对于选定的\((x^i,y^i)\),需要进行以下的运算:
\(x^i--> \begin{cases} f_1^i= similarity(x^i,l^1) \\ f_2^i = similarity(x^i,l^2) \\ f_3^i = similarity(x^i,l^3)\\ ...\\f_i^i = similarity(x^i,l^i)=1\\...\\ f_m^i = similarity(x^i,l^m) \end{cases}\)
这样就得到了一个新的向量\(f^i=\begin{bmatrix} f_1^i \\ f_2^i \\ ...\\f_m^i \end{bmatrix}\),这个向量就是用于描述数据集的特征向量。
需要说明的是,\(x^i\)或者\(f^i\)都是m维或者m+1维的向量,如果是m+1维的向量,那么就是添加了\(x_0\)或者\(f_0=1\)
那么接下来该怎么使用SVM呢?
下图就是一个使用的过程,将得出的f向量与\(\theta\)向量进行相乘运算:

那么一个新的问题就又出现了,\(\theta\)向量是怎么得出的呢?
我们需要对在15.2中提出的公式:\(min_\theta\; C\sum\limits_{i=1}^m[y^{(i)}cost_1(\theta^Tx^{(i)})+(1-y^{(i)}cost_0(\theta^Tx^{(i)}))]+\frac{1}{2}\sum\limits_{i=1}^n\theta_i^2\)进行修改如下:
\(min_\theta\; C\sum\limits_{i=1}^m[y^{(i)}cost_1(\theta^Tf^{(i)})+(1-y^{(i)}cost_0(\theta^Tf^{(i)}))]+\frac{1}{2}\sum\limits_{i=1}^m\theta_i^2\)
更改地方:将原来的\(\theta^Tx^{(i)}\)变成\(\theta^Tf^{(i)}\);最后一项\(\sum\limits_{i=1}^n\theta_i^2\)的求和上限改成m。
其中,大多数SVM在计算的时候,还会对\(\sum\limits_{i=1}^m\theta_i^2\)做如下的优化:
\(\sum\limits_{i=1}^n\theta_i^2=\sum\limits_{i=1}^n\theta_i^TM\theta_i\)其中M是依赖于Kernel function的函数(只需要知道这一步能提高运算的效率就好)。
其实有很多软件包以及将这些细节优化完成了,直接调用即可,包括最小化函数 \(min_\theta\)。
最后再说一下参数问题,总结如下:

15.6 Using an SVM
15.1~15.5总得来说是从抽象的层面上来讲解了什么是SVM,那么这一节主要讲运行或者说使用SVM需要做的事情。
吴恩达在这一节中一直强调,不建议自己写代码来实现像是矩阵的转置、逆矩阵、或者平方的计算,同样还包括SVM最优化的问题也是不建议自己来实现,我直接用别人建立好的库函数就可以了,毕竟像SVM的提出已经很久来了,很多优化已经做得非常好,因此建议是直接使用即可。
那么只需要去考虑参数的选择即可,像是SVM中,需要指明参数C和需要选择的Kernel function。
在使用Gaussian Kernel的时候,需要注意一个问题:归一化。
如果是预测房间时,有面积(百万数量级),房间数(个位数量级)等特征,根据\(exp(-\frac{||x-l^1||^2}{2\sigma^2})\)的特性,就会导致面积对整个式子的影响大于房间数对整个式子的影响,因为还牵扯到平方的存在问题,那么就会将房间数对函数的影响的可能性给去掉了:

就像上图中说的,需要注意特征缩放的问题。
至于Kernel function的选择还是有其他的,但是呢,还是需要满足一些性质:

但是人们常用的还是线性Kernel(不传或者说不使用参数就是线性的Kernel)和Gaussian Kernel。
下图是简单说明了还有polynomial kernel,通式的表达方法就是\((x^Tl+constant)^{degree}\)
还有字符串的,卡方的,直方图的……

还有就是多分类的问题,许多SVM Package已经内置了多分类的实现方法,当然你也可以使用用one-vs.-all一对多的方法,这个方法思想与[logistic regression](#7.6 Multi-class classfication: One-versus-All)提到的一样。
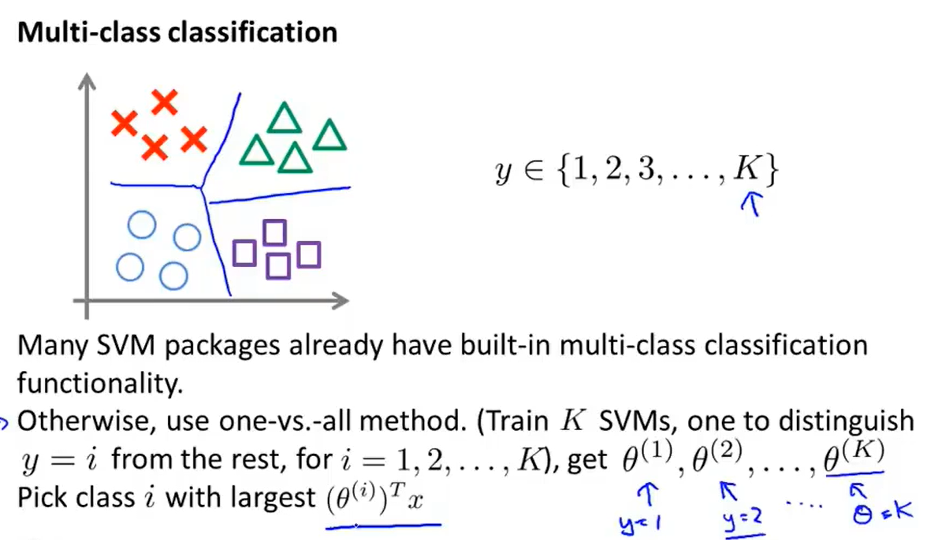
因为引入SVM是通过logistic regression来引入的,SVM的hypothesis还是在logistic regression的hypothesis的基础上进行修改的。那么对于不同的情况该怎么选择的,如何从这两者中选择呢?
分三种情况来讨论:
- n很大,m很小
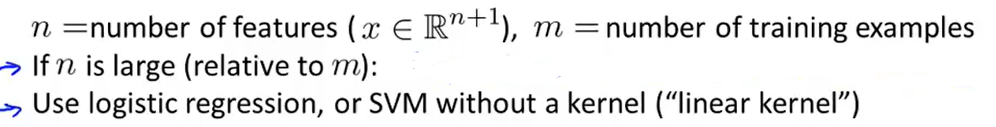
比如m=10,n=10000,那么这个时候就是用线性的SVM(因为没有足够的数据来拟合复杂的非线性的模型)或者logistic regression。
- n很小,m中等大小
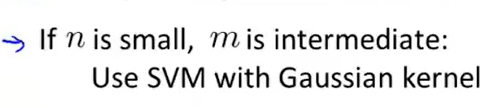
比如n=1000,m=10~10000的时候,可以是用Gaussian Kernel。
就拿以前的例子来讲,假设n=2,x1和x2,那么区分下面的数据集就是用的Gaussian kernel。
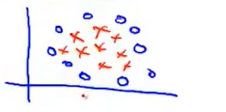
- n很小,m很大

比如n=1~1000,m=1000000+。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号