爬虫简介
爬虫简介
安装


# homebrew python3 + pip3 mongodb mysql redis # 必要库 lxml urllib re requests selenium beautifulsoup4 pyquery pymysql pymongo redis flask django jupyter pip3 install requests selenium beautifulsoup4 pyquery pymysql pymongo redis flask django jupyter # 驱动 chromedriver phantomjs # 软件 datagrip, robomongo
世界上80%的爬虫是基于Python开发的, 学好爬虫技能, 可为后续的大数据分析、挖掘、机器学习等提供重要的数据源.
爬虫
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本. 可以理解为在网络上爬行的一直蜘蛛, 互联网就比作一张大网, 而爬虫便是在这张网上爬来爬去的蜘蛛, 如果它遇到你需要的资源,那么它就会抓取下来.
(其实通俗的讲就是通过程序去获取web页面上自己想要的数据,也就是自动抓取数据)
爬虫的本质和原理
请求网站并提取数据的自动化程序
通过代码, 模拟浏览器向服务器发送一个请求. 自动化, 循环的模拟浏览器向服务器发送一个请求
浏览器打开网页的过程:
当你在浏览器中输入地址后,经过DNS服务器找到服务器主机,向服务器发送一个请求,服务器经过解析后发送给用户浏览器结果,包括html,js,css等文件内容,浏览器解析出来最后呈现给用户在浏览器上看到的结果.
所以用户看到的浏览器的结果就是由HTML代码构成的, 爬虫就是为了获取这些内容,通过分析和过滤html代码,从中获取我们想要资源(文本, 图片, 视频.....)
爬虫的流程:

Request, Response

Request中包含
请求方式
主要有:GET/POST两种类型常用,另外还有HEAD/PUT/DELETE/OPTIONS
GET和POST的区别就是:请求的数据GET是在url中, POST则是存放在请求头部
GET: 向指定的资源发出"显示"请求. 使用GET方法应该只用在读取数据, 用GET可能会被网络蜘蛛等随意访问.
POST: 向指定资源提交数据, 请求服务器进行处理(例如提交表单或者上传文件). 数据被包含在请求本文中. 这个请求可能会创建新的资源或修改现有资源,或二者皆有.
HEAD:与GET方法一样,都是向服务器发出指定资源的请求, 只不过服务器将不传回资源的本文部分. 它的好处在于,使用这个方法可以在不必传输全部内容的情况下,就可以获取其中“关于该资源的信息”(元信息或称元数据).
PUT:向指定资源位置上传其最新内容.
OPTIONS:这个方法可使服务器传回该资源所支持的所有HTTP请求方法。用'*'来代替资源名称,向Web服务器发送OPTIONS请求,可以测试服务器功能是否正常运作.
DELETE:请求服务器删除Request-URI所标识的资源.
请求URL
URL,即统一资源定位符,也就是我们说的网址,统一资源定位符是对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址. 互联网上的每个文件都有一个唯一的URL, 它包含的信息指出文件的位置以及浏览器应该怎么处理它.
URL的格式由三部分组成:
①第一部分是协议(或称为服务方式)
②第二部分是存有该资源的主机IP地址(有时也包括端口号)
③第三部分是主机资源的具体地址,如目录和文件名等
爬虫爬取数据时必须要有一个目标的URL才可以获取数据,因此,它是爬虫获取数据的基本依据.
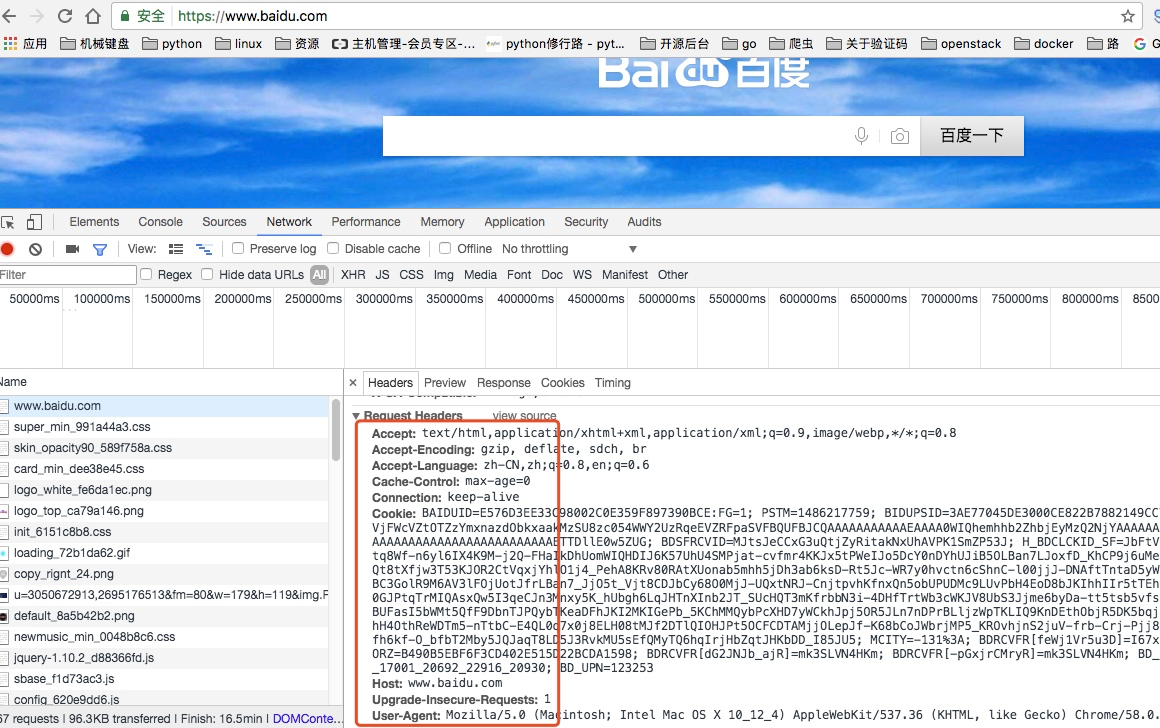
请求头
包含请求时的头部信息,如User-Agent,Host,Cookies等信息,下图是请求请求百度时,所有的请求头部信息参数
请求体
请求是携带的数据,如提交表单数据时候的表单数据(POST)
Response中包含
所有HTTP响应的第一行都是状态行, 依次是当前HTTP版本号, 3位数字组成的状态代码, 以及描述状态的短语, 彼此由空格分隔.
响应状态
有多种响应状态,如:200代表成功,301跳转,404找不到页面,502服务器错误
- 1xx消息——请求已被服务器接收,继续处理
- 2xx成功——请求已成功被服务器接收、理解、并接受
- 3xx重定向——需要后续操作才能完成这一请求
- 4xx请求错误——请求含有词法错误或者无法被执行
- 5xx服务器错误——服务器在处理某个正确请求时发生错误 常见代码: 200 OK 请求成功 400 Bad Request 客户端请求有语法错误,不能被服务器所理解 401 Unauthorized 请求未经授权,这个状态代码必须和WWW-Authenticate报头域一起使用 403 Forbidden 服务器收到请求,但是拒绝提供服务 404 Not Found 请求资源不存在,eg:输入了错误的URL 500 Internal Server Error 服务器发生不可预期的错误 503 Server Unavailable 服务器当前不能处理客户端的请求,一段时间后可能恢复正常 301 目标永久性转移 302 目标暂时性转移
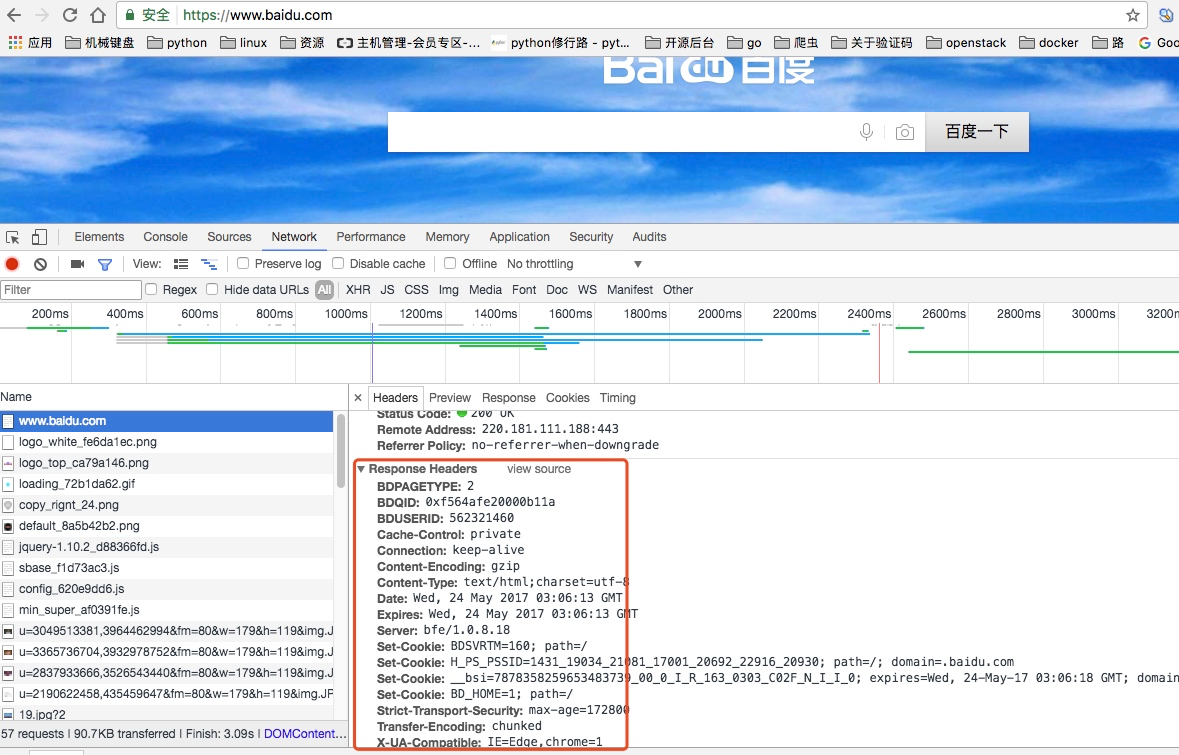
响应头
如内容类型, 类型的长度, 服务器信息, 设置Cookie, 如下图
响应体
最主要的部分,包含请求资源的内容,如网页HTMl,图片,二进制数据等
能抓到的数据类型

解析方式
- 直接处理
- Json解析
- 正则表达式处理
- BeautifulSoup解析处理
- PyQuery解析处理
- XPath解析处理
数据保存

抓取的页面数据和浏览器里看到的不一样
出现这种情况是因为, 很多网站中的数据都是通过js, ajax动态加载的, 所以直接通过get请求获取的页面和浏览器显示的不同.
解决JavaScript渲染的问题:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号