Towards Unifying Multi-Lingual and Cross-Lingual Summarization:论多语言与跨语言概括的统一

为了使文本摘要适应多语言世界,先前的工作提出了多语言摘要(MLS)和跨语言摘要(CLS)。然而,由于定义不同,这两项任务被单独研究,这限制了对两者的兼容和系统研究。在本文中,我们的目标是将MLS和CLS统一到一个更通用的设置中,即多对多摘要(M2MS),其中单个模型可以处理任何语言的文档,并生成任何语言的摘要。作为迈向M2MS的第一步,我们进行了初步研究,表明M2MS可以比MLS和CLS更好地跨不同语言传递任务知识。此外,我们提出了PISCES,这是一个预先训练的M2MS模型,通过三阶段预训练学习语言建模、跨语言能力和摘要能力。实验结果表明,我们的PISCES显著优于最新基线,尤其是在零样本方向
1.介绍
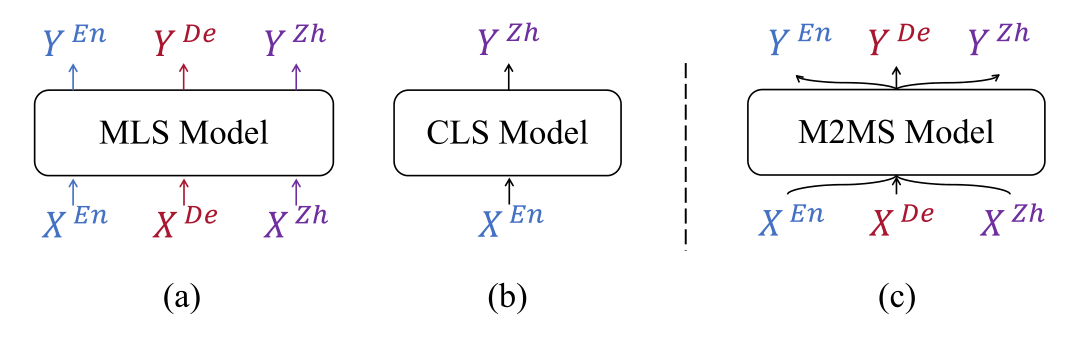
多语言摘要(MLS)旨在建立一个统一的模型来处理多种语言的文档并生成相应语言的摘要。
跨语言摘要(CLS)则从不同源语言的给定文档中生成目标语言的摘要。
在本文中,目标是把MLS和CLS统一到一个更通用的设置中,称为多对多摘要(M2MS)。
提出了PISCES模型——一个经过预训练的M2MS模型,通过三个预训练阶段学习语言建模、跨语言能力和总结能力。
实验结果表明,与最先进的基准模型(mBART-50、mT5)相比,PISCES取得了令人满意的结果,尤其是在零样本方向。此外,我们发现PISCES甚至能够为从未在微调阶段出现的语言的文档生成摘要。
2.在一个单一模型中统一所有方向是否相互帮助?
使用mBART-50模型作为摘要模型,设置四种训练模型
- ONE:分别训练几个模型,每个模型都是在一个方向上构建和评估。当方向是跨语言(单语言)时,相应的模型是CLS(单语言)模型。
- U-CLS:用所有跨语言样本训练一个统一的模型,并在所有方向上测试该模型。
- MLS:用所有语言中的单语样本训练一个统一的模型。然后,对训练后的模型进行全方位评估。
- M2MS:这是这项工作引入的新设置,在该设置中,模型在各个方向上都得到了训练和评估。。
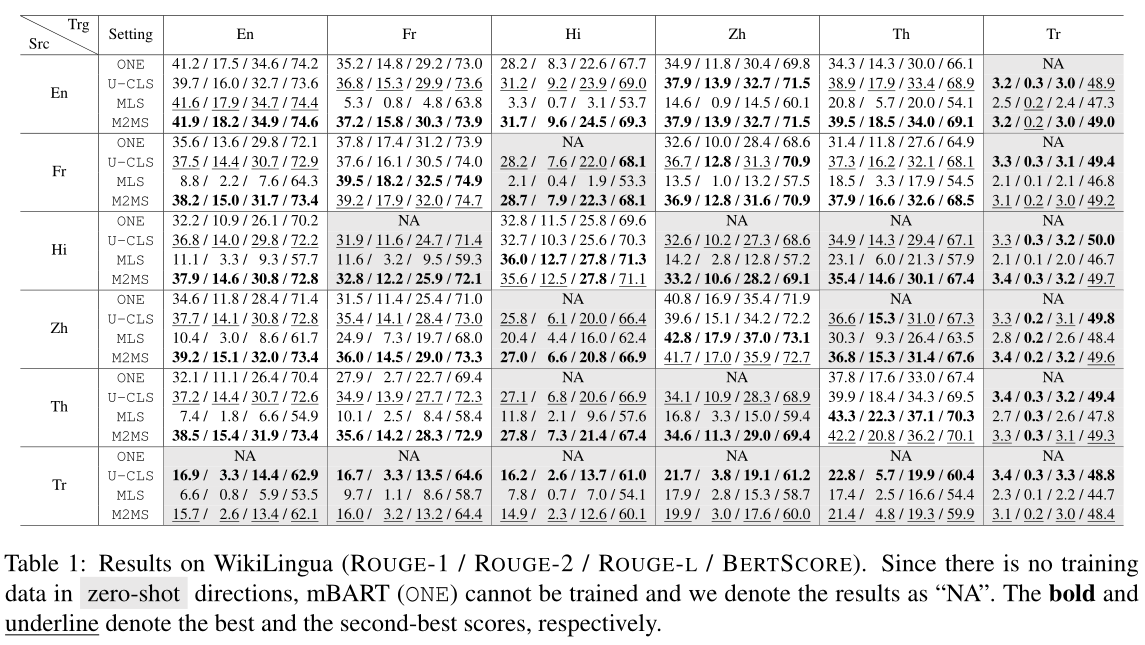
比较结果,表明
(1)在M2MS环境中训练出的多语言模型比在MLS、CLS和统一CLS环境中训练出来的模型能够更好地跨不同语言传递任务知识。
(2)与统一CLS相比,M2MS有助于模型在可见语言之间实现更好的可转移性,但牺牲了向不可见语言的可转移能力。
3. PISCES模型
包含三个预训练阶段。

3.1 元预训练
使用mBART-50作为元预训练模型。该模型在大规模多语言未标记语料库上进行预训练,以学习多语言建模。具体来说,使用两个预训练任务:(1)文本填充:随机遮蔽文本序列的文本跨度。(2)句子排序:随机打乱文档中的句子。为了指示输入和输出语言,语言标签(例如,\(<En>\)和\(<Zh>\))分别附加在编码器和解码器侧的输入处。
3.2跨语言预训练
尽管mBART-50是有效的,但在其预训练阶段,输入和输出序列总是用同一种语言,导致跨语言能力未得到充分开发。
提出训练目标:跨语言去噪:让模型基于有噪声(文本填充)的句子生成目标语言的完整句子。这样,预先训练的模型不仅需要理解源语言中的文本,还需要学习不同语言之间的转换。
3.3特定任务的预训练
针对特定任务的预训练旨在缩小预训练和fune-tune阶段之间的差距。
直接采用M2MS作为其预训练任务。基于高质量的M2MS样本难以收集的事实,我们从多语言未标记语料库中构建了伪样本。具体来说,计算每个句子在源文档中的重要性(根据rouge分数)。选择重要性高的句子作为 gap sentences (其实就是遮蔽重要性高的句子),然后把遮蔽的句子通过谷歌翻译转化为其他语言,作为伪标签,让模型预测标签。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号