多语言摘要的对比-对齐联合学习

1.简介
以往的大多数多语言摘要模型专注于为不同的语言训练一个模型,或者共享编码器/解码器层。 Cao et al. (2020) and Lewis et al. (2020a) 试图为所有语言训练一个模型,但他们发现,尽管低资源语言可以从更大的训练数据中受益,但丰富资源语言的性能却被牺牲了。因此,我们想研究以下问题:我们能否设计一个统一的多语言摘要模型,既有利于高资源语言,也有利于低资源语言?
2.方法
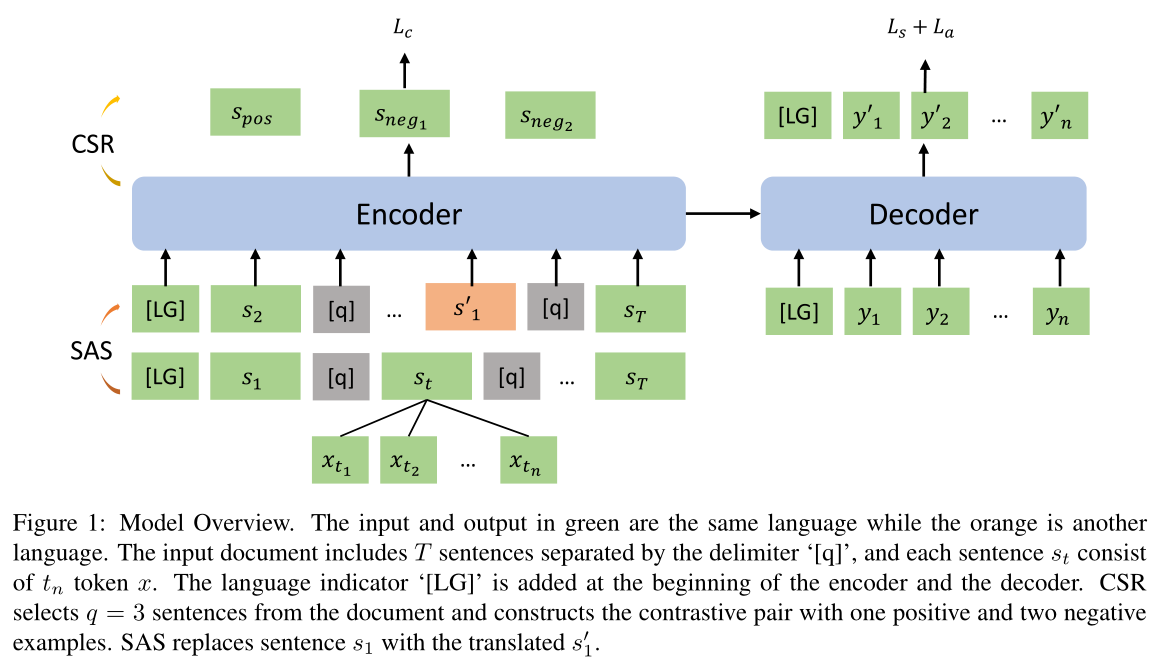
使用mBART(Liu et al,2020)作为模型初始化。它是一个强大的基于Transformer的多语言预训练模型,在25种语言的单语文档语料库上训练,具有去噪训练目标。它提供了跨语言的共享词汇和良好的多语言模型。我们通过对不同语言的所有摘要数据进行联合训练,在不同语言之间充分共享模型参数。
2.1对比句排序
摘要任务中的输出比输入短得多。因此,摘要模型在微调短语期间从文档中获取显著信息是很重要的。
设计了一种对比训练策略,即对比句子排序(CSR),帮助模型区分独立于语言的显著信息。
具体说,在训练过程中,从文档中随机选择q个句子,计算每个句子和真实摘要的相似度,分数最高的为正样本,其他的为负样本,此外,我们可以改变每种语言的负样本数,以缓解数据之间的不平衡。
每次数据加载器从数据集中加载数据时,构建一个正负样本对,并且保存对应的句子掩码。
使用一个带有sigmoid函数的线性层从encoder的最后一层被掩码的隐状态中得到正负样本的分数。


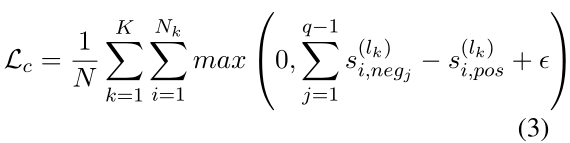
2.2句子对齐替换
从文档中抽取lead 句子(因为这些句子在摘要任务中比较重要),用翻译工具(谷歌翻译)把句子翻译成其他语言,获得对齐的信息,然后将翻译后的句子随机插入原始文档。
3.实验
单语言模型:为每种语言训练一个相同参数的单语言模型,在单语摘要任务上进行微调。
多语言模型:联合训练五种语言的摘要。
1. 对于transformer,用语言指示器在多语言摘要任务上对mBART进行微调。
2. 对于CALMS,在mBART添加了SAS和CSR任务。
3.1 单语言模型 vs 多语言模型
对于Transformer,联合模型在资源丰富的语言上表现较差,而在低资源语言上得到了改进。表明,没有多语言预训练的统一多语言模型牺牲了丰富的资源语言,改进了低资源语言。
添加本文的训练任务后的mBART,在五种语言上都优于单语言模型。这表明,不仅低资源语言可以从更大的训练数据中受益,而且高资源语言也可以通过多语言联合训练得到进一步改进。多语言模型在一定程度上帮助模型共享跨语言的潜在空间。
3.2 mBART vs CALMS
CALMS在所有五种语言上都表现出色。
3.3 转换到其他语言
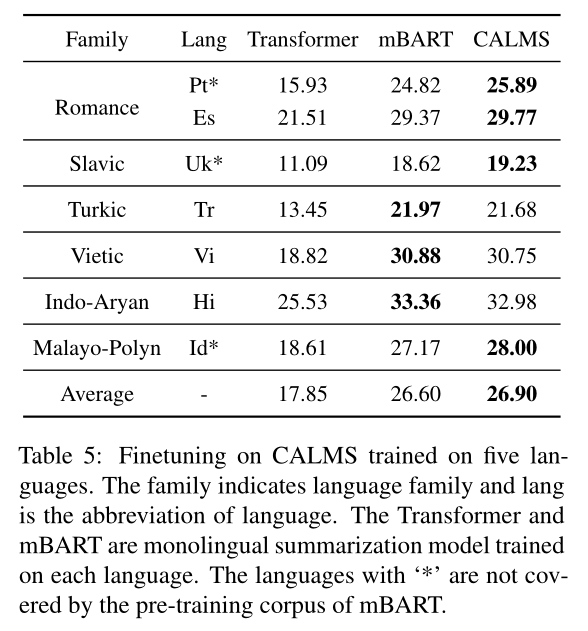
将在五种语言训练过的CALMS在另外的六种语言上做微调,其中有三种语言不在mBART的预训练语料中。
如表所示,CALMS在Pt、Es、Uk和Id方面优于单语Transformer和mBART。在这些语言中,Pt和Es与Fr是同一语系,而Uk和Ru都属于斯拉夫语。这表明,我们的多语言摘要模型CALMS可以帮助相似语言相对于在其有限的训练数据上训练的单语模型获得更好的结果。对于Id,它不在预训练阶段,我们的CALMS在这方面也表现出了更好的结果。然而,对于其他远离训练语言的语言,CALMS与单语模型相比没有明显的优势。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号