TACL 2022 | 跨语言摘要最新综述:典型挑战及解决方案

跨语言摘要是指用一种语言(如英语)为给定文档生成不同语言(如中文)的摘要。
1.早期的pipeline方法
早期对跨语言摘要的研究主要集中在 pipeline 方法,即让模型分步完成单语摘要和机器翻译。根据完成先后顺序的不同又可分为先摘要后翻译方法和先翻译后摘要方法。
1.1先摘要后翻译
首先为源语言文档生成源语言摘要,再将摘要翻译至目标语言。早期机器翻译的性能有限,翻译后的摘要可能可读性较低,为了缓解这个问题,他们首先使用经过训练的SVM模型来预测每个英语句子的翻译质量,其中该模型仅利用英语句子中的特征。然后,他们选择质量高、信息量大的句子形成摘要,最终由谷歌机器翻译服务翻译成中文。
1.2先翻译后摘要
分为三类:
- 提取式:从翻译文件中选择完整的句子作为摘要。
- 压缩式:首先从翻译文件中提取关键句子,并进一步去除关键句子中的不相关或多余的单词,以获得最终摘要。
- 抽象式:生成新的句子作为摘要,这些句子不限于原始单词或短语。
2.端到端的方法
随着神经网络的快速发展,提出了许多端到端的多语言摘要模型。
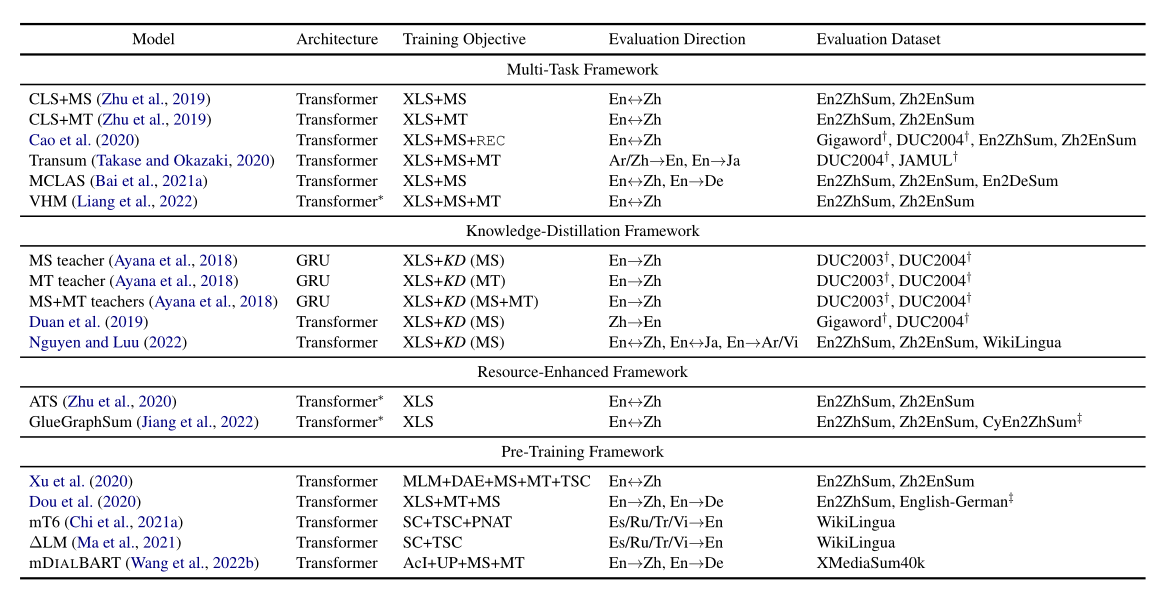
总结之前的端到端的跨语言摘要模型,将它们分为四个框架。
- 多任务框架
- 知识提炼框架
- 资源增强框架
- 预训练框架
2.1多任务框架
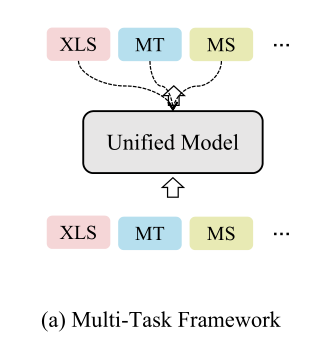
端到端模型直接进行跨语言摘要具有挑战性,因为他需要翻译和摘要两个能力。

Zhu et al. (2019)利用一个共享的transformer的encoder对输入序列进行编码,然后分别用两个独立的decoder进行机器翻译和单语言摘要。
Cao et al. (2020) 使用两个encoder-decoder模型分别以源语言和目标语言进行单语言摘要。同时,源encoder和目标decoder共同进行跨语言摘要。然后用两个线性映射器将encoder的输出从源语言转换为目标语言,反之亦然。此外,采用了两个鉴别器来区分编码表示和映射表示。因此,整个模型可以共同学习总结文档并调整两种语言之间的表示。
2.2知识提炼框架
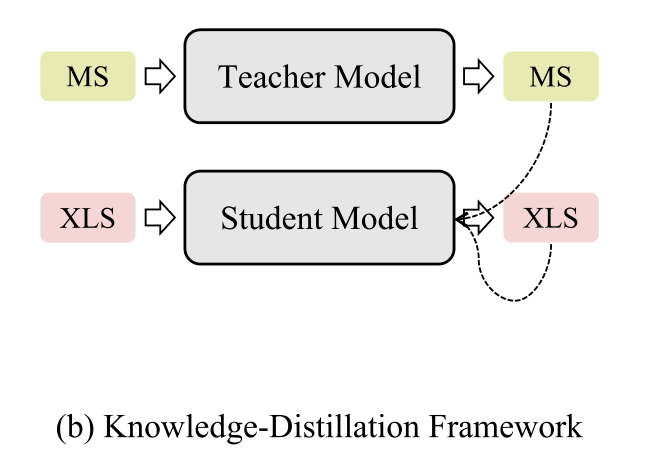
知识提炼的最初想法是将一组模型(即教师模型)中的知识提炼成一个单一的模型(即学生模型)。由于MT/MS和XLS之间的密切关系,一些研究人员试图在知识提取框架中使用MS或MT,或同时使用这两种模型来教授XLS模型。
Ayana等人(2018)利用大规模MS和MT语料库分别训练MS和MT模型。然后,他们使用经过训练的MS或MT,或者这两种模型作为教师模型来教授XLS学生模型。
2.3资源增强框架
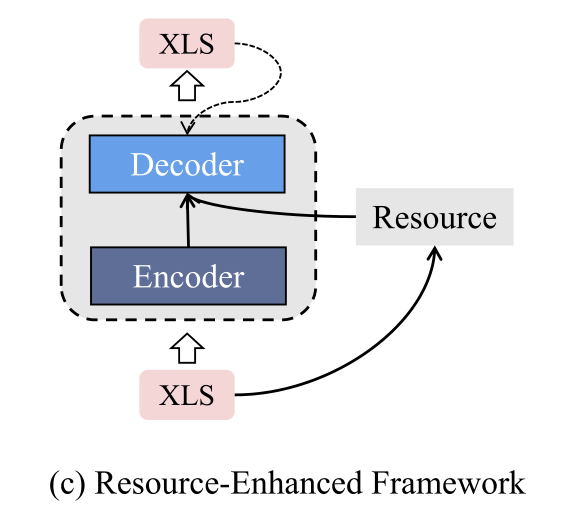
资源增强框架利用额外的资源来丰富输入文档的信息,输出摘要的生成概率取决于编码信息和丰富信息。
Zhu et al. (2020) 探索了XLS中的翻译模式。具体说,首先用transformer的encoder把输入文档编码,然后通过快速对齐工具包 (Dyer et al., 2013)获得输入文档中单词的翻译分布,最后,transformer的decoder基于输出分布和翻译分布生成目标语言的摘要。这样,额外的双语对齐信息有助于XLS模型更好地学习从源语言到目标语言的转换。
2.4预训练框架
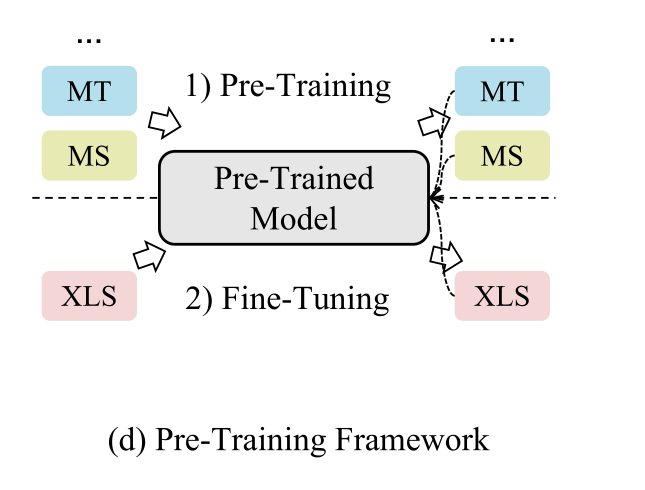
预训练的模型通常首先从大规模语料库中学习一般表示,然后通过微调来适应特定的任务。
例如,mBART作为一种多语言预训练模型,是从BART中派生出来的。mBART是在大量未标记的多语言数据上使用BART风格的去噪目标进行预训练的。mBART最初显示了其在MT方面的优势,梁等人(2022)发现,通过简单的微调,它也可以在大规模XLS数据集上优于许多多任务XLS模型。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号