Unlimiformer:Long-Range Transformers with Unlimited Length Input

动机
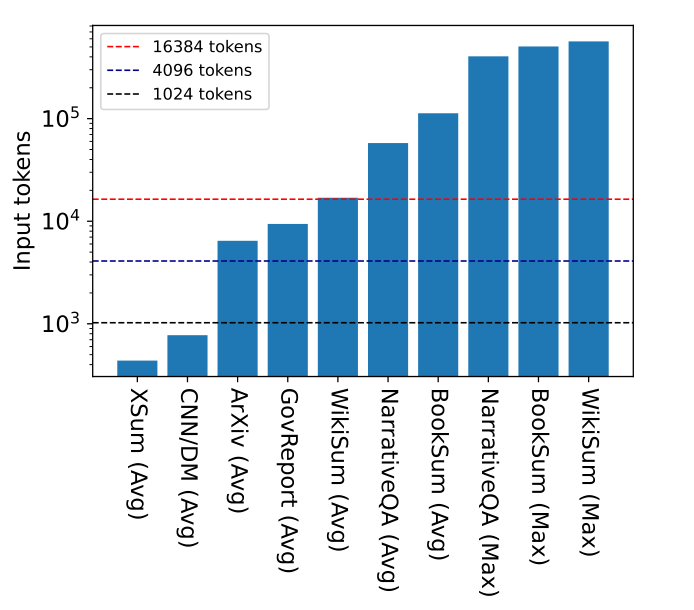
有一些任务,比如说书籍摘要,可能包含500k tokens的输入。在这种极端的例子中,transformer不能简单地使用,通常会修改模型基本架构,但这样需要从头开始预训练模型,需要大量计算资源。有一些架构(比如Longformer-Encoder-Decoder (LED; Beltagy et al., 2020))可以用先前预训练的模型,但仍需要进一步训练位置嵌入或者全局注意力权重,这些计算也都是昂贵的。
作者提出了Unlimiformer,这是一种基于检索的方法,用于增强预训练过的语言模型,使得能够在测试时接受无限长度的输入。
模型
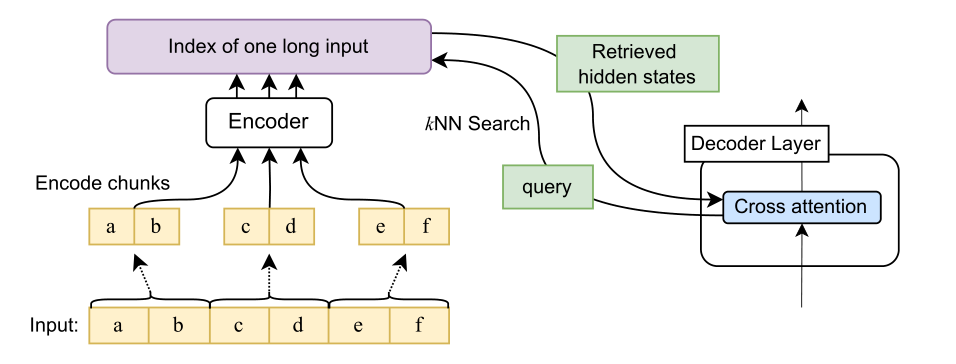
Encoding
使用给定模型的编码器对输入的重叠块进行编码,如 Ivgi et al. (2022)所述。我们只保留每个块中编码向量的中间一半,以确保编码两边都有足够的上下文。
最后使用Faiss(Johnson et al,2019)等库,使用点积作为索引的最近邻居相似性度量,在kNN索引中对编码输入进行索引。
增强检索的交叉注意力
在标准交叉注意力中,decoder只关注encoder最后一层的隐状态,并且encoder的输入往往是截断的,其实只编码了前k个token输入。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号