Efficient Long-Text Understanding with Short-Text Models
动机
基于transformer的预训练模型由于其二次复杂性,不能处理长序列。虽然提出了很多高效的transformer变体,但通常需要从零开始进行昂贵的预训练。
本文提出了一种可以重复利用经过训练测试的短文本预训练模型的处理长序列的方法。
最近的分析(Xiong et al,2022a)表明,具有局部注意力的稀疏变换器在多语言理解任务上与其他变体具有竞争力。
本文的方法属于局部稀疏注意力变体家族,但是与它们不同的是,本文重新使用和扩展了现有的短文本模型,不需要专门预训练重头实现。
方法
基于一个假设:在encoder-decoder架构中,encoder可以有效地将具有局部上下文的输入token置于上下文背景中,而decoder处理长程依赖。
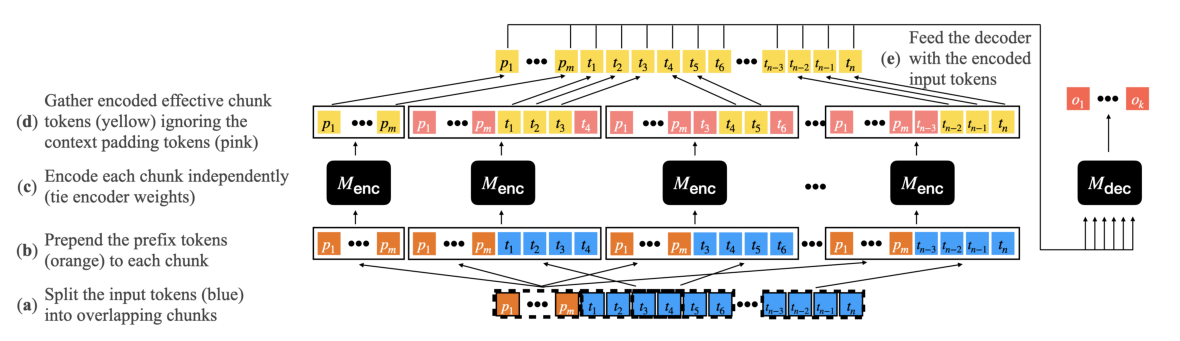
Input
使用一个预训练过的encoder-decoder模型 M 作为骨干。接受长度为n的序列文档(蓝色方块),以及长度为m的可选的短序列前缀(橙色方块),m<<n,前缀通常表示关于文档的问题、生成任务的指令或假设、静态任务特定前缀(比如“summarize”)、动态任务(QA数据集中的问题)。
通过以下步骤:
(a):文档tokens被拆分为长度为c的C个块(图中c=4),每个块的中间(1−ρ)×c个块称为有效块,因为它们将构成编码器的输出,并每侧通过token进行上下文填充。有效块的左右各加(ρ × c)/2个token,用于把有效块中的每个token置于上下文环境中。
(b):每个块前面都有可选的前缀token
(c):使用M编码器对每个块独立编码
(d):从每个块中只保留有效块中的token,并把它们连接起来
(e):使用M编码器对前缀token进行编码,使得解码器能够访问前缀token
(f):最后使用M解码器生成输出,该解码器对m+n个编码的token使用标准交叉注意力。
边缘情况另行处理(第一个块和最后一个块),见附录A
模型的复杂度
在编码器中,每个块中的复杂度是c的二次方,但c<<n,因此计算是n的线性复杂度,计算如下:
长度为n的序列划分为大小为c的C个块,因为ρ ∈ [0, 0.5],所以C ∈ [n/c , 2n/c]。假设用l个注意力层的模型对输入进行编码,则复杂度为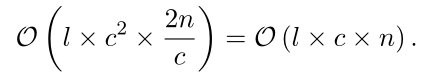
decoder就是transformer的标准decoder。
局限性
长输出:为了获得线性复杂度,SLED假设输出长度k是常数。这是因为解码器在输出和输入之间的O(nk)交叉注意之上,对输出使用二次自注意。虽然目前大多数长文本任务都遵循这一假设,但未来的任务,如学术报告或脚本编写,可能需要生成长文本。
SLED的核心假设是信息假设的局部性。当输入文本很长时,如果需要遥远的实体分辨率或事实知识,这种假设可能会被打破。例如,一本书中的一章可能会提到“他们正在走进房间”,而关于哪个房间或谁走的知识在几章后就可以找到了。在这种情况下,SLED使用的编码器将无法访问此信息,从而将更多的责任转移到解码器,并降低上下文编码的有效性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号