长序列模型
DIALOGLM: Pre-trained Model for Long Dialogue Understanding and Summarization
DIALOGLM,是一种用于长对话理解和总结的预训练encoder2decoder模型。
1.方法
预训练任务:基于窗口的去噪和五种对话噪声
1.1基于窗口的去噪
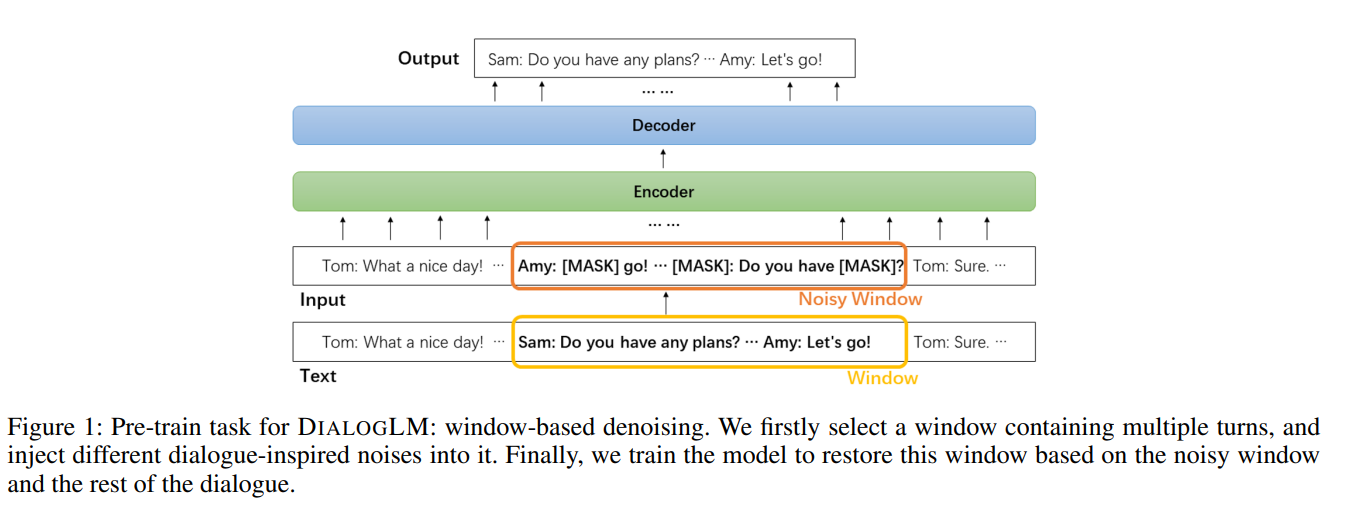

1.2五种对话噪声
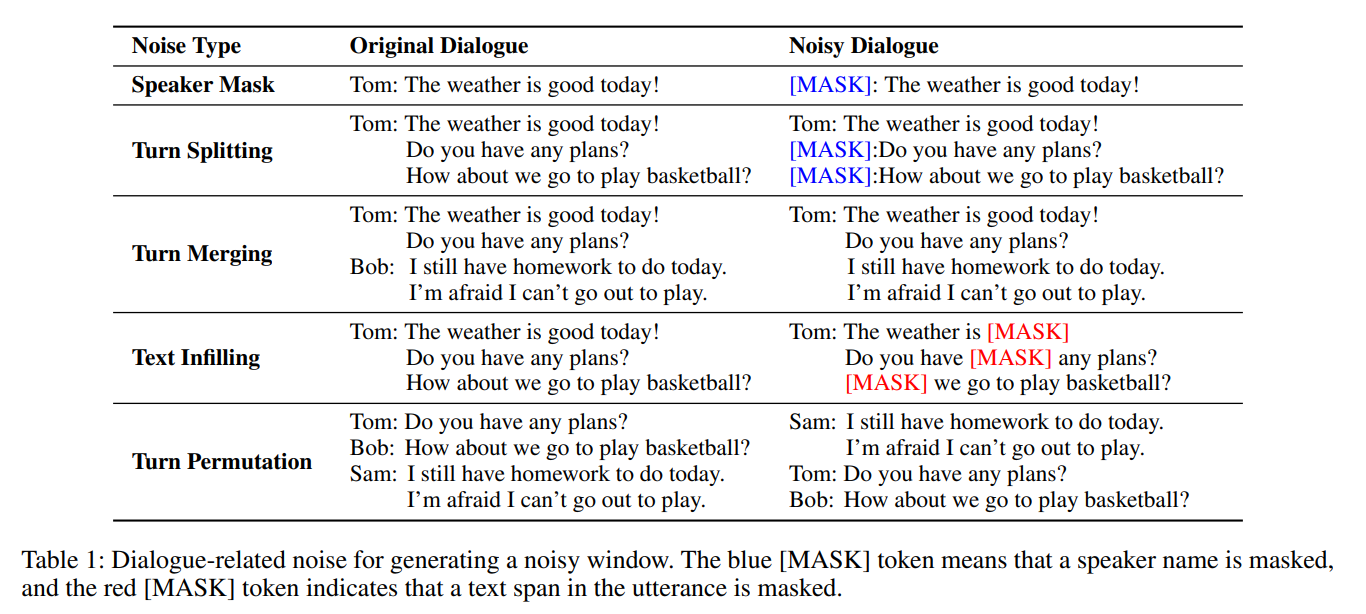
- Speaker Mask: 对于窗口中每一轮的演讲者姓名,随机抽取其中的 50% 并替换为特殊的 [MASK_SPEAKER]token
- Turn Splitting: 对话中的单个轮次可以由多个句子组成。 我们选择窗口中句子数量最多的回合,并将其拆分为多个回合。保持第一个被拆分轮次的说话者不变,并以[MASK_SPEAKER]作为所有后续新拆分轮次的说话者。
- Turn Merging: 随机采样多个连续轮次并将它们合并为一个轮次。保持第一回合的发言者不变,并删除所有后续回合的发言者。 合并匝数取自泊松分布 (λ = 3),并设置为至少 2。
- Text Infilling: 在一个窗口中,我们随机抽取几个文本跨度并用 [MASK] 标记替换每个跨度。文本跨度的长度也来自泊松分布(λ = 3)。0 长度跨度对应于在 Lewis 等人中插入 [MASK] 标记。
- Turn Permutation: 以随机顺序打乱窗口中的所有回合。这种噪音是在 turn merging 和 turn splitting 之后添加的。它可以进一步扰乱说话者和轮次信息,使模型只有在完全理解上下文时才能恢复窗口。
模型架构
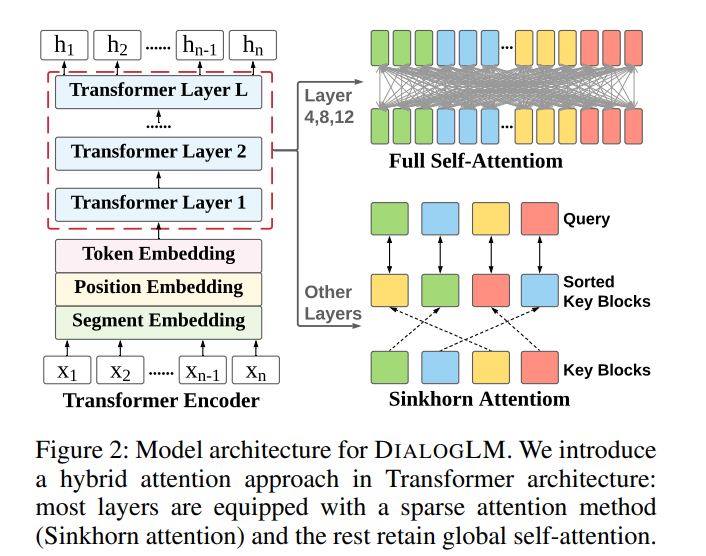
基础架构是transformer,采用了混合注意力方法。
Sinkhorn attention
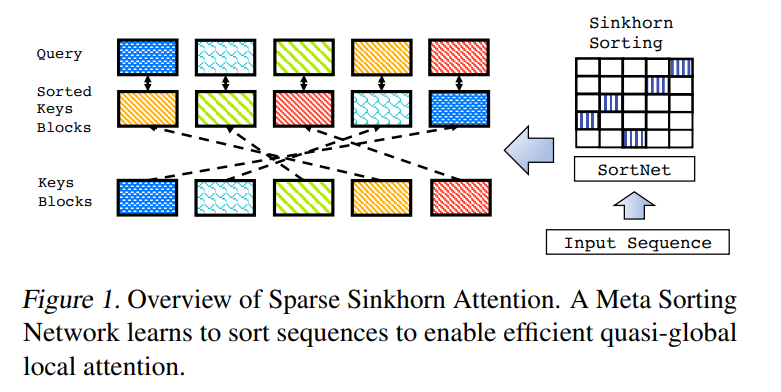
输入是一个长为\(l\)的序列X,首先将其分为\(N_{b}\)个小块,每个小块包含了b个token。
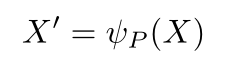
\(X∈R^{l×d}\)就是输入的序列,\(l(序列长度),d(特征维度),X^{'}∈R^{N_{b}×d},N_{b}\)就是块数.
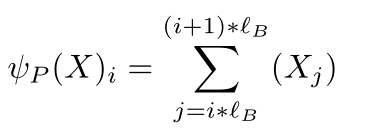
取属于local窗口的所有token的和,简单就是窗口内token之和作为块代表。
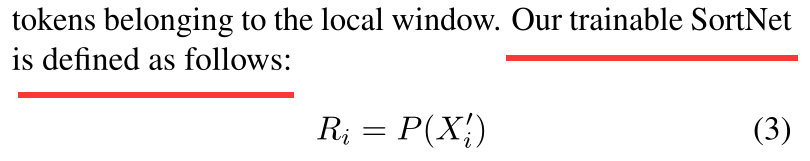
然后定义一个可训练的排序网络,把块进行排序

这个网络可以像上述这样定义

在处理长序列时,编码器自注意力占最大的计算开销,因此我们使用最近提出的稀疏 Sinkhorn 注意力 (sparse Sinkhorn attention) 对其进行改进。 局部注意力方法 local attention method(例如基于块的注意力)将输入分成几个块,并限制单词只关注自己块中的单词。这大大减少了计算负担,但也丢失了全局信息。Sinkhorn 注意力通过另外引入一个排序网络(sorting network),以新的顺序对原始块进行排序,并允许每个块不仅关注块内的 token,而且还以新的顺序关注到对应的块。如图2所示,绿色块可以关注到黄色块,因为黄色块与绿色块排列后的位置相同。 通过 Sinkhorn attention,不同的层学习不同的排序,因此每个块可以访问不同层上多个位置的信息。
然而,对于文本摘要等任务来说,完整的对话语义非常重要。因此,本模型保持了几个编码器层(Layer 4,8,12)的自注意力不变。这种混合方式可以实现局部和全局信息的交互。与不引入稀疏注意力的模型相比,在输入更长的序列和减少训练时间的前提下,可以达到相似或更好的性能。本文使用 UNILMV2 初始化模型。UNILMV2 的第 4、第 8 和第 12 编码器层保持完全自注意力。
实验
为了预训练 DIALOGLM,通过对噪声窗口去噪进一步训练 UNILM,总共 200,000 步对话数据。将批量大小设置为 64,将最大学习率设置为 2e-5。
预训练数据是 MediaSum 数据集 和 OpenSubtitles Corpus。
MediaSum 是一个媒体采访数据集,由 463.6K 文字本组成。OpenSubtitles 是从一个包含 60 种语言的电影和电视字幕的大型数据库编译而来的。这里使用英语部分作为预训练语料库。这两个大规模的预训练数据集包含大量与多个参与者的长时间对话,并具有清晰的对话文本结构。在预训练期间,窗口大小设置为输入长度的 10%,最大窗口大小限制为 512 个标记。 在生成嘈杂的窗口时,我们首先屏蔽 50% 的说话者,然后随机进行 Turn Splitting 或 Turn Merging,并利用 Text Infilling 来屏蔽话语中 15% 的标记,最后进行Turn Permutation。
本文使用 8 块 40GB 内存的 A100 GPU 完成实验。我们对 DIALOGLM 的两个版本进行了预训练:
DIALOGLM 是通过对噪声窗口去噪进一步预训练 UNILM 基础获得的。它的最大输入长度是 5,120,超过这个长度的令牌在实验中被截断。
DIALOGLM-sparse 在 DIALOGLM 的预训练过程中额外引入了混合注意力方法,因此其最大长度增加到 8,192 tokens。
[========]
LONG DOCUMENT SUMMARIZATION WITH TOP-DOWNAND BOTTOM-UP INFERENCE
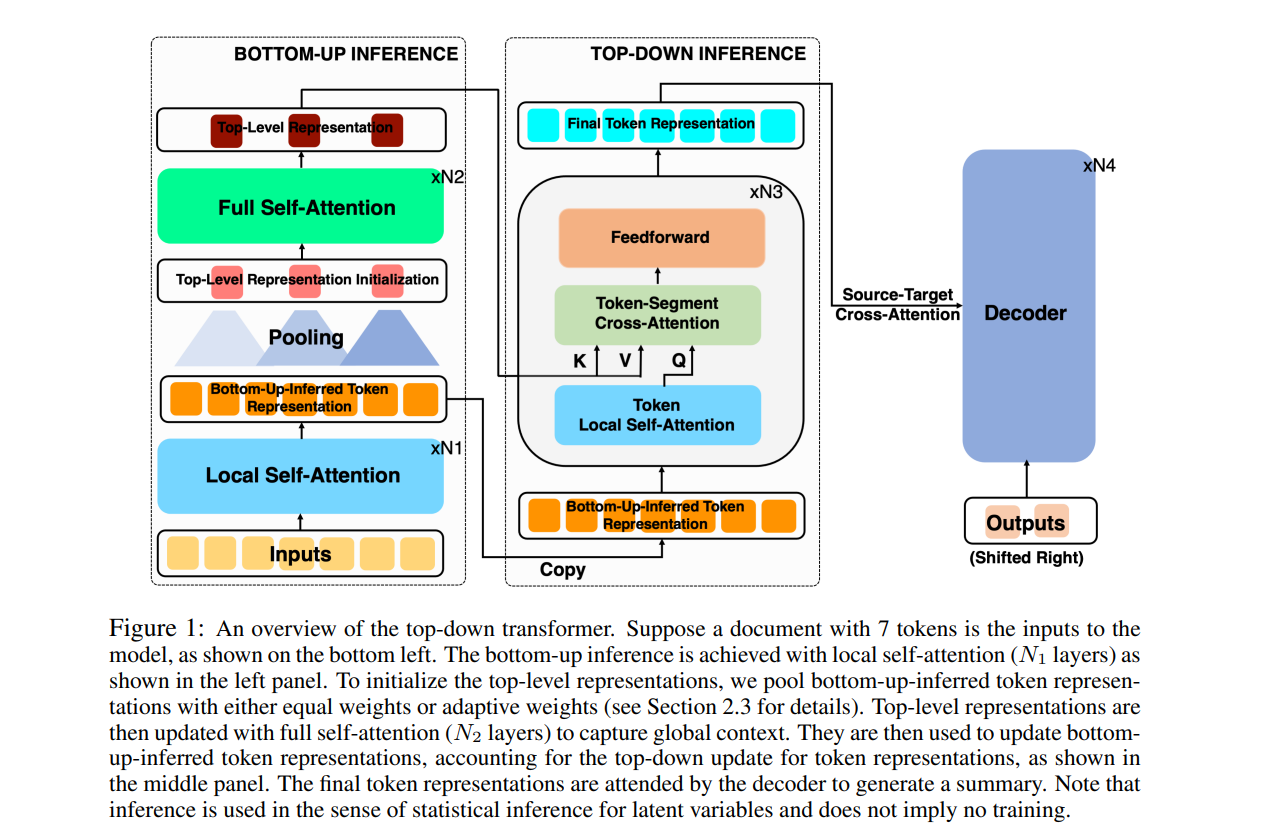
该论文研究如何推断良好的潜在表征,提高其摘要能力。
高级变量(如那些表示句子、片段的变量)以较粗的时间尺度和抽象的细节对文档进行建模,并且适合于捕获文档的长期依赖关系;相比之下低级变量(representing tokens)保留了详细信息,防止了摘要丢失关键细节。
先前的综述工作(Cheng&Lapata,2016;Nallapati等人,2016;Zhang等人,2019;Xu等人,2020)也探索了层次模型。但他们大多专注于提取摘要,并遵循自下而上的推理方法。它们汇集单词或子单词中的信息以形成句子表示,并在此基础上进行分类以做出提取决策。
方法
1.自底向上的推理
N1层,局部自注意力来计算token的上下文嵌入。每个token只关注大小为w的窗口内的token。
2.自上向下的推理
自底向上推理中局部自注意的也有局限性,即每个token只捕获局部窗口内的上下文,而不是整个文档的上下文。为了缓解这个问题,我们提出了一种自上而下的推理for token representations。
作者将 representations 分为两级,low level就是上述的token,采用局部自注意力计算。
top level采用更粗糙的粒度(区别于token,可能是sentence,segment等),由于粒度粗糙,因此完全可以通过全局注意力计算。
在全注意力更新后的 top level representations 将被用于更新 bottom-up-inferred token representations 。
在实例化自顶向下的推理时,需要确定top level的粗粒度。在这里作者采用固定长度的token组成。
3.池化层
由上一节可知,作者采用固定长度的段组成top level。
segment representations 通过 pooling token representations初始化。
假设文档被划分为M个片段,则第j个片段的嵌入被初始化为:
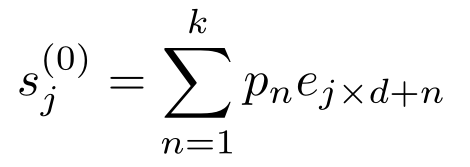
其中 k 是核大小(kernel size),d 是步幅(stride),pn 是第n个 token 的权重。
两种计算pn的方法:
-
平局池化,pn=1/k (简单方便,效果不理想)
-
自适应池化,引用摘要来定义每个 token 的重要性来分配自适应权重。(为此训练了一个用参考摘要构建的标签的重要性标记器)
-
为重要性标注者构建训练标签:(1)文档词和参考词的词库化;(2) 如果文档单词出现在参考单词列表中并且是非停止词,则将其标记为重要单词
-
训练具有构造标签的自上而下的变压器编码器作为重要性标记器
-
使用oracle权重(即从步骤1构建的标签)训练摘要模型,并使用学习的标签分配的自适应重要性权重对其进行测试

 浙公网安备 33010602011771号
浙公网安备 33010602011771号