将知识整合到文档摘要中——前缀调优(prefix-tuning)在GPT-2上的应用
简介
事实上,当使用预训练的模型生成摘要时,我们实际上一直在试图找出如何使用文档和模型的先验生成正确的摘要。如果模型的先验是正确的,或者输入文档可以有效地影响摘要生成,那么生成的摘要将是正确的,相反,摘要将与原始文本不一致。
因此,将知识添加到模型中以引导其生成正确摘要的问题可以转化为如何在文档摘要之前更有效地将文本与模型相结合的问题。遵循这个想法,我们提出了一种将知识整合到基于前缀调整的文档摘要。
为了将知识融入生成,我们只需在原文前面添加一段由OpenIE(Angeli et al,2015)提取的自然语言提示,以强调我们关心的关系。通过实验,我们发现,由于连续前缀的表达能力很强,经过训练,连续前缀可以识别自然语言提示中的模式,从而从中提取关键信息,然后将提取的信息与原文结合起来进行摘要生成。
综述
研究主要涉及两个方向。一种是基于提示的学习,另一种是可控的生成。
基于提示的学习:这里我们主要指前缀调优(prefix-tuning),训练一组连续的前缀提示,可以强调原文开头添加的信息,从而实现可控生成。
可控的生成:前缀调优(prefix-tuning)为可控生成开辟了更多可能性。很多研究都是关于更改前缀的,很少有研究前缀微调的性能以及如果我们直接改变文档会发生什么,这就是我们在本文中要做的。
方法
在本文中,我们使用OpenIE提取句子中存在的关系,然后选择包含我们关心的实体的三元组作为通过词性标注(POS)或命名实体识别(NER)添加到原始文本中的关系。
在将三元关系添加到文本后,我们在修改后的文本上训练一组连续的前缀提示,希望这组前缀能够识别我们添加的信息,并帮助模型结合原始文本生成具有添加关系的事实一致的句子。为了评估生成结果,我们使用CoCo对原始文本分别对黄金摘要和生成的摘要进行评分,并计算生成的摘要在黄金摘要上的ROUGE分数。
前缀调优(prefix-tuning)
与传统的基于微调的方法相比,基于提示的学习最显著的特点是,它倾向于修改任务,让模型使用自己的知识来完成任务,而不需要专门设计额外的结构来使模型适应任务。
例如,TL;DR是GPT-2训练的提示,用于提示模型进行摘要任务。与TL;DR相反,前缀不包括文本中的自然语言提示,而是使用“past_key_values”将一组可训练参数连接起来,作为文本X前面的前缀。
在训练中,保持模型的参数不变,只训练前缀中的参数,我们获得一组前缀,允许模型执行特定任务。具体来说,由于GPT-2的结构是一个多层Transformer解码器,它对下一个单词的预测是由所有前面的单词共同决定的,所以只要我们能够对左侧上下文进行有针对性的更改,那么我们就可以控制模型的生成。
“past_key_values”最初用于存储模型的先前计算结果以加快计算速度,但前缀调整巧妙地利用了这一点,通过全连接神经网络(MLP)将一组参数映射到“past_key_values”所需的大小,然后将它们传递给模型的“past_key_values“参数,以实现在X之前添加前缀的目的。
传递给模型后,该参数将与模型的现有键和值在序列长度维度上串联,从而控制摘要的生成。
知识融合
尽管语言模型包含大量知识,但这种知识也是模型生成的摘要并不总是与原文事实一致的原因。
因此,如何利用我们需要的知识并消除错误的先验就成了一个问题。为此,我们通过在文本之前添加一组自然语言提示来强调我们所关心的事实。直观地说,如果我们在原文前面添加一组以关键字(如“关键关系”)为前导的结构化关系,这相当于给模型一个生成提示。然后,首先,模型的先验将假设此处包含一些重要信息。其次,添加的关系增加了关系中单词的权重,使它们更有可能出现在生成的摘要中。第三,通过实验,我们发现前缀调优非常善于提取结构化信息,因此在结构上添加前缀提示可以使可训练的连续前缀帮助模型关注这些结构化信息。
在我们的实验中,我们首先将这种方法应用于句子提取的初步实验,给模型一些关于句子的信息,看看模型是否能够准确地提取出该句子,然后将这种想法应用于知识增强的文档摘要。
对于句子提取,我们首先测试模型是否可以在没有任何指导的情况下,通过用源文本的第一句训练模型来准确地提取第一句。然后,我们在源文本前面添加任何句子的前三个标记,并用这些句子训练模型,看看模型是否能够准确地提取这些句子。最后,我们从一个句子中提取任意3个标记,并训练模型,看看模型是否能够准确地提取该句子。对于知识增强的文档摘要,我们使用OpenIE首先提取黄金摘要中包含的所有三元关系,然后对黄金摘要执行NER以挑出所有实体。在源文本前面添加包含我们关心的实体的三元组,我们就有了一个训练数据Xrel。我们提出的方法的俯视图如图1所示。
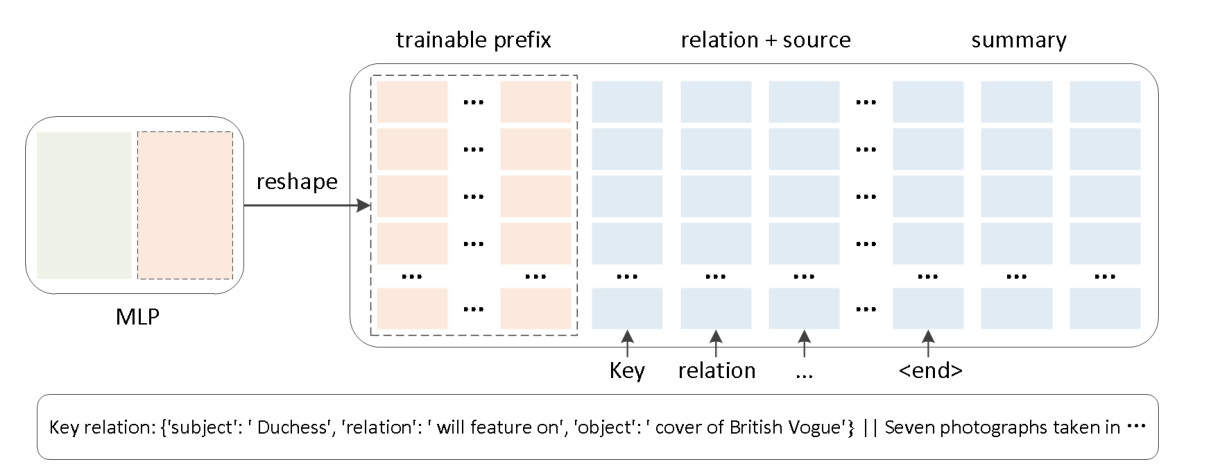
MLP中的粉红色区块代表MLP的最后一层。前缀调优对其进行重新整形,并将其传递给GPT-2的“past_key_values”参数,从而达到向模型添加连续前缀提示的目的。下面的简短文本是参照的一个示例。
key relation:{'subject':'Duchess' 'relation':'will feature on' 'object':'cover of British Vogue'}||Seven photographs taken in ...
关键关系:{“主题”:“公爵”“关系”:“将出现在”,“对象”:“英国时尚封面”}||七张照片拍摄于...
实验
首先通过几个初步实验来检验前缀调整的性能,然后在此基础上进行知识增强文档摘要。
基准
为了评估模型的性能,我们在实验中使用了两个指标。ROUGE评估生成摘要和黄金摘要之间的重叠程度,CoCo评估生成摘要与原文的事实一致性。
初步实验
初步实验分为两部分,第一部分是摘要,第二部分是句子提取。实验结果表明,前缀调整对于GPT-2上的文档摘要任务是有效的,并且它能够很好地从文本中的结构化内容中提取信息。前缀调优的这种性能很符合我们的目的。
生成式摘要
生成式摘要是一项初步实验,旨在检验GPT-2上在不添加关系的情况下对文档摘要进行前缀调整的性能。该结果可以用作知识增强文档摘要的基线。
CNN/Daily Mail:当在CNN/Daily Mail上对文档摘要任务使用前缀调整时,如果我们只使用长度为5的前缀,则ROUGE-1仅约为20,但如果使用更长的前缀,那么模型的性能立即显著提高。如果我们使用长度为100的前缀,并允许模型生成最大长度为100个的摘要,那么使用GPT-2在CNN/Daily Mail上生成的摘要的ROUGE-1可以达到30,这与Li和Liang(2021)报告的结论一致,即前缀越长,其表达能力越强。对于我们使用的数据部分,ROUGE分数超过了GPT-2使用TL;DR在CNN/Daily Mail上对文档摘要所报告的分数。见表2

然而,我们在使用前缀调整生成的CNN/Daily Mail摘要中发现了一个问题,即源文本中的原始句子经常出现在摘要中。由于有许多研究报告称,模型生成的CNN/Daily Mail摘要与XSum的摘要在抽象水平上存在显著差异(Lewis等人,2020;Xu等人,2020),我们使用XSum进行了另一项抽象摘要实验,以确定前缀调整是否会导致原文中的句子和单词出现在摘要中,或者训练数据的特性是否使得模型以这种方式表现。
XSum:如上所述,XSum数据集的黄金摘要非常简洁和精炼,这对预先训练的语言模型提出了更高的挑战。如果使用100长度的前缀,并且允许模型生成最大长度为100的摘要,那么GPT-2生成的摘要的ROUGE-1非常低,只有大约20%,但好消息是,生成的摘要确实更抽象,几乎没有出现原始文本中的原始句子。本实验表明,文章原句在摘要中的出现是数据集的结果。如果替换了一个非常抽象的数据集,则不会发生这种情况。此外,由于前缀调整可以完美地提取数据文本任务中的关键信息,如(Li and Liang,2021)所示,并且可以识别CNN/Daily Mail中的句子范围,而无需对训练数据进行任何处理,例如屏蔽,我们发现前缀调优可能对目标与源重叠的情况非常敏感,并且只需少量的训练就可以准确地识别来自源的具有特定模式的结构化信息。我们利用这一假设进行了句子提取的初步实验,探讨了前缀调整是否真的能识别句子范围,并像我们预期的那样从来源中提取句子。
抽象摘要的另一个有趣发现是,通过使用在CNN/Daily Mail上训练的前缀进行抽象摘要,并让模型生成XSum的摘要,该模型也表现出与生成CNN/Daily Mail摘要类似的行为,即多次从原文中生成句子,而不是更抽象的句子。
这表明,具有特定性能的经过训练的前缀提示可以传输到其他数据集使用,并允许使用其他数据集生成的文本显示类似的性能。
句子提取
句子提取是为了进一步探索前缀调整的性能。具体来说,这个初步实验使用方法论中提出的方法来测试前缀调优是否能够真正准确地识别我们想要提取的信息,尤其是它们的边界。实验表明,当使用CNN/Daily Mail进行句子提取实验时,如果在没有任何指导的情况下直接使用源的第一个句子(SenEx1)来训练模型,则该模型可以几乎完美地提取该句子。如果将句子的前三个标记添加到源的前面,然后训练模型(SenEx2),则模型可以在大部分时间提取该句子,但准确性降低。如果将一个句子中的任何三个标记添加到源中,并使用该句子训练模型(SenEx3),则模型仍然可以提取该句子,但ROUGE-1得分降至约65%。
上述初步实验表明,前缀调优确实可以直接从原始文本中提取关键信息,并且其提取非常精确,可以识别文本中结构化信息的模式,以令牌精度提取重要信息,并过滤掉原始文本中包含该信息的帧。因此,从理论上讲,我们可以通过这种方式将我们关心的知识添加到文本中,然后让文本将添加的知识结合起来,生成事实一致的摘要。以下是知识增强型文档摘要的功能。
知识增强型文档摘要
如方法论部分所述,我们分别提取了CNN/Daily Mail和XSum目标中的关系,然后将选定的关系添加到原始文本中,并训练前缀以生成摘要。结果表明,具有添加关系的数据集确实生成了与我们添加的关系主题更相关的摘要,并且大多数生成的摘要与添加的关系保持事实一致性。然而,在某些情况下,这种解决方案可能会出错。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号