knn和线性分类器
一、knn算法概述
knn首选是最简单的分类算法,其是有监督学习的分类算法之一。
二、knn算法过程
knn(k nearest neighbors k个最近的邻居):knn是当预测一个新的值x的时候,根据它距离k个点是什么类别来判断所属的类别。(具体理解见下图)
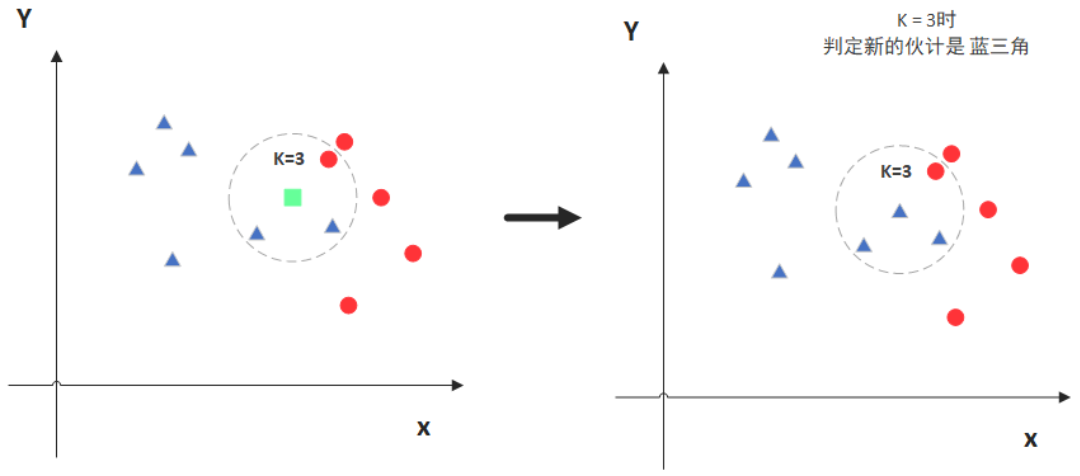
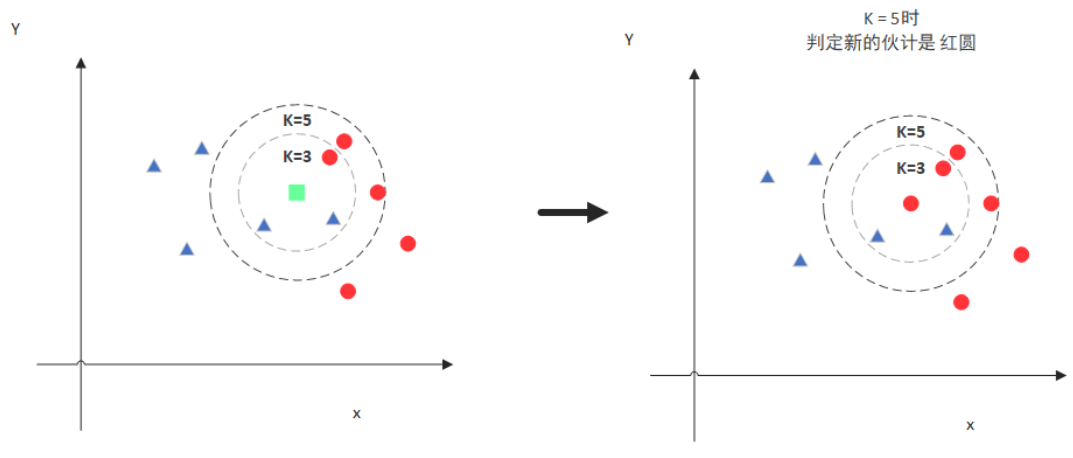
注意到k的选取和点的距离的计算方式有关,会影响最终的结果。
三、距离的计算方式
L1距离(曼哈顿距离)

L2距离(欧式距离)
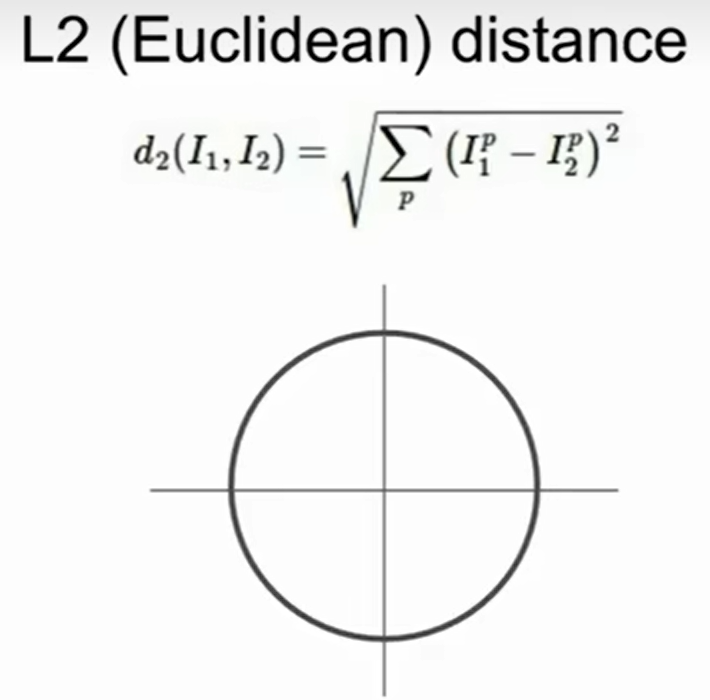
四、K值选择
K值的选取是根据交叉验证,从选取一个较小的K值开始,不断增加k的值,最终找到一个合适的K值。另外,交叉验证的图大致如下:

错误率是先降低,再升高。原因是首先周围有更多的样本可以借鉴了,分类准确率会更高一点。其次就是当K的增大的过程中,Knn就没有什么意义了。
五、Knn特点
非参的:
这个模型不会对数据做出任何的假设,另外这个模型的建立是根据数据来决定的。对比的是,线性回归则是首先假设线性回归是一条直线。
惰性:
没有明确的训练过程或者是因为训练过程很快。
Knn算法优点
1.相对于其他算法更简单易用。
2.模型训练更快。
3.预测效果好。
4.对异常值不敏感。
Knn算法缺点
1.预测阶段缓慢
2.对内存要求较高
3.对不相关的功能和数据规模敏感
六、knn与k-means的区别
knn算法:
knn算法基于k个周围的邻居来对未标记的观察进行分类,不用对未看见的数据集进行泛化。
k-means算法:
牧师-村民模型
有四个牧师去郊区布道,一开始牧师们随意选了几个布道点,并且把这几个布道点的情况公告给了郊区所有的村民,于是每个村民到离自己家最近的布道点去听课。
听课之后,大家觉得距离太远了,于是每个牧师统计了一下自己的课上所有的村民的地址,搬到了所有地址的中心地带,并且在海报上更新了自己的布道点的位置。
牧师每一次移动不可能离所有人都更近,有的人发现A牧师移动以后自己还不如去B牧师处听课更近,于是每个村民又去了离自己最近的布道点……
就这样,牧师每个礼拜更新自己的位置,村民根据自己的情况选择布道点,最终稳定了下来。
算法步骤
1.选择初始化的 k 个样本作为初始聚类中心 a=a1,a2,…ak ;
2.针对数据集中每个样本点计算它到 k 个聚类中心的距离,并将其分到距离最小的聚类中心所对应的类中;
3.针对每个类别点 ,重新计算它们的聚类中心;
4.重复上述2、3两步,直到达到某个终止条件
七、线性分类器
模型介绍
线性分类器是一种线性映射,将输入的图像特征映射为类别分数。

决策规则:若某个分类的得分比其他都要大,则该图片属于这个分类。
分类过程
1.图像表示成向量
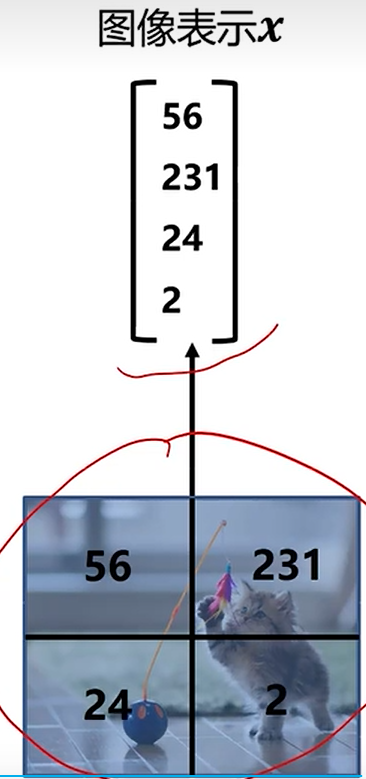
2.计算当前图片每个类别的分数
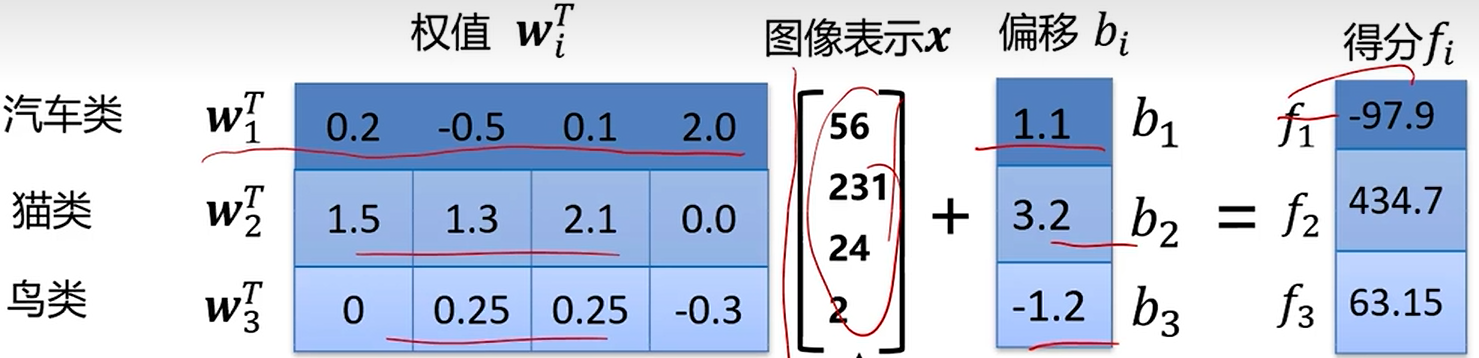
3.通过类别得分判定当前图像属于猫类
模型特点
形式简单、易于理解
通过层级结构(神经网络)或者高维映射(支 撑向量机)可以
形成功能强大的非线性模型

 浙公网安备 33010602011771号
浙公网安备 33010602011771号