
如何避免微服务设计中的耦合问题
如何避免微服务设计中的耦合问题
译自:How to Avoid Coupling in Microservices Design
Distributed monolith (分布一体式)是一个幽默的词,用来暗指那些设计欠佳的架构。如果忽略了微服务设计实践,不仅会无法克服一体式带来的缺点,也会导致出现新的、复杂的问题或恶化已存在的问题。当你在自豪地称之为微服务架构的同时,由于设计上缺少足够目的性的,最终的架构与随机爆破而成的碎片没有什么区别。
避免分布一体式的第一步非常简单:避免同时实现微服务。一体式是简单的,因为无需考虑分布式系统存在的复杂性。一个数据库,一个日志存储位置,一个监控系统,更简单的问题定位,以及端到端测试等等。除非你有充分的理由去使用微服务,否则最好采用同样的理念。
本文将主要关注微服务设计中的松耦合的重要性。我将给出一些简单的、可以避免耦合和导致分布一体式架构设计的例子。
微服务中的松耦合?
两个系统中,如果修改任意一方的设计、实现或行为不会对另一方造成影响,则称两个服务是松耦合的。当涉及到微服务时有可能会发生耦合,即对一个微服务的修改,会立即直接或间接地影响到与其他所有微服务的协作。
下面看一些设计中存在耦合的场景。
数据库共享
数据库共享是实现耦合的一种常见方式。当一个服务修改其实现时,会导致修改另外一个服务的实现。
选择数据存储、方案、以及请求的语言等细节应该对客户端不可见,如果共享了数据库,则可能会暴露所有的实现细节。为什么要隐藏实现细节?这是因为如果暴露了实现细节,那么未来对实现细节进行调整时将有可能会导致客户端代码不可用,除非客户端也同步做了相应的修改(这种方式是不可行或不可持续的)。在图1的左侧,Customers 与 Orders共享了数据库,因此Orders可以访问Customers 的数据模型细节,当这些细节发生变化时,有可能会导致异常。
应该如何处理?
一种方式是像图1的右侧那样,让Customers 提供一个API,Orders客户以通过该API获取customer的数据。只要Customers的合同不变,则数据格式也不会发生变化。Orders 无需知道数据的来源,且Customers 可以自主决定将该数据替换为另一个流数据源,而无需担心对其他服务的影响。
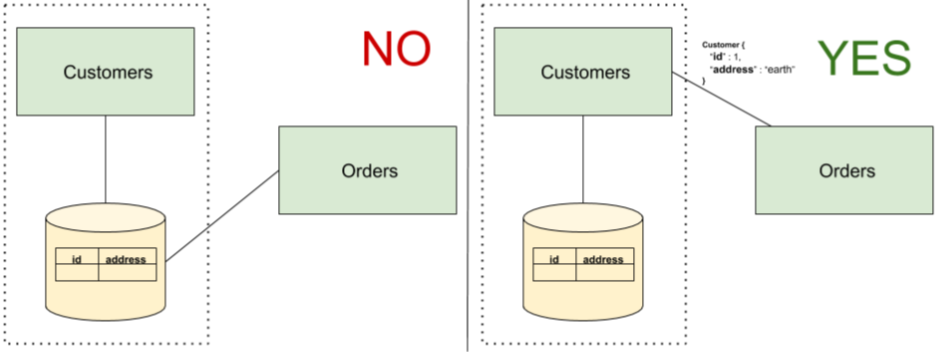
Fig. 1 — Implementation coupling through database sharing
代码共享
除了使用独立的数据库,微服务还有可能掉入共享库耦合的陷阱中。除了耦合造成的问题外,共享库的膨胀也可能导致需要通过不断更新来满足客户端的需求。因此共享代码应该尽量轻量,且尽量减少依赖性,并且应排除特定领域的逻辑。
在图2的左侧,Customers 在与Orders共享的库中定义了customer 对象。Customers 使用该对象模型来响应对customer 数据的请求。Orders 使用相同的对象来读取(请求的)响应body。如果Customers 打算对customer 对象的内部结构进行调整时,如将地址字段切分为多条地址线,这种情况会导致Orders 服务崩溃。注意这种不正确的模式也可能会影响客户对编程语言的选择,例如当Customers 决定切换到一个不同的编程语言,它需要考虑使用其对象模型实现的所有服务。
应该如何处理?
Customers 和 Orders 应该在独立依赖库中包含customers 对象的拷贝。只要Customers 遵循"合同",则所有服务都可以正常运行。
记住,每次发生变更时,你不需要将一堆崩溃的服务黏合到一起,只需要专注于创建一个灵活的架构,并丢掉分布一体式。

Fig. 2–Implementation coupling through code sharing
同步通信
当由于服务(呼叫者)期望另一个服务(被呼叫者)的即时响应而无法继续处理时,便会发生暂时性耦合。由于被呼叫者存在响应延迟,因此有可能会对呼叫者的响应时间造成不利影响。被调用者必须保持开启状态,并能够正常响应。这种情况通常发生在同步通信的场景下。
如图3所示,Customers 准备数据的时间越长,Orders 在响应客户端之前等待的时间也就越长。换句话说,Customers 的响应延迟导致了Orders 的响应延迟。这种处理方式也可能导致级联错误,如果Customers 无法响应,Orders 最终也会因为超时而无法响应。如果在一段时间内,Customers 一直很慢且无法响应,则可能会导致Orders 打开大量到Customers的连接,最终导致内存耗尽而失败。为了提供一个满意的服务,Orders 应该消除暂时性耦合存在的基础。没有人希望愤怒的顾客排队等待他们的订单到达,分布一体式的创建者也不例外。
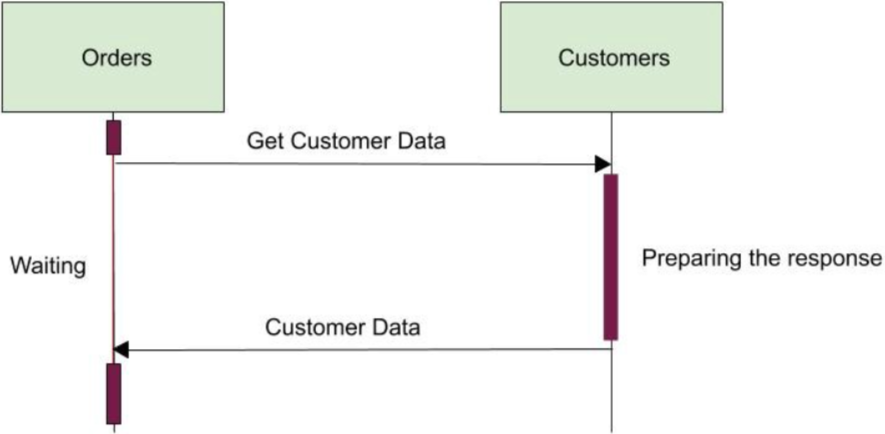
Fig. 3 — Temporal coupling caused by synchronous communication between services
应该如何处理?
问题的答案依赖于你需要一个长期的还是一个短期的解决方案。如果你需要继续使用同步调用,则需要通过缓存(请求的)响应或使用熔断模式控制级联失败的方式来降低暂时性的依赖。一种更好的方式是切换到异步通信,使用轮询或依赖像Kafka这样的消息代理来传递消息。当采用异步通信时,服务应该考虑和下游服务达成最终一致性状态的延迟对响应时间的影响,并做出必要的调整来防止"合同"的中断。服务级别的协定是"合同"的重要组成部分。
共享测试环境
当持续集成或持续发布一个服务需要依赖另一个服务时,就会发生部署耦合。微服务意味着敏捷,独立的部署和处理是实现该目标的必要条件。
一个典型的例子是:部署的服务共享相同的测试环境。假设一个服务在最终部署到生产环境前需要做一个简单的性能测试。如果该服务与其他服务共享相同的测试环境(有可能同时运行性能测试),有可能会导致测试环境崩溃或由于发生非预期的高流量而导致资源饱和,最终有可能会导致部署失败。

Fig. 4 — Deployment coupling caused by sharing test environments
在图4的左侧,Delivery 和Orders使用相同的Customers 服务来模拟进行性能测试。Orders 团队最初设计该模拟服务的目的是为了在给定资源量的情况下模仿客户的行为。在添加了Delivery 之后,计算的资源量将会失效,同时运行两个服务的性能测试将会导致部署失败。因此,必须重新配置模拟服务,以使用更多资源来模仿相同的响应率。
应该如何处理?
很简答,不要和任何服务共享模拟服务。
运行集成测试的下游服务
这也是一种部署耦合。当针对一个微服务的实例进行功能测试时,该微服务实例会在非测试环境中直接调用下游服务。这种依赖性会导致下游服务必须在整个测试阶段保持运行状态。任何可用性延迟或下游服务的响应时间都可能会导致测试、构建流程以及部署同时失败。
应该如何处理?
在集成测试中模拟下游服务(除非有充足的理由必须使用真实的下游服务)。更好的方式是将下游服务容器化,并加载到相同的微服务实例中,以此来避免网络连接问题。
共享过多的领域数据
领域驱动设计(DDD)是将一体式服务拆分为微服务的推荐技术。一般原则是为每个业务子域启用一个微服务。每个微服务都在其子域的边界内运行,而不必处理其外部的任何事物。
如果微服务共享领域特定的数据,则会导致领域耦合,违背了分离边界的初衷。服务将无法控制客户端如何使用共享的数据。一个客户端可能会无意间拥有其本不该拥有的数据,或因为缺乏特定领域的知识而错误地使用这些数据。
再者,如果服务共享了太多的领域数据,则有可能因为共享敏感数据而引入安全风险。你可能会对自己认为的敏感数据进行防护,但无法保证客户端也做出类似的动作,这是因为对这部分数据的责任和认知已经超出了它们的范畴。
图5展示了一个领域耦合的例子。在图的左侧,Orders向Customers 请求customer数据,然后接收到customer的信用卡号以及地址。再调用Billing,传递费用和商品ID,以及所有这些数据。在Billing成功向客户收费后,Orders 会向Delivery发送相同的数据字段集。图的右侧,展示了这些微服务间期望交互的数据。如果设计合理,Billing应该是唯一一个拥有并保存账单信息的微服务,不需要从其他服务接收这些信息。
应该如何处理?
仅共享客户端真正需要的数据,如果客户端需要的数据超出了领域边界,则需要重新考虑服务边界。
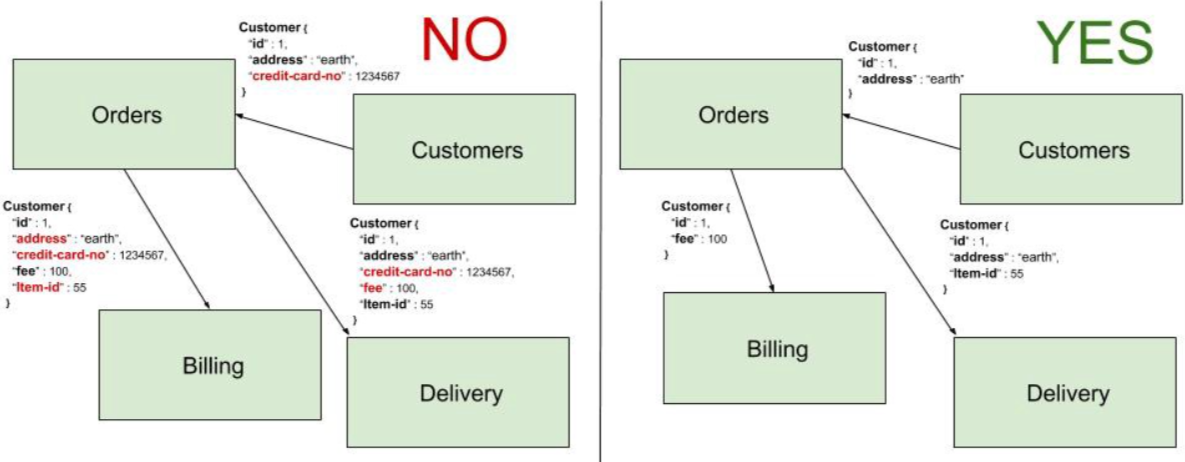
Fig. 5 — Domain coupling through excessive data sharing
总结
微服务是一个新的架构风格,如果没有合理地采用,则有可能会降低其带来的受益。为了避免过早地设计微服务网络,如分布一体式,你的系统一开始应该是个整体,然后逐步将其打散为合理的微服务。
当从一体式迁移到微服务架构时,可能有很多方式导致设计上的失误,其中缺少松耦合是必须要注意的一点。耦合可能以多种形式出现:实现上的,临时的,部署的以及领域上的耦合。本文中给出了每种类型的耦合的例子,以及一些建议方案来帮助避免对应的耦合场景。如果你的服务已经是分布一体式的,不用担心,遵循本文中讨论的一些技术来采取纠正措施永远不会太晚。
引用
- Sam Newman (2020), Monolith to Microservices. O’REILLY.
- Martin Fowler, How to break a Monolith into Microservices.
本文来自博客园,作者:charlieroro,转载请注明原文链接:https://www.cnblogs.com/charlieroro/p/14428617.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号