

MySql索引
- mysql索引主要分为两种结构:B+Tree(默认)和Hash索引
- 索引分类:
Normal普通索引:大多数情况下可以使用。
Unique唯一索引:表示唯一不允许重复的索引,主键自动拥有Unique约束的唯一索引。
Full Text全文索引:检索长文本的时候效果好
SPATIAL空间索引:地理空间位置数据类型的索引。 - mysql为什么不用二叉查找树
- 二叉查找树高度不平衡,当数据量增大时,树的高度会增加,导致查找效率降低,高度越高,IO次数越多,效率越低。
- 二叉查找树每个结点只存储一个数据,磁盘块的利用率低,导致性能下降,不能发挥磁盘预读功能。
- 局部性原理:描述程序在访问存储器时的局部性行为,CPU访问存储器时,无论存取指令还是存储数据,访问的存储单元都趋于聚集在一个较小的连续区域中。
时间局部性:如果一个信息项正在被访问,那么在近期它可能还会被再次访问。
空间局部性:在最近的将来将要用到的信息很可能与现在正在使用的信息在空间地址是临近的。
顺序局部性:在我们的程序中,大部分指令都是顺序执行的,顺序执行和非顺序执行的比例大概是5:1. - 磁盘预读:根据局部性原理,磁盘顺序读取的效率很高(不需要寻道时间),所以即使只需要读取一个字节,磁盘也会读取一页的数据。
- mysql为什么不用AVL(平衡二叉查找树)
- 每次增加和删除数据会旋转维护数据,维护成本高。
- AVL树高时,查找效率还是很低。
- 每个节点存储一个数据,节点数据内容太少,不能发挥磁盘预读功能。
- mysql为什么不用红黑树
- 红黑树树高时,IO次数越多,效率越低,查找效率还是很低。
- 每个节点存储一个数据,节点数据内容太少,不能发挥磁盘预读功能。
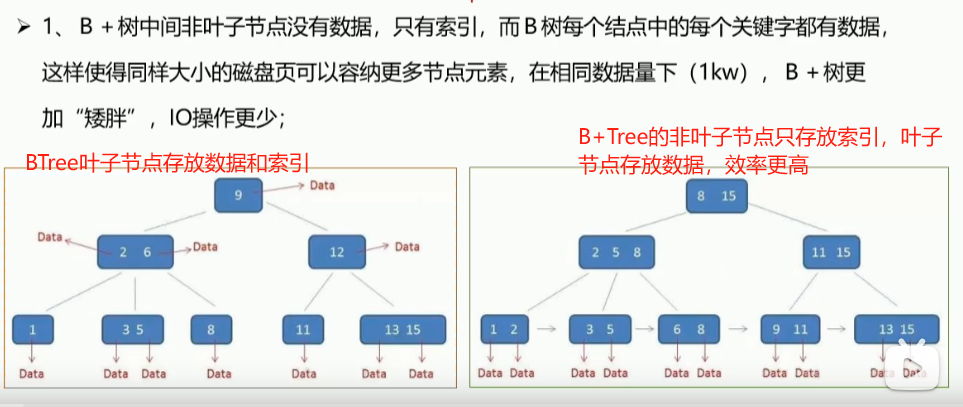
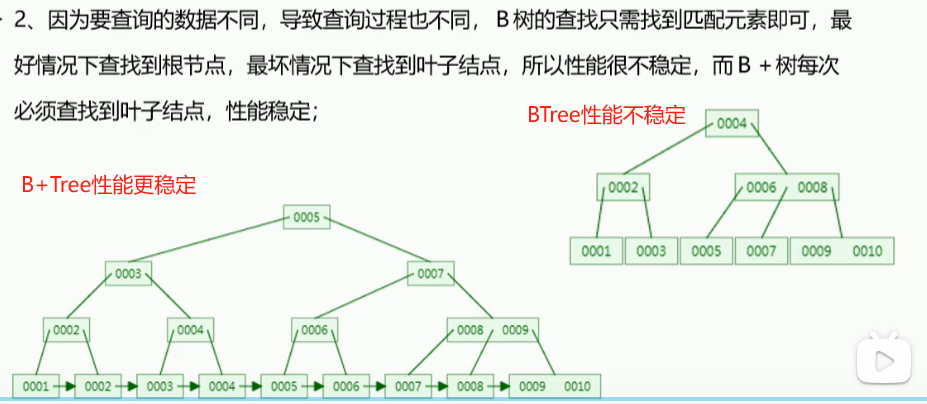
- 为什么没有采用BTree而采用了B+Tree
| 特性 | B-Tree | B+Tree |
| ------ | ------------------ | ------------------------ |
| 数据存储位置 | 所有节点(内节点+叶子节点)都存数据 | 只在叶子节点存储数据,非叶子节点只存索引 |
| 叶子节点 | 不一定全部挂在一起 | 所有叶子节点通过链表相连 |
| 查询效率 | 查询路径较短,但范围查找效率低 | 范围查找、高频排序更高效 |
| 磁盘预读效率 | 较差 | 更适合磁盘块预读(叶子链+顺序访问) |
9. 聚集/聚簇索引、非聚集/聚簇索引:
聚集/聚簇索引是主键和数据在一起,InnoDB是聚集/聚簇索引。
非聚集/聚簇索引是主键和数据不在一起。MyISAM是非聚集/聚簇索引,InnoDB的二级索引也是非聚簇索引。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号