TensorFlow学习笔记3-从MNIST开始
TensorFlow学习笔记3-从MNIST开始学习softmax
本笔记内容为“从MNIST学习softmax regression算法的实现”。
注意:由于我学习机器学习及之前的书写习惯,约定如下:
-
\(X\)表示训练集的设计矩阵,其大小为m行n列,m表示训练集的大小(size),n表示特征的个数;
-
\(W\)表示权重矩阵,其大小是n行k列,n为输入特征的个数,k为输出(特征)的个数;
-
\(\boldsymbol{y}\)表示训练集对应标签,其大小为m行,m表示训练集的大小(size);
-
\(\boldsymbol{y’}\)表示将测试向量\(x\)输入后得到的测试结果;
总之:
注意区分这里的:\(\boldsymbol{y'}=XW+\boldsymbol{b}\) 表示矩阵形式的预测结果(\(\boldsymbol{y’}\)和\(\boldsymbol{b}\)是向量);
之前机器学习中的是(如《机器学习实战》中SVM一章):$y’=\omega^T x+b $ 表示向量形式的预测结果(\(y'\)和\(b\)是标量);
算法部分:包括预测模型和优化目标
以手写输入MNIST为例:
预测模型
\[\boldsymbol{y'}=softmax(\boldsymbol{z})=softmax(X \times W + \boldsymbol{b})
\]
其中softmax函数是归一化函数:
\[softmax(x_i)=\frac{exp(x_i)}{\sum_j exp(x_j)}
\]
其中\(i , j\)的范围为1~10。softmax函数将\(\boldsymbol{z}\)归一化之后变为\(\boldsymbol{y’}\)(预测值)。如下图。
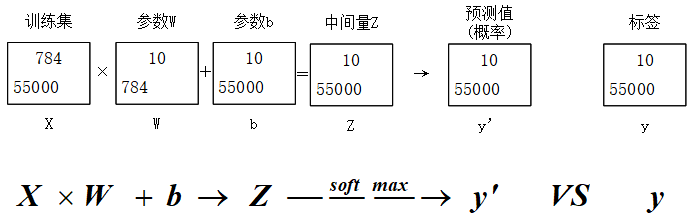
- 训练集:共55000条数据,每条数据中有784个特征(将28*28个像素点进行展开,忽略了像素间的结构关系),矩阵中m=55000,n=784;
- 参数\(W\)中的元素\(W_{i,j}\)的含义是:第i个像素点在数字j中占的权重,意思是如果很多数字j的实例中都有i,说明像素点i很大可能代表数字j,那么其权重会很大。
- 参数\(b\)中的元素\(b_{i,j}\)的含义是:第i个像素点在数字j的偏置量,意思是如果大部分数字都是0,则0的特征对应的bias值会很大。

优化目标:交叉熵的最小化
交叉熵:
\[H_{y}(y')=-\sum{y_i log(y'_i)}
\]
其中,
每个batch中的所有预测项的交叉熵的平均值为评价指标。
实现部分:
用随机梯度下降优化器对评价指标进行优化。
每次随机选取训练集中的100个子集作为batch(桶)进行训练,共训练1000次。
预测模型的评价
统计准确率。
附代码:
import tensorflow as tf
# 1 Collect data
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/",one_hot=True);
print(mnist.train.images.shape, mnist.train.labels.shape);
print(mnist.test.images.shape,mnist.test.labels.shape);
print(mnist.validation.images.shape,mnist.validation.labels.shape);
# 2 Create Model
X = tf.placeholder(tf.float32,[None,784]);
y = tf.placeholder(tf.float32,[None,10]);
W = tf.Variable(tf.random_uniform([784,10],-1,1));
b = tf.Variable(tf.zeros([10]));
z = tf.matmul(X,W)+b;
y_ = tf.nn.softmax(z);
# 3 loss function
loss = -tf.reduce_mean(tf.reduce_sum(y*tf.log(y_),axis=1));
optimizer = tf.train.GradientDescentOptimizer(0.5);
train = optimizer.minimize(loss);
# 4 initialzer
init = tf.initialize_all_variables();
sess = tf.InteractiveSession();
sess.run(init);
# 5 Train
for step in range(1000):
x_batch,y_batch = mnist.train.next_batch(100);
sess.run(train,feed_dict={X:x_batch,y:y_batch});
if step%10 ==0:
print(step/10,"%",sess.run(loss,feed_dict={X:x_batch,y:y_batch}));
# 6 Output
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(y_,1));
accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32));
print(accuracy.eval({X:mnist.test.images,y:mnist.test.labels}));
sess.close();
更进一步
- 使用
InteractiveSession将这个session注册为默认的session,之后的运算都默认跑在这个session里,不同session之间的运算与数据相互独立。
比较
batch_xs, batch_ys = mnist.train.next_batch(100) # 使用minibatch,一个batch大小为100
train_step.run({x: batch_xs, y: batch_ys})
与
batch = mnist.train.next_batch(50)
train_step.run(feed_dict={x: batch[0], y_: batch[1]})
的异同。
本质没有区别:也就是说只要是字典dict形式的写法,就是输入;否则就是输出。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号