机器学习实战笔记-2-7分类机器学习形象化总结
-
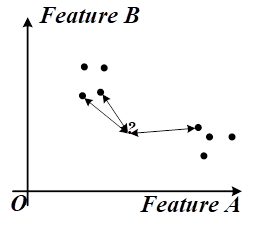
kNN算法:就看测试向量距哪种更近,前k个最近的点中哪类多,预测结果就是哪类。
-
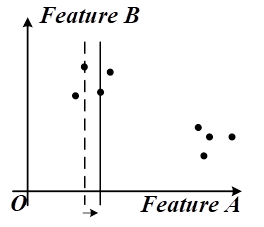
决策树:选择用来划分数据集的最好特征(最大的\(infoGain = baseEntropy - newEntropy\)),对该特征的每一个值创建一个子节点,递归至label完全相同或已用完所有特征。
-
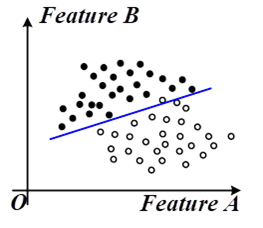
朴素贝叶斯:if \(p\left( c_{1} \middle| x,y \right) > p\left( c_{2} \middle| x,y \right)\),则属于类别c2。假设:每个特征相互独立且同等重要。
\[p\left( c_{i} \middle| x,y \right) = \frac{p\left( x,y \middle| c_{i} \right)p(c_{i})}{p(x,y)} \rightarrow \ p\left( x \middle| c_{i} \right) \bullet p\left( y \middle| c_{i} \right) \bullet p(c_{i}) \]
增大回归系数后进行迭代,直到迭代完所有样本。本质是:在训练样本下的极大似然概率最大时的回归系数。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号