
GPT-1:与BERT对比简单看GPT-1
个人主页:https://bento.me/zhengyanghou
Github:https://github.com/Jenqyang

GPT-1发表于2018年6月,比BERT早几个月。GPT-1使用的是Transformer decoder(解码器),而BERT使用的是Transformer encoder(编码器)。
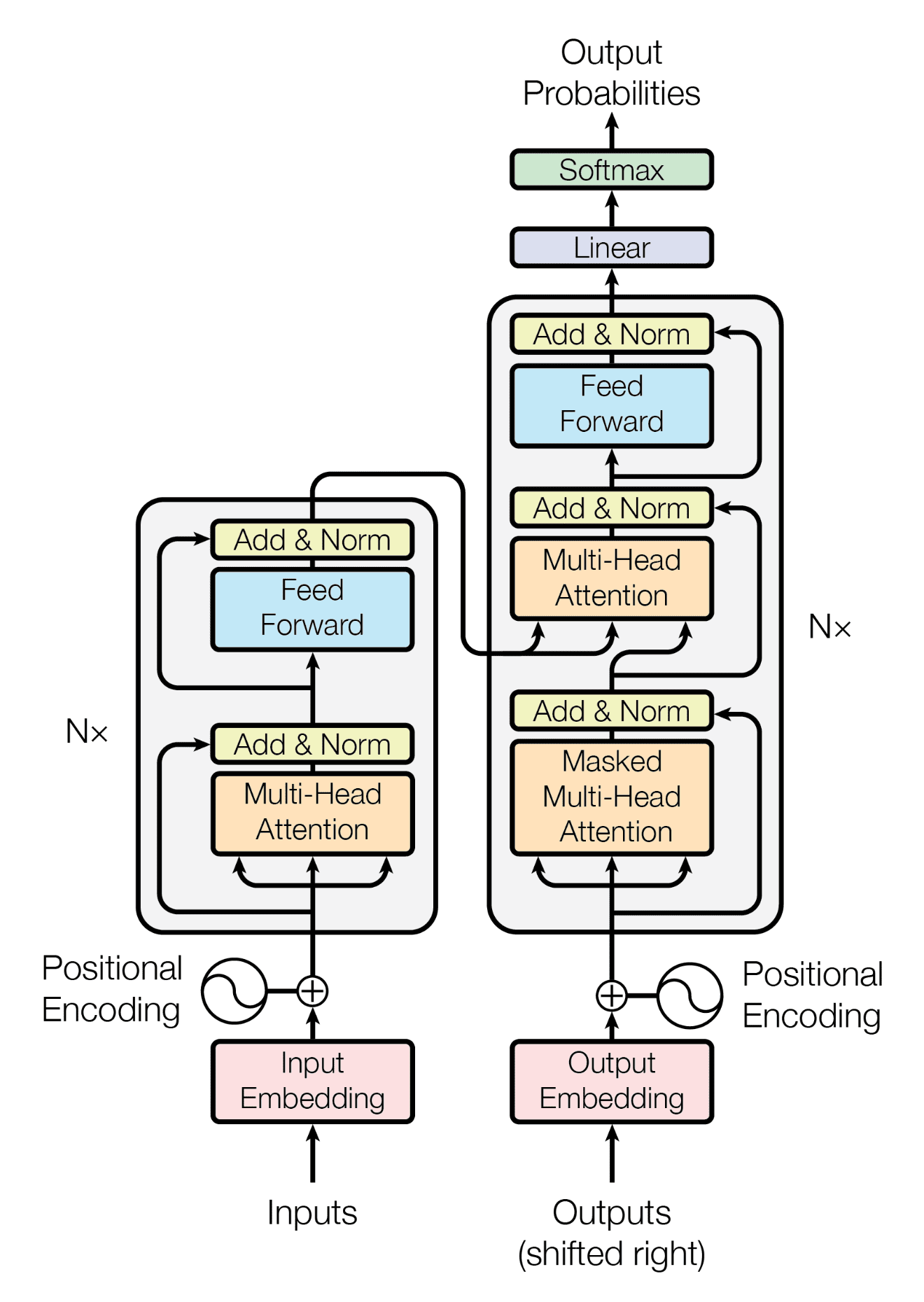
解码器和编码器最大的区别是解码器加入了掩码机制(Mask),这就导致在实际问题中,BERT是在做完型填空(没有Mask就意味着同时知道历史和未来的数据,要做的是根据历史和未来预测当前,这当然简单得多),而GPT-1是在续写作文(加入Mask就意味着只知道当前和历史数据,要做的是根据历史预测未来,这就比BERT要难)。
这也是为什么BERT前几年在NLP界的影响力也远高于GPT。
GPT-1的构造分为两个阶段:Unsupervised pre-training和Supervised fine-tuning。GPT-1在预训练阶段(pre-training)使用无标注的数据进行无监督训练,在微调(fine-tuning)阶段使用有标注的数据进行监督训练。
Unsupervised pre-training
预训练阶段器目标函数为:
$$L_1(U)=\sum_i logP(u_i|u_{i-k},\cdots,u_{i-1};\Theta)$$
其中$\Theta$就是GPT-1模型,通过$u_i$之前的数据计算得到$u_i$的概率。
Supervised fine-tuning
GPT-1的微调相当于一个分类任务,给定输入序列$(x1,\cdots,xm)$都有标签$y$(其实就是标号),将序列$(x1,\cdots,xm)$放入训练好的模型中的得到Transformer块最后一层的输出$h^m_l$,接着和一个输出层$W_y$相乘,最后经过一层$softmax$就得到目标$y$的预测概率:
$$P(y|x1,\cdots,xm) = softmax(h_l^m W_y)$$
得到目标函数:
$$L_2(C) = \sum_{(x,y)}logP(y|x1,\cdots,x^m)$$
但实际上微调的目标函数是:
$$L_3(C) = L_2(C) + \lambda\ast L_1(C)$$
这是因为同时预测序列的下一个词和预测序列的标签效果最好,因此也加入了无监督训练时的目标函数。
这点与BERT就不太一样了,BERT微调时只使用了下游任务的目标函数。
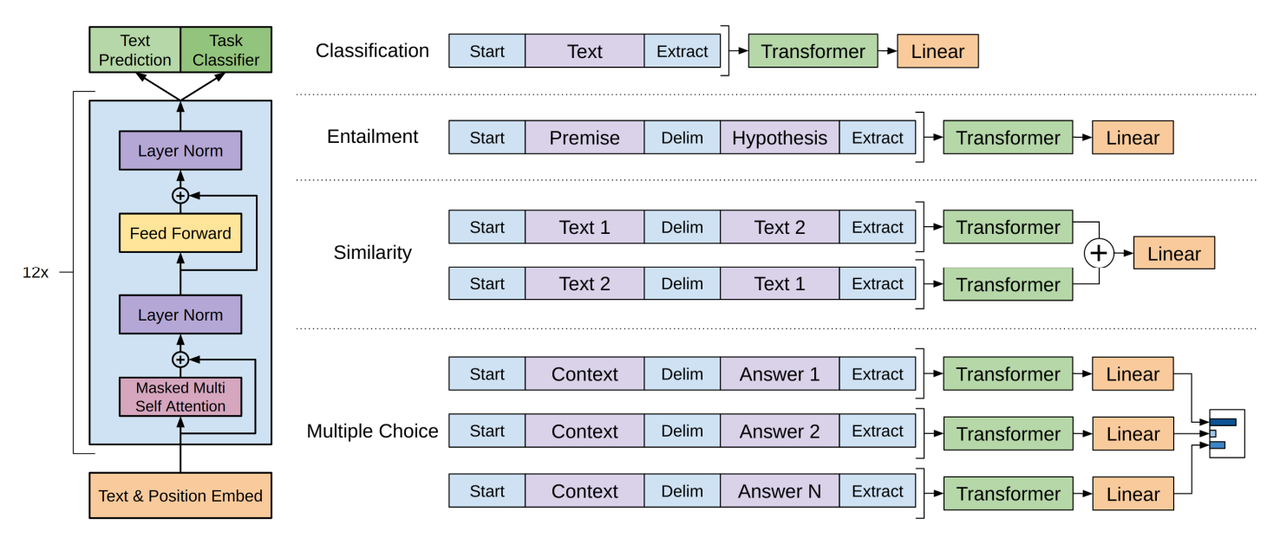
上图展示了几类常见的下游任务都能够转换成序列-标签的形式。原理就是将所有序列进行拼接,对每个组合情况都进行标号。在不同下游任务中Transformer的模型保持不变。这样,不同的子任务都能转成相同的下游任务格式,GPT-1也能以这样的形式进行微调。
GPT-1使用spaCy分词器(tokenizer),在包含7000本未发表书籍的BooksCorpus数据集上进行预训练,最终得到SOTA效果。
个人主页:https://bento.me/zhengyanghou
Github:https://github.com/Jenqyang
本文由mdnice多平台发布

 浙公网安备 33010602011771号
浙公网安备 33010602011771号