Embedding and Predicting Software Security Entity Relationships: A Knowledge Graph Based Approach
嵌入和预测软件安全实体关系:一种基于知识图谱的方法
一、摘要
软件安全知识涉及异构的安全概念(如软件弱点和攻击模式)和安全实例(如特定软件产品的漏洞),可视为软件安全实体。在软件安全实体中,有很多类型内的关系,也有很多跨类型的关系。预测软件安全实体关系有助于丰富软件安全知识(例如,发现现有实体之间缺失的关系)。不幸的是,软件安全实体目前记录在单独的数据库中,例如常见漏洞和暴露 (CVE)、常见弱点枚举 (CWE) 和常见攻击模式枚举和分类 (CAPEC)。这种超文档表示不能支持软件实体关系的有效推理。
在本文中,我们建议将来自不同数据库的异构软件安全概念和实例整合到一个连贯的知识图谱中。我们开发了一种知识图谱嵌入方法,该方法将软件安全实体的符号关系和描述信息嵌入到连续向量空间中。生成的实体和关系嵌入可预测软件安全实体关系。基于开放世界假设,我们进行了广泛的实验来评估我们基于知识图谱的方法在预测软件安全实体的各种类型内和跨类型关系方面的有效性。
二、数据集介绍
Common Weakness Enumeration (CWE) 是社区开发的常见软件弱点模式列表,例如 CWE183: Permissive Whitelist。通用攻击模式枚举和分类 (CAPEC) 是攻击者用来利用已知弱点(例如 CAPEC-182:Flash 注入)的已知攻击模式列表。 Common Vulnerabilities and Exposures (CVE) 是一个公开披露的网络安全漏洞和软件产品暴露的数据库,例如 CVE-20181002200 是 Debian Linux 中 plexus-archiver 工具的目录遍历漏洞。
三、文章贡献
(1)我们的知识图谱是第一个集成异构安全概念和实例的软件安全知识图谱。这种知识异构有利于嵌入软件安全实体关系。
(2)我们开发了一种先进的知识图嵌入方法,将安全概念和实例的结构性和描述性知识嵌入到连续向量空间中,以预测软件安全实体关系。
(3)大量实验表明,我们基于知识图谱的嵌入方法可以准确预测软件安全实体的类型内和跨类型关系。
四、句子嵌入
给定预训练词嵌入字典,获得句子嵌入的一种简单方法是对句子中词的词嵌入求平均(即平均池化)。然而,研究 表明,与平均池化相比,使用 CNN 编码器可以为嵌入句子提取更多信息特征。因此,我们设计了一个 CNN 编码器,它将可变长度实体描述作为输入并输出描述的句子嵌入。它有五个层,包括输入层、两个卷积层和两个池化层。输入层将输入句子表示为 nw 维词嵌入序列。卷积层将 N 个过滤器应用于输入句子上的 n-gram 滑动窗口以提取特征。第一个池化层使用最大池化来捕获最重要的特征。第二个池化层使用均值池化来避免信息丢失。
给定实体的描述,CNN 编码器输出一个固定长度的向量作为初始 Ed,它将用于设定的评分函数方程。在嵌入过程中,将调整初始 Ed 以最小化损失函数方程。梯度将通过 CNN 层反向传播以训练编码器模型。在这个过程中,可以选择性地对输入层中预先训练的词嵌入进行微调。
五、评估指标
我们使用三个指标:(1)Top-k 准确率(Top-k Acc):正确实体在 top-k 列表中的预测任务的比例。我们报告 Top-5 准确率 和 Top-10 准确率。 (2)Mean Reciprocal Rank (MRR):每个预测任务的正确实体的倒数秩的平均值。 (3)Mean Average Precision (MAP):每个预测任务的所有相关实体的平均精度的平均值。请注意,如果知识图中存在损坏的三元组,将其排在原始三元组之前并没有错 。所以我们也认为这样的预测在 Top-k Acc 和 MRR 上是正确的。
六、模型结果
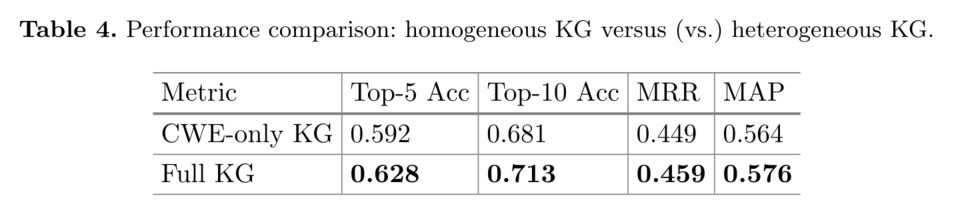
全异构知识图谱的预测性能始终优于仅 CWE 的同构知识图谱。
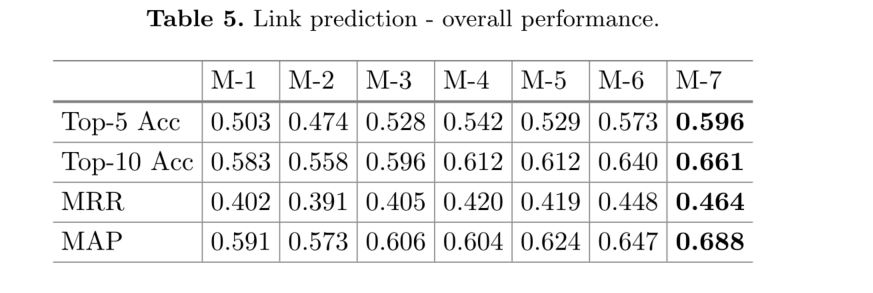
在M1~M等评分函数下模型的连接预测整体的性能比较如下。
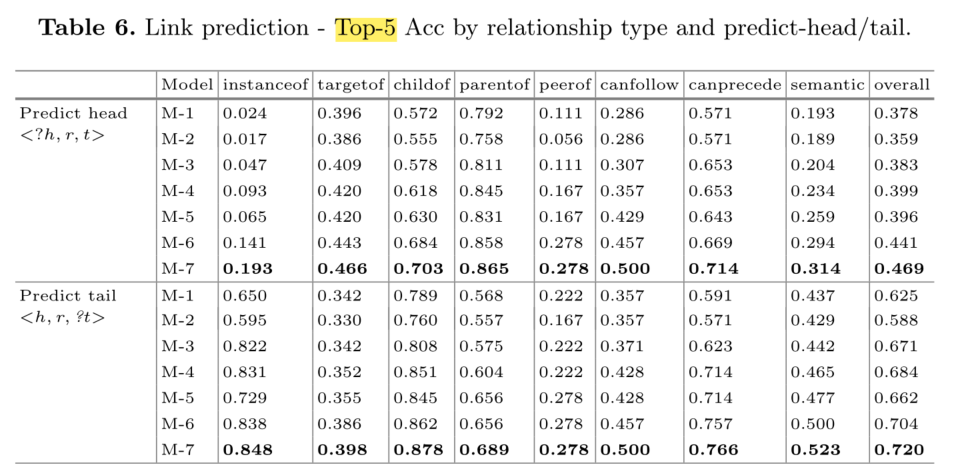
下表中给出了Top-5准确率的详细性能。我们可以看到,M-7在所有关系和预测头和预测尾任务中都取得了最好的性能(在所有情况下都显著优于M-1)。
七、嵌入性能因素
(1)一段关系的三元组越多,它学到的预测性嵌入就越多。
(2)其次,关系的语义越多样化,预测嵌入就越难学习。
(3)一段关系的“多”端越多,学习嵌入对预测“多”端的预测性就越低。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号