Network Embedding
网络表示
- 网络表示学习(DeepWalk,LINE,node2vec,SDNE)
- 网络表示学习相关资料
- NE(Network Embedding)论文小览
- 网络表示学习领域(NRL/NE)必读论文汇总
- 一文详解 Word2vec 之 Skip-Gram 模型
- 自编码器
- skip-gram源码解析的一些文章和见解

Word2Vec
word2vec是根据词的共现关系,将词映射到低维向量,并保留了语料中丰富的信息
- Skip-Gram
- 给定input word 预测上下文( 如已知 Wt 预测上下文Wt-2,Wt-1,Wt+1)
- CBOW
- 给定上下文,预测input word( 如已知 Wt 上下文Wt-2,Wt-1,Wt+1 预测 Wt)

分为两个部分:
- 建立模型
- 目的:基于训练数据构建神经网络,训练好后使用模型通过训练数据所学到的参数(建模不是最终目的)
- 通过模型获取嵌入词向量
基于神经网络的语言模型的目标函数通常取为如下对数似然函数:

关键是条件概率函数P的构造
基于Hierarchical softmax 的CBOW 模型优化目标函数如上
基于Hierarchical softmax 的skip-gram 模型,优化的目标函数如
DeepWalk
将一个网络中的每个节点映射成一个低维的向量,即希望在原始网络中关系越紧密的结点对应的向量在其空间中距离越近
- word2vec针对的是文本,或者说是有序的单词序列
- Deepwalk针对的是带有拓扑结构的网络
- 针对每个节点跑了个随机游走,游走过程中就得到了一系列的有序节点序列,这些节点序列可以类比于文章的句子,节点类比于句子中的单词,然后再使用word2vec跑,得到对应的向量
过程:
- 为每个节点生成随机游走Wv,然后用来更新网络嵌入(7)
- 选择skip-gram 作为更新节点表示的方法

skip -gram
关键思想:产长预测句子中附近的单词嵌入
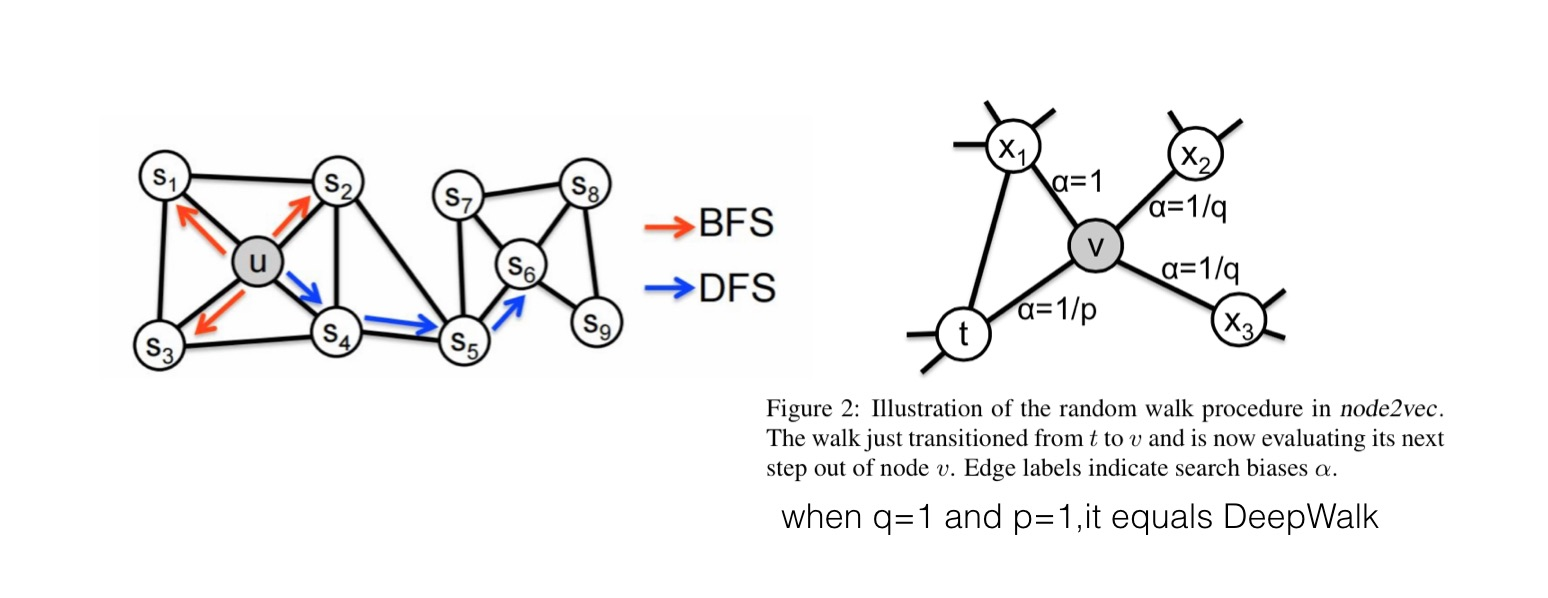
Node2vec
类似于deepwalk,主要的创新点在于改进了随机游走的策略,定义了两个参数p和q,在BFS和DFS中达到一个平衡,同时考虑到局部和宏观的信息,并且具有很高的适应性
LINE(Large scale information network embedding)
2015年提出的一中网络表示学习方法,该方法提出了一阶相似度与二阶邻近度的概念,基于这两个邻近度,提出了优化函数,得到的最优化结果即为每个节点的向量表示
- 一阶相似性:直接相连的节点表示尽可能相近(适用于无向)
- 二阶相似性:两个节点公共的邻居节点越多,两个节点的表示越相近,类似,使用预警相似的两个单词很有可能是同义词(适用于有向图和无向图)
- 边缘采样算法优化目标,采样概率与权重成比例
- 因为边的权重差异大,直接 SGD 效果不好,这里按照边的权重采样,每条边当作 binary 算
- DW 没有提供明确的目标,没有阐明哪些网络属性将被保留,仅适用于未加权网络,LINE 适用于网络的加权和不加权的边

MMDW(Max-Margin DeepWalk Discriminative Learning of Network Representation)
DW本身是无监督的,如果能够引入label数据,生成的向量对于分类任务会有更好的作用
将DeepWalk和Max-Margin(SVM)结合起来
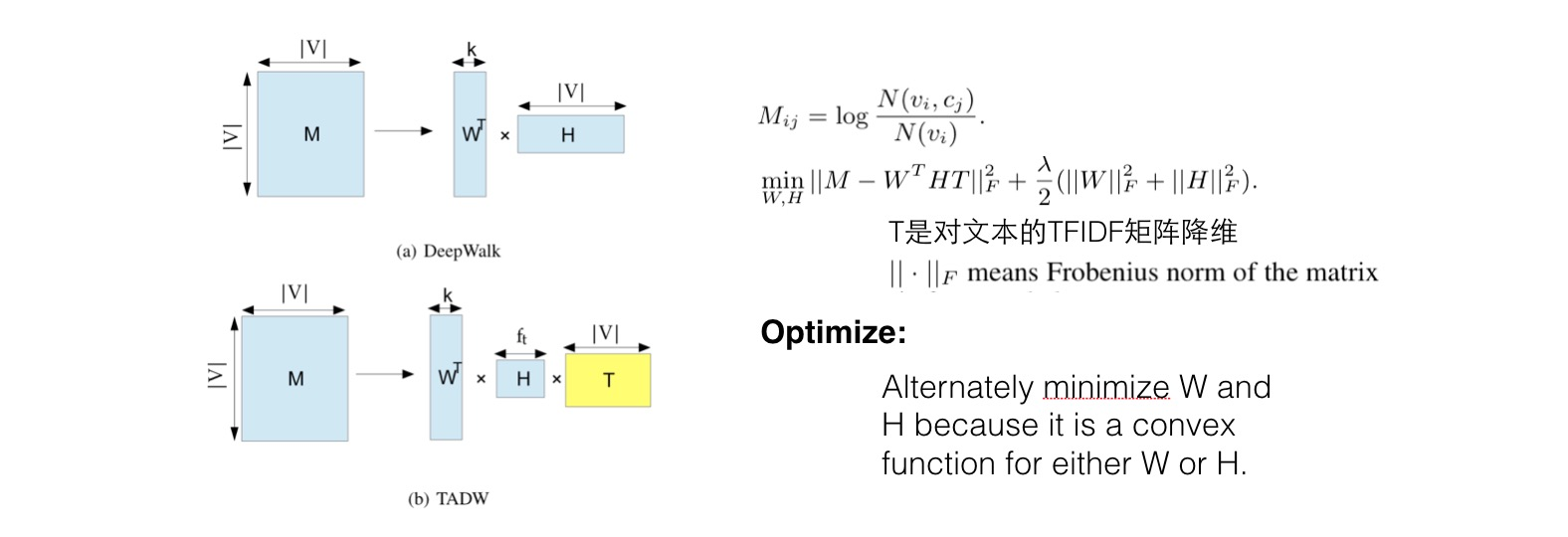
TADW(Network Representation Learning with Rich Text Information.)
在矩阵分解这个框架中,将文本直接以一个子矩阵的方式加入,会使学到的向量包含更丰富的信息。
文本矩阵是对TFIDF矩阵的SVD降维结果
Extra Info
CANE
CENE(A General Framework for Content-enhanced Network Representation Learning)
问题
同时利用网络结构特征和文本特征来学习网络中节点的embedding

如果您认为本文对得起您所阅读所花的时间,欢迎点击右下角↘ 推荐。您的支持是我继续写作最大的动力,谢谢 (●'◡'●)
字节跳动职位长期内推,如有需求可发送简历至 lichaoran.cr@bytedance.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号