数据操作
一、数据操作介绍
数据操作最重要的一步也是第一步就是收集数据.
而收集数据的方式有很多种,第一种就是我们已经将数据下载到了本地,在本地通过文件进行访问.
第二种就是需要到网站的API处获取数据或者网页上爬取数据.
还有一种可能就是你的公司里面有自己的数据库,直接访问数据库里面的数据进行分析。
需要注意的是我们不仅需要将数据收集起来还要将不同格式的数据进行整理,最后再做相应的操作。
二、数据导入、存储
访问数据是数据分析的所必须的第一步,只有访问到数据才可以对数据进行分析。
1. 文本格式
常用pandas解析函数:
pandas提供了一些用于将表格型数据读取为DataFrame对象的函数。以下
| 函数 | 描述 |
|---|---|
| read_csv | 从文件、url或者文件型对象读取分割好的数据,逗号是默认分隔符 |
| read_table | 从文件、url或者文件型对象读取分割好的数据,制表符('\t')是默认分隔符 |
| read_fwf | 读取定宽格式数据(无分隔符) |
| read_clipboard | 读取剪贴板中的数据,可以看做read_table的剪贴板。再将网页转换为表格 |
| read_excel | 从Excel的XLS或者XLSX文件中读取表格数据 |
| read_hdf | 读取pandas写的HDF5文件 |
| read_html | 从HTML文件中读取所有表格数据 |
| read_json | 从json字符串中读取数据 |
| read_pickle | 从Python pickle格式中存储的任意对象 |
| read_msgpack | 二进制格式编码的pandas数据 |
| read_sas | 读取存储于sas系统自定义存储格式的SAS数据集 |
| read_stata | 读取Stata文件格式的数据集 |
| read_feather | 读取Feather二进制文件格式 |
| read_sql | 将SQL查询的结果(SQLAlchemy)读取为pandas的DataFrame |
我们可以通过上表对这些解析函数有一个简单了解,其中read_csv和read_table是以后用得最多的两个方法,接下来我们主要就这两个方法测试。
(1)read_csv
csv文件就是一个以逗号分隔字段的纯文本文件,用于测试的文件是本身是一个Excel文件,需要修改一下扩展名,但是简单的修改后缀名不行,还需要将字符编码改变为utf-8,因为默认的是ASCII,否则是会报错的。然后就可以通过read_csv将它读入到一个
DataFrame:
import pandas as pd
import numpy as np
data = pd.read_csv("douban_movie.csv")# 可以是本地的文件,需要绝对路径
data
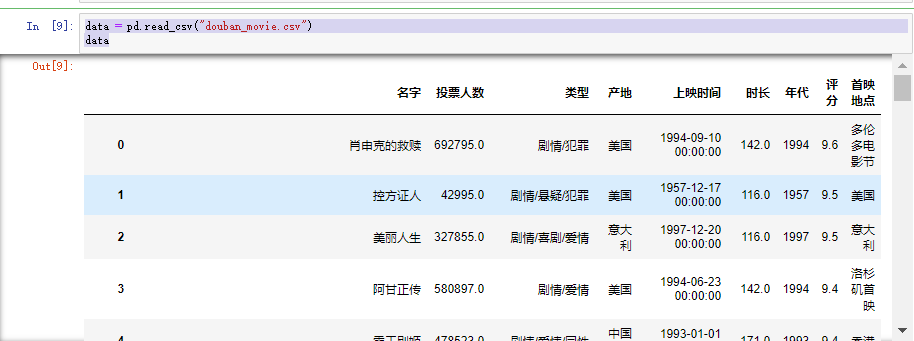 需要注意的是:
需要注意的是:
到这里可能就会有人有疑问了,为什么我自己本地的文件,文件路劲不对,那是因为在我们这个方法当中的路径,当它往往左斜的时候,需要用双斜杠,否则就要是由右斜杠
(2)read_table
还可以使用read_table,并且指定分隔符
data = pd.read_table("douban_movie.csv",sep=',')
data.head()# 只显示5条数据
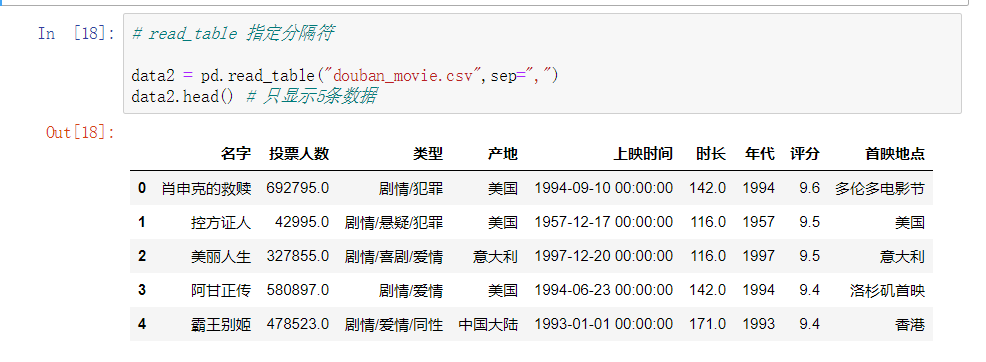
如果不指定分隔符,它的数据之间会有逗号。
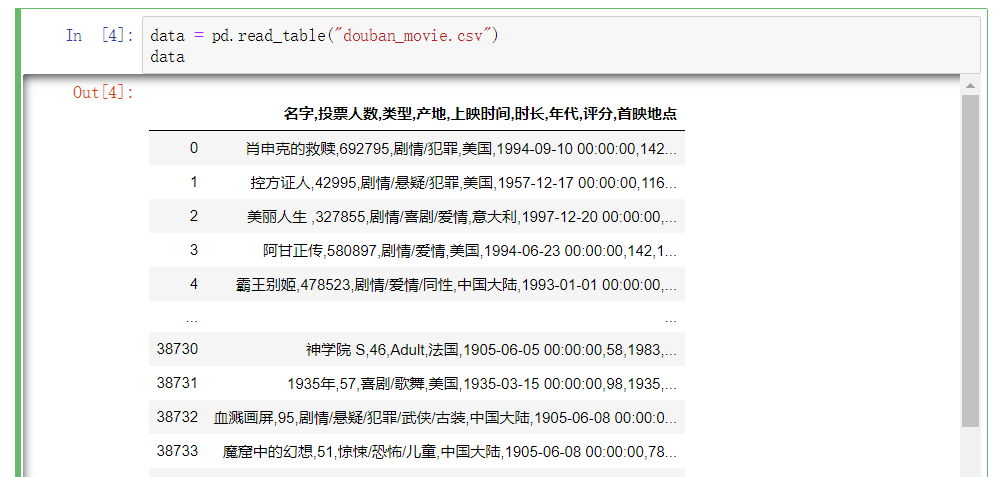
(3)指定列名
pandas可以帮助我们自动分配列名,也可以自已指定列名
默认列名
指定列名
具体的参数如下:
这些参数是read_csv 和 read_table共有的
2. 二进制
(1)pickle
在python种有一个自带的序列化模块pickle,它是进行二进制格式操作存储数据最高校,最方便的方式之一,在pandas有一个to_pickle方法可以将数据以pickle格式写入硬盘
import pandas as pd
df = pd.read_csv("E:/Test/test_j.csv")
df.to_pickle("E:/Test/df_pickle")
运行完之后会发现没有反应,但是可以打开你存储的文件夹会发现这个pickle文件已经存在里面了。
虽然说这种方式非常的方便,但是却很难保证格式的长期有效性,一个今天被pickle化的对象可能明天会因为库的新版本而无法反序列化,在pandas当中还支持其他的二进制格式。如下
(2)HDF5
HDF5主要用于存储大量的科学数组数据。以C库的形式提供,并且有许多其他语言的接,列如:java、julia、当然还有我们的Python。
HDF5中的HDF代表分层数据格式,每个HDF5文件可以存储多个数据集并且支持元数据
pandas .read_hdf函数是一个使用HDF5格式的一个快捷方式
import pandas as pd
import numpy as np
frame = pd.DataFrame({'a':np.random.randn(100)})
frame.to_hdf('E:/jupyter/pandas_test/mydata.h5','obj3',format='table')
pd.read_hdf('E:/jupyter/pandas_test/mydata.h5','obj3',where=['index < 5'])
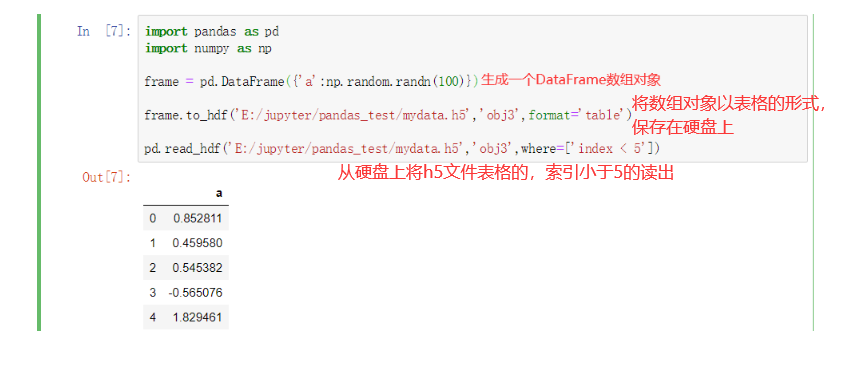
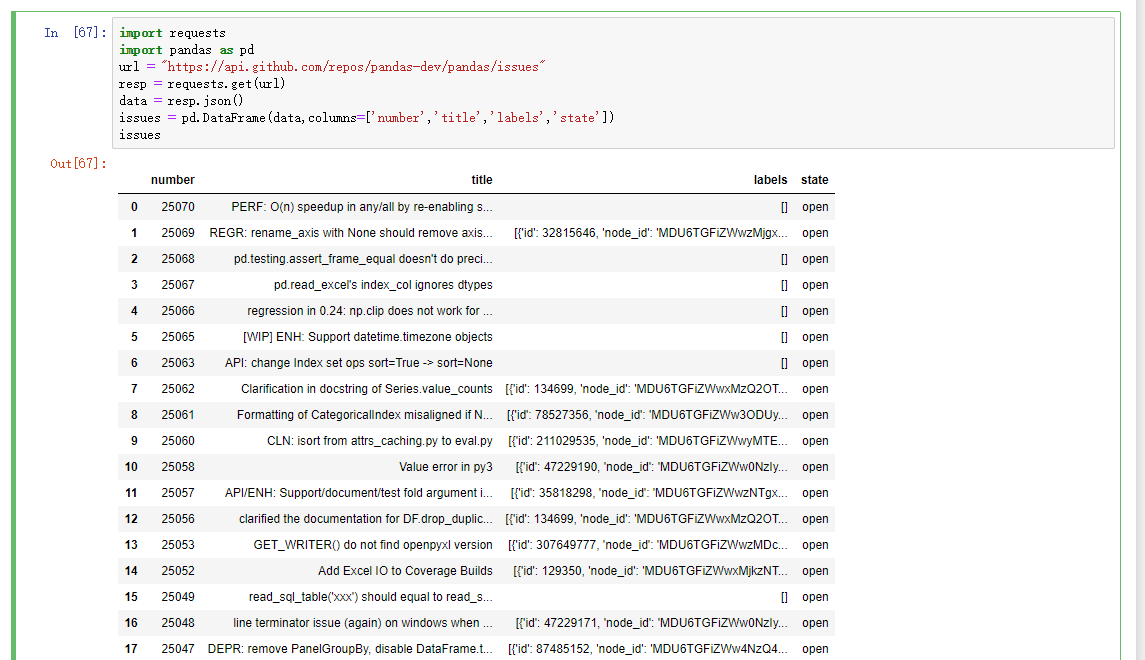
3.Web API
现在很多网站都有公开的API,通过JSON或者其他什么格式提供数据服务,那接下来我们就通过python的request模块访问web API
url = "https://api.github.com/repos/pandas-dev/pandas/issues"
resp = requests.get(url)
data = resp.json()
# 因为data中的每个元素都是一个字典,可以直接将data传给DataFrame,并且将其中自己喜欢的字段展示出来
issues = pd.DataFrame(data,columns=['number','title','labels','state'])
issues
4.操作数据库
在数据分析的操作当中,读写数据库主要还是由pandas来进行操作。在工作环境最为常用的就是Mysql数据库,所以就以操作mysql作为示例:
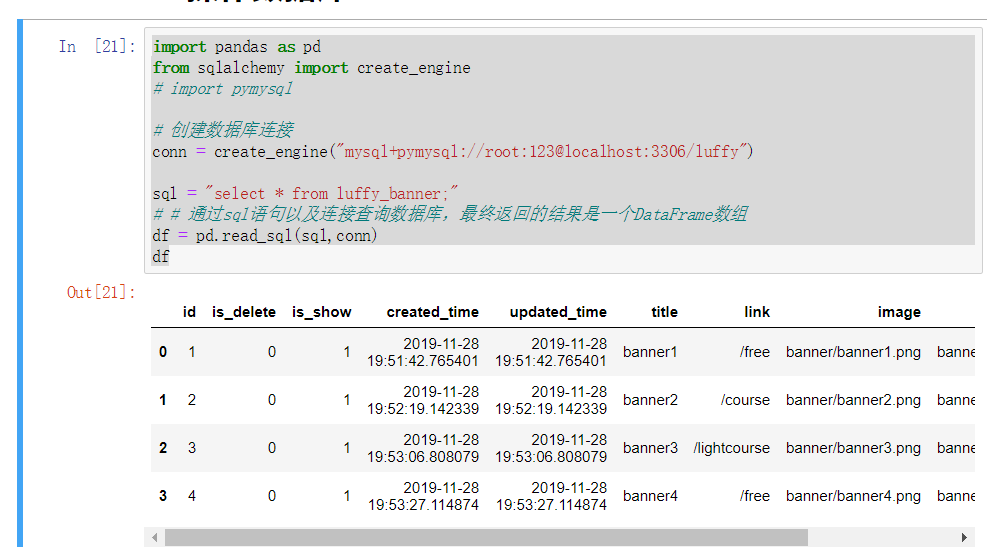
(1)导出数据
import pandas as pd
from sqlalchemy import create_engine
# import pymysql
# 创建数据库连接
conn = create_engine("mysql+pymysql://root:123@localhost:3306/luffy")
sql = "select * from luffy_banner;"
# # 通过sql语句以及连接查询数据库,最终返回的结果是一个DataFrame数组
df = pd.read_sql(sql,conn)
df
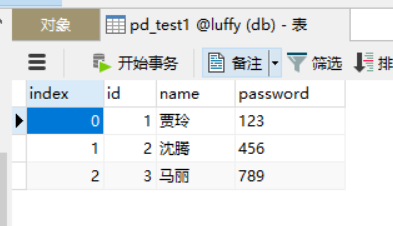
(2)导入数据
在pandas当中存在一个to_sql函数,可以将数据写入数据库,它支持两类mysql引擎,一个是sqlalchemy,另一个是sqlit3.
但是由于sqlit3后就没有更新,所以就建议使用sqlalchemy
import pandas as pd
from sqlalchemy import create_engine
import pymysql
# 创建数据库连接
conn = create_engine("mysql+pymysql://root:123@localhost:3306/luffy")
# key为列,键为值
data = pd.DataFrame({'id':[1,2,3],
'name':['贾玲','沈腾','马丽'],
'password':['123','456','789']})
# 第一个参数:新建的表名;第二个:数据库连接
data.to_sql('pd_test1',conn,index = True)
运行结束后,通过可视化工具打开数据库就可以看见,一个DataFrame数组就直接存在数据库里面了
三、数据分组和聚合
在数据分析当中,我们有时需要将数据拆分,然后在每一个特定的组里进行运算,这些操作通常也是数据分析工作中的重要环节。
分组聚合相对来说也是一个稍微难理解的点,需要各位有一定的功力来学习
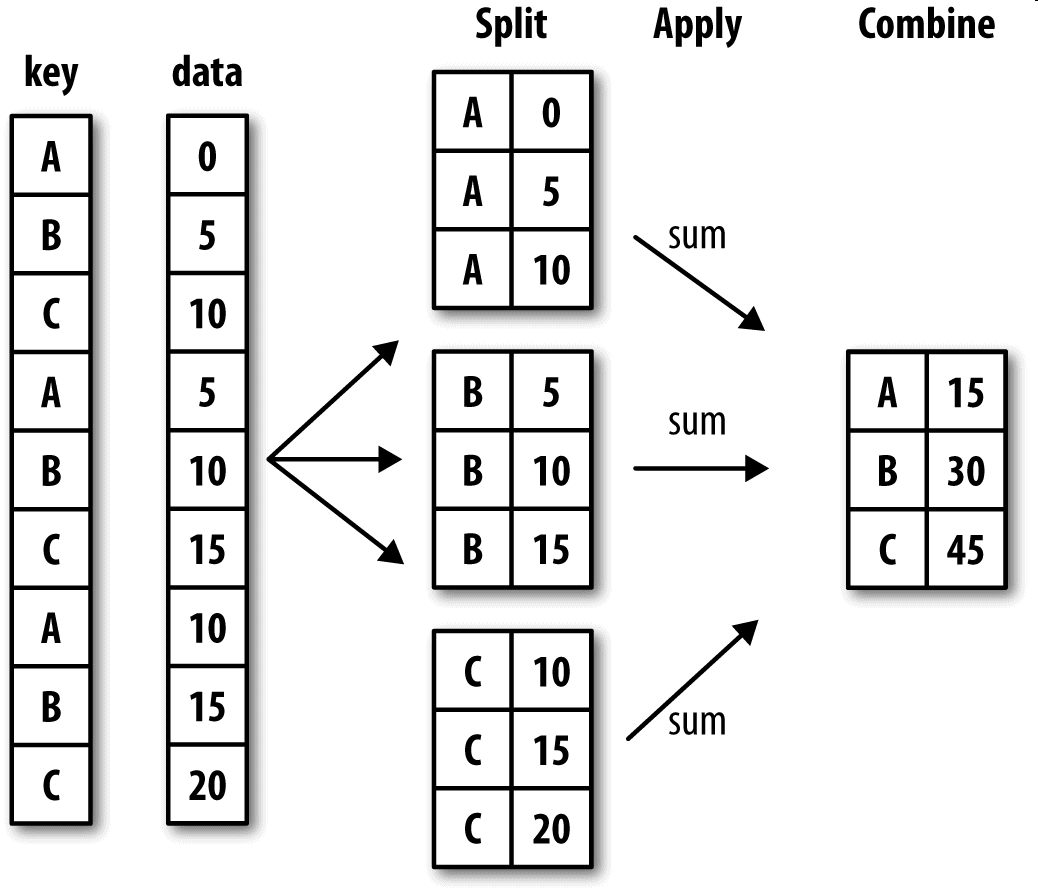
1. 分组(GroupBy机制)
pandas对象(无论Series、DataFrame还是其他的什么)当中的数据会根据提供的一个或者多个键被拆分为多组,拆分操作实在对象的特定轴上执行分,就比如DataFrame可以在他的行上或者列上进行分组,然后将一个函数应用到各个分组上并产生一个新的值。
最后将所有的执行结果合并到最终的结果对象中
分组键可以是多种样式,并且键不一定是完全相同的类型:
- 列表或者数组,长度要与待分组的轴一样
- 表示DataFrame某个列名的值。
- 字典或Series,给出待分组轴上的值与分组名之间的对应关系
- 函数,用于处理轴索引或者索引中的各个标签
后三种只是快捷方式,最周任然是为了产生一组用于拆分对象的值。
首先,通过一个很简单的DataFrame数组尝试一下:
df = pd.DataFrame({'key1':['x','x','y','y','x',
'key2':['one','two','one',',two','one'],
'data1':np.random.randn(5),
'data2':np.random.randn(5)})
df
运行结果如下:
> key1 key2 data1 data2
0 x one 0.951762 1.632336
1 x two -0.369843 0.602261
2 y one 1.512005 1.331759
3 y two 1.383214 1.025692
4 x one -0.475737 -1.182826
测试如下:
1.访问data1,并根据key1调用groupby
f1 = df['data1'].groupby(df['key'])
print(f1)
结果如下:
<pandas.core.groupby.generic.SeriesGroupBy object at 0x000002906F7EC780>
2.上述运行是没有进行任何计算的,但是我们想要的中间数据已经拿到了,接下来,就可以调用groupby进行任何计算了
f1.mean() # 调用mean函数求出平均值
结果如下:
key1
x -0.023235
y -0.616363
Name: data1, dtype: float64
3.以上数据经过分组键(一个Series数组)进行了聚合,产生了一个新的Series,索引就是key1列中的唯一值。这些索引名称就为key1.接下来就尝试一次将多个数据的列表传进来
f2 = df['data1'].groupby([df['key1'],df['key2']])
f2.mean()
结果如下:
key1 key2
x one 0.407317
two -0.884339
y two -0.940015
one -0.292710
Name: data1, dtype: float64
4.传入多个数据之后,就会发现,得到的数据具有一个层次化的索引,key1对应的x/y;key2对应的noe/two
f2.mean().unstack() # 通过unstack方法就可以让索引不堆叠在一起了
结果如下:
key2 one two
key1
x 0.552454 -0.962275
y 1.244774 0.183788
补充
- 分组键可以是任意长度的数组
- 分组时,会与不是数组数据的列会从结果中排除,例如key1、key2这样的列
- Groupby的size方法,返回一个含有分组大小的Series
# 以上面的f2测试
f2.size()
> key1 key2
x one 2
two 1
y one 1
two 1
Name: data1, dtype: int64
到这里跟着我上面的步骤一步一步的分析,会发现还是很简单的,但是一定要动手练,只有多练才能融汇贯通
2. 聚合(组内应用某个函数)
聚合是指任何能够从数组产生标量值的数据转换过程。
刚才上面的操作会发现使用Groupby并不会直接得到一个显性的结果,而是一个中间数据,可以通过执行类似mean、count、min等计算得出结果,常见的还有一些:
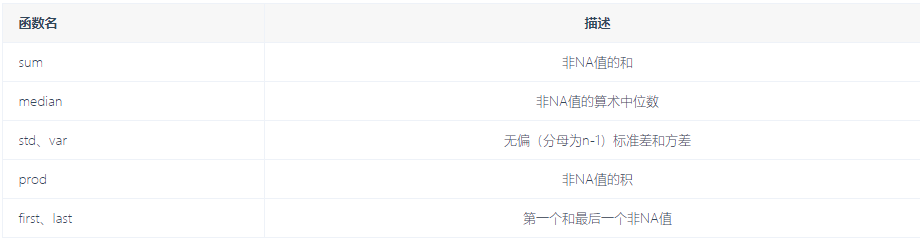
自定义聚合函数
不仅可以使用这些常用的聚合运算,还可以自己自定义。
df = pd.DataFrame({'key1':['x','x','y','y','x'],
'key2':['one','two','one','two','one'],
'data1':np.random.randn(5),
'data2':np.random.randn(5)})
f1 = df['data1'].groupby(df['key1'])
# 自定义的函数
def peak_to_peak(arr):
return arr.max() - arr.min()
# 使用自定义的聚合函数,需要将其传入aggregate或者agg方法当中
f1.aggregate(peak_to_peak)
运行结果:
key1
x 3.378482
y 1.951752
Name: data1, dtype: float64
多函数聚合
可以将分组过后的非显性结果,一次性显示多个计算数据
最终得到的列就会以相应的函数命名生成一个DataFrame数组
f1.agg(['mean','std'])
运行结果:
mean std
key1
x -0.856065 0.554386
y -0.412916 0.214939
以上我们是可以通过agg或者aggragate来实现多函数聚合以及自定义聚合函数,但是一定要注意agg方法只能进行聚合操作。
进行其他例如:排序,这些方法是会报错的,agg返回的数据的标量,所以有些时候并不适合使用agg,这就要看我们接下来的操作了
3. apply
Groupby当中自由度最高的方法就是apply,它会将待处理的对象拆分为多个片段,然后各个片段分别调用传入的函数,最后将他们组合在一起。

# 分析欧洲杯和欧洲冠军联赛决赛名单
import pandas as pd
url="https://en.wikipedia.org/wiki/List_of_European_Cup_and_UEFA_Champions_League_finals"
eu_champions=pd.read_html(url) # 获取数据
a1 = eu_champions[2] # 取出决赛名单
a1.columns = a1.loc[0] # 使用第一行的数据替换默认的横向索引
a1.drop(0,inplace=True) # 将第一行的数据删除
a1.drop('#',axis=1,inplace=True) # 将以#为列名的那一列删除
a1.columns=['Season', 'Nation', 'Winners', 'Score', 'Runners_up', 'Runners_up_Nation', 'Venue','Attendance'] # 设置列名
a1.tail() # 查看后五行数据
a1.drop([64,65],inplace=True) # 删除其中的缺失行以及无用行
a1
运行结果如下:

现在想根据分组选出Attendance列中值最高的三个。
# 先自定义一个函数
def top(df,n=3,column='Attendance'):
return df.sort_values(by=column)[-n:]
top(a1,n=3)
运行结果如下:

接下来,就对a1分组并使用apply调用该函数
a1.groupby('Nation').apply(top)
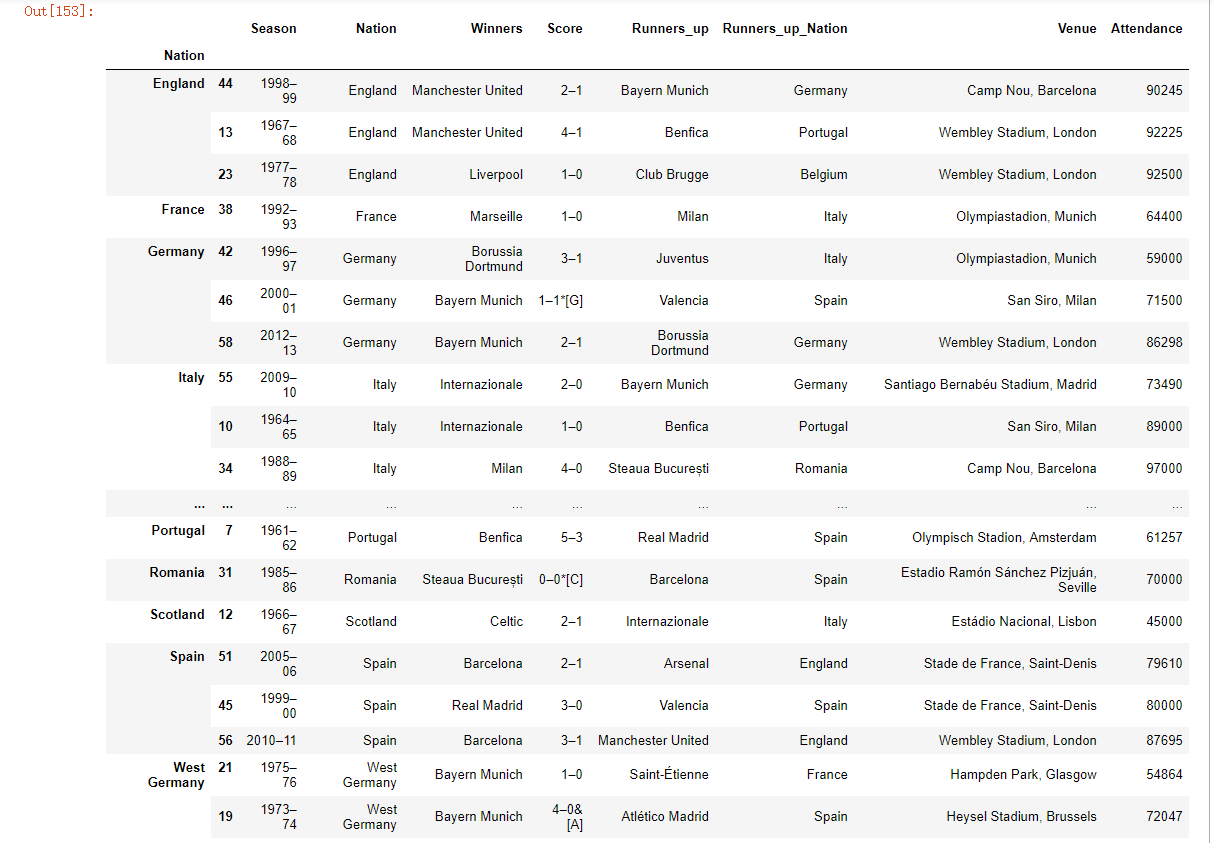
运行之后会发现,我们通过这个操作将每个国家各个年份时段出席的人数的前三名进行了一个提取。
以上top函数实在DataFrame的各个片段上调用,然后结果又通过pandas.concat组装到一起,并且以分组名称进行了标记
以上只是基本用法,apply的强大之处就在于传入函数能做什么都由自已说了算,它只是返回一个pandas对象或者标量值就行
四、pandas其他常用方法
pandas常用方-法(使用Series和DataFrame)
- mean(axis=0,skipna=False)
- sum(axis=1)
- sort_index(axis,···ascending) 按行或列索引排序
- sort_value(by,axis,ascending)按值排序
- apply(func,axis=0)将自定义函数应用在各行或各列上,func可反倒会标量或者Series
- applymap(func)将函数应用在DataFrame各个元素上
- map(func)将函数应用在Series各个元素上

 浙公网安备 33010602011771号
浙公网安备 33010602011771号